Fine-Tuning Vision-Language Models for Understanding Current Damage and Scoring Priority with Quality Guard Agent
Pith reviewed 2026-06-30 11:48 UTC · model grok-4.3
The pith
Fine-tuning LLaVA-1.5-7B on 2k-3k bridge images produces natural language damage descriptions that a rule-based engine converts to five-level repair priorities, filtered by a Swallow-8B quality guard.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
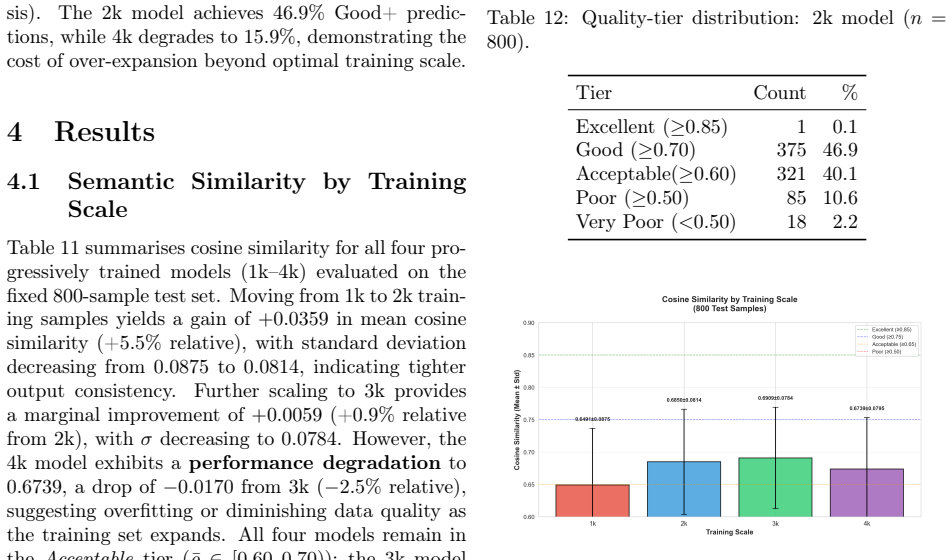
Fine-tuning LLaVA-1.5-7B with QLoRA on up to 4,000 image-text pairs allows the model to output natural language descriptions of bridge damage from which a rule-based scoring engine computes five-level repair priorities; a Swallow-8B Quality Guard rejects unsuitable outputs to avoid spurious scores, with 2k-3k samples proving sufficient for peak semantic similarity of 0.6909 on a fixed 800-image test set and inference optimized to 10.06 seconds per image.
What carries the argument
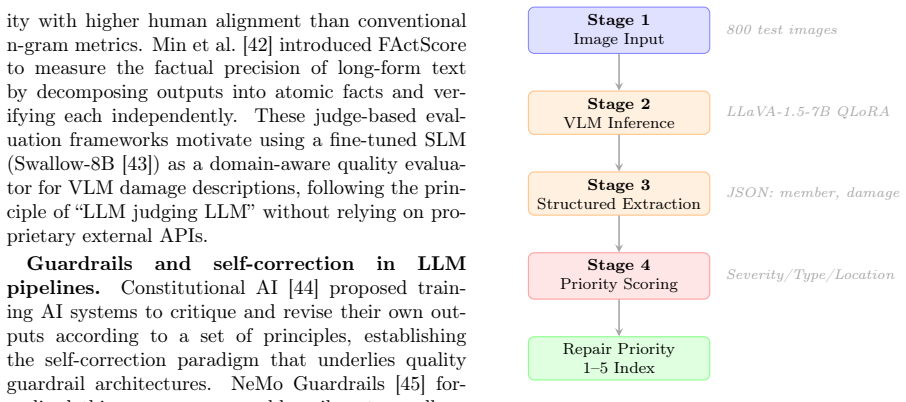
The two-stage pipeline of a fine-tuned vision-language model generating natural language damage descriptions, followed by a rule-based engine for priority scoring and protected by a Swallow-8B quality guard agent.
If this is right
- Reduces inter-rater variability in qualitative damage ratings assigned during mandatory bridge inspections.
- Supplies AI-assisted triage to augment the capacity of aging expert engineers.
- Advances data governance by standardizing damage understanding from visual records.
- Achieves 70.2 percent faster inference per image through torch.compile and batch processing.
- Prevents erroneous priority scores by filtering low-quality or unrecognised images via the quality guard.
Where Pith is reading between the lines
- The approach could extend to inspections of other infrastructure types such as roads or tunnels if comparable image-text datasets exist.
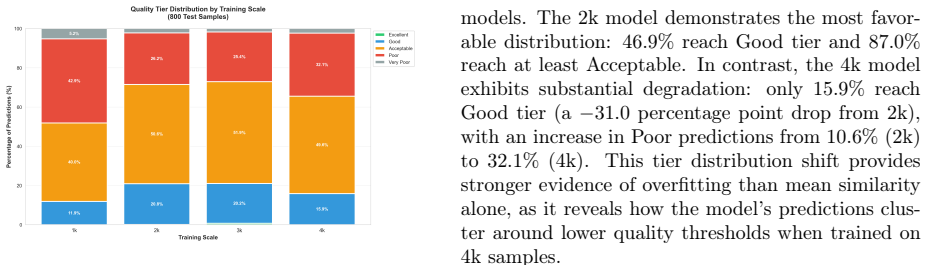
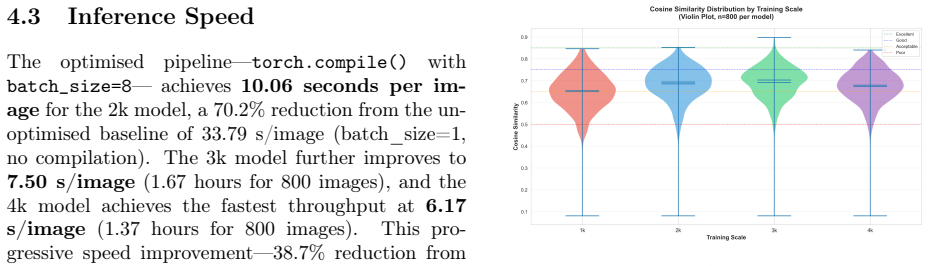
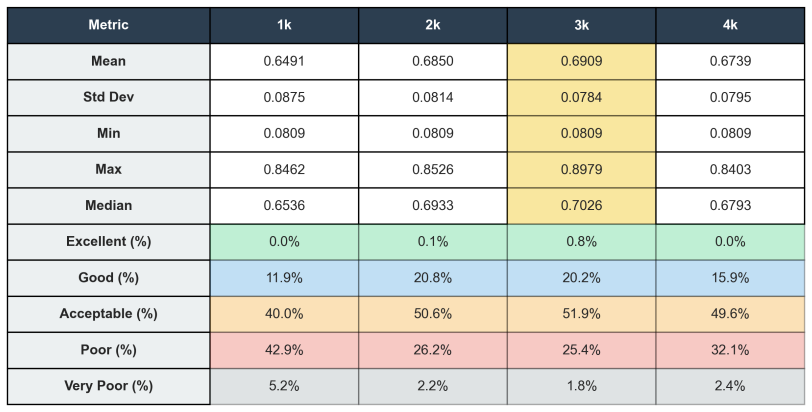
- Data quality and curation matter more than volume, since adding noisier samples beyond 3k reduced performance.
- Widespread adoption might gradually shift inspection workflows toward hybrid human-AI review rather than fully manual assessments.
Load-bearing premise
The rule-based scoring engine can map VLM-generated natural language descriptions of damage patterns into consistent five-level priority indices without large errors from ambiguous or incomplete descriptions.
What would settle it
Direct comparison of the automated five-level priority scores against consensus scores from multiple expert engineers on a new held-out set of bridge images, measuring agreement rates and variability reduction.
Figures




read the original abstract
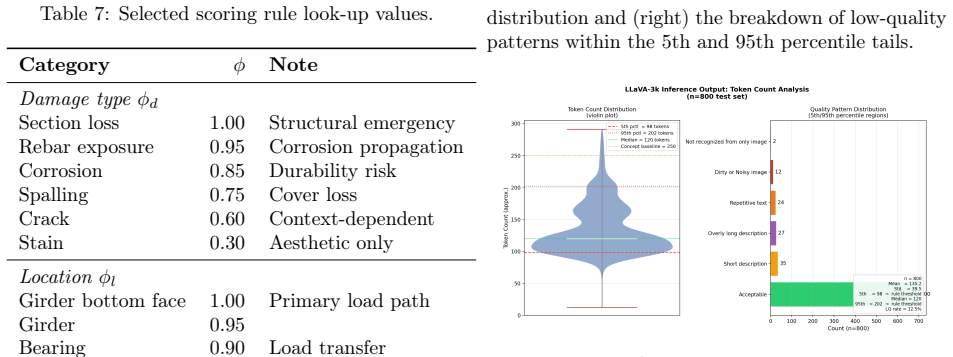
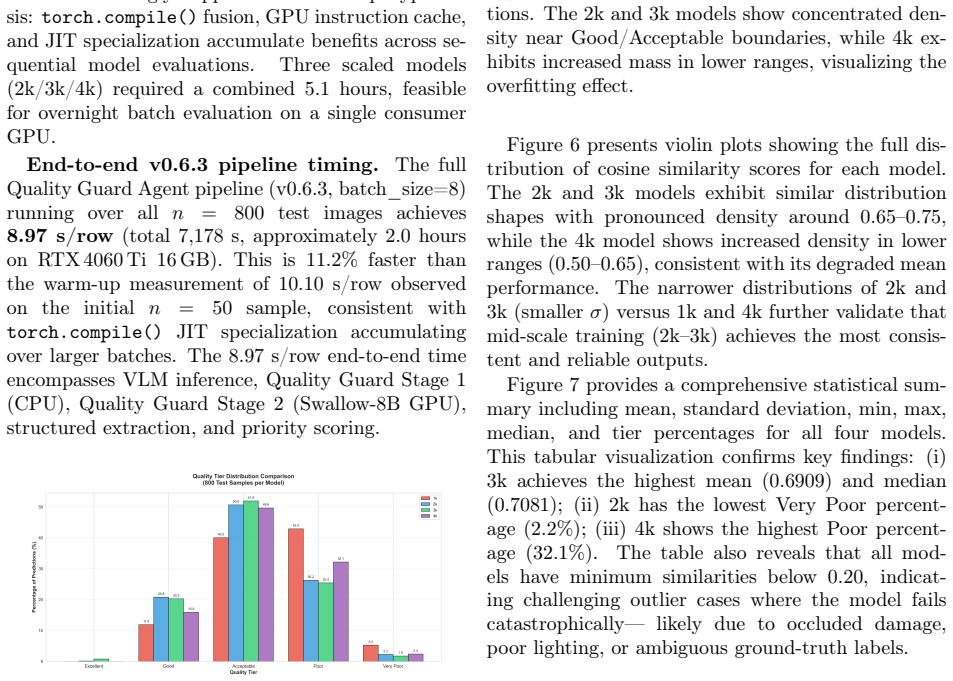
Bridge inspection in Japan requires mandatory visual assessments every five years, yet qualitative damage ratings (levels a-e) assigned by different engineers exhibit significant inter-rater variability -- a critical barrier to consistent infrastructure management. The aging of skilled engineers further threatens inspection capacity. This paper presents a methodology for automating bridge damage understanding and repair priority scoring using fine-tuned Vision-Language Models (VLMs). We fine-tune LLaVA-1.5-7B with QLoRA on up to 4,000 paired bridge damage images and inspection text records, then evaluate on a fixed test set of 800 images. The model outputs natural language descriptions identifying structural members and damage patterns, from which a rule-based scoring engine calculates a five-level repair priority index. A progressive training study (1k/2k/3k/4k samples) reveals that 2k training samples achieve near-optimal validation loss in only 2.9 hours of training; beyond 2k, validation loss improves by no more than 0.2% per doubling of training samples, exhibiting clear diminishing returns. Furthermore, semantic similarity on the held-out test set peaks at 3k (0.6909) and degrades at 4k (0.6739), indicating that quality-curated mid-scale data outperforms larger but noisier corpora. Inference optimization combining torch.compile() and batch processing (batch_size=8) achieves 10.06 seconds per image -- a 70.2% reduction over the unoptimized baseline. Our approach contributes to data governance in bridge inspection, reduces inter-rater variability, and provides AI-assisted triage to augment expert engineers in inspection workflows. Furthermore, we introduce a two-stage Quality Guard using a fine-tuned Swallow-8B SLM to reject low-quality VLM outputs before priority scoring, preventing spurious scores from damaged or unrecognised images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a methodology for automating bridge damage assessment and repair priority scoring in Japan using fine-tuned vision-language models. It fine-tunes LLaVA-1.5-7B with QLoRA on up to 4,000 image-text pairs to generate natural language damage descriptions, applies a rule-based engine to derive five-level (a-e) repair priorities, and introduces a two-stage Quality Guard (fine-tuned Swallow-8B) to filter low-quality outputs. On an 800-image held-out test set, it reports peak semantic similarity of 0.6909 at 3k training samples, diminishing returns in validation loss beyond 2k samples, and a 70.2% inference speedup via torch.compile and batching.
Significance. If the rule-based engine maps VLM descriptions to priorities with high consistency to expert judgments, the work could help standardize mandatory bridge inspections by mitigating inter-rater variability and supporting triage for aging infrastructure. The scaling study and inference optimizations provide practical guidance for deploying VLMs in real-world inspection workflows.
major comments (2)
- [Abstract] Abstract and evaluation on held-out test set: the central claim that the rule-based scoring engine yields 'reliable' five-level repair priority indices is unsupported by evidence; only semantic similarity of the generated descriptions (peak 0.6909) is reported, with no accuracy, Cohen's kappa, confusion matrix, or other agreement metric comparing the computed a-e priorities against the original human inspection records on the 800-image test set.
- [Abstract] Abstract: no baseline comparisons are provided for either the fine-tuned VLM descriptions or the final priority scores against the unfine-tuned LLaVA-1.5-7B, human inter-rater agreement, or alternative scoring methods, which is required to substantiate the claim of reduced variability and reliable automation.
minor comments (1)
- The progressive training study (1k/2k/3k/4k) reports validation loss improvements but provides no error bars, statistical significance tests, or details on how the fixed 800-image test set was constructed relative to the training splits.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive major comments. We agree that the current evaluation leaves important gaps in validating the priority scoring and in providing baselines, and we will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation on held-out test set: the central claim that the rule-based scoring engine yields 'reliable' five-level repair priority indices is unsupported by evidence; only semantic similarity of the generated descriptions (peak 0.6909) is reported, with no accuracy, Cohen's kappa, confusion matrix, or other agreement metric comparing the computed a-e priorities against the original human inspection records on the 800-image test set.
Authors: We agree that direct agreement metrics between the rule-based a-e priorities and the human inspection records on the test set are missing. The manuscript currently uses semantic similarity of the VLM descriptions as the reported metric and treats the rule-based engine as a fixed, deterministic post-processing step. In the revision we will compute and report accuracy, Cohen's kappa, and a confusion matrix for the derived priorities against the original human labels on the 800-image held-out set, and we will add a dedicated subsection on priority-scoring validation. revision: yes
-
Referee: [Abstract] Abstract: no baseline comparisons are provided for either the fine-tuned VLM descriptions or the final priority scores against the unfine-tuned LLaVA-1.5-7B, human inter-rater agreement, or alternative scoring methods, which is required to substantiate the claim of reduced variability and reliable automation.
Authors: We acknowledge the absence of baselines. We will add a comparison of semantic similarity (and, in the new priority validation subsection, agreement metrics) between the fine-tuned model and the base LLaVA-1.5-7B on the same test set. For human inter-rater agreement we will incorporate quantitative estimates from the bridge-inspection literature cited in the introduction. Direct implementation of alternative learned scoring methods is outside the current scope, but we will expand the discussion to clarify how the rule-based engine plus quality guard is intended to mitigate variability; we will mark this limitation explicitly. revision: partial
Circularity Check
No circularity; empirical evaluation on held-out test set
full rationale
The paper describes fine-tuning LLaVA-1.5-7B with QLoRA on 2k-4k image-text pairs, evaluating semantic similarity (peaking at 0.6909) on a fixed 800-image held-out test set, and using a rule-based engine on VLM outputs plus a fine-tuned Swallow-8B guard. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text that reduce reported metrics back to inputs by construction. All results are direct empirical measurements on unseen data, satisfying the condition for a self-contained derivation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- training sample counts (1k/2k/3k/4k)
- QLoRA hyperparameters
axioms (2)
- domain assumption Natural language descriptions produced by the fine-tuned VLM contain extractable information about structural members and damage patterns that can be mapped by fixed rules to a five-level priority index.
- domain assumption A separately fine-tuned Swallow-8B model can reliably identify low-quality VLM outputs before scoring occurs.
invented entities (1)
-
Quality Guard Agent (fine-tuned Swallow-8B SLM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Periodic inspection guidelines for road bridges (doro-kyo teiki tenken yoryo)
Ministry of Land, Infrastructure, Transport and Tourism (MLIT), Japan. Periodic inspection guidelines for road bridges (doro-kyo teiki tenken yoryo). Technical report, MLIT, 2023. Avail- able:https://www.mlit.go.jp/road/sisaku/ yobohozen/yobohozen.html
2023
-
[2]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Sys- tems (NeurIPS), volume 36, 2023
2023
-
[3]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Wenliang Dai, Junnan Li, Dongxu Li, An- thony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision- language models with instruction tuning.arXiv preprint arXiv:2305.06500, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
GPT-4 technical report
OpenAI. GPT-4 technical report. Technical re- port, OpenAI, 2023
2023
-
[5]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtz- man, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs.arXiv preprint arXiv:2305.14314, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Takato Yasuno. Quantized vision-language mod- els for damage assessment: A comparative study of LLaVA-1.5-7B quantization levels.arXiv preprint arXiv:2603.26770, 2026
-
[7]
Takato Yasuno. Multi-stage bridge inspec- tion system: Integrating foundation models with location anonymization.arXiv preprint arXiv:2601.17254, 2026. 19
-
[8]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (ICML), 2021
2021
-
[9]
Flamingo: a visual lan- guage model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Mal- colm Reynolds, et al. Flamingo: a visual lan- guage model for few-shot learning. InAd- vances in Neural Information Processing Sys- tems (NeurIPS), volume 35, 2022
2022
-
[10]
BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[11]
Improved baselines with vi- sual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with vi- sual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. Highlight paper
2024
-
[12]
MiniGPT-4: En- hancing vision-language understanding with ad- vanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: En- hancing vision-language understanding with ad- vanced large language models. InInterna- tional Conference on Learning Representations (ICLR), 2024
2024
-
[13]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Gir- shick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Gir- shick. Segment anything. InInternational Con- ference on Computer Vision (ICCV), 2023
2023
-
[14]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detec- tion.arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Deeplearning-basedcrackdamage detection using convolutional neural networks
Young-Jin Cha, Wooram Choi, and Oral Büyüköztürk. Deeplearning-basedcrackdamage detection using convolutional neural networks. Computer-Aided Civil and Infrastructure Engi- neering, 32(5):361–378, 2017
2017
-
[16]
Spencer, Vedhus Hoskere, and Yasutaka Narazaki
Billie F. Spencer, Vedhus Hoskere, and Yasutaka Narazaki. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering, 5(2):199–222, 2019
2019
-
[17]
Thomas, and Marc Maguire
Sattar Dorafshan, Robert J. Thomas, and Marc Maguire. Comparison of deep convolutional neu- ral networks and edge detectors for image-based crack detection in concrete.Construction and Building Materials, 186:1031–1045, 2018
2018
-
[18]
Machine learn- ing for crack detection: Review and model per- formance comparison.Journal of Computing in Civil Engineering, 34(5), 2020
Yi-An Hsieh and Yichang Tsai. Machine learn- ing for crack detection: Review and model per- formance comparison.Journal of Computing in Civil Engineering, 34(5), 2020
2020
-
[19]
Takato Yasuno. Few-shot1/aanomalies feed- back: Damage vision mining opportunity and embedding feature imbalance.arXiv preprint arXiv:2307.12676, 2023
-
[20]
Frangopol
Dan M. Frangopol. Life-cycle performance, man- agement, and optimisation of structural systems under uncertainty: accomplishments and chal- lenges.Structure and Infrastructure Engineering, 7(6):389–413, 2011
2011
-
[21]
Automatic pixel-level crack detection on dam surface using deep convolutional network.Sensors, 18(7):2090, 2018
Liyuan Yang, Boyuan Li, Wei Li, Zhenduo Liu, Guoyong Yang, and Jizhong Xiao. Automatic pixel-level crack detection on dam surface using deep convolutional network.Sensors, 18(7):2090, 2018
2090
-
[22]
WinCLIP: Zero-/few-shot anomaly classification and segmentation
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. WinCLIP: Zero-/few-shot anomaly classification and segmentation. InPro- ceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2023
2023
-
[23]
AnomalyCLIP: Object- agnostic prompt learning for zero-shot anomaly detection
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. AnomalyCLIP: Object- agnostic prompt learning for zero-shot anomaly detection. InInternational Conference on Learn- ing Representations (ICLR), 2024
2024
-
[24]
Anoma- lyGPT: Detecting industrial anomalies using large vision-language models
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Anoma- lyGPT: Detecting industrial anomalies using large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024
2024
-
[25]
Heterogeneous Graph Importance Scoring and Clustering with Automated LLM-based Interpretation
Takato Yasuno. Heterogeneous graph im- portance scoring and clustering with auto- mated LLM-based interpretation.arXiv preprint arXiv:2605.02919, 2026. 20
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Yunkang Cao, Xiaohao Xu, Chen Sun, Xiaonan Huang, and Weiming Shen. Towards generic anomaly detection and understanding: Large- scale visual-linguistic model (GPT-4V) takes the lead.arXiv preprint arXiv:2311.02782, 2023
-
[27]
Towardszero- shot anomaly detection and reasoning with mul- timodal large language models
Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, VishalM.Patel, andIshtDwivedi. Towardszero- shot anomaly detection and reasoning with mul- timodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[28]
Towards training-free anomaly detec- tion with vision and language foundation mod- els
Jinjin Zhang, Guodong Wang, Yizhou Jin, and Di Huang. Towards training-free anomaly detec- tion with vision and language foundation mod- els. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recogni- tion (CVPR), 2025
2025
-
[29]
LogicAD: Explainable anomaly detection via VLM-based text feature extraction
Er Jin, Qihui Feng, Yongli Mou, Stefan Decker, Gerhard Lakemeyer, Oliver Simons, and Johannes Stegmaier. LogicAD: Explainable anomaly detection via VLM-based text feature extraction. InProceedings of the AAAI Confer- ence on Artificial Intelligence (AAAI), 2025
2025
-
[30]
An in- tegrated approach for automated acquisition of bridge data and deficiency evaluation
Abdelhady Omar and Osama Moselhi. An in- tegrated approach for automated acquisition of bridge data and deficiency evaluation. InPro- ceedings of the 40th International Symposium on Automation and Robotics in Construction (IS- ARC), pages 341–348, Chennai, India, 2023
2023
-
[31]
Im- proved information extraction from bridge in- spection reports using fine-tuned generative pre- trained transformers
Abdelhady Omar and Osama Moselhi. Im- proved information extraction from bridge in- spection reports using fine-tuned generative pre- trained transformers. InProceedings of the 42nd International Symposium on Automation and Robotics in Construction (ISARC), pages 1551– 1558, Montreal, Canada, 2025
2025
-
[32]
Comparing few-shot learning with LLMs for efficient text classifica- tion in road maintenance applications
Varun Kumar Reja, Ching Yau Mok, Aritra Pal, and Ioannis Brilakis. Comparing few-shot learning with LLMs for efficient text classifica- tion in road maintenance applications. InPro- ceedings of the 42nd International Symposium on Automation and Robotics in Construction (ISARC), pages 1017–1024, Montreal, Canada, 2025
2025
-
[33]
Automated inspection report gener- ation using multimodal large language models and set-of-mark prompting
Hongxu Pu, Xincong Yang, Zhongqi Shi, and Nan Jin. Automated inspection report gener- ation using multimodal large language models and set-of-mark prompting. InProceedings of the 41st International Symposium on Automation and Robotics in Construction (ISARC), pages 1003–1009, Lille, France, 2024
2024
-
[34]
VL-Con: Vision-language dataset for deep learning-based construction monitoring applications
Shun-Hsiang Hsu, Junryu Fu, and Mani Golparvar-Fard. VL-Con: Vision-language dataset for deep learning-based construction monitoring applications. InProceedings of the 41st International Symposium on Automation and Robotics in Construction (ISARC), pages 1128–1135, Lille, France, 2024
2024
-
[35]
Prieto Ayllón, and Borja Gar- cía de Soto
Eyob Mengiste, Muammer Semih Sonkor, Zihao Zheng, Samuel A. Prieto Ayllón, and Borja Gar- cía de Soto. Automating weekly construction ac- tivity progress reporting: Leveraging AI-driven workflows. InProceedings of the 42nd Interna- tional Symposium on Automation and Robotics in Construction (ISARC), pages 641–648, Mon- treal, Canada, 2025
2025
-
[36]
Crack detection and seg- mentation for bridges using state-of-the-art deep learning methods: Single-stage vs
Ahmed Assad, Mohamad Bo Arki, Miray Sweid, and Amin Hammad. Crack detection and seg- mentation for bridges using state-of-the-art deep learning methods: Single-stage vs. two-stage de- tectors. InProceedings of the 42nd International Symposium on Automation and Robotics in Con- struction (ISARC), pages 996–1003, Montreal, Canada, 2025
2025
-
[37]
Transformer-based multi-resolution fast 3D re- construction for structural damage detection
Hui Zuo, Tao Sun, Hao Xie, Xiao Ma, Nima Shirzad-Ghaleroudkhani, and Qipei Mei. Transformer-based multi-resolution fast 3D re- construction for structural damage detection. InProceedings of the 42nd International Sym- posium on Automation and Robotics in Con- struction (ISARC), pages 988–995, Montreal, Canada, 2025
2025
-
[38]
3D reconstruction of a bridge with concrete dam- age classification using deep learning
Christopher Joseph Núñez Varillas, Marck Stee- war Regalado Espinoza, Luis Mario Huay- par Acurio, Antonio Stefano Bedon Rosario, Jor- dan Antony Romaní Chavez, Oscar Manuel So- lis Garcia, Karol Maricruz Agreda Estela, and Micaela Anthoaneth Cardenas Contreras. 3D reconstruction of a bridge with concrete dam- age classification using deep learning. InPro...
2024
-
[39]
Automated decision-making tool for optimal long-term scheduling of MRR strate- gies: A case study on bridges
Mohammed Alsharqawi, Saleh Abu Dabous, and Tarek Zayed. Automated decision-making tool for optimal long-term scheduling of MRR strate- gies: A case study on bridges. InProceed- ings of the 42nd International Symposium on Automation and Robotics in Construction (IS- ARC), pages 272–279, Montreal, Canada, 2025. 21
2025
-
[40]
Judging LLM-as-a-Judge with MT-Bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, SiyuanZhuang, ZhanghaoWu, YonghaoZhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), volume 36, 2023
2023
-
[41]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuo- hang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
FActScore: Fine-grained atomic eval- uation of factual precision in long form text gen- eration
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Ha- jishirzi. FActScore: Fine-grained atomic eval- uation of factual precision in long form text gen- eration. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP), 2023
2023
-
[43]
Llama-3-Swallow-8B-Instruct-v0.1: A japanese-enhanced instruction-tuned large lan- guage model
Tokyo Institute of Technology LLM Research Group. Llama-3-Swallow-8B-Instruct-v0.1: A japanese-enhanced instruction-tuned large lan- guage model. Hugging Face Model Hub, 2024
2024
-
[44]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Constitutional AI: Harm- lessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
NeMoGuardrails: Atoolkitfor controllable and safe LLM applications with pro- grammable rails
Traian Rebedea, Razvan Dinu, Makesh Nar- simhan Sreedhar, Christopher Parisien, and JonathanCohen. NeMoGuardrails: Atoolkitfor controllable and safe LLM applications with pro- grammable rails. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Lan- guage Processing (EMNLP): System Demonstra- tions, 2023
2023
-
[46]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learn- ing to retrieve, generate, and critique through self-reflection.arXiv preprint arXiv:2310.11511, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Chain-of-Verification Reduces Hallucination in Large Language Models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, RobertaRaileanu, XianLi, AsliCelikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models.arXiv preprint arXiv:2309.11495, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with ver- bal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Large language model alignment: A survey.arXiv preprint arXiv:2309.15025, 2023
Tianhao Shen, Renren Jin, Yufei Huang, Chuang Liu, Weilong Dong, Zishan Guo, Xinwei Wu, Yan Liu, and Deyi Xiong. Large language model alignment: A survey.arXiv preprint arXiv:2309.15025, 2023
-
[51]
Takato Yasuno. Adapting methods for domain- specific japanese small LMs: Scale, archi- tecture, and quantization.arXiv preprint arXiv:2603.18037, 2026
-
[52]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for transformers at scale.arXiv preprint arXiv:2208.07339, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
torch.compile: PyTorch 2.0 com- pilation
PyTorch Team. torch.compile: PyTorch 2.0 com- pilation. PyTorch Documentation, 2023
2023
-
[54]
Unsloth: Ef- ficient fine-tuning for large language mod- els.https://github.com/unslothai/unsloth,
Daniel Han and Michael Han. Unsloth: Ef- ficient fine-tuning for large language mod- els.https://github.com/unslothai/unsloth,
-
[55]
Japanese sentence-BERT: sentence-bert-base-ja-mean-tokens-v2
Sonoisa. Japanese sentence-BERT: sentence-bert-base-ja-mean-tokens-v2. Hugging Face Model Hub, 2021
2021
-
[56]
O’Reilly Media, 2024
John Berryman and Albert Ziegler.Prompt En- gineering for LLMs: The Art and Science of Building Large Language Model–Based Applica- tions. O’Reilly Media, 2024
2024
-
[57]
Packt Pub- lishing, 2025
Anjanava Biswas and Wrick Talukdar.Building Agentic AI Systems: Designing, Implementing, and Scaling Autonomous AI Agents. Packt Pub- lishing, 2025
2025
-
[58]
O’Reilly Media, 2024
Chip Huyen.AI Engineering: Building Applica- tions with Foundation Models. O’Reilly Media, 2024
2024
-
[59]
No Score
Michael Albada.Building Applications with AI Agents: Designing and Deploying Autonomous, Goal-Oriented AI Systems. O’Reilly Media, 2025. 22 Quality Guard Agent (v0.6.3) Image Inputn= 800bridge inspection images VLM Inference:LLaVA-1.5-7B+QLoRA adapter (3k fine-tune) batch_size=8,torch.compile()⇒10.10 s/image Stage 1: Rule-Based Filter CPU-only filter,≈0.0...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.