Prompt Injection Detection is Regime-Dependent: A Deployment-Aware Evaluation with Interpretable Structural Signals
Pith reviewed 2026-06-29 18:39 UTC · model grok-4.3
The pith
Prompt injection detection performance varies strongly by operating regime and threshold choice, with no single model best everywhere.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
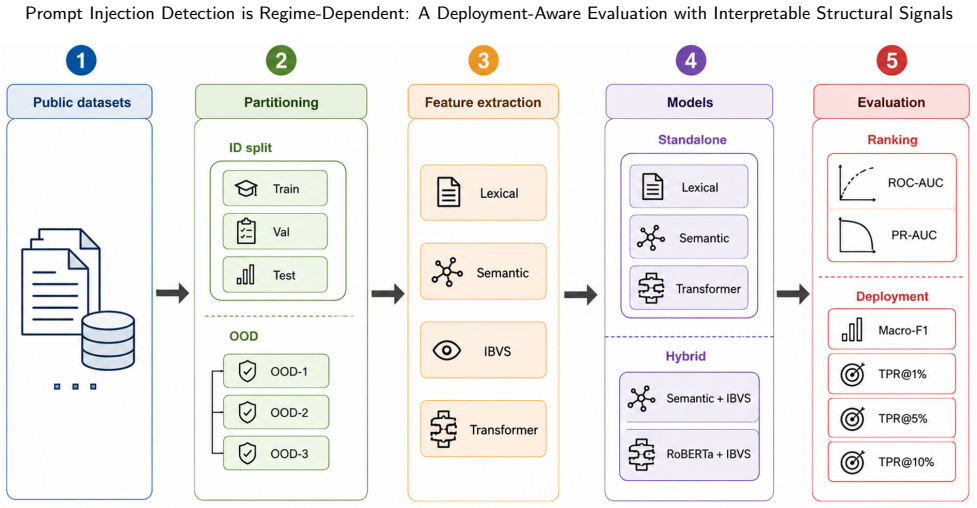
Detection performance is highly regime-dependent and sensitive to threshold selection, with no single model dominating across all settings. Transformer-based models achieve the strongest overall performance, while structural signals that capture hierarchy overrides, system prompt spoofing, role redefinition, and evasion patterns provide modest but consistent gains in certain regimes and improve low false positive rate behaviour in harder scenarios.
What carries the argument
The multi-regime experimental framework that evaluates lexical, semantic, structural, and transformer-based detectors across repeated out-of-distribution splits using both ranking and thresholded deployment metrics.
If this is right
- Transformer models should be the default starting point but still require testing in each new regime before deployment.
- Structural signals can be added to improve behaviour specifically at low false-positive rates.
- Evaluations must report thresholded metrics rather than ranking alone to reflect actual use.
- No universal detector exists, so selection must depend on the expected out-of-distribution scenario.
Where Pith is reading between the lines
- Production systems may need to maintain several detectors and route queries based on detected regime.
- The same regime-dependence pattern could appear in related tasks such as jailbreak or output filtering evaluation.
- Live traffic testing would provide a stronger check than the controlled splits used here.
Load-bearing premise
The chosen out-of-distribution settings, repeated data splits, and multi-regime framework accurately capture the real-world operating constraints and deployment scenarios for prompt injection detection.
What would settle it
An independent replication that uses the same data splits and regimes but finds one detector achieving the highest performance across every threshold and setting would falsify the regime-dependence claim.
Figures

read the original abstract
Prompt injection poses a critical threat to the safe deployment of large language models, yet existing detection approaches are typically evaluated under limited settings that do not reflect real-world operating constraints. In this work, we present a deployment-aware evaluation of prompt injection detection using a multi-model and multi-regime experimental framework. We compare lexical, semantic, structural, and transformer-based detectors across multiple out-of-distribution settings, repeated data splits, and both ranking and thresholded deployment metrics. We introduce interpretable structural signals that capture hierarchy overrides, system prompt spoofing, role redefinition, and evasion patterns, and assess their contribution both within sparse models and in combination with strong encoder baselines. Our results show that detection performance is highly regime-dependent and sensitive to threshold selection, with no single model dominating across all settings. Transformer-based models achieve the strongest overall performance, while structural signals provide modest but consistent gains in certain regimes and improve low false positive rate behaviour in harder scenarios. These findings highlight the gap between ranking performance and deployment effectiveness and underscore the importance of evaluating prompt injection defences under realistic operational constraints. Code will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a deployment-aware evaluation framework for prompt injection detection in LLMs. It compares lexical, semantic, structural, and transformer-based detectors across multiple out-of-distribution regimes, repeated data splits, and both ranking and thresholded metrics. The authors introduce interpretable structural signals capturing hierarchy overrides, system prompt spoofing, role redefinition, and evasion patterns, and evaluate their contribution alone and in combination with encoder baselines. The central empirical finding is that detection performance is highly regime-dependent and threshold-sensitive, with no single model dominating across settings; transformer models perform strongest overall while structural signals yield modest but consistent gains in select regimes and improve low-FPR behavior in harder cases.
Significance. If the multi-regime experimental design and repeated splits are executed as described, the work provides a useful corrective to overly optimistic single-setting evaluations common in the prompt-injection literature. The emphasis on the gap between ranking metrics and deployment-relevant thresholded metrics, together with the planned code release, strengthens the practical value of the contribution. The modest, qualified claims (no universal winner, regime dependence) align with the empirical scope and avoid overgeneralization.
minor comments (3)
- The abstract states results and metrics but provides no details on dataset sizes, exact OOD construction, or statistical testing; while the full manuscript presumably supplies these, a brief methods summary in the abstract would improve standalone readability.
- The structural signals are described at a high level (hierarchy overrides, spoofing, etc.); a short table or pseudocode listing the exact features and how they are computed would aid reproducibility even before code release.
- The claim that structural signals 'improve low false positive rate behaviour in harder scenarios' would benefit from an explicit definition of 'harder scenarios' and the precise FPR operating points used for comparison.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The recognition of the multi-regime design, repeated splits, and distinction between ranking and thresholded metrics is appreciated. With no specific major comments provided in the report, we note that the manuscript will be revised for any minor issues identified during the process.
Circularity Check
No significant circularity; empirical evaluation is self-contained
full rationale
The paper is an empirical comparative study that evaluates multiple detector classes (lexical, semantic, structural, transformer) across out-of-distribution regimes, repeated splits, and both ranking and thresholded metrics. All reported performance differences, regime-dependence claims, and assessments of structural-signal contributions are direct outputs of the described experimental protocol rather than reductions of any fitted parameter, self-definition, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that would collapse the central findings back to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic’s responsible scal- ing policy, version 1.0
Anthropic, 2023. Anthropic’s responsible scal- ing policy, version 1.0. URL:https://www-cdn. anthropic.com/1adf000c8f675958c2ee23805d91aaade1cd4613/ responsible-scaling-policy.pdf. policy document
2023
-
[2]
Constitutional classifiers++: Efficient production-grade defenses against universal jailbreaks,
Cunningham,H.,Wei,J.,Wang,Z.,Persic,A.,Peng,A.,Abderrachid, J., Agarwal, R., Chen, B., Cohen, A., Dau, A., Dimitriev, A., Gilson, R., Howard, L., Hua, Y., Kaplan, J., Leike, J., Lin, M., Liu, C., Mikulik,V.,Mittapalli,R.,O’Hara,C.,Pan,J.,Saxena,N.,Silverstein, A., Song, Y., Yu, X., Zhou, G., Perez, E., Sharma, M., 2026. Con- stitutional classifiers++: Eff...
-
[3]
BERT: Pre- training of deep bidirectional transformers for language understand- ing, in: Proceedings of NAACL-HLT 2019, pp
Devlin, J., Chang, M.W., Lee, K., Toutanova, K., 2019. BERT: Pre- training of deep bidirectional transformers for language understand- ing, in: Proceedings of NAACL-HLT 2019, pp. 4171–4186. URL: https://aclanthology.org/N19-1423.pdf. A. Akinrele and S. N. Gowda:Preprint submitted to ElsevierPage 17 of 19 Prompt Injection Detection is Regime-Dependent: A D...
2019
-
[4]
Dong, J., Zhang, Y., Liu, Y., Zhong, Z., Wei, T., Zhang, C., Qiu, H.,
-
[5]
Revisiting the Reliability of Language Models in Instruction-Following
Revisiting the reliability of language models in instruction- following. arXiv preprint arXiv:2512.14754 URL:https://arxiv. org/abs/2512.14754
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
When benchmarks lie: Evaluating malicious prompt classifiers under true distribution shift
Fomin, M., 2026. When benchmarks lie: Evaluating malicious prompt classifiers under true distribution shift. arXiv preprint arXiv:2602.14161 URL:https://arxiv.org/abs/2602.14161
-
[7]
Selective Classification for Deep Neural Networks
Geifman, Y., El-Yaniv, R., 2017. Selective classification for deep neural networks. arXiv preprint arXiv:1705.08500 URL:https:// arxiv.org/abs/1705.08500, doi:10.48550/arXiv.1705.08500
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.08500 2017
-
[8]
Mitigating prompt injection attacks with a layered defense strategy
Google, 2025. Mitigating prompt injection attacks with a layered defense strategy. URL:https://security.googleblog.com/2025/06/ mitigating-prompt-injection-attacks.html. google Online Security Blog, accessed April 2026
2025
-
[9]
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., Fritz, M., 2023. Not what you’ve signed up for: Compromising real- worldLLM-integratedapplicationswithindirectpromptinjection,in: Proceedingsofthe16thACMWorkshoponArtificialIntelligenceand Security, ACM. pp. 79–90. URL:https://doi.org/10.1145/3605764. 3623985, doi:10.1145/3605764.3623985
-
[10]
On calibration of modern neural networks, in: International conference on machine learning, PMLR
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q., 2017. On calibration of modern neural networks, in: International conference on machine learning, PMLR. pp. 1321–1330
2017
-
[11]
Toxicity detection for free, in: Advances in Neural Information Processing Systems, pp
Hu, Z., Piet, J., Zhao, G., Jiao, J., Wagner, D., 2024. Toxicity detection for free, in: Advances in Neural Information Processing Systems, pp. 17518–17540. URL: https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 1f69928210578f4cf5b538a8c8806798-Abstract-Conference.html
2024
-
[12]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan,H.,Upasani,K.,Chi,J.,Rungta,R.,Iyer,K.,Mao,Y.,Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., Khabsa, M., 2023. Llama guard: LLM-based input-output safeguard for human-AI conversa- tions.arXivpreprintarXiv:2312.06674URL:https://arxiv.org/abs/ 2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Jacobs,R.A.,Jordan,M.I.,Nowlan,S.J.,Hinton,G.E.,1991.Adaptive mixturesoflocalexperts. NeuralComputation3,79–87. URL:https: //doi.org/10.1162/neco.1991.3.1.79, doi:10.1162/neco.1991.3.1.79
-
[14]
Detectionmethodforpromptinjectionby integratingpre-trainedmodelandheuristicfeatureengineering
Ji,Y.,Li,R.,Mao,B.,2025. Detectionmethodforpromptinjectionby integratingpre-trainedmodelandheuristicfeatureengineering. arXiv preprint arXiv:2506.06384 URL:https://arxiv.org/abs/2506.06384
-
[15]
Jiang, L., Rao, K., Han, S., Ettinger, A., Brahman, F., Kumar, S., Mireshghallah, N., Lu, X., Sap, M., Choi, Y., Dziri, N., 2024. WILDTEAMING at scale: From in-the-wild jailbreaks to (adversar- ially) safer language models, in: Advances in Neural Information Processing Systems. URL:https://arxiv.org/abs/2406.18510
-
[16]
Injecguard: Benchmarking and mitigating over-defense in prompt injection guardrail models
Li, H., Liu, X., 2024. Injecguard: Benchmarking and mitigating over-defense in prompt injection guardrail models. arXiv preprint arXiv:2410.22770 URL:https://arxiv.org/abs/2410.22770
-
[17]
Formal- izing and benchmarking prompt injection attacks and defenses, in: 33rd USENIX Security Symposium (USENIX Security 2024), USENIX Association
Liu, Y., Jia, Y., Geng, R., Jia, J., Gong, N.Z., 2024. Formal- izing and benchmarking prompt injection attacks and defenses, in: 33rd USENIX Security Symposium (USENIX Security 2024), USENIX Association. URL:https://www.usenix.org/conference/ usenixsecurity24/presentation/liu-yupei
2024
-
[18]
Liu, Y., Jia, Y., Jia, J., Song, D., Gong, N.Z., 2025. Datasentinel: A game-theoretic detection of prompt injection attacks, in: 2025 IEEE Symposium on Security and Privacy (SP), IEEE. URL:https://doi. org/10.1109/SP61157.2025.00250, doi:10.1109/SP61157.2025.00250
-
[19]
Decoupled weight decay regular- ization, in: International Conference on Learning Representations (ICLR)
Loshchilov, I., Hutter, F., 2019. Decoupled weight decay regular- ization, in: International Conference on Learning Representations (ICLR). URL:https://openreview.net/pdf?id=Bkg6RiCqY7
2019
-
[20]
An Empirical Study of Multi-Generation Sampling for Jailbreak Detection in Large Language Models
Luo, H., Gowda, S.N., 2026. An empirical study of multi-generation sampling for jailbreak detection in large language models. arXiv preprint arXiv:2604.18775
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Maloyan, N., Namiot, D., 2026. Prompt injection attacks on agentic coding assistants: A systematic analysis of vulnerabilities in skills, tools, and protocol ecosystems. arXiv preprint arXiv:2601.17548 URL:https://arxiv.org/abs/2601.17548
-
[22]
Mosbach, M., Andriushchenko, M., Klakow, D., 2020. On the sta- bilityoffine-tuningBERT:Misconceptions,explanations,andstrong baselines.arXivpreprintarXiv:2006.04884URL:https://arxiv.org/ pdf/2006.04884
-
[23]
Anyone can jailbreak: Prompt-based attacks on llms and t2is
Mustafa, A.B., Ye, Z., Lu, Y., Pound, M.P., Gowda, S.N., 2025. Anyone can jailbreak: Prompt-based attacks on llms and t2is. arXiv preprint arXiv:2507.21820
-
[24]
Low- effort jailbreak attacks against text-to-image safety filters
Mustafa,A.B.,Ye,Z.,Lu,Y.,Pound,M.P.,Gowda,S.N.,2026. Low- effort jailbreak attacks against text-to-image safety filters. arXiv preprint arXiv:2604.01888
-
[25]
Promptinjectionisnotsqlin- jection(itmaybeworse)
NationalCyberSecurityCentre,2025. Promptinjectionisnotsqlin- jection(itmaybeworse). URL:https://www.ncsc.gov.uk/blog-post/ prompt-injection-is-not-sql-injection. blog post, accessed April 2026
2025
-
[26]
GPT-4 system card
OpenAI, 2023. GPT-4 system card. URL:https://cdn.openai.com/ papers/gpt-4-system-card.pdf. system card
2023
-
[27]
GPT-5 system card
OpenAI, 2025a. GPT-5 system card. URL:https://cdn.openai.com/ gpt-5-system-card.pdf. system card
-
[28]
How we think about safety and alignment
OpenAI, 2025b. How we think about safety and alignment. URL: https://openai.com/safety/how-we-think-about-safety-alignment/. webpage, accessed April 2026
2026
-
[29]
Prompt obfuscation for large language models, in: 34th USENIX Se- curity Symposium (USENIX Security 2025), USENIX Associa- tion
Pape, D., Mavali, S., Eisenhofer, T., Schönherr, L., 2025. Prompt obfuscation for large language models, in: 34th USENIX Se- curity Symposium (USENIX Security 2025), USENIX Associa- tion. URL:https://www.usenix.org/conference/usenixsecurity25/ presentation/pape
2025
-
[30]
arXiv preprint arXiv:2505.04806 URL:https: //arxiv.org/abs/2505.04806, doi:10.48550/arXiv.2505.04806
Pathade,C.,2025.Redteamingthemindofthemachine:Asystematic evaluation of prompt injection and jailbreak vulnerabilities in large language models. arXiv preprint arXiv:2505.04806 URL:https: //arxiv.org/abs/2505.04806, doi:10.48550/arXiv.2505.04806
-
[31]
Rababah, B., Wu, S.T., Kwiatkowski, M., Leung, C., Akcora, C.G.,
-
[32]
arXiv preprint arXiv:2410.13901 URL:https://arxiv.org/abs/2410.13901, doi:10.48550/arXiv.2410.13901
SoK: Prompt hacking of large language models. arXiv preprint arXiv:2410.13901 URL:https://arxiv.org/abs/2410.13901, doi:10.48550/arXiv.2410.13901
-
[33]
Sharma, M., Tong, M., Mu, J., Wei, J., Kruthoff, J., Goodfriend, S., Ong, E., Peng, A., Agarwal, R., Anil, C., Askell, A., Bailey, N., Benton, J., Bluemke, E., Bowman, S.R., Christiansen, E., Dau, A., Gopal, A., Gilson, R., Graham, L., Howard, L., Kalra, N., Lee, T., Lin, K., Lofgren, P., Mosconi, F., O’Hara, C., Olsson, C., Petrini, L., Rajani, S., Saxen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Wallace, E., Xiao, K., Leike, R., Weng, L., Heidecke, J., Beutel, A.,
-
[35]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
The instruction hierarchy: Training LLMs to prioritize priv- ileged instructions. arXiv preprint arXiv:2404.13208 URL:https: //arxiv.org/abs/2404.13208
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Wolpert, D.H., 1992. Stacked generalization. Neural Networks 5, 241–259. URL:https://doi.org/10.1016/S0893-6080(05)80023-1, doi:10.1016/S0893-6080(05)80023-1
-
[37]
Prompt Injection as Role Confusion
Ye, C., Cui, J., Hadfield-Menell, D., 2026. Prompt injection as role confusion. arXiv preprint arXiv:2603.12277 URL:https://arxiv. org/abs/2603.12277
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Yi, J., Xie, Y., Zhu, B., Kiciman, E., Sun, G., Xie, X., Wu, F.,
-
[39]
URL:https://doi.org/10.1145/3690624.3709179, doi:10.1145/ 3690624.3709179
Benchmarkinganddefendingagainstindirectpromptinjection attacks on large language models, in: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ACM. URL:https://doi.org/10.1145/3690624.3709179, doi:10.1145/ 3690624.3709179
-
[40]
Don’t listen to me: Understanding and exploring jailbreak prompts of large language models, in: 33rd USENIX Security Symposium (USENIX Security 2024), USENIX Association
Yu, Z., Liu, X., Liang, S., Cameron, Z., Xiao, C., Zhang, N., 2024. Don’t listen to me: Understanding and exploring jailbreak prompts of large language models, in: 33rd USENIX Security Symposium (USENIX Security 2024), USENIX Association. URL:https://www. usenix.org/conference/usenixsecurity24/presentation/yu-zhiyuan
2024
-
[41]
Zhao, W., Ben-Levi, D., Hao, W., Yang, J., Mao, C., 2025. Di- versity helps jailbreak large language models, in: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language A. Akinrele and S. N. Gowda:Preprint submitted to ElsevierPage 18 of 19 Prompt Injection Detection is Reg...
2025
-
[42]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J.Z., Fredrikson, M., 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 URL:https: //arxiv.org/abs/2307.15043. A. Akinrele and S. N. Gowda:Preprint submitted to ElsevierPage 19 of 19
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.