Adversarial Orthogonal Disentanglement for LVLM Hallucination Mitigation
Pith reviewed 2026-06-29 22:36 UTC · model grok-4.3
The pith
Adversarial Orthogonal Disentanglement isolates a hallucination direction in LVLM latent space to enable training-free mitigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
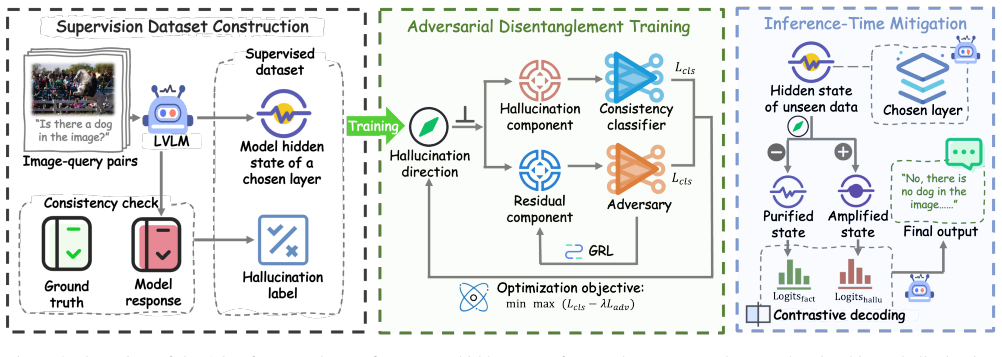
AOD learns a hallucination-related direction through a minimax objective: a classifier concentrates hallucination signals into the projected component, while an adversary removes them from the orthogonal residual space via a Gradient Reversal Layer. The learned direction enables a training-free dual-forward-pass contrastive decoding strategy that suppresses hallucinations while preserving general capabilities.
What carries the argument
The minimax objective with Gradient Reversal Layer that separates hallucination signals into one linear direction while preserving the orthogonal complement for general capabilities.
If this is right
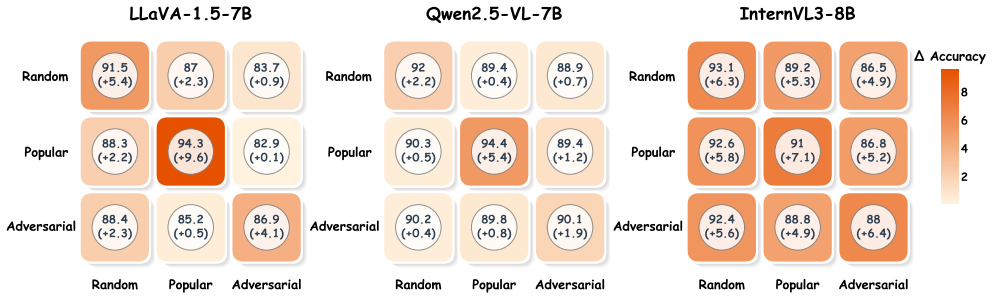
- Improves POPE accuracy by over 6% on average across tested LVLMs.
- Boosts AMBER scores by 6%.
- Maintains strong performance on utility benchmarks such as MMMU.
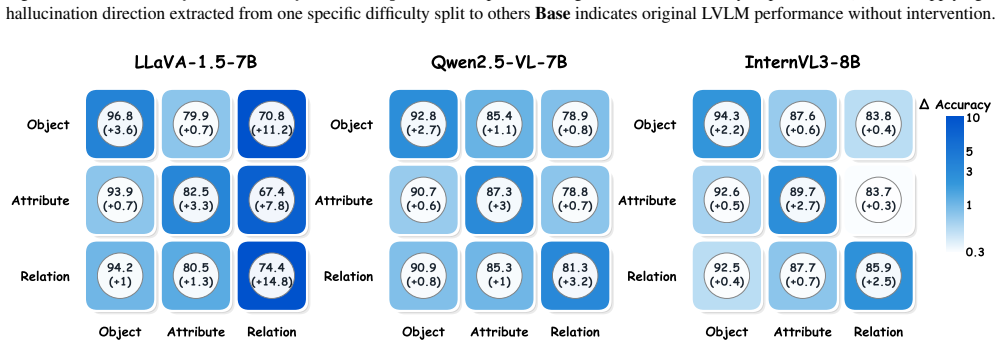
- Shows robust transfer across datasets, capturing general hallucination biases.
- Outperforms strong baselines on four hallucination and four utility benchmarks.
Where Pith is reading between the lines
- If the direction is consistent, it could be precomputed once and applied to new models without retraining.
- The approach suggests hallucinations are a directional bias rather than scattered noise in representation space.
- Similar disentanglement might apply to other failure modes like factual errors in text-only models.
- Testing on larger or different architectures would confirm if the linear separability holds broadly.
Load-bearing premise
Hallucination signals can be concentrated into one linearly projectable direction that is cleanly separable from the orthogonal residual space.
What would settle it
If the contrastive decoding using the learned direction fails to improve hallucination metrics on new datasets or if the direction extracted from one model does not transfer to another without retraining.
Figures



read the original abstract
Large Vision-Language Models (LVLMs) have advanced multimodal understanding, yet their reliability is limited by hallucination, where generated content conflicts with visual facts. Existing mitigation methods either rely on costly external interventions, such as instruction tuning and retrieval, or use internal mechanisms that remain limited by flawed attention weights and entangled hidden representations. We propose Adversarial Orthogonal Disentanglement (AOD), a latent geometric framework for mitigating LVLM hallucinations. AOD learns a hallucination-related direction through a minimax objective: a classifier concentrates hallucination signals into the projected component, while an adversary removes them from the orthogonal residual space via a Gradient Reversal Layer. The learned direction enables a training-free dual-forward-pass contrastive decoding strategy that suppresses hallucinations while preserving general capabilities. Experiments on three LVLMs across four hallucination and four utility benchmarks show that AOD consistently outperforms strong baselines. It improves POPE accuracy by over 6\% on average, boosts AMBER by 6\%, and maintains strong performance on utility tasks such as MMMU. Further analysis shows robust transfer across datasets, suggesting that AOD captures general hallucination-related biases rather than dataset-specific artifacts. Our source code and datasets are available at https://github.com/Hunter-Wrynn/AOD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adversarial Orthogonal Disentanglement (AOD), a latent-space method for LVLM hallucination mitigation. A minimax objective trains a classifier to concentrate hallucination signals into a projected direction while a Gradient Reversal Layer adversary purges them from the orthogonal residual; the resulting direction supports a training-free dual-forward contrastive decoding procedure. Experiments across three LVLMs report average gains of >6% on POPE, 6% on AMBER, and preserved utility on MMMU and similar benchmarks, with evidence of cross-dataset transfer.
Significance. If the disentanglement holds, AOD supplies a lightweight, training-free geometric intervention that avoids external retrieval or instruction tuning while releasing code and datasets—an explicit strength. The approach could clarify whether hallucination biases occupy a single linear direction in multimodal latent spaces and, if so, offer a reusable mitigation primitive.
major comments (3)
- [§3.2] §3.2, Eq. (3)–(5): the minimax objective and GRL construction presuppose that hallucination signals concentrate into one linearly projectable direction cleanly separable from the orthogonal residual; the manuscript provides no direct test (e.g., higher-order statistics or non-linear probes) that this geometry actually obtains, which is load-bearing for the claim that contrastive decoding in §3.3 suppresses hallucinations without collateral utility loss.
- [Experiments section] Experiments section, Table 2 and §4.3: the reported POPE and AMBER gains are presented without protocol details on baseline re-implementations, statistical tests, or variance across random seeds; this prevents assessment of whether the 6% margins are robust or sensitive to the precise definition of the hallucination direction.
- [§4.4] §4.4: the cross-dataset transfer analysis is cited as evidence that the direction captures general biases rather than artifacts, yet no ablation removes the classifier or GRL to quantify how much of the gain is attributable to the orthogonal disentanglement versus the contrastive decoding alone.
minor comments (2)
- [Abstract] Abstract: the phrase 'over 6% on average' should be replaced by the exact mean and standard deviation across the three models.
- [§3.3] Notation: the projection operator and the orthogonal complement are introduced without an explicit equation defining the residual space used in the dual-forward pass.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (3)–(5): the minimax objective and GRL construction presuppose that hallucination signals concentrate into one linearly projectable direction cleanly separable from the orthogonal residual; the manuscript provides no direct test (e.g., higher-order statistics or non-linear probes) that this geometry actually obtains, which is load-bearing for the claim that contrastive decoding in §3.3 suppresses hallucinations without collateral utility loss.
Authors: We agree that the assumption of a dominant linear direction is foundational to the AOD framework and that direct validation via non-linear probes or higher-order statistics would strengthen the geometric claim. The current evidence is indirect, resting on downstream performance gains. In the revision we will add an analysis section that applies non-linear classifiers to the residual space and reports higher-order moment statistics to test the separability assumption more rigorously. revision: yes
-
Referee: Experiments section, Table 2 and §4.3: the reported POPE and AMBER gains are presented without protocol details on baseline re-implementations, statistical tests, or variance across random seeds; this prevents assessment of whether the 6% margins are robust or sensitive to the precise definition of the hallucination direction.
Authors: The referee correctly identifies missing methodological details. The original manuscript omitted explicit re-implementation protocols for baselines, statistical testing procedures, and multi-seed variance. We will revise the Experiments section to include full baseline reproduction details, paired statistical significance tests, and standard deviations computed over at least five random seeds for both POPE and AMBER results. revision: yes
-
Referee: [§4.4] §4.4: the cross-dataset transfer analysis is cited as evidence that the direction captures general biases rather than artifacts, yet no ablation removes the classifier or GRL to quantify how much of the gain is attributable to the orthogonal disentanglement versus the contrastive decoding alone.
Authors: We acknowledge that the transfer results alone do not isolate the contribution of the adversarial disentanglement step. To address this, the revised manuscript will include a new ablation that compares (i) the full AOD pipeline, (ii) contrastive decoding using a randomly initialized direction, and (iii) contrastive decoding using the direction obtained without the GRL adversary. This will quantify the incremental benefit attributable to the orthogonal component. revision: yes
Circularity Check
No significant circularity; method is externally validated on benchmarks
full rationale
The paper defines AOD via a standard minimax objective (classifier + GRL adversary) trained on data to isolate a hallucination direction, then applies the resulting direction in a training-free contrastive decoder. Reported gains (e.g., +6% POPE, +6% AMBER) are measured on separate hallucination and utility benchmarks with transfer analysis across datasets. No equations reduce the evaluation metrics to the training objective by construction, no self-citation is invoked as a uniqueness theorem, and no fitted parameter is relabeled as an independent prediction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hallucination signals exist as a linearly separable direction in LVLM latent space that can be isolated without destroying orthogonal utility representations
Forward citations
Cited by 1 Pith paper
-
HunterAgent: Neuro-Symbolic Attack Trace Reconstruction under Anti-Forensics
HunterAgent combines LLM hypothesis generation with symbolic verification and cost-bounded graph search to reconstruct attack paths under anti-forensics, reporting 86.1% mean F1 on benchmarks with reduced hallucinations.
Reference graph
Works this paper leans on
-
[1]
Ayala and P
O. Ayala and P. Bechard. Reducing hallucination in structured outputs via retrieval-augmented generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (Volume 6: Industry Track), pages 228–238, 2024. 2
2024
-
[2]
Benazha, S
H. Benazha, S. Ayache, H. Kadri, and T. Artières. Mea- suring hallucination in disentangled representations. In 2024 International Joint Conference on Neural Net- works (IJCNN), pages 1–8. IEEE, 2024. 3
2024
-
[3]
Cadene, C
R. Cadene, C. Dancette, M. Cord, D. Parikh, et al. Rubi: Reducing unimodal biases for visual question answering.Advances in Neural Information Processing Systems, 32:841–852, 2019. 3
2019
- [4]
-
[5]
L. Chen, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, J. Wang, Y . Qiao, D. Lin, et al. Are we on the right way for evaluating large vision-language models? arXiv preprint arXiv:2403.20330, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Cheng, Y
R. Cheng, Y . Ding, S. Cao, R. Duan, X. Jia, S. Yuan, S. Qin, Z. Wang, and X. Jia. Pbi-attack: Prior-guided bimodal interactive black-box jailbreak attack for tox- icity maximization. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 609–628, 2025. 1
2025
- [7]
- [8]
-
[9]
J. Duan, F. Kong, H. Cheng, J. Diffenderfer, B. Kailkhura, L. Sun, X. Zhu, X. Shi, and K. Xu. Truthprint: Mitigating large vision-language mod- els object hallucination via latent truthful-guided pre- intervention. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 7372– 7382, 2025. 1, 3, 5, 6
2025
-
[10]
L. Fu, B. Yang, Z. Kuang, J. Song, Y . Li, L. Zhu, Q. Luo, X. Wang, H. Lu, M. Huang, Z. Li, G. Tang, B. Shan, C. Lin, Q. Liu, B. Wu, H. Feng, H. Liu, C. Huang, J. Tang, W. Chen, L. Jin, Y . Liu, and X. Bai. Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning, 2024. URL https://arxiv.org/ abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Ganin, E
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V . Lem- pitsky. Domain-adversarial training of neural networks. J. Mach. Learn. Res., 17(1):2096–2030, Jan. 2016. ISSN 1532-4435. 2, 4
2096
-
[12]
T. Guan, F. Liu, X. Wu, R. Xian, Z. Li, X. Liu, X. Wang, L. Chen, F. Huang, Y . Yacoob, et al. Hallusion- bench: an advanced diagnostic suite for entangled lan- guage hallucination and visual illusion in large vision- language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14375–14385, 2024. 5
2024
-
[13]
Higgins, L
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner. beta- V AE: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations, 2017. URL https: //openreview.net/forum?id=Sy2fzU9gl . 3
2017
- [14]
-
[15]
Z. Hu, L. Shen, S. Lai, and C. Yuan. Task-adaptive feature disentanglement and hallucination for few-shot classification.IEEE Transactions on Circuits and Sys- tems for Video Technology, 33(8):3638–3648, 2023. 3
2023
-
[16]
Karras, S
T. Karras, S. Laine, and T. Aila. A style-based genera- tor architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 3
2019
-
[17]
Y . Kim, B. O. Kang, and H. J. Song. Context-aware image caption editing via hallucination-resistant visual instruction tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5842–5852, 2025. 2
2025
-
[18]
S. Leng, H. Zhang, G. Chen, X. Li, S. Lu, C. Miao, and L. Bing. Mitigating object hallucinations in large vision-language models through visual contrastive de- coding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024. 2, 5, 6
2024
-
[19]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rock- täschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020. 1
2020
-
[20]
X. Li, C. Wen, Y . Hu, Z. Yuan, and X. X. Zhu. Vision- language models in remote sensing: Current progress and future trends.IEEE Geoscience and Remote Sens- ing Magazine, 12(2):32–66, 2024. 1
2024
-
[21]
Y . Li, Y . Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023. 4, 5
2023
-
[22]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 5
2024
-
[23]
Y . Liu, Z. Li, M. Huang, B. Yang, W. Yu, C. Li, X.- C. Yin, C.-L. Liu, L. Jin, and X. Bai. Ocrbench: on the hidden mystery of ocr in large multimodal mod- els.Science China Information Sciences, 67(12), Dec
-
[24]
doi: 10.1007/s11432-024- 4235-6
ISSN 1869-1919. doi: 10.1007/s11432-024- 4235-6. URL http://dx.doi.org/10.1007/ s11432-024-4235-6. 5
-
[25]
Locatello, S
F. Locatello, S. Bauer, M. Lucic, G. Raetsch, S. Gelly, B. Schölkopf, and O. Bachem. Challenging common assumptions in the unsupervised learning of disentan- gled representations. Ininternational conference on machine learning, pages 4114–4124. PMLR, 2019. 3
2019
- [26]
-
[27]
J. Pang, R. Cheng, Z. Ye, X. Ma, Z. Wu, X. Huang, and Y .-G. Jiang. Steering the verifiability of multimodal ai hallucinations.arXiv preprint arXiv:2604.06714, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [28]
-
[29]
Rohrbach, L
A. Rohrbach, L. A. Hendricks, K. Burns, T. Darrell, and K. Saenko. Object hallucination in image cap- tioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, 2018. 5
2018
-
[30]
Sapkota and M
R. Sapkota and M. Karkee. Object detection with multimodal large vision-language models: An in-depth review.Information Fusion, 126:103575, 2026. 1
2026
-
[31]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
J. Su, J. Chen, H. Li, Y . Chen, L. Qing, and Z. Zhang. Activation steering decoding: Mitigating hallucination in large vision-language models through bidirectional hidden state intervention. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[33]
J. Su, J. Chen, H. Li, Y . Chen, L. Qing, and Z. Zhang. Activation steering decoding: Mitigating hallucination in large vision-language models through bidirectional hidden state intervention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12964– 12974, 2025. 4, 5, 6
2025
-
[34]
Subramani, N
N. Subramani, N. Suresh, and M. E. Peters. Extracting latent steering vectors from pretrained language mod- els. InFindings of the Association for Computational Linguistics: ACL 2022, pages 566–581, 2022. 4
2022
- [35]
-
[36]
J. M. Varela, A. B. de Palhares Jr, and D. H. Duarte. Entanglement detection and quantification through ma- chine learning: A comprehensive review.Brazilian Journal of Physics, 56(1):25, 2026. 1
2026
- [37]
-
[38]
J. Wang, Y . Wang, G. Xu, J. Zhang, Y . Gu, H. Jia, J. Wang, H. Xu, M. Yan, J. Zhang, et al. Amber: An llm-free multi-dimensional benchmark for mllms hallu- cination evaluation.arXiv preprint arXiv:2311.07397,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2- vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
H. Wu, H. Huang, A. Yu, J. Cao, Z. Lei, and R. He. Exemplar guided cross-spectral face hallucination via mutual information disentanglement. In2020 25th In- ternational Conference on Pattern Recognition (ICPR), pages 4206–4212. IEEE, 2021. 3
2021
-
[41]
RealWorldQA: A benchmark for real-world spa- tial understanding
xAI. RealWorldQA: A benchmark for real-world spa- tial understanding. https://huggingface.co/ datasets/xai-org/RealworldQA, 2024. Ac- cessed: 2025-04-26. 5
2024
-
[42]
S.-J. Xia, H. Zhang, Y . Jiang, X. Chen, Y . Chen, Z. Li, Z. Wan, and A. Sun. Rethinking hallucinations: A cognitive-inspired taxonomy and comprehensive sur- vey in large language models, large vision-language models, and multimodal large language models.Large Vision-Language Models, and Multimodal Large Lan- guage Models (November 09, 2025), 2025. 1
2025
-
[43]
H. Yang, D. Liu, Z. Chen, J. Han, and S. Hu. Mitigating object hallucinations in large vision-language models via multi-scale visual integration. 2
-
[44]
T. Yang, Z. Li, J. Cao, and C. Xu. Mitigating hallu- cination in large vision-language models via modular attribution and intervention. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. URL https://openreview.net/forum?id= Bjq4W7P2Us. 2
2025
-
[45]
X. Yue, Y . Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y . Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y . Liu, W. Huang, H. Sun, Y . Su, and W. Chen. Mmmu: A mas- sive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of CVPR, 2024. 5
2024
-
[46]
F. Zhang, Y . Wu, Z. Wang, X. Wang, C. Lv, X. Huang, and X. Zheng. Vib-probe: Detecting and miti- gating hallucinations in vision-language models via variational information bottleneck.arXiv preprint arXiv:2601.05547, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [47]
-
[48]
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Z. Zhu, Y . Zhang, X. Zhuang, F. Zhang, Z. Wan, Y . Chen, Q. QingqingLong, Y . Zheng, and X. Wu. Can we trust ai doctors? a survey of medical hallucination in large language and large vision-language models. In Findings of the Association for Computational Linguis- tics: ACL 2025, pages 6748–6769, 2025. 1
2025
-
[50]
Zhuang, Z
X. Zhuang, Z. Zhu, Y . Xie, L. Liang, and Y . Zou. Vas- parse: Towards efficient visual hallucination mitigation via visual-aware token sparsification. InProceedings of the Computer Vision and Pattern Recognition Con- ference, pages 4189–4199, 2025. 2, 5, 6
2025
-
[51]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 3, 7 A. Appendix A.1. Benchmark Details POPEPOPE is a polling-style object hallucination bench- mark built on MSCOCO images. Each example asks ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Consistency labels yi ∈ {0,1} are generated by comparing ˆai with ground-truth answers ai
Base Inference & Labeling:We process input pairs (xi, qi) through the frozen base LVLM to obtain predic- tions ˆai. Consistency labels yi ∈ {0,1} are generated by comparing ˆai with ground-truth answers ai. For POPE- style experiments, prompts explicitly force single-word answers to ensure unambiguous labels
-
[53]
For all main experiments, we setℓ= 24
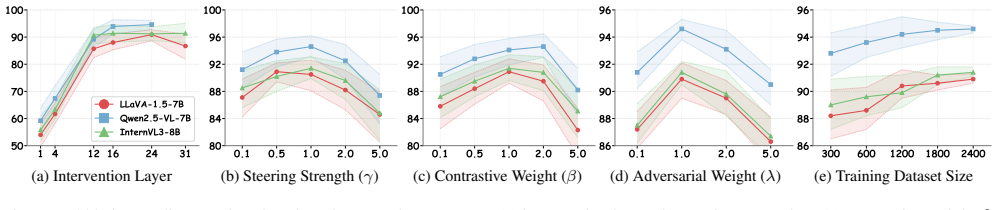
Hidden State Extraction:We extract hidden activations zi ∈R d at the intervention layer ℓ corresponding to the last generated token position (i.e., token_index=-1). For all main experiments, we setℓ= 24
-
[54]
Adversarial Training:We learn the hallucination- correlated direction v∗ using the extracted pairs {(zi, yi)}N i=1 via the minimax objective
-
[55]
It can be dynamically applied during inference via contrastive decoding or reused across unseen datasets without backbone fine-tuning
Inference Intervention:Once trained, v∗ acts as a plug- and-play steering vector. It can be dynamically applied during inference via contrastive decoding or reused across unseen datasets without backbone fine-tuning. Optimization and training parameters.Given a hid- den representation z and a unit-norm direction v, AOD de- composes the representation into...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.