AssertLLM2: A Comprehensive LLM Benchmark for Assertion Generation from Design Specifications
Pith reviewed 2026-07-01 16:13 UTC · model grok-4.3
The pith
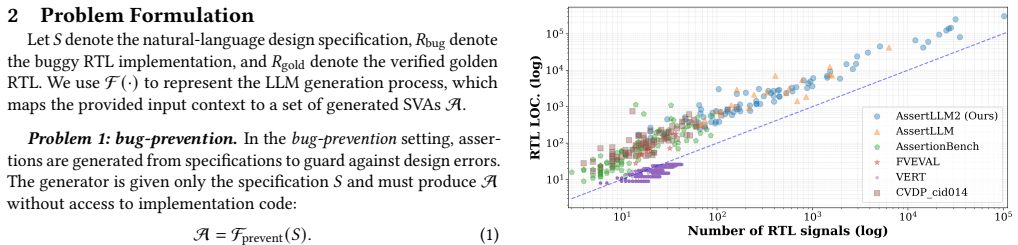
AssertLLM2 supplies 83 designs with specifications and buggy RTL to test whether LLMs can generate assertions that both prevent and detect hardware bugs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
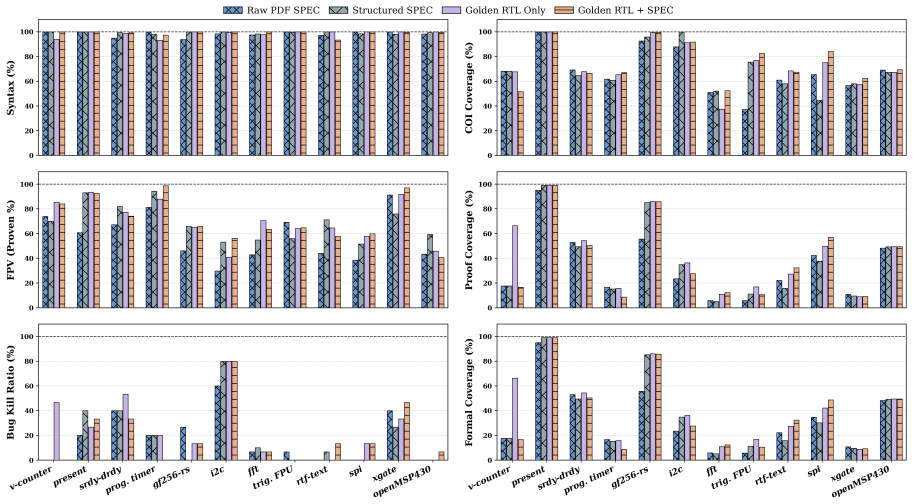
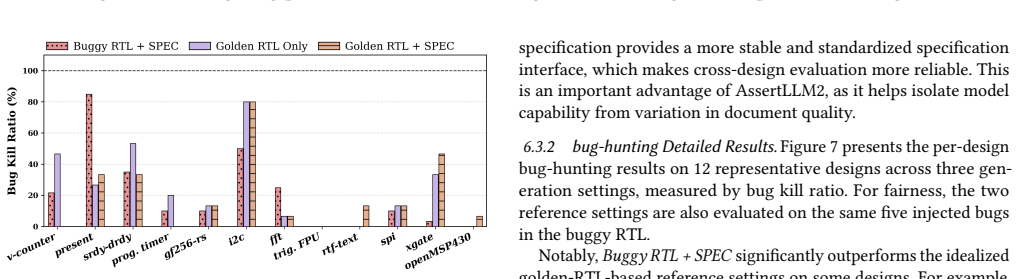
AssertLLM2 is the first benchmark to explicitly use buggy RTL as input to evaluate the bug-detection capability of LLM-generated assertions, supported by a dataset of 83 real-world designs, structured specifications, golden RTL, and systematically mutated variants, together with an evaluation framework spanning syntactic validity, formal provability, coverage, and mutation-based bug detection.
What carries the argument
The benchmark dataset of structured design specifications paired with verified golden RTL and mutated buggy RTL variants across 13 functional categories, enabling separate bug-prevention and bug-hunting tasks.
If this is right
- LLM-generated assertions can be evaluated for their ability to expose injected faults in RTL rather than only for syntactic or coverage properties.
- Baselines established on AssertLLM2 can be used to track progress of future LLMs on assertion tasks in hardware verification.
- The two-task formulation separates the problem of writing correct assertions from the problem of writing assertions that detect specific implementation errors.
- Designs in the benchmark include dependency-complete golden RTL, allowing assertions to be checked with formal tools without additional setup.
Where Pith is reading between the lines
- If the benchmark's mutation-based scores correlate with real silicon bug escapes, teams could adopt the bug-hunting setting as a pre-silicon filter before tape-out.
- The separation of bug-prevention and bug-hunting tasks suggests that different prompting or fine-tuning strategies may be optimal for each.
- Extending the benchmark with timing or power assertions would test whether the same LLM approach generalizes beyond functional properties.
Load-bearing premise
The chosen set of 83 designs and the four evaluation metrics are sufficient to produce a realistic and extensive assessment of assertion generation performance.
What would settle it
A follow-up study that applies the same LLMs to a substantially larger or differently distributed collection of industrial designs and obtains materially different rankings on the mutation-based bug-detection metric would undermine the benchmark's claim to realistic coverage.
Figures




read the original abstract
Assertion-based verification (ABV) is a cornerstone of modern hardware design, yet manually translating design intent into formal SystemVerilog Assertions (SVAs) remains labor-intensive and error-prone. While Large Language Models (LLMs) show promise for automating this process, existing benchmarks remain limited by unrealistic task formulations, weak specification inputs, and oversimplified evaluation. To address these limitations, we introduce AssertLLM2, an open-source benchmark for realistic assertion generation in hardware verification. AssertLLM2 contains 83 real-world designs across 13 functional categories. For each design, the benchmark provides a structured design specification, a verified dependency-complete golden RTL, and systematically mutated buggy RTL variants. These support two practical settings: bug-prevention, where assertions are generated from specifications to guard against design errors, and bug-hunting, where assertions are generated to expose discrepancies between intended behavior and faulty implementations. To the best of our knowledge, AssertLLM2 is the first benchmark to explicitly use buggy RTL as input to evaluate bug-detection capability. AssertLLM2 further adopts a more rigorous evaluation framework spanning syntactic validity, formal provability, coverage, and mutation-based bug detection. Our benchmark enables a more realistic and extensive assessment of assertion generation and establishes rigorous baselines for state-of-the-art LLMs in practical hardware verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AssertLLM2, an open-source benchmark for evaluating LLMs on generating SystemVerilog Assertions (SVAs) from design specifications. It comprises 83 real-world designs across 13 functional categories, each providing a structured specification, verified dependency-complete golden RTL, and systematically mutated buggy RTL variants. The benchmark supports two settings—bug-prevention (assertions from specs to guard against errors) and bug-hunting (assertions to detect discrepancies in faulty implementations)—and employs an evaluation framework covering syntactic validity, formal provability, coverage, and mutation-based bug detection. It claims, to the best of its knowledge, to be the first benchmark explicitly using buggy RTL as input for assessing bug-detection capability.
Significance. If the benchmark construction, design selection, and evaluation framework hold as described, this work would offer a meaningful advance by addressing limitations in prior benchmarks through more realistic inputs and metrics focused on practical hardware verification. The explicit inclusion of buggy variants, support for both prevention and detection scenarios, and open-source release are concrete strengths that enable reproducible baselines and future comparisons in the field.
minor comments (2)
- [Abstract] Abstract: the phrase 'establishes rigorous baselines' would benefit from a brief parenthetical note on the number of LLMs evaluated or the scale of the reported results to convey the extent of the empirical component.
- [Benchmark Construction] The manuscript should ensure that the description of the mutation process for creating buggy RTL variants includes explicit details on the mutation operators and coverage of common bug types to strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the benchmark's contributions, and recommendation for minor revision. We appreciate the acknowledgment of the realistic inputs, dual settings, and open-source aspects as strengths.
Circularity Check
No significant circularity detected
full rationale
This is a benchmark-construction paper whose central contribution is the definition and release of AssertLLM2 (83 designs, structured specs, golden RTL, mutated buggy variants, and four evaluation axes). No derivation chain, fitted parameters, or predictive claims exist that could reduce to the paper's own inputs by construction. The sole novelty statement is explicitly qualified ('to the best of our knowledge') and does not rely on self-citation load-bearing or uniqueness theorems imported from prior author work. The evaluation framework is described directly from the benchmark elements without any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llm-assisted circuit verification: A comprehensive survey,
H. Liu, Y. Lu, M. Wang, X. Yao, and B. Yu, “Llm-assisted circuit verification: A comprehensive survey, ” in2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC), 2026
2026
-
[2]
A survey on assertion-based hardware verification,
H. Witharana, Y. Lyu, S. Charles, and P. Mishra, “A survey on assertion-based hardware verification, ”ACM Computing Surveys (CSUR), 2022
2022
-
[3]
Assertion-based verification: Industry myths to realities (invited tuto- rial),
H. Foster, “Assertion-based verification: Industry myths to realities (invited tuto- rial), ” inInternational Conference on Computer Aided Verification, 2008
2008
-
[4]
F. Wu, E. Pan, R. Kande, M. Quinn, A. Tyagi, D. K. Houngninou, J. Rajendran, and J. Hu, “Spec2assertion: Automatic pre-rtl assertion generation using large language models with progressive regularization, ”arXiv preprint arXiv:2505.07995, 2025
-
[5]
ChatSVA: Bridging SVA Generation for Hardware Verification via Task-Specific LLMs
L. T. Fu, J. Zhou, S. Ren, M. Zhang, J. Xiong, H. Jiang, N. Guan, X. Wang, and J. Yang, “Chatsva: Bridging sva generation for hardware verification via task-specific llms, ” arXiv preprint arXiv:2604.02811, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Assertcoder: Llm-based assertion gen- eration via multimodal specification extraction,
E. Tian, Y. Ci, Q. Yang, Y. Li, and Z. Lyu, “Assertcoder: Llm-based assertion gen- eration via multimodal specification extraction, ”arXiv preprint arXiv:2507.10338, 2025
-
[7]
Assertionforge: Enhancing formal verification assertion generation with structured representation of specifications and rtl,
Y. Bai, G. B. Hamad, S. Suhaib, and H. Ren, “Assertionforge: Enhancing formal verification assertion generation with structured representation of specifications and rtl, ” in2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025
2025
-
[8]
Assertgen: En- hancement of llm-aided assertion generation through cross-layer signal bridging,
H. Lyu, Y. Wang, Y. Du, M. Shi, Z. Chao, W. Li, T. Wang, and H. Li, “Assertgen: En- hancement of llm-aided assertion generation through cross-layer signal bridging, ” arXiv preprint arXiv:2509.23674, 2025
-
[9]
Assertminer: Module-level spec generation and assertion mining using static analysis guided llms,
H. Lyu, Y. Wang, J. Zhou, Z. Chao, T. Wang, and H. Li, “Assertminer: Module-level spec generation and assertion mining using static analysis guided llms, ” in2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC), 2026
2026
-
[10]
Assertfix: Empowering automated assertion fix via large language models,
H. Lyu, Y. Du, Y. Wang, Z. Chao, T. Wang, and H. Li, “Assertfix: Empowering automated assertion fix via large language models, ”arXiv preprint arXiv:2509.23972, 2025
-
[11]
Chiraag: Chatgpt informed rapid and automated assertion generation,
B. Mali, K. Maddala, V. Gupta, S. Reddy, C. Karfa, and R. Karri, “Chiraag: Chatgpt informed rapid and automated assertion generation, ” in2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), 2024
2024
-
[12]
Automated verilog assertion generation using fine-tuned llms with subtask-specific iterative prompt- ing,
M. Shahidzadeh, B. Ghavami, S. J. Wilton, and L. Shannon, “Automated verilog assertion generation using fine-tuned llms with subtask-specific iterative prompt- ing, ” in2025 26th International Symposium on Quality Electronic Design (ISQED), 2025
2025
-
[13]
Bridging rtl and assertion generation with large language models,
J. Thangellamudi and S. M. P. Dinakarrao, “Bridging rtl and assertion generation with large language models, ”IEEE Design & Test, 2026
2026
-
[14]
Enhancing large language models for hardware verification: A novel systemverilog assertion dataset,
A. Menon, S. Miftah, S. Kundu, S. Kundu, A. Srivastava, A. Raha, G. Sonnenschien, S. Banerjee, D. Mathaikutty, and K. Basu, “Enhancing large language models for hardware verification: A novel systemverilog assertion dataset, ”ACM Transactions on Design Automation of Electronic Systems, 2025
2025
-
[15]
Assertionbench: A benchmark to eval- uate large-language models for assertion generation,
V. Pulavarthi, D. Nandal, S. Dan, and D. Pal, “Assertionbench: A benchmark to eval- uate large-language models for assertion generation, ” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025
2025
-
[16]
Fveval: Understanding language model capabilities in formal verification of digital hardware,
M. Kang, M. Liu, G. B. Hamad, S. M. Suhaib, and H. Ren, “Fveval: Understanding language model capabilities in formal verification of digital hardware, ” in2025 Design, Automation & Test in Europe Conference (DATE), 2025
2025
-
[17]
N. Pinckney, C. Deng, C.-T. Ho, Y.-D. Tsai, M. Liu, W. Zhou, B. Khailany, and H. Ren, “Comprehensive verilog design problems: A next-generation benchmark dataset for evaluating large language models and agents on rtl design and verification, ” arXiv preprint arXiv:2506.14074, 2025
-
[18]
W. Fang, M. Li, M. Li, Z. Yan, S. Liu, Z. Xie, and H. Zhang, “Assertllm: Generating and evaluating hardware verification assertions from design specifications via multi-llms, ”arXiv preprint arXiv:2402.00386, 2024
-
[19]
Detecting defects in software requirements specification,
A. A. Alshazly, A. M. Elfatatry, and M. S. Abougabal, “Detecting defects in software requirements specification, ”Alexandria Engineering Journal, 2014
2014
-
[20]
Natural language is not enough: Benchmarking multi-modal generative ai for verilog generation,
K. Chang, Z. Chen, Y. Zhou, W. Zhu, K. Wang, H. Xu, C. Li, M. Wang, S. Liang, H. Li et al., “Natural language is not enough: Benchmarking multi-modal generative ai for verilog generation, ” inProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024
2024
-
[21]
FreeCores,
FreeCores, “FreeCores, ” https://github.com/orgs/freecores
-
[22]
Hummingbirdv2 E203 Core and SoC,
riscv-mcu, “Hummingbirdv2 E203 Core and SoC, ” https://github.com/riscv-mcu/ e203_hbirdv2
-
[23]
OpenCores,
OpenCores, “OpenCores, ” https://opencores.org/
-
[24]
VexRiscv: A FPGA friendly 32 bit RISC-V CPU implementation,
SpinalHDL, “VexRiscv: A FPGA friendly 32 bit RISC-V CPU implementation, ” https://github.com/SpinalHDL/VexRiscv
-
[25]
Cadence Design Systems, Inc.,JasperGold Apps User’s Guide, Cadence Design Systems, Inc., Sep. 2015
2015
-
[26]
Mantra: Mutation testing of hardware design code based on real bugs,
J. Wu, Y. Lei, Z. Zhang, X. Meng, D. Yang, P. Li, J. He, and X. Mao, “Mantra: Mutation testing of hardware design code based on real bugs, ” in2023 60th ACM/IEEE Design Automation Conference (DAC), 2023
2023
-
[27]
Pyverilog: A python-based hardware design processing toolkit for verilog hdl,
S. Takamaeda-Yamazaki, “Pyverilog: A python-based hardware design processing toolkit for verilog hdl, ” inInternational Symposium on Applied Reconfigurable Computing, 2015
2015
-
[28]
Cadence Design Systems, Inc.,Conformal Equivalence Checking User Guide, Ca- dence Design Systems, Inc., Oct. 2021
2021
-
[29]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, ”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Claude sonnet 4.5 system card,
Anthropic, “Claude sonnet 4.5 system card, ” Anthropic, Tech. Rep., 2025
2025
-
[31]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, El-Kishkyet al., “Openai gpt-5 system card, ”arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong et al., “Deepseek-v3.2: Pushing the frontier of open large language models, ”arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Qwen3-Coder-Next Technical Report
R. Cao, M. Chen, J. Chen, Z. Cui, Y. Feng, B. Hui, Y. Jing, K. Li, M. Li, J. Linet al., “Qwen3-coder-next technical report, ”arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Meta, “The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. ” [Online]. Available: https://ai.meta.com/blog/llama-4-multimodal- intelligence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.