Mosaic: Compositional Multi-Concept Erasure via Vector Field Blending
Pith reviewed 2026-06-29 22:51 UTC · model grok-4.3
The pith
Mosaic erases multiple target concepts from one image by blending concept-specific masks in the vector field.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
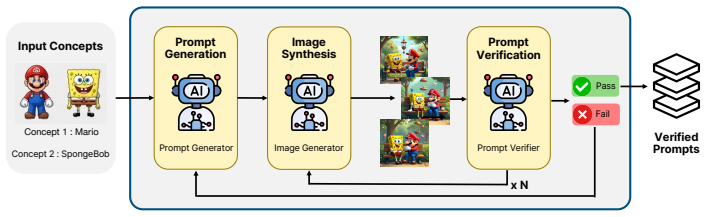
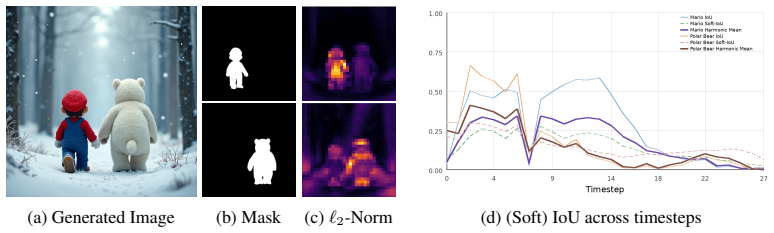
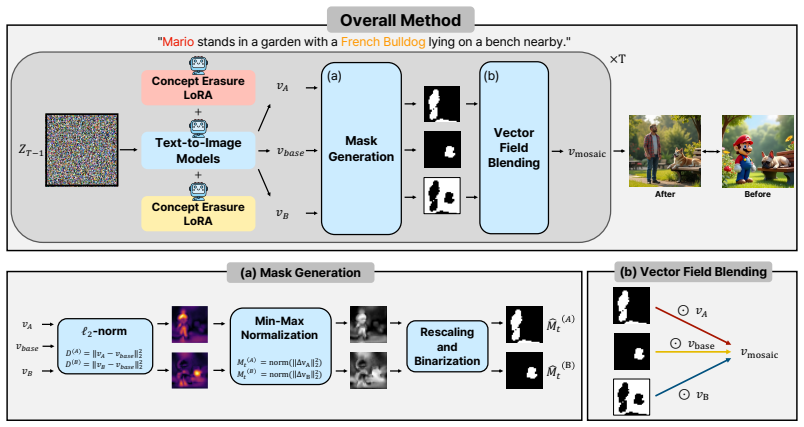
Mosaic is a framework for compositional multi-concept erasure in flow-based T2I models that exploits spatial locality of target concepts in the vector field. It dynamically builds concept-specific masks and performs selective blending to remove multiple targets simultaneously while leaving non-target regions intact, all without additional optimization.
What carries the argument
Dynamic construction of concept-specific masks followed by selective vector field blending.
If this is right
- Multiple concepts can be removed from a single complex scene in one forward pass.
- No per-concept fine-tuning or optimization is needed after the initial model training.
- The same blending procedure applies to both same-category and different-category concept pairs.
- Non-target context and overall scene structure remain unchanged after erasure.
Where Pith is reading between the lines
- If vector-field locality generalizes, the same mask-blending idea could apply to other generative architectures that produce spatial fields.
- Real-time multi-concept editing tools could be built on top of this approach without retraining.
- Platforms generating images on demand might adopt the method to reduce post-filtering steps for safety.
Load-bearing premise
Target concepts occupy sufficiently separate regions in the vector field that their masks can be blended without affecting each other or unrelated image content.
What would settle it
A test image containing two target concepts where the blended output still shows visible traces of either concept or alters non-target elements would falsify the central claim.
Figures












read the original abstract
Concept erasure has emerged as a key research direction for ensuring safe and ethical image synthesis in Text-to-Image (T2I) models. While existing studies have explored concept erasure across multiple concepts, they typically assume only a single target concept per image, a limitation increasingly exposed by modern flow-based T2I models, which can generate complex scenes with multiple concepts simultaneously. To address this gap, we introduce compositional multi-concept erasure, a new task that aims to simultaneously remove multiple target concepts within a single scene. We propose CoME-Bench, a benchmark for evaluating compositional multi-concept erasure, which covers both intra- and cross-category scenarios. We further propose Mosaic, a novel framework for multi-concept erasure in flow-based T2I models, which exploits the spatial locality of target concepts in the vector field by dynamically constructing concept-specific masks and selectively blending them without additional optimization. Extensive experiments demonstrate that Mosaic effectively removes multiple target concepts in complex compositional scenes while preserving non-target contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of compositional multi-concept erasure in flow-based T2I models (removing multiple target concepts from a single complex scene), proposes the CoME-Bench benchmark covering intra- and cross-category cases, and presents the Mosaic framework. Mosaic exploits assumed spatial locality of concepts in the vector field to dynamically build per-concept masks and blend them for optimization-free erasure while preserving non-target regions. The abstract asserts that extensive experiments confirm Mosaic's effectiveness on this task.
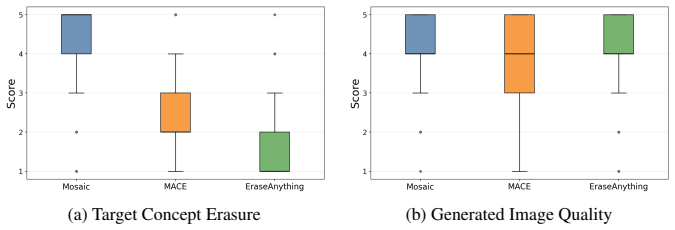
Significance. If the spatial-locality assumption holds and the method delivers the claimed erasure/preservation tradeoff on a properly controlled benchmark, the work would address a genuine gap between single-concept erasure methods and modern flow-based generators that produce multi-concept scenes. The introduction of a dedicated benchmark is a positive step toward standardized evaluation.
major comments (2)
- [Abstract] Abstract: the central claim that 'Mosaic effectively removes multiple target concepts in complex compositional scenes while preserving non-target contexts' is asserted on the basis of 'extensive experiments,' yet the abstract supplies no metrics, baselines, quantitative tables, or controls. This absence makes the headline result unverifiable and is load-bearing for the paper's contribution.
- [Abstract] Abstract (method description): the framework is presented as relying on 'spatial locality of target concepts in the vector field' to enable dynamic mask construction and selective blending. No validation, overlap statistics, activation visualizations, or failure-case analysis of this locality assumption is referenced, leaving the core technical premise untested against the skeptic's concern that diffuse or overlapping fields would cause leakage or incomplete erasure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We respond point-by-point to the major comments below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Mosaic effectively removes multiple target concepts in complex compositional scenes while preserving non-target contexts' is asserted on the basis of 'extensive experiments,' yet the abstract supplies no metrics, baselines, quantitative tables, or controls. This absence makes the headline result unverifiable and is load-bearing for the paper's contribution.
Authors: We agree that the abstract would benefit from greater specificity to support verifiability of the central claim. In the revised version we will incorporate concise quantitative indicators drawn from the CoME-Bench results (e.g., target-concept erasure success and non-target preservation scores) together with a brief statement of the primary baselines. revision: yes
-
Referee: [Abstract] Abstract (method description): the framework is presented as relying on 'spatial locality of target concepts in the vector field' to enable dynamic mask construction and selective blending. No validation, overlap statistics, activation visualizations, or failure-case analysis of this locality assumption is referenced, leaving the core technical premise untested against the skeptic's concern that diffuse or overlapping fields would cause leakage or incomplete erasure.
Authors: The locality assumption is foundational to the dynamic masking procedure. Although the reported experiments demonstrate effective erasure without leakage in practice, we accept that explicit supporting analysis would address potential skepticism. We will add a dedicated paragraph and accompanying figure in the method or experiments section that reports activation overlap statistics and selected vector-field visualizations, including any observed edge cases. revision: yes
Circularity Check
No circularity: method is a direct construction from stated spatial-locality assumption
full rationale
The paper presents Mosaic as a framework that exploits an assumed spatial locality property of concepts in the vector field to build and blend masks. No equations, fitted parameters, or self-citation chains are shown that reduce the claimed erasure performance to the inputs by construction. The central claim rests on an empirical assumption about locality rather than a self-referential derivation or renamed fit. This is self-contained against external benchmarks and receives the default non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[2]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InThe Ninth International Conference on Learning Representations, 2021
2021
-
[3]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 10684–10695, 2022
2022
-
[4]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. InAdvances in Neural Information Processing Systems, volume 35, pag...
2022
-
[5]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[7]
Artists land a win in class action lawsuit against a.i
Richard Whiddington. Artists land a win in class action lawsuit against a.i. com- panies. Artnet News, August 2024. URL https://news.artnet.com/art-world/ artists-vs-stability-ai-lawsuit-moves-ahead-2524849
2024
-
[8]
Ai brad pitt dupes french woman out of C830,000
Laura Gozzi. Ai brad pitt dupes french woman out of C830,000. BBC News, January 2025. URLhttps://www.bbc.com/news/articles/c2l0y7q3k7ro
2025
-
[9]
Diffu- sion art or digital forgery? investigating data replication in diffusion models
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Diffu- sion art or digital forgery? investigating data replication in diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6048–6058, 2023
2023
-
[10]
Hayeon Jeong and Jong-Seok Lee. Dominating vs. dominated: Generative collapse in diffusion models.arXiv preprint arXiv:2512.20666, 2025
-
[11]
Sathwik Karnik, Juyeop Kim, Sanmi Koyejo, Jong-Seok Lee, and Somil Bansal. Steering away from memorization: Reachability-constrained reinforcement learning for text-to-image diffusion.arXiv preprint arXiv:2603.00140, 2026
-
[12]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 22522–22531, 2023
2023
-
[13]
Investigating toxicity and bias in stable diffusion text-to-image models.Scientific Reports, 15(1):31401, 2025
Matthias Schneider and Thilo Hagendorff. Investigating toxicity and bias in stable diffusion text-to-image models.Scientific Reports, 15(1):31401, 2025
2025
-
[14]
Training- free framework for defending unsafe image synthesis attack
Junha Park, Jaehui Hwang, Ian Ryu, Hyungkeun Park, Jiyoon Kim, and Jong-Seok Lee. Training- free framework for defending unsafe image synthesis attack. In2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1906–1910, 2026
1906
-
[15]
Stable diffusion 2.0 release
Stability AI. Stable diffusion 2.0 release. Stability AI Blog, November 2022. URL https: //stability.ai/news/stable-diffusion-v2-release
2022
-
[16]
Ablating concepts in text-to-image diffusion models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22634–22645, 2023
2023
-
[17]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2426–2436, 2023. 11
2023
-
[18]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5099–5108, 2024
2024
-
[19]
Mace: Mass concept erasure in diffusion models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. Mace: Mass concept erasure in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6430–6440, 2024
2024
-
[20]
Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers
Chi-Pin Huang, Kai-Po Chang, Chung-Ting Tsai, Yung-Hsuan Lai, Fu-En Yang, and Yu- Chiang Frank Wang. Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers. InEuropean Conference on Computer Vision, volume 17, pages 360–376, 2024
2024
-
[21]
SAeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders
Bartosz Cywi´nski and Kamil Deja. SAeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders. InForty-second International Conference on Machine Learning, 2025
2025
-
[22]
Cure: Concept unlearning via orthogonal representation editing in diffusion models
Shristi Das Biswas, Arani Roy, and Kaushik Roy. Cure: Concept unlearning via orthogonal representation editing in diffusion models. InAdvances in Neural Information Processing Systems, 2025
2025
-
[23]
Erasing thousands of concepts: Towards scalable and practical concept erasure for text-to-image diffusion models
Hoigi Seo, Byung Hyun Lee, Jaehyun Cho, Sungjin Lim, and Se Young Chun. Erasing thousands of concepts: Towards scalable and practical concept erasure for text-to-image diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, 2026
2026
-
[24]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[25]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[26]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[27]
Eraseanything: Enabling concept erasure in rectified flow transformers
Daiheng Gao, Shilin Lu, Wenbo Zhou, Jiaming Chu, Jie Zhang, Mengxi Jia, Bang Zhang, Zhaoxin Fan, and Weiming Zhang. Eraseanything: Enabling concept erasure in rectified flow transformers. InForty-second International Conference on Machine Learning, 2025
2025
-
[28]
Minimalist concept erasure in generative models
Yang Zhang, Er Jin, Yanfei Dong, Yixuan Wu, Philip Torr, Ashkan Khakzar, Johannes Stegmaier, and Kenji Kawaguchi. Minimalist concept erasure in generative models. InForty-second International Conference on Machine Learning, 2025
2025
-
[29]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[30]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Editing implicit assumptions in text- to-image diffusion models
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Editing implicit assumptions in text- to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7030–7038, 2023
2023
-
[32]
Direct unlearning optimization for robust and safe text-to- image models
Yong-Hyun Park, Sangdoo Yun, Jin-Hwa Kim, Junho Kim, Geonhui Jang, Yonghyun Jeong, Junghyo Jo, and Gayoung Lee. Direct unlearning optimization for robust and safe text-to- image models. InAdvances in Neural Information Processing Systems, volume 37, pages 80244–80267, 2024
2024
-
[33]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7559–7568, 2024. 12
2024
-
[34]
SDErasure: Concept-specific trajectory shifting for concept erasure via adaptive diffusion classifier
Fengyuan Miao, Shancheng Fang, Lingyun Yu, Yadong Qu, Yuhao Sun, Xiaorui Wang, and Hongtao Xie. SDErasure: Concept-specific trajectory shifting for concept erasure via adaptive diffusion classifier. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[35]
Disentangled Sparse Representations for Concept-Separated Diffusion Unlearning
Hyeonjin Kim, Hangyeol Jung, Heechan Yun, Sungjun Yun, and Dong-Jun Han. Disen- tangled sparse representations for concept-separated diffusion unlearning.arXiv preprint arXiv:2605.12122, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Suma: A subspace mapping approach for robust and effective concept erasure in text-to-image diffusion models
Kien Nguyen, Anh Tran, and Cuong Pham. Suma: A subspace mapping approach for robust and effective concept erasure in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19587–19596, 2025
2025
-
[37]
Defensive unlearning with adversarial training for robust concept erasure in diffusion models
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models. InAdvances in neural information processing systems, volume 37, pages 36748–36776, 2024
2024
-
[38]
Memories of forgotten concepts
Matan Rusanovsky, Shimon Malnick, Amir Jevnisek, Ohad Fried, and Shai Avidan. Memories of forgotten concepts. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2966–2975, 2025
2025
-
[39]
Continualflow: Learning and unlearning with neural flow matching
Lorenzo Simone, Davide Bacciu, and Shuangge Ma. Continualflow: Learning and unlearning with neural flow matching. InICML 2025 Workshop on Machine Unlearning for Generative AI, 2025
2025
-
[40]
Flowedit: Inversion-free text-based editing using pre-trained flow models
Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. Flowedit: Inversion-free text-based editing using pre-trained flow models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19721–19730, 2025
2025
-
[41]
Ring-a-bell! how reliable are concept removal methods for diffusion models? InThe Twelfth International Conference on Learning Representations, 2024
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are concept removal methods for diffusion models? InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[42]
Unlearncanvas: Stylized image dataset for enhanced machine unlearning evaluation in diffusion models
Yihua Zhang, Chongyu Fan, Yimeng Zhang, Yuguang Yao, Jinghan Jia, Jiancheng Liu, Gaoyuan Zhang, Gaowen Liu, Ramana Kompella, Xiaoming Liu, and Sijia Liu. Unlearncanvas: Stylized image dataset for enhanced machine unlearning evaluation in diffusion models. InAdvances in Neural Information Processing Systems, volume 37, pages 96387–96423, 2024
2024
-
[43]
Rui Ma, Qiang Zhou, Yizhu Jin, Daquan Zhou, Bangjun Xiao, Xiuyu Li, Yi Qu, Aishani Singh, Kurt Keutzer, Jingtong Hu, et al. A dataset and benchmark for copyright infringement unlearning from text-to-image diffusion models.arXiv preprint arXiv:2403.12052, 2024
-
[44]
Holistic unlearning benchmark: A multi-faceted evaluation for text-to-image diffusion model unlearning
Saemi Moon, Minjong Lee, Sangdon Park, and Dongwoo Kim. Holistic unlearning benchmark: A multi-faceted evaluation for text-to-image diffusion model unlearning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16356–16366, 2025
2025
-
[45]
Comprehensive assessment and analysis for NSFW content erasure in text-to-image diffusion models
Die Chen, Zhiwen Li, Cen Chen, Yuexiang Xie, Xiaodan Li, Jinyan Ye, Yingda Chen, and Yaliang Li. Comprehensive assessment and analysis for NSFW content erasure in text-to-image diffusion models. InAdvances in Neural Information Processing Systems, 2025
2025
-
[46]
Lu Wei, Yuta Nakashima, and Noa Garcia. Emma: Concept erasure benchmark with compre- hensive semantic metrics and diverse categories.arXiv preprint arXiv:2512.17320, 2025
-
[47]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. 13
2022
-
[50]
Z-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers
Nanxiang Jiang, Zhaoxin Fan, Baisen Wang, Daiheng Gao, Junhang Cheng, Jifeng Guo, Yalan Qin, Yeying Jin, Hongwei Zheng, Faguo Wu, et al. Z-erase: Enabling concept erasure in single-stream diffusion transformers.arXiv preprint arXiv:2603.25074, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
O’Reilly Media, Inc
Steven Bird, Ewan Klein, and Edward Loper.Natural language processing with Python: analyzing text with the natural language toolkit. " O’Reilly Media, Inc.", 2009
2009
-
[52]
Fully convolutional networks for se- mantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for se- mantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015
2015
-
[53]
Jaccard metric losses: Optimizing the jaccard index with soft labels.Advances in Neural Information Processing Systems, 36:75259–75285, 2023
Zifu Wang, Xuefei Ning, and Matthew Blaschko. Jaccard metric losses: Optimizing the jaccard index with soft labels.Advances in Neural Information Processing Systems, 36:75259–75285, 2023
2023
-
[54]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Generalized intersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 658–666, 2019
2019
-
[56]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[57]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
2004
-
[58]
Wang, E.P
Z. Wang, E.P. Simoncelli, and A.C. Bovik. Multiscale structural similarity for image quality assessment. InThe Thirty-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pages 1398–1402 V ol.2, 2003
2003
-
[59]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[60]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 14 MOSAIC: Compositional Multi-Concept Erasure via Vector Field Blending Supplementary Materials A. Baseline Implemen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.