Pair-In, Pair-Out: Latent Multi-Token Prediction for Efficient LLMs
Pith reviewed 2026-06-29 18:08 UTC · model grok-4.3
The pith
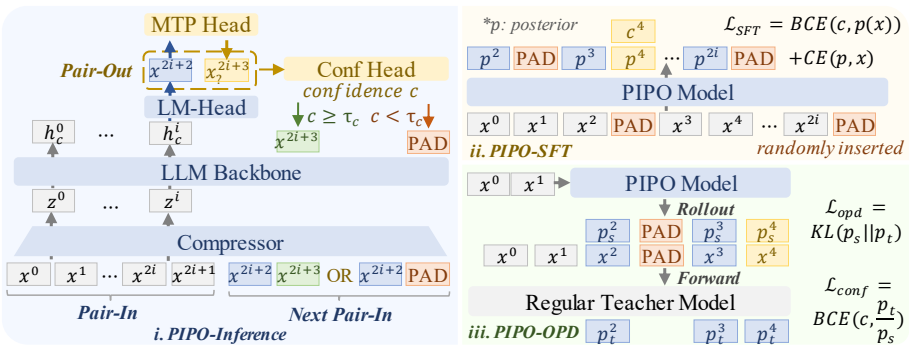
PIPO unifies latent input compression with multi-token output prediction as mirror operations and removes the verifier pass via a distilled confidence head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By viewing the latent compressor and the MTP head as mirror-image operations and training a confidence head alongside on-policy distillation, PIPO enables reliable multi-token generation that improves pass rates and reduces latency compared to standard autoregressive decoding.
What carries the argument
The Pair-In, Pair-Out architecture that pairs input token folding with output token unfolding, together with an OPD-trained confidence head for acceptance decisions.
If this is right
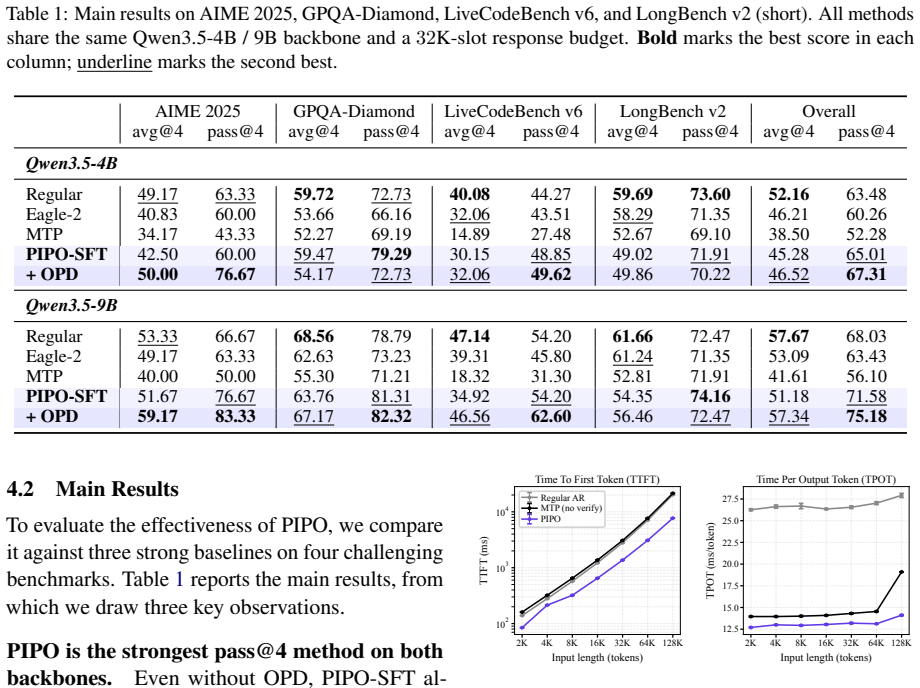
- Improves pass@4 by up to 7.15 points over regular decoding.
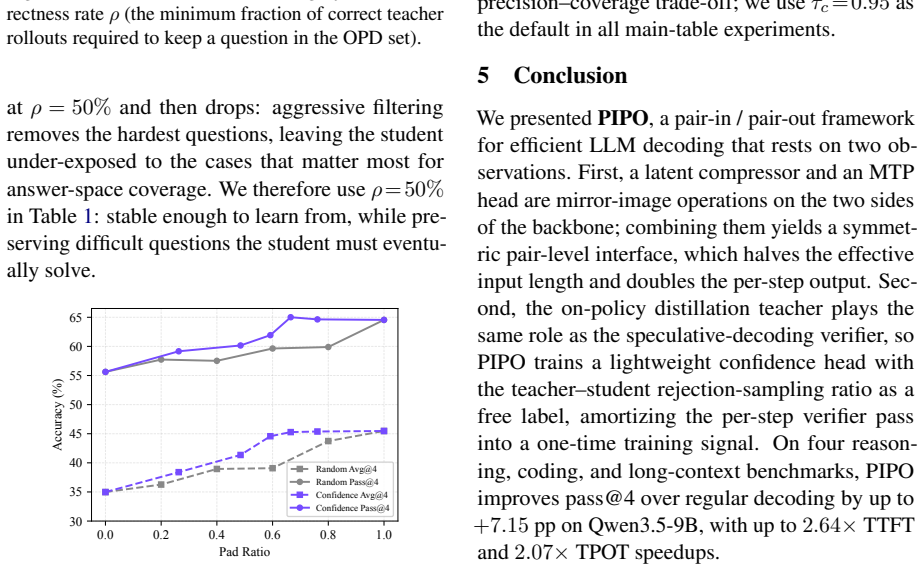
- Delivers up to 2.64x first-token latency speedup.
- Delivers up to 2.07x per-token latency speedup.
- Effective on Qwen3.5-4B and 9B models across AIME 2025, GPQA-Diamond, LiveCodeBench v6, and LongBench v2.
Where Pith is reading between the lines
- The mirroring principle could extend to triple or higher-order token pairings for greater compression.
- The OPD-trained acceptance rule may transfer to other speculative decoding setups without retraining.
- Energy use per generated token could drop enough to make longer reasoning traces practical on edge devices.
- Integration with existing quantization or pruning methods might produce additive speedups.
- keywords:[
Load-bearing premise
That the confidence head trained with on-policy distillation yields acceptance decisions reliable enough to eliminate the need for a separate verifier pass without reducing output quality.
What would settle it
Running PIPO without any verifier on a held-out reasoning benchmark and measuring whether pass rates fall below those of standard autoregressive decoding would settle the reliability claim.
Figures



read the original abstract
Long chain-of-thought reasoning has made autoregressive decoding the dominant inference cost of modern large language models. Existing methods target either the input side (latent compression) or the output side (speculative decoding and multi-token prediction, MTP), but the two lines of work have been pursued independently. Moreover, output-side methods must incur an expensive verifier pass to validate the unreliable draft tokens predicted by MTP. To address these issues, we propose \textbf{Pair-In, Pair-Out (PIPO)}, which unifies both sides by viewing a latent compressor and an MTP head as mirror-image operations: the compressor folds two input tokens into one latent representation, while the MTP head unfolds one hidden state into one additional output token. To remove the verifier cost without sacrificing reliability, PIPO trains a lightweight confidence head that decides whether draft tokens should be accepted. We observe that On-Policy Distillation (OPD) naturally matches the rejection-sampling criterion of speculative decoding, so the confidence head can be trained alongside OPD with negligible extra cost. Experiments on AIME 2025, GPQA-Diamond, LiveCodeBench v6, and LongBench v2 with Qwen3.5-4B and 9B backbones show that PIPO improves pass@4 over regular decoding by up to $+7.15$ points, while delivering up to $2.64\times$ first-token-latency and $2.07\times$ per-token-latency speedups. Project Page: GitHub.com/RedAI-Infra/PIPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Pair-In, Pair-Out (PIPO) to unify latent input compression with multi-token prediction (MTP) on the output side for efficient autoregressive decoding in long chain-of-thought reasoning. It introduces a lightweight confidence head trained jointly with on-policy distillation (OPD) to perform accept/reject decisions on draft tokens, eliminating the separate verifier pass required by standard speculative decoding. Experiments on AIME 2025, GPQA-Diamond, LiveCodeBench v6, and LongBench v2 using Qwen3.5-4B and 9B backbones report up to +7.15 pass@4 improvement over regular decoding together with 2.64× first-token and 2.07× per-token latency speedups.
Significance. If the central empirical claims hold, the unification of input-side compression and output-side MTP with an OPD-trained confidence head could deliver meaningful inference efficiency gains for reasoning models without incurring verifier overhead. The observation that OPD aligns with speculative-decoding rejection sampling would be a useful training insight if quantitatively validated.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline gains (+7.15 pass@4, 2.64× first-token latency) rest on the claim that the OPD-trained confidence head produces accept/reject decisions whose reliability matches a separate verifier; however, the manuscript supplies no calibration metrics (e.g., ECE or reliability diagrams), no ablation against an oracle verifier, and no analysis of distribution shift induced by the paired latent compressor, leaving the weakest assumption untested.
- [Abstract] Abstract: the reported speedups and accuracy improvements are presented without error bars, data-exclusion criteria, or controls for post-hoc selection, so it is impossible to determine whether the numbers reflect genuine generalization or fitting artifacts.
minor comments (2)
- The GitHub project page is referenced but no code, model checkpoints, or reproduction instructions are described in the text.
- Notation for the latent compressor and MTP head as 'mirror-image operations' is introduced without an accompanying equation or diagram clarifying the exact dimensionality mapping.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the empirical support and reporting.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline gains (+7.15 pass@4, 2.64× first-token latency) rest on the claim that the OPD-trained confidence head produces accept/reject decisions whose reliability matches a separate verifier; however, the manuscript supplies no calibration metrics (e.g., ECE or reliability diagrams), no ablation against an oracle verifier, and no analysis of distribution shift induced by the paired latent compressor, leaving the weakest assumption untested.
Authors: We appreciate the referee's emphasis on rigorous validation of the confidence head. While the on-policy distillation procedure is constructed to align directly with the rejection-sampling rule of speculative decoding, we agree that explicit calibration evidence is currently missing. In the revised manuscript we will add ECE scores and reliability diagrams for the confidence head, an ablation study against an oracle verifier, and a quantitative analysis of any distribution shift introduced by the paired latent compressor. These results will be reported in the Experiments section. revision: yes
-
Referee: [Abstract] Abstract: the reported speedups and accuracy improvements are presented without error bars, data-exclusion criteria, or controls for post-hoc selection, so it is impossible to determine whether the numbers reflect genuine generalization or fitting artifacts.
Authors: We concur that transparent statistical reporting is essential. In the revision we will include error bars (standard deviation across multiple random seeds) for all headline metrics, explicitly document the data-exclusion criteria and full evaluation protocol, and state that no post-hoc benchmark or hyper-parameter selection was performed. These clarifications will be added to both the abstract and the Experiments section. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark measurements, not self-defined quantities
full rationale
The abstract and description contain no equations, fitted parameters presented as predictions, or self-citations that reduce the reported pass@4 gains or latency speedups to quantities defined by the same inputs. The unification of latent compression and MTP as mirror operations is a conceptual framing, not a derivation that collapses by construction. The OPD-confidence-head observation is stated as an empirical match enabling joint training, without any reduction to a tautology or prior self-result. The central results are external benchmark numbers (AIME, GPQA, etc.) that remain falsifiable outside the training procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching.arXiv preprint arXiv:2503.05179. Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xi- aozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, and 1 others. 2025. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. InP...
-
[2]
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Jiaze Li, Hao Yin, Wenhui Tan, Jingyang Chen, Boshen Xu, Yuxun Qu, Yijing Chen, Jianzhong Ju, Zhenbo Luo, and Jian Luan. 2025a. Revisor: Beyond textual reflection, towards multimodal introspective reason- ing in long-form v...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Guilherme Penedo, Anton Lozhkov, Hynek Ky- dlíˇcek, Loubna Ben Allal, Edward Beeching, Agustín Piqueres Lajarín, Quentin Gallouédec, Nathan Habib, Lewis Tunstall, and Leandro von Werra. 2025. Codeforces. https://huggingface. co/datasets/open-r1/codeforces. David Rein, Betty Li Hou, Asa Cooper S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476. Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Che...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
DeepThink
encourages LLMs to produce explicit step- by-step traces before answering, and has been shown to substantially improve performance on complex tasks such as mathematics, code gener- ation, long-form writing, and multimodal under- standing (Cao et al., 2025; Li et al., 2025a). Re- cent “DeepThink” models (Jaech et al., 2024; Guo et al., 2025) go further by ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.