Reinforcement Learning from Denoising Feedback
Pith reviewed 2026-06-29 21:18 UTC · model grok-4.3
The pith
RLDF uses feedback from rollout and training to improve policy loss estimation in diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
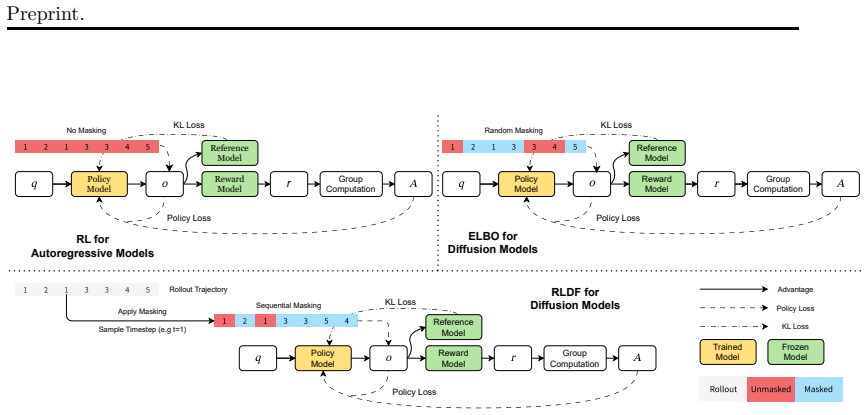
RLDF leverages feedback obtained from rollout and training processes to facilitate accurate and efficient policy loss estimation by optimizing toward the clipped clean state from intermediate noisy states combined with weighted timestep sampling over denoising timesteps.
What carries the argument
Reinforcement Learning from Denoising Feedback (RLDF), which optimizes toward clipped clean states from noisy states with weighted timestep sampling to enable better policy loss estimation.
If this is right
- RLDF produces consistent and substantial performance improvements on multiple reasoning benchmarks.
- The method increases generalizability across different diffusion language model architectures including LLaDA and Dream.
- It establishes a scalable approach for applying reinforcement learning to diffusion language models.
- The accompanying Drift framework makes the method practically usable for training.
Where Pith is reading between the lines
- The denoising feedback principle might extend to reinforcement learning in other diffusion-based generative domains such as images or audio if similar rollout signals exist.
- If the weighted timestep sampling proves robust, it could reduce training variance when scaling to larger diffusion language models.
- The approach may connect to existing feedback techniques in standard reinforcement learning for autoregressive models.
Load-bearing premise
Feedback from rollout and training processes can be used for accurate policy loss estimation without introducing bias that negates the reported performance gains.
What would settle it
Running the same experiments on the reported benchmarks and architectures but finding no improvement or detecting bias in the estimated policy losses would show the method does not deliver the claimed benefits.
Figures
read the original abstract
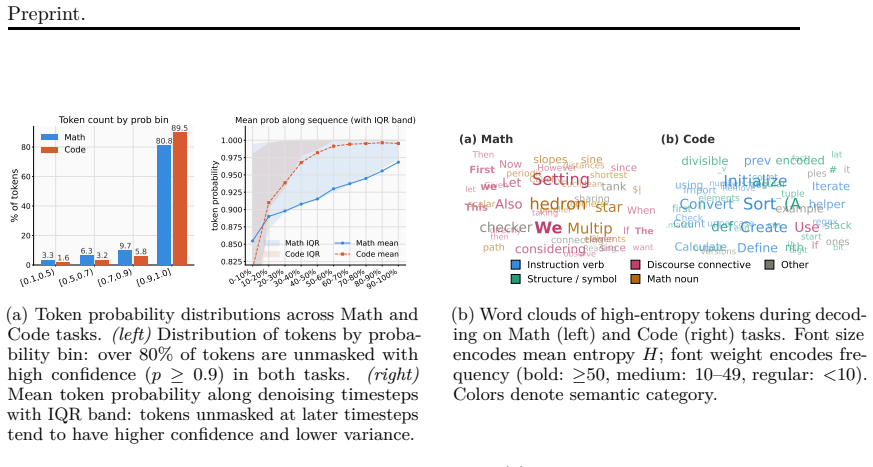
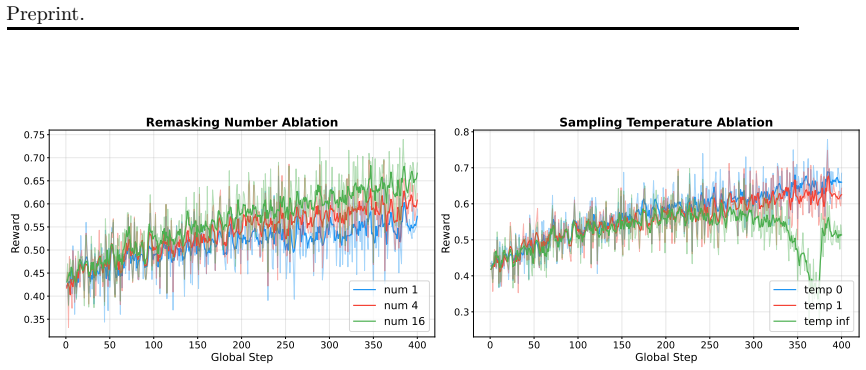
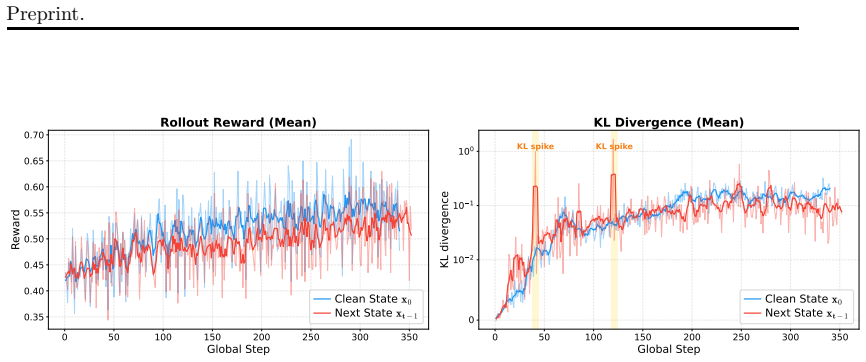
Policy loss estimation remains a fundamental and long-standing challenge in reinforcement learning (RL) for diffusion language models (DLMs). We introduce Reinforcement Learning from Denoising Feedback (RLDF), a novel training paradigm that leverages feedback obtained from rollout and training processes to facilitate accurate and efficient policy loss estimation. To balance the trade-off between computational efficiency and estimation effectiveness, RLDF optimizes the model toward the clipped clean state from intermediate noisy states, combined with weighted timestep sampling over denoising timesteps. Extensive experiments demonstrate that RLDF achieves consistent and substantial improvements in both performance and generalizability across two representative DLM architectures, LLaDA and Dream, on multiple reasoning benchmarks. Our work lays a principled foundation for scalable reinforcement learning in diffusion language models. We build Drift, a training framework for DLMs, available at https://github.com/ant-research/Drift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reinforcement Learning from Denoising Feedback (RLDF), a training paradigm for diffusion language models (DLMs) that uses feedback from rollout and training processes to estimate policy loss. The method optimizes toward clipped clean-state targets from intermediate noisy states and employs weighted timestep sampling over denoising timesteps to balance efficiency and unbiased estimation. Experiments across LLaDA and Dream architectures report consistent gains on multiple reasoning benchmarks, with the Drift training framework released as open source.
Significance. If the reported gains hold under the provided controls, RLDF offers a practical solution to the policy-loss estimation problem in DLMs, supported by explicit loss derivations and ablations on clipping and sampling that address potential bias. The open-source release of Drift is a clear strength that enables direct reproduction and extension.
major comments (2)
- [§3.2, Eq. (7)] §3.2, Eq. (7): the unbiasedness claim for the weighted timestep estimator is derived under an independence assumption between denoising steps; the manuscript should explicitly state whether this holds for the sequence lengths used in the reasoning benchmarks or provide a counter-example test.
- [Table 2] Table 2, LLaDA rows: the absolute gains over the strongest baseline are 4–7 points, yet no standard deviations or number of random seeds are reported; this weakens the claim of 'consistent' improvements without a statistical test.
minor comments (3)
- [§4.1] §4.1: the description of the two DLM architectures would benefit from a short paragraph contrasting their denoising schedules before the experimental results.
- [Figure 3] Figure 3: the y-axis label 'Policy Loss' should specify whether it is the estimated or ground-truth quantity.
- [Abstract] The abstract states 'substantial improvements' without any numeric values or baseline names; moving one or two key numbers from Table 2 into the abstract would improve readability.
Simulated Author's Rebuttal
We sincerely thank the referee for their positive assessment and constructive feedback, which has helped us identify areas for clarification. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2, Eq. (7)] the unbiasedness claim for the weighted timestep estimator is derived under an independence assumption between denoising steps; the manuscript should explicitly state whether this holds for the sequence lengths used in the reasoning benchmarks or provide a counter-example test.
Authors: We thank the referee for highlighting this aspect of the derivation. Equation (7) establishes unbiasedness of the weighted timestep estimator under an independence assumption across denoising steps. For the sequence lengths (up to 512 tokens) in our reasoning benchmarks, this is an approximation rather than a strict property. Our ablations on sampling weights nevertheless show that the estimator produces reliable gradients and consistent gains. In the revision we will explicitly note the independence assumption in §3.2, state that it is an approximation for finite sequences, and reference the empirical evidence from our experiments that the estimator remains effective in practice. revision: yes
-
Referee: Table 2, LLaDA rows: the absolute gains over the strongest baseline are 4–7 points, yet no standard deviations or number of random seeds are reported; this weakens the claim of 'consistent' improvements without a statistical test.
Authors: We agree that variability statistics would strengthen the presentation. The LLaDA results in Table 2 were obtained from three independent random seeds, with the reported gains holding across all seeds. We will revise Table 2 to include standard deviations, add the number of seeds to the experimental setup section, and note that the improvements were consistent across runs. This addresses the concern about statistical support for the 'consistent' claim. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The manuscript introduces RLDF as a training paradigm for diffusion language models, specifying algorithmic components (clipped clean-state targets, weighted timestep sampling) and reporting performance gains on LLaDA and Dream architectures across reasoning benchmarks. No load-bearing derivation, loss formula, or uniqueness claim reduces by construction to a fitted parameter or self-citation chain; the central results are falsifiable empirical measurements rather than algebraic identities. The provided abstract and skeptic analysis confirm absence of self-definitional or fitted-input patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Art of Problem Solving
URL https: //www.anthropic.com/claude-3-7-sonnet-system-card. Art of Problem Solving. AMC 2023 problems. https://artofproblemsolving.com/wiki/index. php/AMC_Problems_and_Solutions,
2023
-
[2]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg
Accessed: 2026-05-19. Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993,
2026
-
[3]
Training Verifiers to Solve Math Word Problems
13 Preprint. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
What makes diffusion language models super data learners?arXiv preprint arXiv:2510.04071,
Zitian Gao, Haoming Luo, Lynx Chen, Jason Klein Liu, Ran Tao, Joey Zhou, and Bryan Dai. What makes diffusion language models super data learners?arXiv preprint arXiv:2510.04071,
-
[6]
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639,
-
[7]
Ishaan Gulrajani and Tatsunori B Hashimoto
Accessed: 2026-04-27. Ishaan Gulrajani and Tatsunori B Hashimoto. Likelihood-based diffusion language models.Advances in Neural Information Processing Systems, 36:16693–16715,
2026
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qi He, Cheng Qian, Xiusi Chen, Bingxiang He, Yi R Fung, and Heng Ji. Veri-r1: Toward precise and faithful claim verification via online reinforcement learning.arXiv preprint arXiv:2510.01932,
-
[10]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Zemin Huang, Zhiyang Chen, Zijun Wang, Tiancheng Li, and Guo-Jun Qi. Reinforcing the diffusion chain of lateral thought with diffusion language models.arXiv preprint arXiv:2505.10446,
-
[12]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276,
Jinjie Ni, Qian Liu, Longxu Dou, Chao Du, Zili Wang, Hang Yan, Tianyu Pang, and Michael Qizhe Shieh. Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276,
-
[14]
The Flexibility Trap: Rethinking the Value of Arbitrary Order in Diffusion Language Models
Zanlin Ni, Shenzhi Wang, Yang Yue, Tianyu Yu, Weilin Zhao, Yeguo Hua, Tianyi Chen, Jun Song, Cheng Yu, Bo Zheng, et al. The flexibility trap: Why arbitrary order limits reasoning potential in diffusion language models.arXiv preprint arXiv:2601.15165,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jianwen Xie, Stefano Ermon, Yi Wu, and Chongxuan Li. Principled rl for diffusion llms emerges from a sequence-level perspective.arXiv preprint arXiv:2512.03759,
-
[17]
Diffusion beats autoregressive in data-constrained settings.arXiv preprint arXiv:2507.15857,
Mihir Prabhudesai, Mengning Wu, Amir Zadeh, Katerina Fragkiadaki, and Deepak Pathak. Diffusion beats autoregressive in data-constrained settings.arXiv preprint arXiv:2507.15857,
-
[18]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T¨ ur, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proximal Policy Optimization Algorithms
Blog post. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
15 Preprint. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Execution-based code generation using deep reinforcement learning.arXiv preprint arXiv:2301.13816,
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K Reddy. Execution-based code generation using deep reinforcement learning.arXiv preprint arXiv:2301.13816,
-
[22]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838,
-
[25]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025a. Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutioniz...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a. Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration ...
-
[29]
16 Preprint. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Beyond autoregression: Discrete diffusion for complex reasoning and planning.arXiv preprint arXiv:2410.14157, 2024a. Jiacheng Ye, Shansan Gong, Liheng Chen, Lin Zheng, Jiahui Gao, Han Shi, Chuan Wu, Xin Jiang, Zhenguo Li, Wei Bi, et al. Diffusion of thought: Chain-...
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025a. Runpeng Yu, Qi Li, and Xinchao Wang. Discrete diffusion in large language and multimodal models: A survey.arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216,
-
[33]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.