AnE: Pushing the Reasoning Frontier of Multimodal LLMs via Anchor Evolution
Pith reviewed 2026-06-29 22:54 UTC · model grok-4.3
The pith
Anchor Evolution advances multimodal LLM reasoning by curating data with ground-truth anchors and internalizing paths via scaffold stripping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
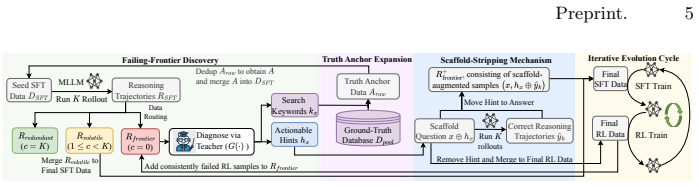
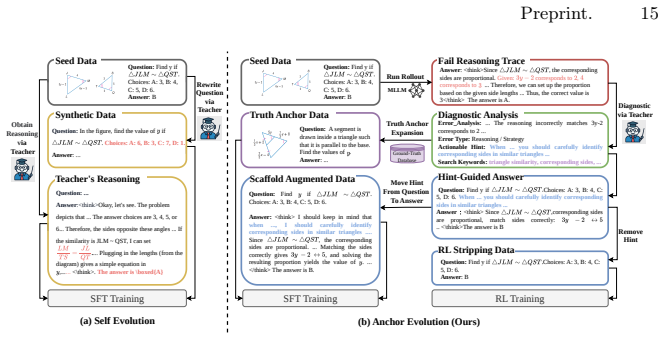
Anchor Evolution integrates Truth Anchor Expansion, which identifies the model's failing frontier through trajectory rollouts and retrieves high-fidelity anchors from ground-truth databases for data curation, with the Scaffold-Stripping Mechanism that first anchors reasoning paths via scaffold-augmented supervision to reduce learning complexity and distribution drift, then applies RL to remove the scaffold template and transition those paths into intrinsic model capabilities, thereby achieving faithful and steady performance gains at the reasoning frontier.
What carries the argument
Anchor Evolution (AnE) paradigm that pairs Truth Anchor Expansion for faithful data curation with the Scaffold-Stripping Mechanism for internalizing reasoning paths.
If this is right
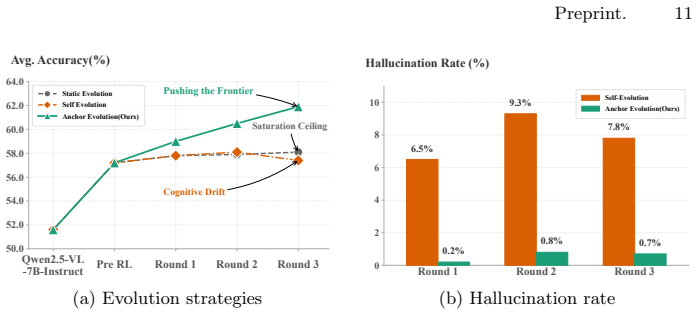
- The method produces a 10.3 percent average improvement on eight multimodal reasoning benchmarks.
- Reasoning paths become intrinsic model capabilities rather than remaining dependent on external scaffolds.
- Cognitive drift and hallucinated paths are reduced through reliance on ground-truth anchors instead of self-generated data.
- The same pipeline reaches state-of-the-art results on the evaluated benchmarks.
Where Pith is reading between the lines
- If ground-truth databases are available in other domains, the same anchoring-plus-stripping pattern could be tested on text-only or video reasoning tasks.
- The approach implies that hybrid SFT-then-RL sequences with explicit anchors may lower the volume of synthetic data needed for continued progress.
- Iterative application of Truth Anchor Expansion could be explored to generate successive waves of frontier-pushing data without manual database expansion.
Load-bearing premise
Ground-truth databases exist that are comprehensive and can supply high-fidelity anchors to pinpoint and correct the model's failing frontier without introducing new biases or gaps.
What would settle it
Running the full AnE pipeline on the base model across the eight multimodal benchmarks and observing zero net gain or an increase in hallucinated reasoning paths compared with the base model would falsify the central claim.
Figures


read the original abstract
Post-training via Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) is crucial for enhancing reasoning in Multimodal Large Language Models (MLLMs), yet existing paradigms often reach a performance bottleneck due to the limitations of static data. While current methods leverage self-reflection or self-evolution to push these boundaries, they still suffer from cognitive drift and hallucinated reasoning paths caused by low-quality synthetic data. To address these challenges, we propose Anchor Evolution (AnE), a new paradigm that integrates truth-anchored data curation and model evolution, achieving faithful and steady performance gains at the reasoning frontier. Specifically, we propose Truth Anchor Expansion, which pinpoints the model failing frontier via trajectory rollouts and leverages ground-truth databases to retrieve high-fidelity anchors for faithful data curation. Subsequently, we introduce the Scaffold-Stripping Mechanism to internalize reasoning capabilities. This mechanism first anchors reasoning paths via scaffold-augmented supervision to mitigate the learning complexity and distribution drift of direct SFT on raw data, then leverages RL to strip the scaffold template, thereby effectively transitioning the reasoning paths into intrinsic model capabilities. Experimental results on multimodal reasoning benchmarks show that our method substantially advances the model performance frontier, improving the base model by 10.3\% across eight multimodal benchmarks and achieving state-of-the-art results. The code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Anchor Evolution (AnE), a post-training paradigm for Multimodal LLMs that integrates Truth Anchor Expansion (trajectory rollouts to identify failing frontiers followed by retrieval of anchors from ground-truth databases for data curation) with a Scaffold-Stripping Mechanism (scaffold-augmented SFT to anchor reasoning paths, followed by RL to internalize them). It claims this yields a 10.3% average improvement over the base model across eight multimodal reasoning benchmarks while reaching SOTA performance, addressing limitations of static data, self-reflection, and synthetic data drift.
Significance. If the performance claims hold under rigorous verification, the combination of external truth anchors with scaffold-based internalization could provide a concrete mechanism for reducing hallucinated reasoning paths in MLLM post-training, offering a reproducible alternative to purely self-evolutionary methods. The stated intent to release code supports potential impact on the field.
major comments (3)
- [Abstract] Abstract: the central claim of a 10.3% improvement and SOTA results across eight benchmarks is presented without any experimental protocol, base model specification, benchmark list, baselines, run counts, error bars, or ablation results, rendering the quantitative advance unverifiable and load-bearing for the paper's contribution.
- [Abstract] Abstract (Truth Anchor Expansion): the method's reliance on ground-truth databases to supply high-fidelity anchors that correct failing frontiers is load-bearing for the claim of faithful curation without introducing new biases, yet no information is given on database construction, coverage of the eight benchmarks, validation against distributional gaps, or retrieval procedure.
- [Abstract] Abstract (Scaffold-Stripping Mechanism): the two-stage process is described at a conceptual level, but the absence of implementation details (scaffold template form, RL algorithm, drift measurement, or how supervision transitions to intrinsic capabilities) prevents evaluation of whether the mechanism actually mitigates the stated distribution drift.
minor comments (1)
- [Abstract] The abstract states that code will be made publicly available, but provides no repository link, license, or reproduction instructions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The abstract is a concise high-level overview, while the full experimental protocols, method details, and results are elaborated in the main text. We address each point below and will revise the abstract to improve verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 10.3% improvement and SOTA results across eight benchmarks is presented without any experimental protocol, base model specification, benchmark list, baselines, run counts, error bars, or ablation results, rendering the quantitative advance unverifiable and load-bearing for the paper's contribution.
Authors: We agree the abstract as written lacks these specifics and is therefore insufficient for standalone verification. The manuscript provides the base model specification, benchmark list, baselines, run counts, error bars, and ablation results in the Experiments section. We will revise the abstract to include a brief statement of the experimental setup. revision: yes
-
Referee: [Abstract] Abstract (Truth Anchor Expansion): the method's reliance on ground-truth databases to supply high-fidelity anchors that correct failing frontiers is load-bearing for the claim of faithful curation without introducing new biases, yet no information is given on database construction, coverage of the eight benchmarks, validation against distributional gaps, or retrieval procedure.
Authors: The manuscript describes database construction, benchmark coverage, validation against distributional gaps, and the retrieval procedure in the Method section. We will revise the abstract to briefly reference these elements of Truth Anchor Expansion. revision: yes
-
Referee: [Abstract] Abstract (Scaffold-Stripping Mechanism): the two-stage process is described at a conceptual level, but the absence of implementation details (scaffold template form, RL algorithm, drift measurement, or how supervision transitions to intrinsic capabilities) prevents evaluation of whether the mechanism actually mitigates the stated distribution drift.
Authors: The manuscript provides the scaffold template form, RL algorithm, drift measurement approach, and transition mechanism in the Method section. We will revise the abstract to include key implementation details of the Scaffold-Stripping Mechanism. revision: yes
Circularity Check
No significant circularity; method relies on external ground-truth databases
full rationale
The paper describes Truth Anchor Expansion as retrieving anchors from external ground-truth databases after trajectory rollouts, followed by Scaffold-Stripping via SFT then RL. No equations, fitted parameters, or self-referential loops are present. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The 10.3% gain is presented as an experimental outcome, not a derivation that reduces to its own inputs by construction. The central claim remains independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ground-truth databases exist and supply high-fidelity anchors that correctly identify and correct model failure points.
Reference graph
Works this paper leans on
-
[1]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Yunxin Li, Zhenyu Liu, Zitao Li, Xuanyu Zhang, Zhenran Xu, Xinyu Chen, Haoyuan Shi, Shenyuan Jiang, Xintong Wang, Jifang Wang, et al. Perception, reason, think, and plan: A survey on large multimodal reasoning models.arXiv preprint arXiv:2505.04921, 2025
-
[3]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl gener- alizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Aojun Lu, Tao Feng, Hangjie Yuan, Wei Li, and Yanan Sun. Why does rl generalize better than sft? a data-centric perspective on vlm post-training.arXiv preprint arXiv:2602.10815, 2026. 16 Z. Wang et al
-
[6]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. Cognitive behaviors thatenable self-improvingreasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Guanghao Zhou, Panjia Qiu, Cen Chen, Jie Wang, Zheming Yang, Jian Xu, and Minghui Qiu. Reinforced mllm: A survey on rl-based reasoning in multimodal large language models.arXiv preprint arXiv:2504.21277, 2025
-
[9]
Kaichen Zhang, Keming Wu, Zuhao Yang, Bo Li, Kairui Hu, Bin Wang, Ziwei Liu, Xingxuan Li, and Lidong Bing. Openmmreasoner: Pushing the frontiers for multi- modalreasoningwithanopenandgeneralrecipe.arXiv preprint arXiv:2511.16334, 2025
-
[10]
OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Openvlthinker: Complex vision-language reasoning via iterative sft-rl cycles.arXiv preprint arXiv:2503.17352, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
SyncLoop: A Multimodal Dual-Loop Framework for Self-Improving Mathematical Reasoning
Xiuwei Chen, Wentao Hu, Hanhui Li, Jun Zhou, Zisheng Chen, Meng Cao, Yihan Zeng,KuiZhang,Yu-JieYuan,JianhuaHan,etal. C2-evo:Co-evolvingmultimodal data and model for self-improving reasoning.arXiv preprint arXiv:2507.16518, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Mmevol: Em- powering multimodal large language models with evol-instruct
Run Luo, Haonan Zhang, Longze Chen, Ting-En Lin, Xiong Liu, Yuchuan Wu, Min Yang, Yongbin Li, Minzheng Wang, Pengpeng Zeng, et al. Mmevol: Em- powering multimodal large language models with evol-instruct. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19655–19682, 2025
2025
-
[13]
Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale
Jiawei Guo, Tianyu Zheng, Yizhi Li, Yuelin Bai, Bo Li, Yubo Wang, King Zhu, Graham Neubig, Wenhu Chen, and Xiang Yue. Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13869–13920, 2025
2025
-
[14]
Jierun Chen, Tiezheng Yu, Haoli Bai, Lewei Yao, Jiannan Wu, Kaican Li, Fei Mi, Chaofan Tao, Lei Zhu, Manyi Zhang, et al. The synergy dilemma of long-cot sft and rl: Investigating post-training techniques for reasoning vlms.arXiv preprint arXiv:2507.07562, 2025
-
[15]
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like rea- soning large vision-language models.arXiv preprint arXiv:2504.11468, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Sicong Leng, Jing Wang, Jiaxi Li, Hao Zhang, Zhiqiang Hu, Boqiang Zhang, Yum- ing Jiang, Hang Zhang, Xin Li, Lidong Bing, et al. Mmr1: Enhancing multi- modal reasoning with variance-aware sampling and open resources.arXiv preprint arXiv:2509.21268, 2025
-
[18]
Yana Wei, Liang Zhao, Jianjian Sun, Kangheng Lin, Jisheng Yin, Jingcheng Hu, Yinmin Zhang, En Yu, Haoran Lv, Zejia Weng, et al. Open vision reasoner: Transferring linguistic cognitive behavior for visual reasoning.arXiv preprint arXiv:2507.05255, 2025. Preprint. 17
-
[19]
Weiting Liu, Han Wu, Yufei Kuang, Xiongwei Han, Tao Zhong, Jianfeng Feng, and Wenlian Lu. Automated optimization modeling via a localizable error-driven perspective.arXiv preprint arXiv:2602.11164, 2026
-
[20]
Xiaomi mimo-vl-miloco technical report.arXiv preprint arXiv:2512.17436, 2025
Jiaze Li, Jingyang Chen, Yuxun Qu, Shijie Xu, Zhenru Lin, Junyou Zhu, Boshen Xu, Wenhui Tan, Pei Fu, Jianzhong Ju, et al. Xiaomi mimo-vl-miloco technical report.arXiv preprint arXiv:2512.17436, 2025
-
[21]
Jack Chen, Fazhong Liu, Naruto Liu, Yuhan Luo, Erqu Qin, Harry Zheng, Tian Dong, Haojin Zhu, Yan Meng, and Xiao Wang. Step-wise adaptive integration of supervised fine-tuning and reinforcement learning for task-specific llms.arXiv preprint arXiv:2505.13026, 2025
-
[22]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, et al. Learning what rein- forcementlearningcan’t:Interleavedonlinefine-tuningforhardestquestions.arXiv preprint arXiv:2506.07527, 2025
-
[23]
Haibo Qiu, Xiaohan Lan, Fanfan Liu, Xiaohu Sun, Delian Ruan, Peng Shi, and Lin Ma. Metis-rise: Rl incentivizes and sft enhances multimodal reasoning model learning.arXiv preprint arXiv:2506.13056, 2025
-
[24]
Feng Zhang, Zezhong Tan, Xinhong Ma, Ziqiang Dong, Xi Leng, Jianfei Zhao, Xin Sun,andYangYang. Adhint:Adaptivehintswithdifficultypriorsforreinforcement learning.arXiv preprint arXiv:2512.13095, 2025
-
[25]
Reflectevo: Improving meta intro- spection of small llms by learning self-reflection
Jiaqi Li, Xinyi Dong, Yang Liu, Zhizhuo Yang, Quansen Wang, Xiaobo Wang, Song-Chun Zhu, Zixia Jia, and Zilong Zheng. Reflectevo: Improving meta intro- spection of small llms by learning self-reflection. InFindings of the Association for Computational Linguistics: ACL 2025, pages 16948–16966, 2025
2025
-
[26]
EvoLMM: Self-Evolving Large Multimodal Models with Continuous Rewards
Omkar Thawakar, Shravan Venkatraman, Ritesh Thawkar, Abdelrahman Shaker, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Khan. Evolmm: Self-evolving large multimodal models with continuous rewards.arXiv preprint arXiv:2511.16672, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Woosung Koh, Wonbeen Oh, Jaein Jang, MinHyung Lee, Hyeongjin Kim, Ah Yeon Kim, Joonkee Kim, Junghyun Lee, Taehyeon Kim, and Se-Young Yun. Adas- tar: Adaptive data sampling for training self-taught reasoners.arXiv preprint arXiv:2505.16322, 2025
-
[28]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Ex- ploring the frontiers of multimodal reasoning with rule-based reinforcement learn- ing.arXiv preprint arXiv:2503.07365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy opti- mization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Ad- vancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025. 18 Z. Wang et al
2087
-
[33]
Runqi Qiao, Qiuna Tan, Peiqing Yang, Yanzi Wang, Xiaowan Wang, Enhui Wan, Sitong Zhou, Guanting Dong, Yuchen Zeng, Yida Xu, et al. We-math 2.0: A versatile mathbook system for incentivizing visual mathematical reasoning.arXiv preprint arXiv:2508.10433, 2025
-
[34]
Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, et al. Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search. arXiv preprint arXiv:2412.18319, 2024
-
[35]
Xingxuan Li, Yao Xiao, Dianwen Ng, Hai Ye, Yue Deng, Xiang Lin, Bin Wang, Zhanfeng Mo, Chong Zhang, Yueyi Zhang, et al. Miromind-m1: An open-source advancement in mathematical reasoning via context-aware multi-stage policy op- timization.arXiv preprint arXiv:2507.14683, 2025
-
[36]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Ha- jishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean confer- ence on computer vision, pages 235–251. Springer, 2016
2016
-
[37]
Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volu...
2021
-
[38]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension
Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. InProceedings of the IEEE Conference on Computer Vision and Pattern recognition, pages 4999–5007, 2017
2017
-
[40]
Runqi Qiao, Qiuna Tan, Guanting Dong, MinhuiWu MinhuiWu, Chong Sun, Xi- aoshuai Song, Jiapeng Wang, Zhuoma Gongque, Shanglin Lei, Yifan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages...
2025
-
[41]
Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns
Yew Ken Chia, Vernon Toh, Deepanway Ghosal, Lidong Bing, and Soujanya Po- ria. Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns. InFindings of the Association for Computational Linguistics: ACL 2024, pages 16259–16273, 2024
2024
-
[42]
Deepanway Ghosal, Vernon Toh Yan Han, Chia Yew Ken, and Soujanya Poria. Are language models puzzle prodigies? algorithmic puzzles unveil serious challenges in multimodal reasoning.arXiv preprint arXiv:2403.03864, 2024
-
[43]
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sampleselectionfordata-efficientvisualreasoningself-improvement.arXiv preprint arXiv:2504.07934, 2025
-
[44]
FineVision: Open Data Is All You Need
Luis Wiedmann, Orr Zohar, Amir Mahla, Xiaohan Wang, Rui Li, Thibaud Frere, Leandro von Werra, Aritra Roy Gosthipaty, and Andrés Marafioti. Finevision: Open data is all you need.arXiv preprint arXiv:2510.17269, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 881–916, 2025. Preprint. 19
2025
-
[46]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluat- ing mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Measuring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024
2024
-
[48]
Mathverse: Does your multi- modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi- modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186. Springer, 2024
2024
-
[49]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Scienceqa: A novel resource for question answering on scholarly articles
Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, and Pushpak Bhat- tacharyya. Scienceqa: A novel resource for question answering on scholarly articles. International Journal on Digital Libraries, 23(3):289–301, 2022
2022
-
[51]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
XiangYue,YuanshengNi,KaiZhang,TianyuZheng,RuoqiLiu,GeZhang,Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[52]
Yunzhuo Hao, Jiawei Gu, Huichen Will Wang, Linjie Li, Zhengyuan Yang, Lijuan Wang, and Yu Cheng. Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark.arXiv preprint arXiv:2501.05444, 2025
-
[53]
Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
2024
-
[54]
Zhongwei Wan, Zhihao Dou, Che Liu, Yu Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Yi Xin, Yifan Jiang, et al. Srpo: Enhancing multi- modal llm reasoning via reflection-aware reinforcement learning.arXiv preprint arXiv:2506.01713, 2025
-
[55]
Shuang Chen, Yue Guo, Zhaochen Su, Yafu Li, Yulun Wu, Jiacheng Chen, Jiayu Chen, Weijie Wang, Xiaoye Qu, and Yu Cheng. Advancing multimodal reason- ing: From optimized cold start to staged reinforcement learning.arXiv preprint arXiv:2506.04207, 2025
-
[56]
Spark: Synergistic policy and reward co- evolving framework.arXiv preprint arXiv:2509.22624, 2025
Ziyu Liu, Yuhang Zang, Shengyuan Ding, Yuhang Cao, Xiaoyi Dong, Haodong Duan, Dahua Lin, and Jiaqi Wang. Spark: Synergistic policy and reward co- evolving framework.arXiv preprint arXiv:2509.22624, 2025
-
[57]
Llava-critic-r1: Your critic model is secretly a strong policy model
Xiyao Wang, Chunyuan Li, Jianwei Yang, Kai Zhang, Bo Liu, Tianyi Xiong, and Furong Huang. Llava-critic-r1: Your critic model is secretly a strong policy model. arXiv preprint arXiv:2509.00676, 2025
-
[58]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt- 4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022. 20 Z. Wang et al
2022
-
[60]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advanc- ing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Mme: A comprehensive eval- uation benchmark for multimodal large language models.Advances in Neural Information Processing Systems, 38, 2026
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive eval- uation benchmark for multimodal large language models.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[62]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, HeWang,andLiYi. Omnispatial:Towardscomprehensivespatialreasoningbench- mark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[63]
Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M Tamer Özsu, Aishwarya Agrawal, David Vazquez, et al. Ui-vision: A desktop-centric gui benchmark for visual perception and interaction.arXiv preprint arXiv:2503.15661, 2025
-
[64]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026. Preprint. 21 Supplementary Material A Details of Experimental Settings E...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Model claimed [X], but the image/text shows [Y]
Failure Analysis - Locate the exact step where the logic first deviates. - Quote the erroneous or hallucinated sentence(s). - Contrast with reality using statements such as: "Model claimed [X], but the image/text shows [Y]." "Model calculated [X], but the correct derivation is [Y]."
-
[66]
Add secondary factors only if necessary
Error Categorization Choose exactly one primary root cause. Add secondary factors only if necessary. If the primary cause fully explains the failure, leave secondary_errors empty. Categories - Perception / Understanding: incorrect reading of the input. - Knowledge / Information: correct perception but missing or wrong external knowledge. - Reasoning / Str...
-
[67]
- Actionable Hint: must contain both: Strategy: high-level advice
Feedback - Explanation: concise diagnosis of why the failure happened. - Actionable Hint: must contain both: Strategy: high-level advice. Mechanism: trigger -> action -> verification
-
[68]
error_analysis
Search Keywords Provide 3-6 short English phrases for retrieving similar practice examples. Use phrases likely to appear in similar questions. Keyword focus: - Perception / Understanding: visual task description or input format. - Knowledge / Information: specific concept or fact. - Reasoning / Strategy: problem structure or logical step. - Execution / Ou...
2011
-
[69]
Area of the Quarter Circle: the radiusrof the circle is given asa= 4cm; the area of a full circle isπr 2; therefore, the area of a quarter circle is 1 4 πr2
-
[70]
The area of a right triangle is given by 1 2 ×base×height
Area of the Right Triangle: the right triangle has one side equal to the radius of the circle,r= 4cm; the other side of the triangle is also4cm (since it’s a square cut in half). The area of a right triangle is given by 1 2 ×base×height
-
[71]
incorrectly added areas
Combining the Areas: the shaded area is the sum of the area of the quarter circle and the area of the right triangle. Substituter= 4cm into the formulas. Let’s calculate each part step by step. Area of the quarter circle: Area= 1 4 πr2 = 1 4 π(4)2 = 1 4 π×16 = 4πcm 2 Area of the right triangle: Area= 1 2 ×4×4 = 1 2 ×16 = 8cm 2 Total shaded area: Shaded ar...
2057
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.