InterSketch: An Interleaved Reasoning Model with Self-correcting Visual Sketch and Stepwise Reward
Pith reviewed 2026-06-29 17:49 UTC · model grok-4.3
The pith
InterSketch interleaves self-correcting visual sketches with text reasoning and uses stepwise rewards for long-horizon visual tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
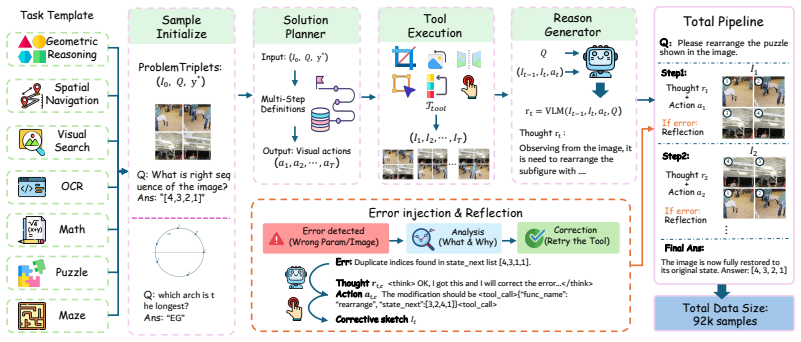
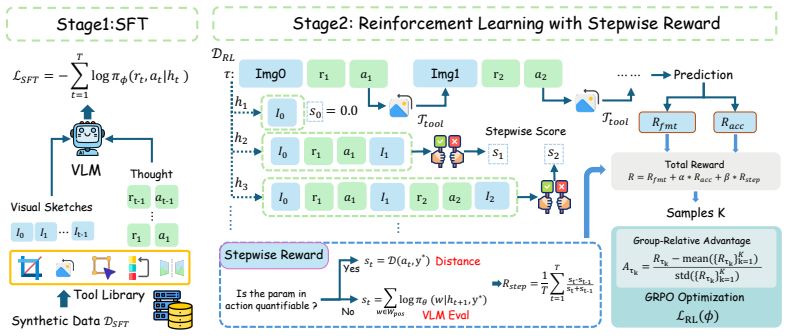
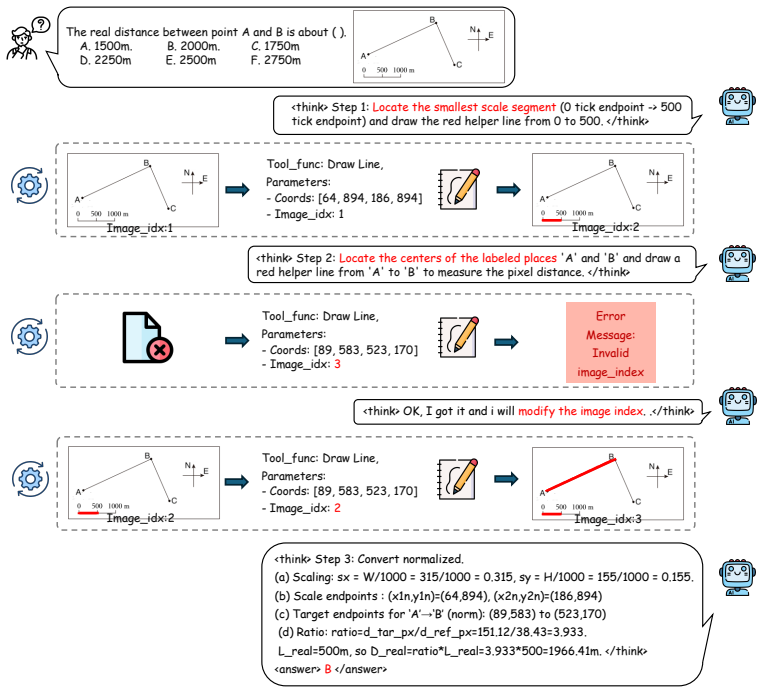
InterSketch dynamically generates intermediate visual sketches using external tools and interleaves them with textual reasoning, enabling effective perception and logical reasoning over long-horizon visual understanding tasks. It builds this via a synthesized high-quality interleaved VT-CoT dataset with reflection in a cold-start stage, then applies a stepwise reward mechanism in reinforcement learning to handle sparse end-only signals.
What carries the argument
Interleaved visual-textual chain-of-thought with self-correcting sketches generated by external tools plus stepwise reward signals during RL training.
If this is right
- Vision-language models gain the ability to maintain and revise visual perceptions across multiple reasoning turns rather than committing to a single text description.
- Stepwise rewards allow credit assignment over extended sequences where only final task success is observable.
- Self-correction via reflection reduces propagation of early perceptual errors into later logical steps.
- The approach yields measurable gains on standard visual reasoning benchmarks that surpass certain closed-source models.
Where Pith is reading between the lines
- Similar interleaving of generated intermediate representations could extend to sequential planning tasks that combine vision with action sequences.
- Reducing dependence on external sketch tools by training an internal generator might lower latency while preserving the same reasoning structure.
- The method suggests a path for hybrid systems that combine tool use with learned reasoning loops in other multimodal domains.
Load-bearing premise
A synthesized high-quality interleaved VT-CoT dataset together with a reflection mechanism suffices to bootstrap multi-turn interleaved reasoning and self-correction.
What would settle it
Training runs that omit the synthesized VT-CoT dataset or the stepwise reward component produce no gains over text-only baselines on long-horizon visual reasoning benchmarks.
Figures











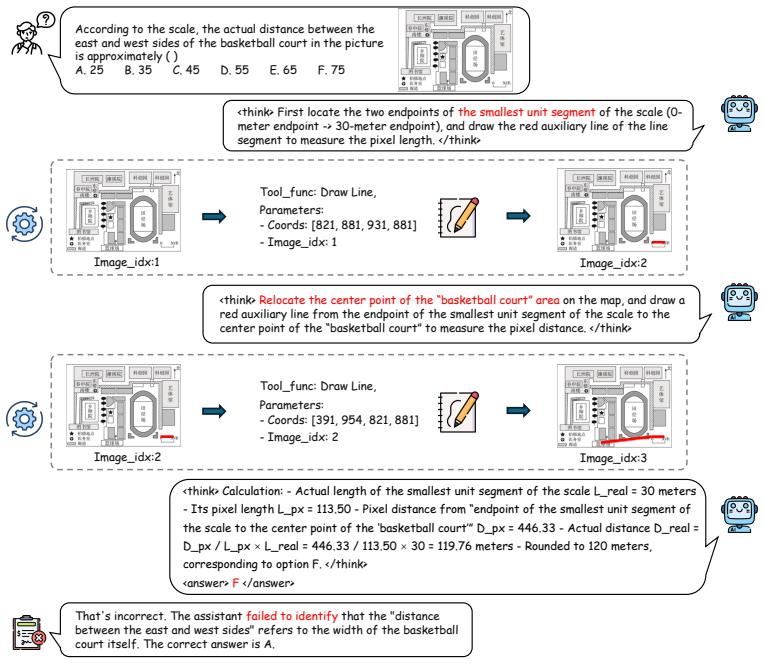
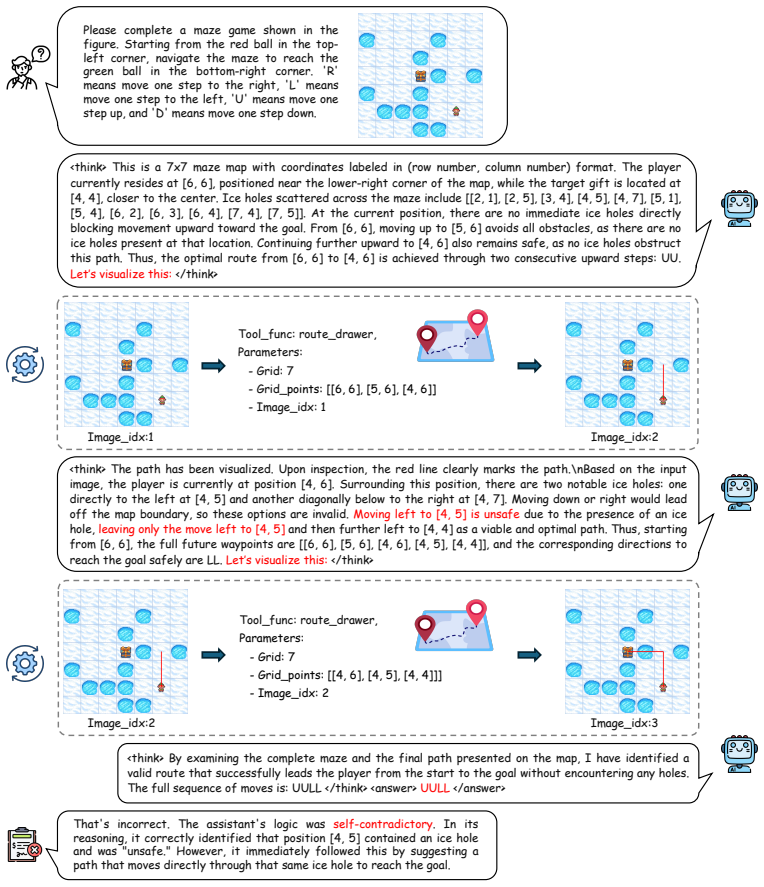
read the original abstract
While vision-language models (VLMs) have exhibited multi-turn visual reasoning capabilities, their reasoning trajectories remain relatively shallow and are dominated by a text-centric paradigm, limiting their applicability to complex visual challenges. In contrast, human-like thought typically involves long-horizon reasoning with an interleaved visual-textual chain-of-thought (VT-CoT). To bridge this gap, we introduce InterSketch, an interleaved reasoning model to enhance the VT-CoT capability via self-correcting and stepwise reward mechanisms. InterSketch dynamically generates intermediate visual sketches using external tools and interleaves them with textual reasoning, enabling effective perception and logical reasoning over long-horizon visual understanding tasks. Specifically, in the first cold-start stage, we propose a synthesized high-quality interleaved VT-CoT dataset and include a reflection mechanism to enable the model's capability in multi-turn interleaved reasoning and self-correction. In the subsequent reinforcement learning (RL) stage, we design a stepwise reward mechanism to mitigate the sparsity of reward signals inherent in end-only supervision over long-horizon reasoning. Extensive experiments on visual reasoning benchmarks demonstrate the effectiveness of InterSketch, even outperforming proprietary models such as Gemini-3-Pro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InterSketch, an interleaved reasoning model for vision-language models that enhances visual-textual chain-of-thought (VT-CoT) via self-correcting visual sketches generated dynamically with external tools and a stepwise reward in RL. It consists of a cold-start stage using a synthesized high-quality interleaved VT-CoT dataset plus reflection mechanism to bootstrap multi-turn reasoning and self-correction, followed by an RL stage with stepwise reward to address sparse end-only supervision in long-horizon tasks. The paper claims this enables effective perception and logical reasoning on complex visual challenges and reports outperformance over proprietary models such as Gemini-3-Pro on visual reasoning benchmarks.
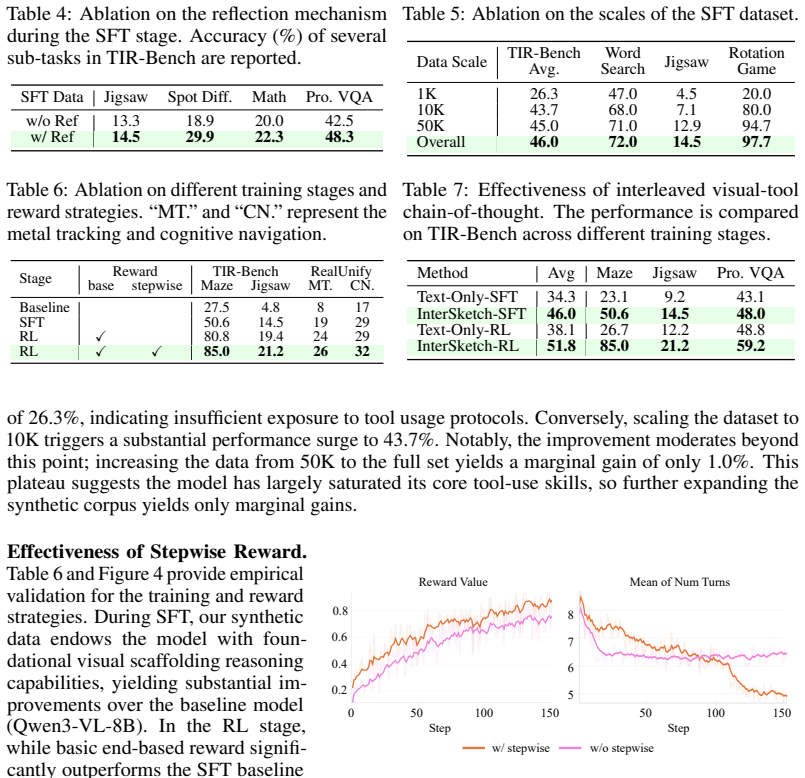
Significance. If the central claims hold after proper validation, the work could advance VLMs beyond text-centric reasoning toward more human-like interleaved VT-CoT, with the external-tool sketch generation and stepwise reward addressing key limitations in long-horizon visual tasks. The two-stage training paradigm is a clear contribution if the bootstrap and reward design are shown to be effective via ablations.
major comments (2)
- [Abstract] Abstract: the claim of outperforming Gemini-3-Pro supplies no information on dataset sizes, baseline implementations, statistical tests, error bars, or exclusion criteria, rendering it impossible to judge whether the reported results support the central claim.
- [Abstract] Cold-start stage description (Abstract): the sufficiency of the synthesized high-quality interleaved VT-CoT dataset together with the reflection mechanism for bootstrapping multi-turn interleaved reasoning and self-correction is asserted without any description of the synthesis procedure, quality filters, coverage of long-horizon cases, or ablations isolating the cold-start contribution; this is load-bearing for the subsequent RL gains and overall outperformance claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comments on the abstract below and will revise the abstract to improve the presentation of our claims and method.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of outperforming Gemini-3-Pro supplies no information on dataset sizes, baseline implementations, statistical tests, error bars, or exclusion criteria, rendering it impossible to judge whether the reported results support the central claim.
Authors: We acknowledge that the abstract, due to space constraints, does not include these evaluation details. The full manuscript reports dataset sizes in Section 4.1, baseline implementations and training details in Section 4.2, and statistical tests with error bars plus exclusion criteria in Section 5 and Appendix B. We will revise the abstract to qualify the outperformance claim and explicitly reference the main text for the full evaluation protocol. revision: yes
-
Referee: [Abstract] Cold-start stage description (Abstract): the sufficiency of the synthesized high-quality interleaved VT-CoT dataset together with the reflection mechanism for bootstrapping multi-turn interleaved reasoning and self-correction is asserted without any description of the synthesis procedure, quality filters, coverage of long-horizon cases, or ablations isolating the cold-start contribution; this is load-bearing for the subsequent RL gains and overall outperformance claim.
Authors: The synthesis procedure, quality filters, long-horizon coverage, and reflection mechanism are described in Section 3.1, while ablations isolating the cold-start stage appear in Section 5.3. We agree the abstract would benefit from a concise summary of these elements. We will revise the abstract to briefly describe the synthesis approach and note the supporting ablations. revision: yes
Circularity Check
No circularity: method uses external tools and independently synthesized dataset
full rationale
The paper presents a two-stage procedure (cold-start on a synthesized interleaved VT-CoT dataset plus reflection, followed by RL with stepwise reward) that relies on external sketch-generation tools and a separately constructed training set. No equations, fitted parameters renamed as predictions, or self-referential definitions appear. The central claims rest on the empirical performance of the resulting model rather than any derivation that reduces to its own inputs by construction. No load-bearing self-citations or uniqueness theorems imported from the authors' prior work are invoked in the supplied text.
Axiom & Free-Parameter Ledger
free parameters (1)
- stepwise reward formulation
axioms (1)
- domain assumption Synthesized interleaved VT-CoT dataset plus reflection mechanism suffices to instill multi-turn self-correction
invented entities (1)
-
stepwise reward mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Thinking with images.https://openai.com/index/thinking-with-images/, 2025
OpenAI. Thinking with images.https://openai.com/index/thinking-with-images/, 2025
2025
-
[7]
Jiawei Gu, Yunzhuo Hao, Huichen Will Wang, Linjie Li, Michael Qizhe Shieh, Yejin Choi, Ranjay Krishna, and Yu Cheng. Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning.arXiv preprint arXiv:2510.27492, 2025
-
[8]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Xin Lai, Junyi Li, Wei Li, Tao Liu, Tianjian Li, and Hengshuang Zhao. Mini-o3: Scaling up reasoning patterns and interaction turns for visual search.arXiv preprint arXiv:2509.07969, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Yang Shi, Yuhao Dong, Yue Ding, Yuran Wang, Xuanyu Zhu, Sheng Zhou, Wenting Liu, Haochen Tian, Rundong Wang, Huanqian Wang, et al. Realunify: Do unified models truly benefit from unification? a comprehensive benchmark.arXiv preprint arXiv:2509.24897, 2025
-
[12]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli ´c, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought.arXiv preprint arXiv:2501.07542, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
DeepEyesV2: Toward Agentic Multimodal Model
Jack Hong, Chenxiao Zhao, ChengLin Zhu, Weiheng Lu, Guohai Xu, and Xing Yu. Deepeyesv2: Toward agentic multimodal model.arXiv:2511.05271, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Zirun Guo, Minjie Hong, Feng Zhang, Kai Jia, and Tao Jin. Thinking with programming vision: Towards a unified view for thinking with images.arXiv preprint arXiv:2512.03746, 2025. 10
-
[15]
arXiv preprint arXiv:2512.24330 (2025)
Yong Xien Chng, Tao Hu, Wenwen Tong, Xueheng Li, Jiandong Chen, Haojia Yu, Jiefan Lu, Hewei Guo, Hanming Deng, Chengjun Xie, et al. Sensenova-mars: Empowering multimodal agentic reasoning and search via reinforcement learning.arXiv preprint arXiv:2512.24330, 2025
-
[16]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556–9567, 2024
2024
-
[17]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Qiucheng Wu, Handong Zhao, Michael Saxon, Trung Bui, William Yang Wang, Yang Zhang, and Shiyu Chang. Vsp: Assessing the dual challenges of perception and reasoning in spatial planning tasks for vlms.arXiv preprint arXiv:2407.01863, 2024
-
[19]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
2022
-
[20]
Otter: A multi-modal model with in-context instruction tuning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Joshua Adrian Cahyono, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[21]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025
Zetong Zhou, Dongping Chen, Zixian Ma, Zhihan Hu, Mingyang Fu, Sinan Wang, Yao Wan, Zhou Zhao, and Ranjay Krishna. Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Swift: a scalable lightweight infrastructure for fine-tuning
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al. Swift: a scalable lightweight infrastructure for fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 29733–29735, 2025
2025
-
[28]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In EuroSys, 2025
2025
-
[29]
Ming Li, Jike Zhong, Shitian Zhao, Haoquan Zhang, Shaoheng Lin, Yuxiang Lai, Chen Wei, Konstantinos Psounis, and Kaipeng Zhang. Tir-bench: A comprehensive benchmark for agentic thinking-with-images reasoning.arXiv preprint arXiv:2511.01833, 2025. 11
-
[30]
Uni-MMMU: A Massive Multi-discipline Multimodal Unified Benchmark
Kai Zou, Ziqi Huang, Yuhao Dong, Shulin Tian, Dian Zheng, Hongbo Liu, Jingwen He, Bin Liu, Yu Qiao, and Ziwei Liu. Uni-mmmu: A massive multi-discipline multimodal unified benchmark.arXiv preprint arXiv:2510.13759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[32]
Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
2024
-
[33]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
2024
-
[34]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Gpt-5.https://openai.com/gpt-5, 2025
OpenAI. Gpt-5.https://openai.com/gpt-5, 2025
2025
-
[36]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Gemini-3-pro.https://deepmind.google/models/gemini/pro/, 2025
Gemini. Gemini-3-pro.https://deepmind.google/models/gemini/pro/, 2025
2025
-
[38]
Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, and Klara Nahrstedt. Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use.arXiv preprint arXiv:2505.19255, 2025
-
[39]
DeepSketcher: Internalizing Visual Manipulation for Multimodal Reasoning
Chi Zhang, Haibo Qiu, Qiming Zhang, Zhixiong Zeng, Lin Ma, and Jing Zhang. Deepsketcher: Internalizing visual manipulation for multimodal reasoning.arXiv preprint arXiv:2509.25866, 2025. 12 Table 8: Comparison with previous tool-augmented visual reasoning methods. Method Avg. Tool Calls Task Diversity Multi-Step Chain Stepwise Reward Reflection OpenThinkI...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.