GE-Sim 2.0: A Roadmap Towards Comprehensive Closed-loop Video World Simulators for Robotic Manipulation
Pith reviewed 2026-06-29 17:20 UTC · model grok-4.3
The pith
GE-Sim 2.0 builds a closed-loop video simulator that trains robotic policies transferable to physical hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
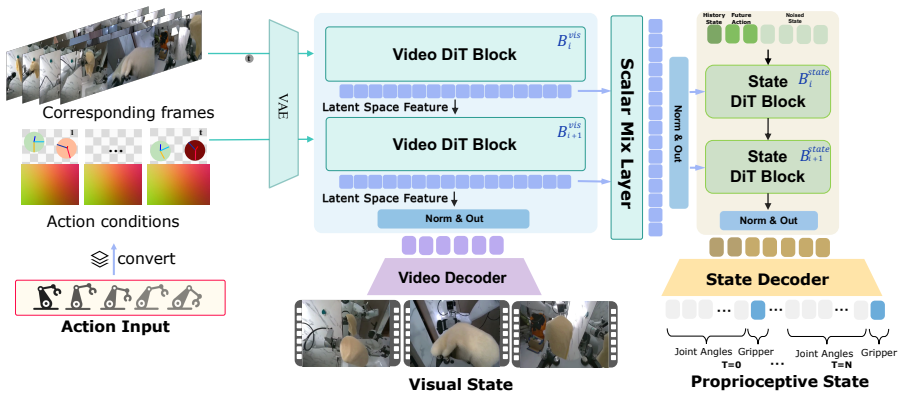
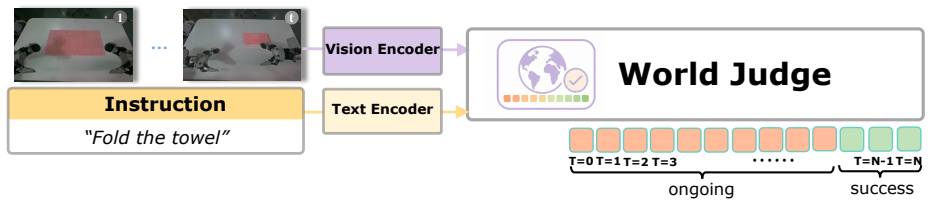
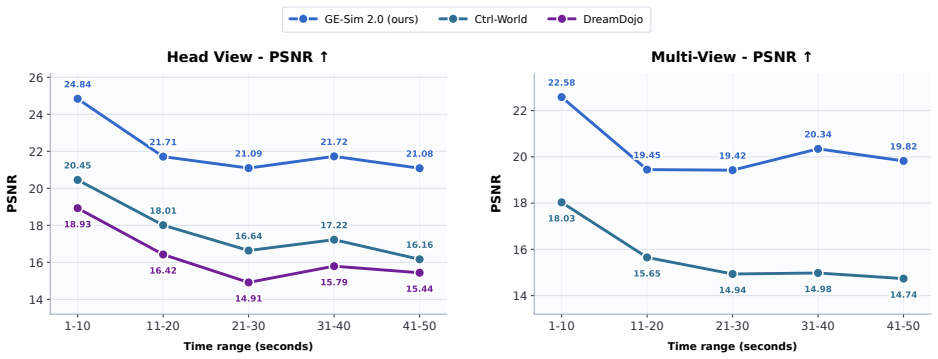
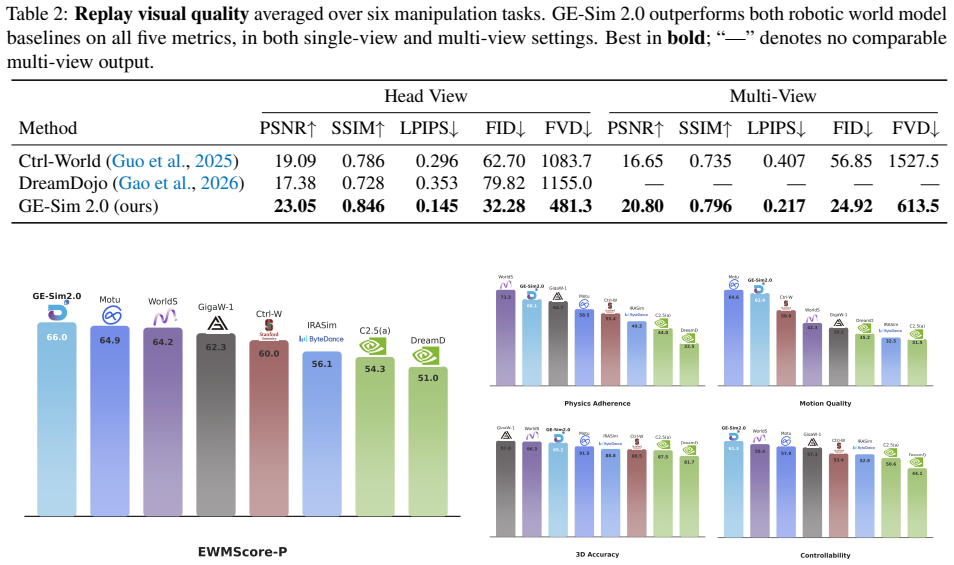
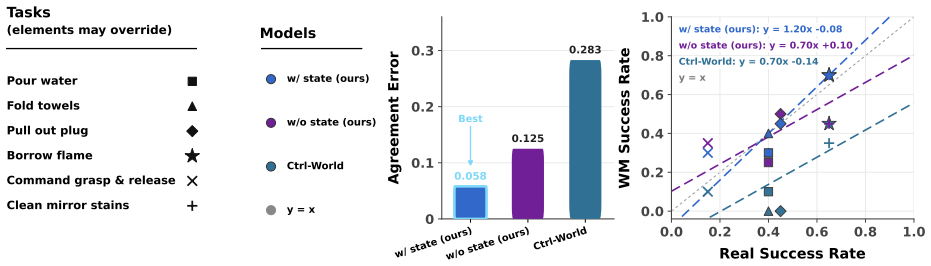
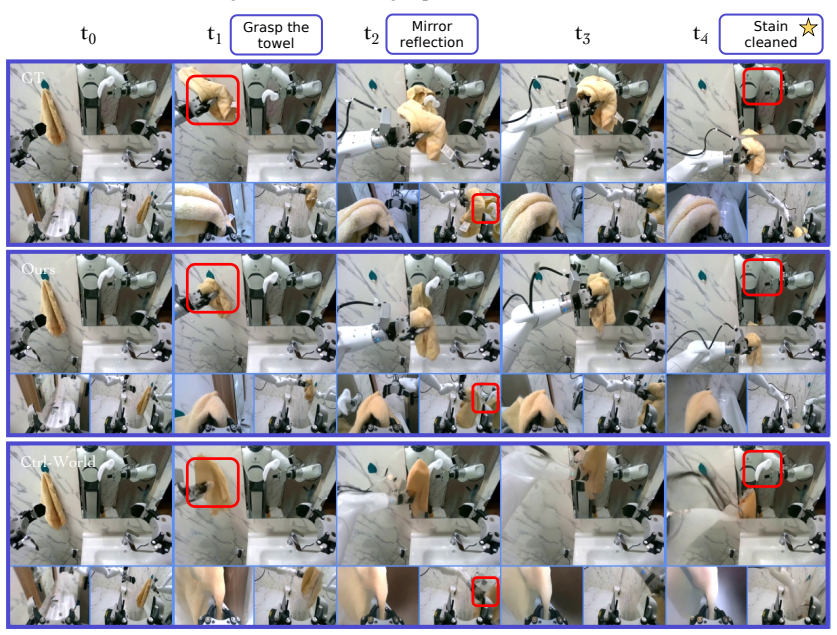
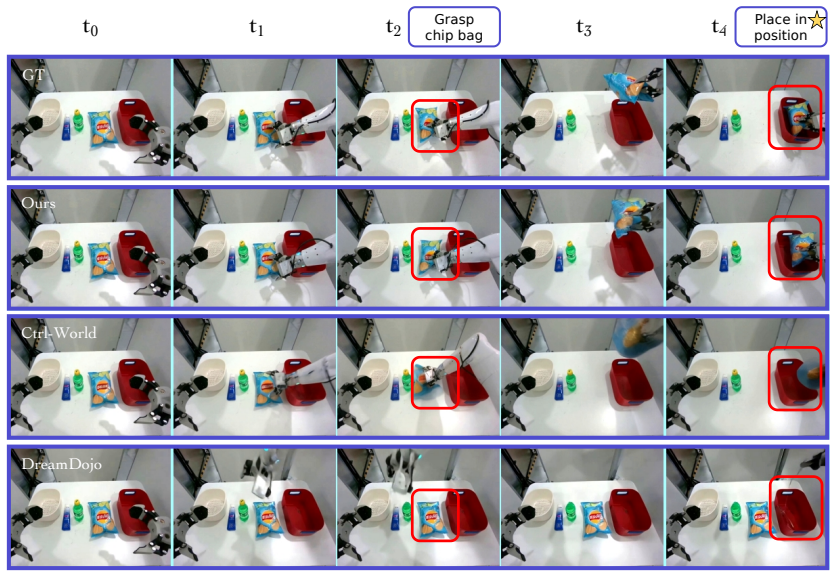
GE-Sim 2.0 extends an action-conditioned video generation base by retraining on large-scale robot interaction data and adding a state expert for decoding proprioceptive state from video latents, a world judge for producing verifiable success signals and rewards, and an acceleration framework that generates 25-frame rollouts in 2.3 seconds with optional frame skipping; the resulting simulator ranks first on the public WorldArena leaderboard at 2B parameters and supports closed-loop policy training whose outputs transfer to measurable real-robot performance gains.
What carries the argument
The three added modules (state expert decoding proprioceptive state from video latents, world judge scoring rollouts against instructions, and acceleration framework for fast inference) that turn video generation into a closed-loop training and evaluation platform.
If this is right
- Policies trained on GE-Sim 2.0 rollouts and rewards achieve measurable gains when transferred to physical robots.
- The simulator ranks first on the WorldArena leaderboard while using only 2B parameters and beating both dedicated robotic world models and closed-source video generators.
- Machine-verifiable success signals from the world judge replace manual inspection for scalable evaluation.
- The acceleration framework supports 25-frame rollouts in 2.3 seconds on one H100 with up to 4x frame skipping for long-horizon tasks.
Where Pith is reading between the lines
- The closed-loop structure could let researchers iterate manipulation policies many times in simulation before any hardware trial.
- State decoding from video latents may reduce reliance on separate proprioceptive sensors during policy execution.
- The same judge-and-reward loop could be adapted to other video-based simulators in domains such as navigation or assembly.
Load-bearing premise
The three new modules together produce generated videos whose success signals and state estimates are sufficiently accurate to support policy transfer to physical robots without additional real-world verification.
What would settle it
A side-by-side deployment test measuring whether policies trained only on GE-Sim 2.0 rewards and states achieve statistically equivalent success rates on physical robots as policies trained on ground-truth real-world rewards.
Figures














read the original abstract
We introduce GE-Sim 2.0 (Genie Envisioner World Simulator 2.0), a closed-loop video world simulator for robotic manipulation. Building on the action-conditioned video generation framework of Genie Envisioner, GE-Sim 2.0 is re-trained on thousands of hours of real-world robot data spanning teleoperation, contact-rich interaction, and on-robot policy deployment, substantially improving action-following fidelity and trajectory coverage. On top of this foundation, three new modules close the loop from video simulation to policy learning: a state expert that decodes proprioceptive state from video latents to support next-chunk prediction by downstream VLA policies; a world judge that scores generated rollouts against task instructions, yielding machine-verifiable success signals and rewards in place of manual inspection; and an acceleration framework that delivers a 25-frame rollout in 2.3 seconds on a single H100, with up to 4* frame skipping at inference for long-horizon evaluation. GE-Sim 2.0 tops the public WorldArena leaderboard at only 2B parameters, outperforming both dedicated robotic world models and closed-source general video generators, and policies trained against its rollouts and rewards translate into measurable real-world gains, establishing GE-Sim 2.0 as a practical platform for scalable evaluation and closed-loop learning of manipulation policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GE-Sim 2.0, a closed-loop video world simulator for robotic manipulation built on the action-conditioned Genie Envisioner framework. It is re-trained on thousands of hours of real-world robot data (teleoperation, contact-rich interaction, policy deployment) and augments the base model with three modules: a state expert that decodes proprioceptive state from video latents, a world judge that scores generated rollouts against task instructions to produce machine-verifiable rewards, and an acceleration framework achieving 25-frame rollouts in 2.3 s on one H100 with optional frame skipping. The paper claims that the resulting 2B-parameter model tops the public WorldArena leaderboard, outperforming both dedicated robotic world models and closed-source video generators, and that policies trained on its simulated rollouts and rewards yield measurable real-world gains.
Significance. If the performance and transfer results are substantiated, the work would represent a meaningful step toward practical, scalable closed-loop simulators for manipulation policy learning and evaluation. The combination of modest parameter count, real-robot training data, and explicit modules for state estimation and automated success scoring could reduce dependence on manual inspection and real-world rollouts, provided the generated videos supply sufficiently accurate signals for downstream VLA training.
major comments (1)
- Abstract: the central claims of leaderboard superiority and real-world policy transfer rest on the accuracy of the state-expert and world-judge modules, yet the manuscript supplies no methods, datasets, error bars, ablation studies, or evaluation protocols that would allow verification of these modules' outputs or the transfer results.
Simulated Author's Rebuttal
We thank the referee for the review and for identifying the need for stronger verification of the state-expert and world-judge modules. We address the single major comment below and commit to revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: Abstract: the central claims of leaderboard superiority and real-world policy transfer rest on the accuracy of the state-expert and world-judge modules, yet the manuscript supplies no methods, datasets, error bars, ablation studies, or evaluation protocols that would allow verification of these modules' outputs or the transfer results.
Authors: We agree that the current manuscript text does not supply sufficient methods, datasets, error bars, ablation studies, or evaluation protocols to fully verify the state-expert and world-judge outputs or the transfer results. The abstract and main sections describe the modules at a high level (state expert as a latent decoder trained on paired video-proprioception data; world judge as an instruction-conditioned scorer) and report leaderboard and transfer outcomes, but lack the requested quantitative details. We will revise the manuscript to add: (1) explicit training datasets and splits for each module, (2) error bars from multiple evaluation runs, (3) ablation studies isolating module contributions to leaderboard and transfer performance, and (4) a dedicated evaluation protocol subsection. These additions will be placed in the methods and experiments sections. revision_made will be yes. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, or first-principles claims that could reduce to inputs by construction. The work introduces three new modules (state expert, world judge, acceleration framework) on top of a retrained video generation base and reports empirical leaderboard performance plus real-world transfer results. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations are visible. The central claims rest on external benchmarks and measured transfer gains rather than any internal reduction to the model's own fitted values or prior author results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar.org/CorpusID: 3532908. O. Bar-Tal, H. Chefer, O. Tov, C. Herrmann, R. Paiss, S. Zada, A. Ephrat, J. Hur, Y . Li, T. Michaeli, O. Wang, D. Sun, T. Dekel, and I. Mosseri. Lumiere: A space-time diffusion model for video generation.SIGGRAPH Asia 2024 Conference Papers,
2024
-
[2]
URL https://api.semanticscholar.org/CorpusID:267095113. K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Blattmann, R
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis. Align your latents: High-resolution video synthesis with latent diffusion models.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22563–22575,
2023
-
[4]
URLhttps://api.semanticscholar.org/CorpusID:258187553. 17 A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023.URL https://arxiv. org/abs/2307.15818, 1:2,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Y . Chen et al. Abot-physworld: Interactive world foundation model for robotic manipulation with physics alignment.arXiv preprint arXiv:2603.23376,
-
[7]
AMAP CV Lab. D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, Q. Ma, S. Nah, L. Magne, J. Xiang, Y . Xie, R. Zheng, D. Niu, Y . L. Tan, K. R. Zentner, G. Kurian, S. Indupuru, P. Jannaty, J. Gu, J. Zhang, J. Malik, P. Abbeel, M.-Y . Liu, Y . Zhu, J. Jang, and L. Fan. Dreamdojo: A generalist robot world model from large-scale ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gen-0: Embodied foundation models that scale with physical interaction
Generalist AI Team. Gen-0: Embodied foundation models that scale with physical interaction. https://generalistai.com/blo g/nov-04-2025-GEN-0, November
2025
-
[10]
Blog post. GigaWorld Team, A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, J. Zhu, K. Li, M. Xu, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861,
-
[11]
googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf
URL https://storage. googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf. J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. Maniskill2: A unified benchmark for generalizable manipulation skills.ArXiv, abs/2302.04659,
-
[12]
URL https: //api.semanticscholar.org/CorpusID:256697500. Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125,
work page internal anchor Pith review Pith/arXiv arXiv
- [13]
-
[14]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, L. Chen, S. Yan, M. Yao, and G. Ren. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635,
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.ArXiv, abs/2505.18719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URL https://api.semanticscholar.org/CorpusID: 278904856. V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State. Isaac gym: High performance gpu-based physics simulation for robot learning.ArXiv, abs/2108.10470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, N. Agarwal, A. Ali, M. Bala, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Y . Shang, Z. Li, Y . Ma, W. Su, X. Jin, Z. Wang, L. Jin, X. Zhang, Y . Tang, H. Su, C. Gao, W. Wu, X. Liu, D. Shah, Z. Zhang, Z. Chen, J. Zhu, Y . Tian, T.-S. Chua, W. Zhu, and Y . Li. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971,
-
[22]
Make-A-Video: Text-to-Video Generation without Text-Video Data
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafni, D. Parikh, S. Gupta, and Y . Taigman. Make-a-video: Text-to-video generation without text-video data.ArXiv, abs/2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
URL https://api.semanticscholar.org/CorpusID:287915787. O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
R. Villegas, M. Babaeizadeh, P.-J. Kindermans, H. Moraldo, H. Zhang, M. T. Saffar, S. Castro, J. Kunze, and D. Erhan. Phenaki: Variable length video generation from open domain textual description.ArXiv, abs/2210.02399,
work page internal anchor Pith review Pith/arXiv arXiv
- [25]
-
[26]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, B. H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su. Sapien: A simulated part-based interactive environment.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11094–11104,
2020
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.