Efficient Benchmarking Is Just Feature Selection and Multiple Regression
Pith reviewed 2026-06-29 20:18 UTC · model grok-4.3
The pith
Reframing efficient benchmarking as feature selection plus kernel ridge regression yields lower prediction errors and stronger rank correlations for LLM scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
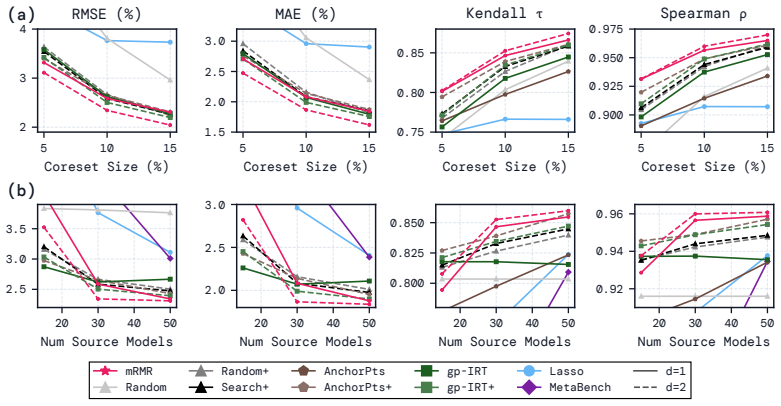
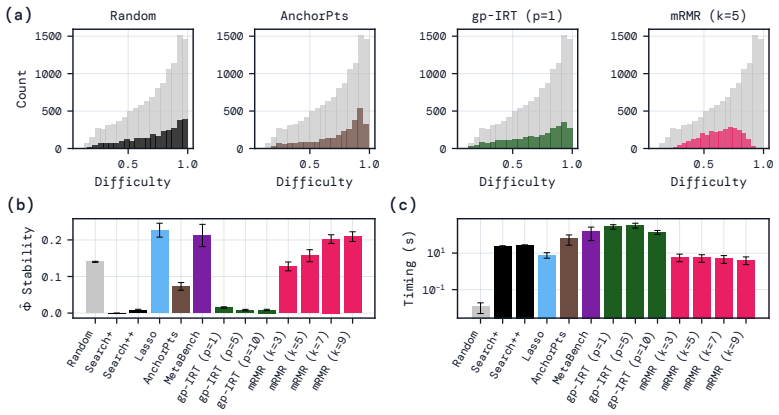
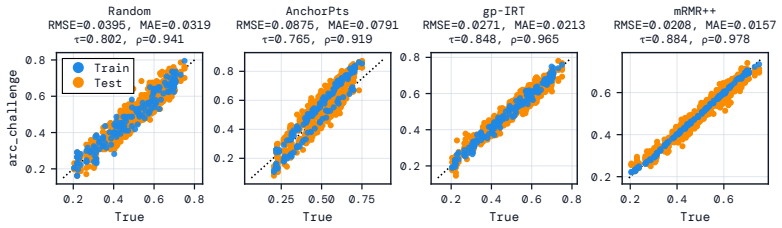
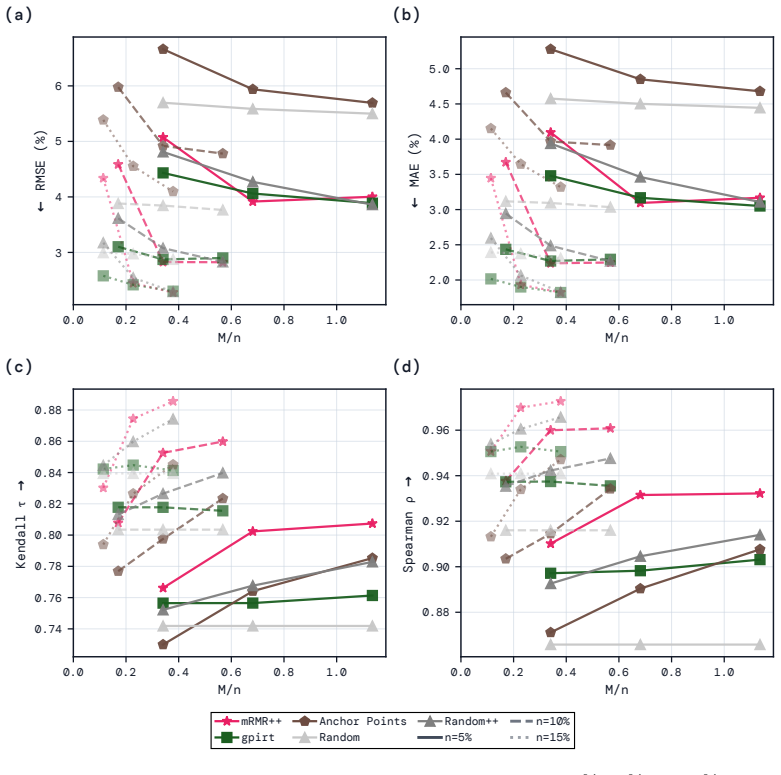
By casting efficient benchmarking as multiple regression with feature selection, kernel ridge regression at the prediction stage combined with mRMR for selecting question subsets consistently produces smaller errors in mean absolute and root mean squared terms, and stronger Spearman and Kendall rank correlations between predicted and actual scores than prior methods, while being computationally faster and more stable across different data splits.
What carries the argument
minimum redundancy maximum relevance (mRMR) feature selection paired with kernel ridge regression for predicting full benchmark scores from a chosen subset of questions
Load-bearing premise
That performance on a small, selected subset of benchmark questions is sufficiently predictive of performance on the full set via a kernel ridge regression model, without the subset choice or model introducing systematic bias across models or benchmarks.
What would settle it
Running the mRMR-plus-kernel-ridge method on a fresh benchmark and model collection and finding that its MAE, RMSE, Spearman ho, or Kendall au values are worse than those from existing efficient benchmarking techniques.
Figures




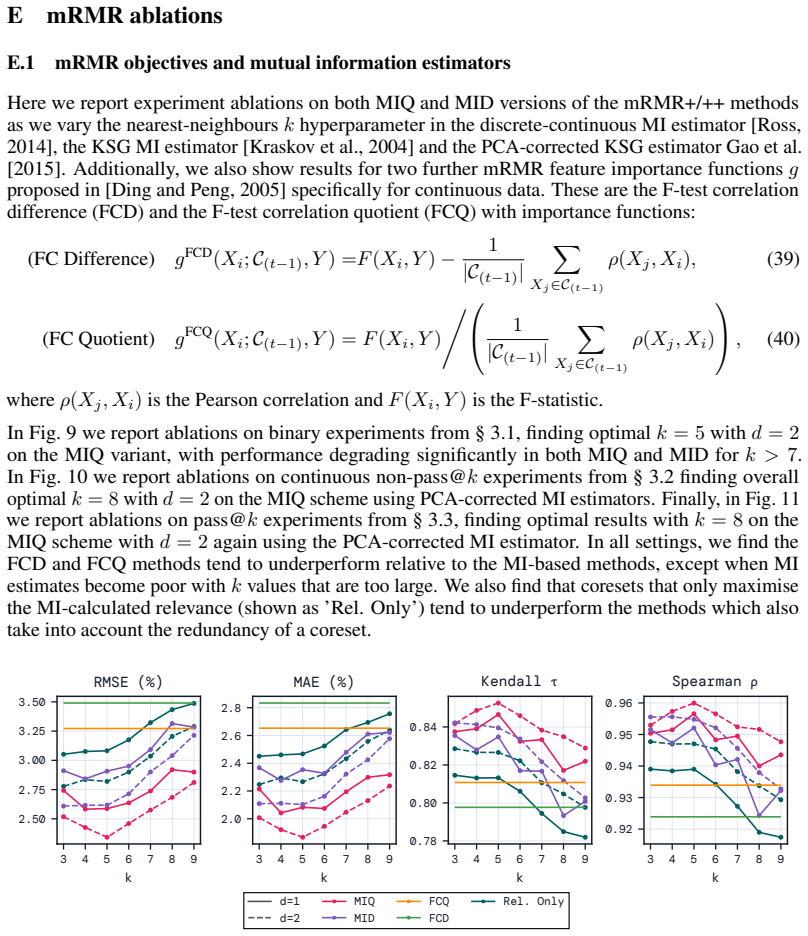






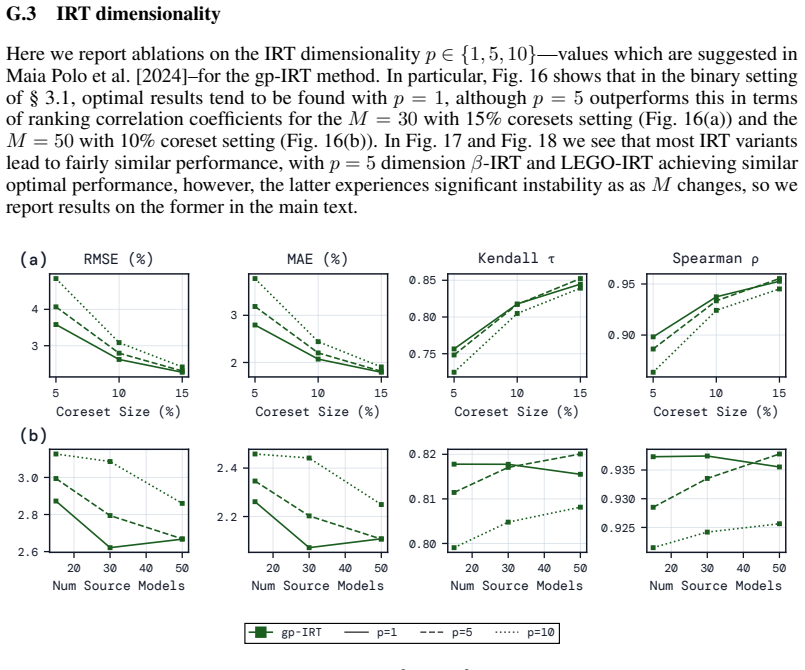



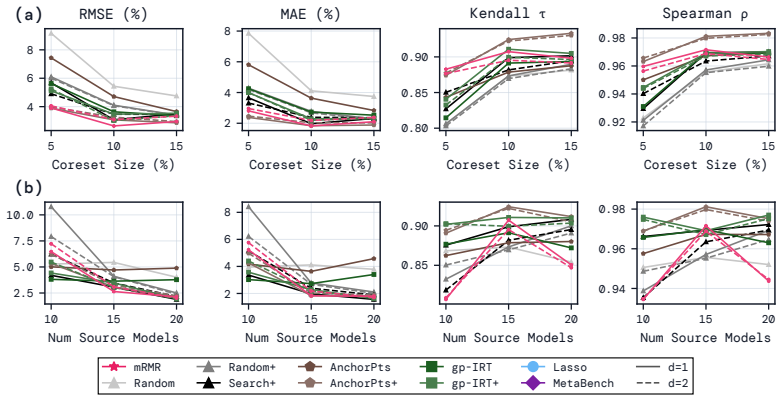

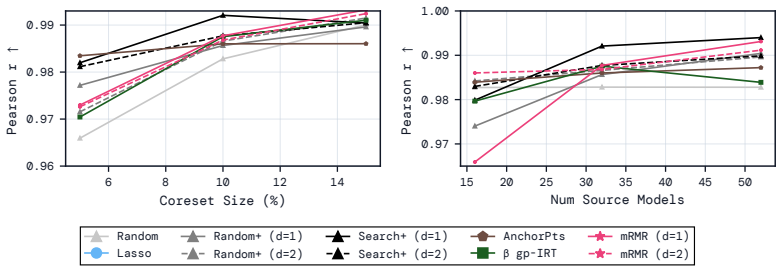
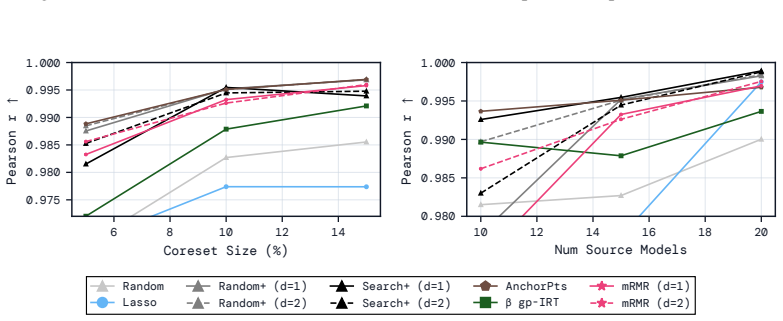
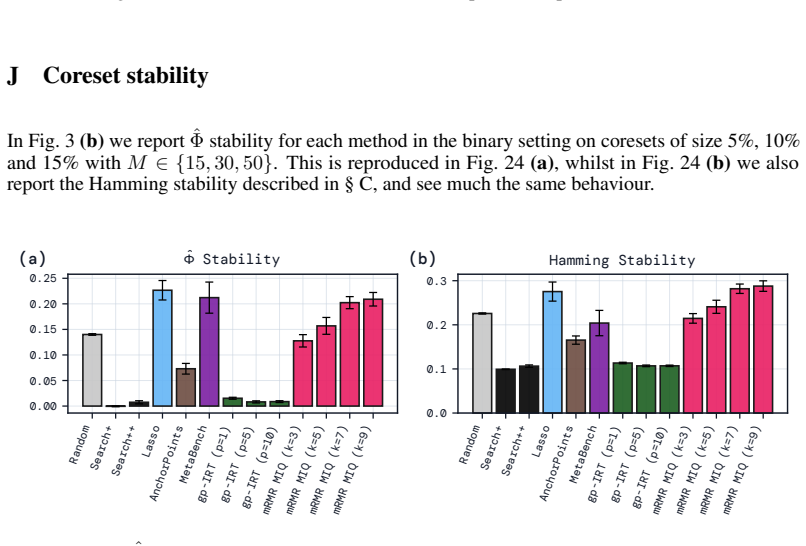
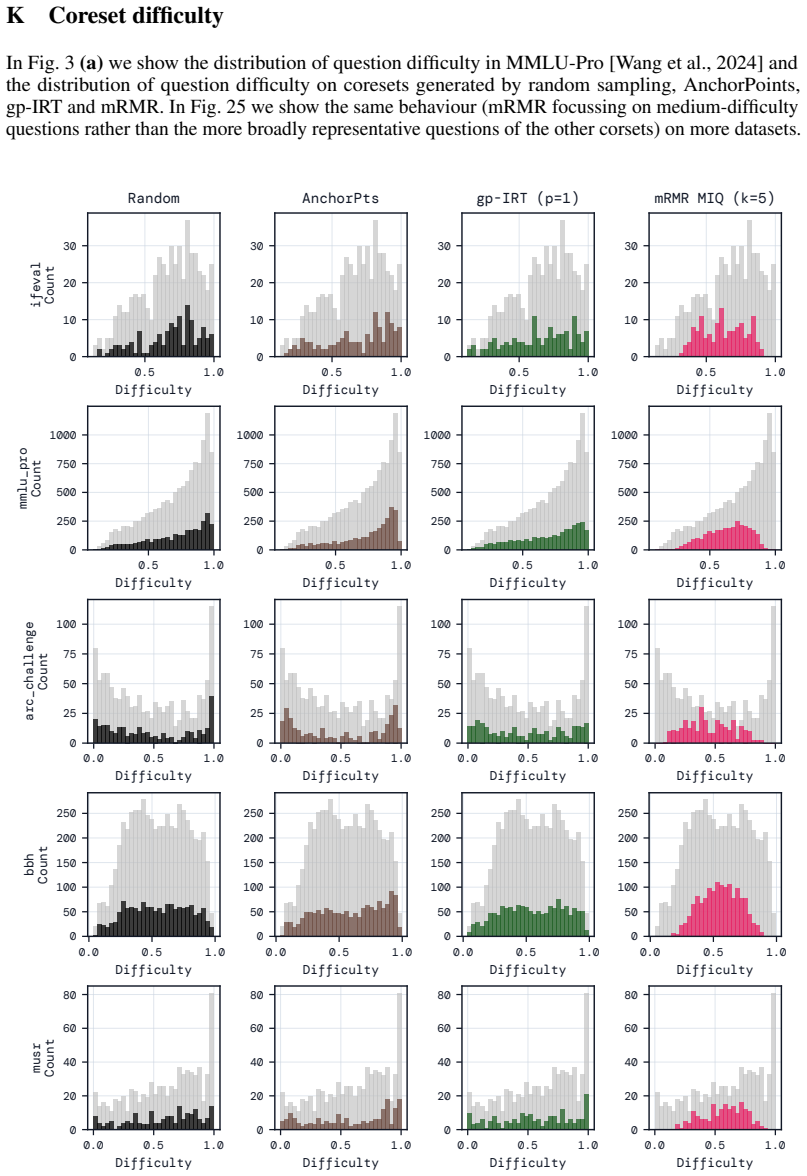


read the original abstract
Efficient benchmarking techniques aim to lower the computational cost of evaluating LLMs by predicting full benchmark scores using only a subset of a benchmark's questions. By reframing this problem as an instance of multiple regression with feature selection, we find that existing efficient benchmarking methods can be greatly improved by simply using kernel ridge regression at the prediction stage. Additionally, using an information-theoretic feature-selection algorithm called minimum redundancy maximum relevance (mRMR), we can further improve upon these methods by selecting question subsets that will be maximally useful for prediction. Except in very data-poor settings, these approaches consistently achieve smaller prediction errors (in both MAE and RMSE), and greater ranking correlation between predicted and true scores (in both Spearman $\rho$ and Kendall $\tau$) across a range of benchmarks using both binary and continuous metrics. Furthermore, mRMR subsampling is much faster than competitor methods (which often involve fitting probabilistic models or running clustering algorithms), and is more likely to select the same questions under different random seeds or training data splits. Tutorial code can be found at https://github.com/sambowyer/mrmr_eval .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reframes efficient LLM benchmarking as a multiple regression task with feature selection. It claims that replacing existing predictors with kernel ridge regression (KRR) and using minimum redundancy maximum relevance (mRMR) to select question subsets yields lower MAE and RMSE, higher Spearman ρ and Kendall τ, faster computation, and greater stability across seeds and splits than prior methods, except in very data-poor regimes. Tutorial code is provided.
Significance. If the empirical claims hold under proper controls, the work supplies a simple, computationally lightweight alternative to clustering or probabilistic-model-based subsampling for efficient benchmarking. The emphasis on reproducibility via public code is a strength.
major comments (2)
- [Experimental evaluation (implicit in abstract claims)] The central claim that mRMR-selected subsets plus KRR produce unbiased predictions for models outside the training distribution is load-bearing. The abstract and methods description give no indication that experiments were stratified by model family, architecture, or training corpus; mRMR relevance scores are computed from full-benchmark scores of the training models, so any architecture-correlated question difficulty can be absorbed by the kernel and produce systematic over- or under-prediction on unseen families. Without such a split, the reported improvements cannot be taken as general.
- [Results and discussion] The statement that improvements hold 'except in very data-poor settings' is not accompanied by a concrete definition of that regime or by ablation tables showing the transition point. This boundary is central to the practical recommendation yet remains unquantified.
minor comments (2)
- [Abstract] The abstract asserts consistent gains in four metrics but supplies no dataset sizes, number of models, error bars, or baseline descriptions; these details must appear in the main text with explicit controls for post-hoc model selection.
- [Methods] Notation for the regression target (full-benchmark score) and the feature matrix (question-level scores) should be introduced once and used consistently; the current description leaves the precise mapping from binary/continuous metrics to the regression problem implicit.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in experimental controls and result quantification. We respond to each below and commit to revisions that directly address the concerns.
read point-by-point responses
-
Referee: [Experimental evaluation (implicit in abstract claims)] The central claim that mRMR-selected subsets plus KRR produce unbiased predictions for models outside the training distribution is load-bearing. The abstract and methods description give no indication that experiments were stratified by model family, architecture, or training corpus; mRMR relevance scores are computed from full-benchmark scores of the training models, so any architecture-correlated question difficulty can be absorbed by the kernel and produce systematic over- or under-prediction on unseen families. Without such a split, the reported improvements cannot be taken as general.
Authors: We agree that the absence of explicit family- or architecture-stratified hold-outs limits the strength of claims about generalization to entirely unseen model distributions. Our model pool is diverse, but relevance scores and kernels were fit without such separation. In revision we will add a new set of experiments that hold out entire model families (e.g., all Llama variants, all Mistral variants) during both mRMR selection and KRR training, then report MAE, RMSE, Spearman ρ and Kendall τ on the held-out families. We will also discuss the scope of the current results as applying within the observed model distribution. revision: yes
-
Referee: [Results and discussion] The statement that improvements hold 'except in very data-poor settings' is not accompanied by a concrete definition of that regime or by ablation tables showing the transition point. This boundary is central to the practical recommendation yet remains unquantified.
Authors: We accept that the qualifier 'very data-poor settings' is imprecise and unsupported by quantitative thresholds or ablations. In the revised manuscript we will (i) define the regime explicitly (training sets of fewer than 30 models for the largest benchmarks, scaled proportionally for smaller ones), (ii) add ablation tables that vary the number of training models from 10 to the full set while holding the question subset fixed, and (iii) mark the point at which the proposed KRR+mRMR method ceases to outperform the baselines in each metric. revision: yes
Circularity Check
Standard regression pipeline with independent empirical validation
full rationale
The paper reframes efficient benchmarking as multiple regression plus feature selection and reports that KRR + mRMR yields lower MAE/RMSE and higher Spearman/Kendall correlations than prior methods across benchmarks. All performance numbers are obtained from explicit train/test splits on held-out model scores; the reported improvements are therefore measured quantities, not quantities forced by the fitting procedure itself. No equations equate a claimed prediction to its own training targets by construction, no uniqueness theorem is imported from self-citation, and the mRMR step is a standard information-theoretic algorithm whose output is not presupposed by the evaluation metrics. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag : Can a Machine Really Finish Your Sentence ? In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 4791--4800, Florence, Italy, July 2019. Association for Computational Ling...
-
[2]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding . In International Conference on Learning Representations , 2021 a . URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[4]
Manning, Christopher Re, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Re, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
2023
-
[5]
Open LLM Leaderboard v2, 2024
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open LLM Leaderboard v2, 2024. URL https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
2024
-
[6]
Anchor points: Benchmarking models with much fewer examples
Rajan Vivek, Kawin Ethayarajh, Diyi Yang, and Douwe Kiela. Anchor points: Benchmarking models with much fewer examples. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 1576--1601, 2024. URL https://aclanthology.org/anthology-files/pdf/eacl/2024.eacl-long.95.pdf
2024
-
[7]
tinyBenchmarks : evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinyBenchmarks : evaluating LLMs with fewer examples. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning , vol...
2024
-
[8]
Schulze Buschoff, and Eric Schulz
Alex Kipnis, Konstantinos Voudouris, Luca M. Schulze Buschoff, and Eric Schulz. metabench - A Sparse Benchmark of Reasoning and Knowledge in Large Language Models . In The Thirteenth International Conference on Learning Representations , 2025. URL https://openreview.net/forum?id=4T33izzFpK
2025
-
[9]
Confident Rankings with Fewer Items : Adaptive LLM Evaluation with Continuous Scores , 2026
Esma Balkır, Alice Pernthaller, Marco Basaldella, José Hernández-Orallo, and Nigel Collier. Confident Rankings with Fewer Items : Adaptive LLM Evaluation with Continuous Scores , 2026. URL https://arxiv.org/pdf/2601.13885
arXiv 2026
-
[10]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE -bench: Can Language Models Resolve Real -world Github Issues ? In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[11]
Yiran Zhang, Mo Wang, Xiaoyang Li, Kaixuan Ren, Chencheng Zhu, and Usman Naseem. TurnBench - MS : A Benchmark for Evaluating Multi - Turn , Multi - Step Reasoning in Large Language Models . In Findings of the Association for Computational Linguistics : EMNLP 2025 , pages 19892--19924, 2025 a . doi:10.18653/v1/2025.findings-emnlp.1084. URL http://arxiv.org...
-
[12]
Chain-of- Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of- Thought Prompting Elicits Reasoning in Large Language Models . In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems , volume 35, pages 24824--24837. Curran A...
2022
-
[13]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The Curious Case of Neural Text Degeneration . In International Conference on Learning Representations , 2020. URL https://openreview.net/forum?id=rygGQyrFvH
2020
-
[14]
The Effect of Sampling Temperature on Problem Solving in Large Language Models
Matthew Renze. The Effect of Sampling Temperature on Problem Solving in Large Language Models . In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics : EMNLP 2024 , pages 7346--7356, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.finding...
-
[15]
Roush, Andreas Kirsch, and Ravid Shwartz-Ziv
Nguyen Nhat Minh, Andrew Baker, Clement Neo, Allen G. Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning Up the Heat : Min -p Sampling for Creative and Coherent LLM Outputs . In The Thirteenth International Conference on Learning Representations , 2025. URL https://openreview.net/forum?id=FBkpCyujtS
2025
-
[16]
Quantifying Language Models ' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying Language Models ' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=RIu5lyNXjT
2024
-
[17]
Bell, Anaelia Ovalle, Jesse Dodge, Antoine Bosselut, Koustuv Sinha, and Adina Williams
Angelika Romanou, Mark Ibrahim, Candace Ross, Chantal Shaib, Kerem Oktar, Samuel J. Bell, Anaelia Ovalle, Jesse Dodge, Antoine Bosselut, Koustuv Sinha, and Adina Williams. Brittlebench: Quantifying LLM robustness via prompt sensitivity, April 2026. URL http://arxiv.org/abs/2603.13285. arXiv:2603.13285 [cs]
Pith/arXiv arXiv 2026
-
[18]
Language Models are Few - Shot Learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
1901
-
[19]
Analysis and comparison of feature selection methods towards performance and stability
Matheus Cezimbra Barbieri, Bruno Iochins Grisci, and Márcio Dorn. Analysis and comparison of feature selection methods towards performance and stability. Expert Systems with Applications, 249: 0 123667, 2024. ISSN 0957-4174. doi:https://doi.org/10.1016/j.eswa.2024.123667. URL https://www.sciencedirect.com/science/article/pii/S0957417424005335
-
[20]
Dipti Theng and Kishor K. Bhoyar. Feature selection techniques for machine learning: a survey of more than two decades of research. Knowledge and Information Systems, 66 0 (3): 0 1575--1637, March 2024. ISSN 0219-3116. doi:10.1007/s10115-023-02010-5. URL https://doi.org/10.1007/s10115-023-02010-5
-
[21]
Hanchuan Peng, Fuhui Long, and C. Ding. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27 0 (8): 0 1226--1238, 2005. doi:10.1109/TPAMI.2005.159
-
[22]
Minimum Redundancy Feature Selection From Microarray Gene Expression Data
Chris Ding and Hanchuan Peng. Minimum Redundancy Feature Selection From Microarray Gene Expression Data . Journal of Bioinformatics and Computational Biology, 03 0 (02): 0 185--205, 2005. doi:10.1142/S0219720005001004. URL https://doi.org/10.1142/S0219720005001004
-
[23]
Zhenyu Zhao, Radhika Anand, and Mallory Wang. Maximum Relevance and Minimum Redundancy Feature Selection Methods for a Marketing Machine Learning Platform . In 2019 IEEE International Conference on Data Science and Advanced Analytics ( DSAA ) , pages 442--452, 2019. doi:10.1109/DSAA.2019.00059
-
[24]
Arthur E. Hoerl and Robert W. Kennard. Ridge Regression : Biased Estimation for Nonorthogonal Problems . Technometrics, 12 0 (1): 0 55--67, 1970. doi:10.1080/00401706.1970.10488634. URL https://doi.org/10.1080/00401706.1970.10488634
-
[25]
Ridge Regression Learning Algorithm in Dual Variables
Craig Saunders, Alexander Gammerman, and Volodya Vovk. Ridge Regression Learning Algorithm in Dual Variables . In Proceedings of the Fifteenth International Conference on Machine Learning , ICML '98, pages 515--521, San Francisco, CA, USA, 1998. Morgan Kaufmann Publishers Inc. ISBN 1558605568
1998
-
[26]
The Elements of Statistical Learning
Trevor Hastie, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning . Springer Series in Statistics . Springer New York Inc., New York, NY, USA, 2001
2001
-
[27]
Chin-Yew Lin and Franz Josef Och. Automatic Evaluation of Machine Translation Quality Using Longest Common Subsequence and Skip - Bigram Statistics . In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics ( ACL -04) , pages 605--612, Barcelona, Spain, July 2004. doi:10.3115/1218955.1219032. URL https://aclanthology.org/...
-
[28]
Brian B. Moser, Arundhati S. Shanbhag, Stanislav Frolov, Federico Raue, Joachim Folz, and Andreas Dengel. A Coreset Selection of Coreset Selection Literature : Introduction and Recent Advances , January 2026. URL http://arxiv.org/abs/2505.17799. arXiv:2505.17799 [cs]
arXiv 2026
-
[29]
NP -completeness of searches for smallest possible feature sets
Scott Davies and Stuart Russell. NP -completeness of searches for smallest possible feature sets. In AAAI Symposium on Intelligent Relevance , pages 37--39. AAAI Press Menlo Park, 1994
1994
-
[30]
Brian C. Ross. Mutual Information between Discrete and Continuous Data Sets . PLOS ONE, 9 0 (2): 0 1--5, February 2014. doi:10.1371/journal.pone.0087357. URL https://doi.org/10.1371/journal.pone.0087357
-
[31]
Alexander Kraskov, Harald Stögbauer, and Peter Grassberger. Estimating mutual information. Phys. Rev. E, 69 0 (6): 0 066138, June 2004. doi:10.1103/PhysRevE.69.066138. URL https://link.aps.org/doi/10.1103/PhysRevE.69.066138
-
[32]
Efficient Estimation of Mutual Information for Strongly Dependent Variables
Shuyang Gao, Greg Ver Steeg, and Aram Galstyan. Efficient Estimation of Mutual Information for Strongly Dependent Variables . In Guy Lebanon and S. V. N. Vishwanathan, editors, Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics , volume 38 of Proceedings of Machine Learning Research , pages 277--286, San Diego...
2015
-
[33]
Ildiko E. Frank and Jerome H. Friedman. A Statistical View of Some Chemometrics Regression Tools . Technometrics, 35 0 (2): 0 109--135, 1993. ISSN 00401706. URL http://www.jstor.org/stable/1269656
arXiv 1993
-
[34]
Ridge Regularization : An Essential Concept in Data Science
Trevor Hastie. Ridge Regularization : An Essential Concept in Data Science . Technometrics, 62 0 (4): 0 426--433, October 2020. ISSN 0040-1706, 1537-2723. doi:10.1080/00401706.2020.1791959. URL https://www.tandfonline.com/doi/full/10.1080/00401706.2020.1791959
-
[35]
Bernhard E. Boser, Isabelle M. Guyon, and Vladimir N. Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory , COLT '92, pages 144--152, New York, NY, USA, 1992. Association for Computing Machinery. ISBN 089791497X. doi:10.1145/130385.130401. URL https://doi.org/10.1145/130...
-
[36]
Regression Shrinkage and Selection Via the Lasso
Robert Tibshirani. Regression Shrinkage and Selection Via the Lasso . Journal of the Royal Statistical Society: Series B (Methodological), 58 0 (1): 0 267--288, January 1996. ISSN 0035-9246. doi:10.1111/j.2517-6161.1996.tb02080.x. URL https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
-
[37]
Lord, M.R
F.M. Lord, M.R. Novick, and Allan Birnbaum. Statistical theories of mental test scores. Statistical theories of mental test scores. Addison-Wesley, Oxford, England, 1968
1968
-
[38]
Item response theory: Parameter estimation techniques
Frank B Baker and Seock-Ho Kim. Item response theory: Parameter estimation techniques . CRC press, 2004. URL https://www.ime.unicamp.br/ cnaber/Baker_Book.pdf
2004
-
[39]
Wim J. Van Der Linden. Handbook of Item Response Theory , Three Volume Set . Chapman and Hall/CRC, Boca Raton, FL : CRC Press, 2015-, 1 edition, February 2018. ISBN 9781315119144. doi:10.1201/9781315119144. URL https://www.taylorfrancis.com/books/9781315119144
-
[40]
Building an Evaluation Scale using Item Response Theory
John P Lalor, Hao Wu, and Hong Yu. Building an Evaluation Scale using Item Response Theory . Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, 2016: 0 648--657, November 2016. doi:10.18653/v1/d16-1062. URL https://europepmc.org/articles/PMC5167538
-
[41]
Clustering Examples in Multi - Dataset Benchmarks with Item Response Theory
Pedro Rodriguez, Phu Mon Htut, John Lalor, and João Sedoc. Clustering Examples in Multi - Dataset Benchmarks with Item Response Theory . In Shabnam Tafreshi, João Sedoc, Anna Rogers, Aleksandr Drozd, Anna Rumshisky, and Arjun Akula, editors, Proceedings of the Third Workshop on Insights from Negative Results in NLP , pages 100--112, Dublin, Ireland, May 2...
-
[42]
What Does Your Benchmark Really Measure ? A Framework for Robust Inference of AI Capabilities , 2025
Nathanael Jo and Ashia Wilson. What Does Your Benchmark Really Measure ? A Framework for Robust Inference of AI Capabilities , 2025. URL https://arxiv.org/pdf/2509.19590
Pith/arXiv arXiv 2025
-
[43]
Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pontus Stenetorp, Sharan Narang, and Dieuwke Hupkes
Lovish Madaan, Aaditya K. Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pontus Stenetorp, Sharan Narang, and Dieuwke Hupkes. Quantifying Variance in Evaluation Benchmarks . In NeurIPS 2024 Workshop on Regulatable ML , 2025. URL https://openreview.net/forum?id=M9dCa4vYgp
2024
-
[44]
A Beta Item Response Model for Continuous Bounded Responses
Yvonnick Noel and Bruno Dauvier. A Beta Item Response Model for Continuous Bounded Responses . Applied Psychological Measurement, 31 0 (1): 0 47--73, 2007. doi:10.1177/0146621605287691. URL https://doi.org/10.1177/0146621605287691
-
[45]
Dorner, and Moritz Hardt
Guanhua Zhang, Florian E. Dorner, and Moritz Hardt. How Benchmark Prediction from Fewer Data Misses the Mark . In The Thirty -ninth Annual Conference on Neural Information Processing Systems , 2025 b . URL https://openreview.net/forum?id=o3bftqj17e
2025
-
[46]
Efficient Attentions for Long Document Summarization
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. Efficient Attentions for Long Document Summarization . In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of ...
-
[47]
Overview of the BioLaySumm 2025 Shared Task on Lay Summarization of Biomedical Research Articles and Radiology Reports
Chenghao Xiao, Kun Zhao, Xiao Wang, Siwei Wu, Sixing Yan, Tomas Goldsack, Sophia Ananiadou, Noura Al Moubayed, Liang Zhan, William Cheung, and Chenghua Lin. Overview of the BioLaySumm 2025 Shared Task on Lay Summarization of Biomedical Research Articles and Radiology Reports . In The 24th Workshop on Biomedical Natural Language Processing and BioNLP Share...
2025
-
[48]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore : Evaluating Text Generation with BERT . In International Conference on Learning Representations , 2020. URL https://openreview.net/forum?id=SkeHuCVFDr
2020
-
[49]
J. P. Kincaid, Jr. Fishburne, Rogers Robert P., Chissom Richard L., and Brad S. Derivation of New Readability Formulas ( Automated Readability Index , Fog Count and Flesch Reading Ease Formula ) for Navy Enlisted Personnel :. Technical report, Defense Technical Information Center, Fort Belvoir, VA, February 1975. URL https://apps.dtic.mil/sti/citations/tr...
1975
-
[50]
Program Synthesis with Large Language Models , August 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program Synthesis with Large Language Models , August 2021. URL http://arxiv.org/abs/2108.07732. arXiv:2108.07732 [cs]
Pith/arXiv arXiv 2021
-
[51]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is Your Code Generated by ChatGPT Really Correct ? Rigorous Evaluation of Large Language Models for Code Generation , 2023. URL https://arxiv.org/abs/2305.01210
Pith/arXiv arXiv 2023
-
[52]
On Leakage of Code Generation Evaluation Datasets
Alexandre Matton, Tom Sherborne, Dennis Aumiller, Elena Tommasone, Milad Alizadeh, Jingyi He, Raymond Ma, Maxime Voisin, Ellen Gilsenan-McMahon, and Matthias Gallé. On Leakage of Code Generation Evaluation Datasets . In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics : EMNLP 2024 , page...
- [53]
-
[54]
M. G. Kendall. A New Measure of Rank Correlation . Biometrika, 30 0 (1-2): 0 81--93, June 1938. ISSN 0006-3444. doi:10.1093/biomet/30.1-2.81. URL https://doi.org/10.1093/biomet/30.1-2.81
-
[55]
On the stability of feature selection algorithms
Sarah Nogueira, Konstantinos Sechidis, and Gavin Brown. On the stability of feature selection algorithms. Journal of Machine Learning Research, 18 0 (174): 0 1--54, 2018
2018
-
[56]
Ppi++: Efficient prediction-powered inference, 2023
Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. Ppi++: Efficient prediction-powered inference, 2023. URL https://arxiv.org/pdf/2311.01453
Pith/arXiv arXiv 2023
-
[57]
Active Evaluation Acquisition for Efficient LLM Benchmarking
Yang Li, Jie Ma, Miguel Ballesteros, Yassine Benajiba, and Graham Horwood. Active Evaluation Acquisition for Efficient LLM Benchmarking . In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Proceedings of the 42nd International Conference on Machine Learning , volume 267 o...
2025
-
[58]
Valentin Hofmann, David Heineman, Ian Magnusson, Kyle Lo, Jesse Dodge, Maarten Sap, Pang Wei Koh, Chun Wang, Hannaneh Hajishirzi, and Noah A. Smith. Fluid Language Model Benchmarking . In Second Conference on Language Modeling , 2025
2025
-
[59]
Beyond One - Size - Fits - All : Tailored Benchmarks for Efficient Evaluation
Peiwen Yuan, Yueqi Zhang, Shaoxiong Feng, Yiwei Li, Xinglin Wang, Jiayi Shi, Chuyi Tan, Boyuan Pan, Yao Hu, and Kan Li. Beyond One - Size - Fits - All : Tailored Benchmarks for Efficient Evaluation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 15591--15615, 2025. URL https://...
2025
-
[60]
Disco: Diversifying sample condensation for efficient model evaluation, 2025
Alexander Rubinstein, Benjamin Raible, Martin Gubri, and Seong Joon Oh. Disco: Diversifying sample condensation for efficient model evaluation, 2025. URL https://arxiv.org/pdf/2510.07959
arXiv 2025
-
[61]
SubLIME : Subset Selection via Rank Correlation Prediction for Data - Efficient LLM Evaluation
Gayathri Saranathan, Cong Xu, Mahammad Parwez Alam, Tarun Kumar, Martin Foltin, Soon Yee Wong, and Suparna Bhattacharya. SubLIME : Subset Selection via Rank Correlation Prediction for Data - Efficient LLM Evaluation . In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Asso...
-
[62]
Effieval: Efficient and generalizable model evaluation via capability coverage maximization, 2025
Yaoning Wang, Jiahao Ying, Yixin Cao, Yubo Ma, and Yugang Jiang. Effieval: Efficient and generalizable model evaluation via capability coverage maximization, 2025. URL https://arxiv.org/pdf/2508.09662
arXiv 2025
-
[63]
BenTo : Benchmark Task Reduction with In - Context Transferability
Hongyu Zhao, Ming Li, Lichao Sun, and Tianyi Zhou. BenTo : Benchmark Task Reduction with In - Context Transferability . In International Conference on Learning Representations ( ICLR ) , 2025. URL https://openreview.net/forum?id=4798eef078
2025
-
[64]
You Don 't Need to Run Every Eval , 2026
Dimitris Papailiopoulos. You Don 't Need to Run Every Eval , 2026. URL https://github.com/anadim/llm-benchmark-matrix
2026
-
[65]
Cheke, and José Hernández-Orallo
Lorenzo Pacchiardi, Lucy G. Cheke, and José Hernández-Orallo. 100 instances is all you need: predicting the success of a new LLM on unseen data by testing on a few instances. 2024 KDD workshop on Evaluation and Trustworthiness of Generative AI Models, 2024. URL https://arxiv.org/abs/2409.03563
arXiv 2024
-
[66]
Vilém Zouhar, Peng Cui, and Mrinmaya Sachan. How to Select Datapoints for Efficient Human Evaluation of NLG Models ? Transactions of the Association for Computational Linguistics, 13: 0 1789--1811, 2025. doi:10.1162/tacl.a.60. URL https://aclanthology.org/2025.tacl-1.80/
-
[67]
Note on Regression and Inheritance in the Case of Two Parents
Karl Pearson. Note on Regression and Inheritance in the Case of Two Parents . Proceedings of the Royal Society of London Series I, 58: 0 240--242, January 1895
-
[68]
Solutions to instability problems with sequential wrapper-based approaches to feature selection
Kevin Dunne, Padraig Cunningham, and Francisco Azuaje. Solutions to instability problems with sequential wrapper-based approaches to feature selection. Journal of Machine Learning Research, 1: 0 22, 2002
2002
-
[69]
Instruction- Following Evaluation for Large Language Models , November 2023
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction- Following Evaluation for Large Language Models , November 2023. URL http://arxiv.org/abs/2311.07911. arXiv:2311.07911 [cs]
Pith/arXiv arXiv 2023
-
[70]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring Mathematical Problem Solving With the MATH Dataset . In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track ( Round 2) , 2021 b . URL https://openreview.net/forum?id=7Bywt2mQsCe
2021
-
[71]
MMLU - Pro : A More Robust and Challenging Multi - Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU - Pro : A More Robust and Challenging Multi - Task Language Understanding Benchmark . In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paq...
-
[72]
Think you have Solved Question Answering ? Try ARC , the AI2 Reasoning Challenge , March 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have Solved Question Answering ? Try ARC , the AI2 Reasoning Challenge , March 2018. URL http://arxiv.org/abs/1803.05457. arXiv:1803.05457 [cs]
Pith/arXiv arXiv 2018
-
[73]
Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and Jason Wei. Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them . In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistic...
-
[74]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A Graduate - Level Google - Proof Q & A Benchmark . In First Conference on Language Modeling , 2024. URL https://openreview.net/forum?id=Ti67584b98
2024
-
[75]
MuSR : Testing the Limits of Chain -of-thought with Multistep Soft Reasoning
Zayne Rea Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. MuSR : Testing the Limits of Chain -of-thought with Multistep Soft Reasoning . In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=jenyYQzue1
2024
-
[76]
CommonsenseQA : A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA : A Question Answering Challenge Targeting Commonsense Knowledge . In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies , ...
-
[77]
Training Verifiers to Solve Math Word Problems , November 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems , November 2021. URL http://arxiv.org/abs/2110.14168. arXiv:2110.14168 [cs]
Pith/arXiv arXiv 2021
-
[78]
LegalBench : A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Neel Guha, Julian Nyarko, Daniel Ho, Christopher Ré, Adam Chilton, Aditya K, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan Choi, Kevin Tobia, Mar...
2023
-
[79]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What Disease Does This Patient Have ? A Large - Scale Open Domain Question Answering Dataset from Medical Exams . Applied Sciences, 11 0 (14), 2021. ISSN 2076-3417. doi:10.3390/app11146421. URL https://www.mdpi.com/2076-3417/11/14/6421
-
[80]
Toward a unified framework for data-efficient evaluation of large language models, 2025
Lele Liao, Qile Zhang, Ruofan Wu, and Guanhua Fang. Toward a unified framework for data-efficient evaluation of large language models, 2025. URL https://arxiv.org/pdf/2510.04051
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.