Eliot: Interactively underline{E}xploring Fast-Changing Scientific underline{Li}terature Trends with underline{O}nline Daunderline{t}a and Learning
Pith reviewed 2026-06-29 15:27 UTC · model grok-4.3
The pith
Eliot retrieves arXiv papers on demand, clusters them into themes, and displays year-by-year distributions to make literature trends traceable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
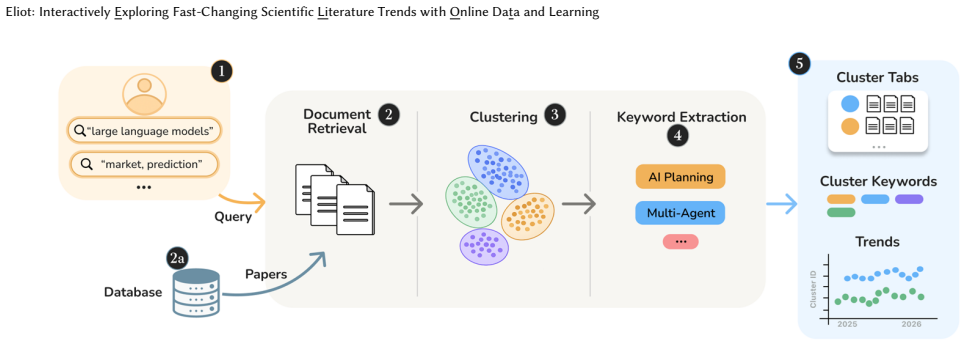
Eliot shows that query-time retrieval followed by embedding-based clustering and temporal visualization can produce interpretable themes and trend views for any arXiv search without relying on hand-crafted taxonomies or fixed scripts, with the chosen pipeline of MiniLM embeddings, UMAP, and agglomerative clustering performing adequately across domains in offline tests and receiving positive interpretability ratings from users.
What carries the argument
The query-time clustering pipeline that embeds titles and abstracts with MiniLM, reduces to 10 dimensions with UMAP, applies agglomerative clustering, extracts keywords per cluster, and renders publication-year histograms for each cluster.
Load-bearing premise
That good scores on offline clustering metrics and high ratings in scenario surveys will translate into actual usefulness when researchers use the system for their own open-ended literature questions.
What would settle it
A study in which domain experts perform the same literature-trend task once with Eliot and once with standard search tools, then compare the accuracy and completeness of the trends they identify.
Figures

read the original abstract
The rapid growth of scientific publishing has made it increasingly difficult to track how fast-moving areas evolve. Search engines and LLM-based assistants retrieve or summarize papers, but often hide how the corpus was selected, organized, or connected to temporal patterns. We present $\texttt{Eliot}$, a publicly deployed interactive system for traceable exploration of evolving scientific literature. Motivated by two studies on Large Language Models (LLMs) and Automated Planning and Scheduling (APS), $\texttt{Eliot}$ generalizes literature-evolution analysis beyond hand-built taxonomies and domain-specific scripts. Given explicit query terms and filters, it retrieves arXiv papers at query time, represents each paper by title and abstract, clusters the corpus into themes, assigns representative keywords, and visualizes each cluster's publication-year distribution. We evaluate $\texttt{Eliot}$ as both an applied system and an interactive research aid. An offline configuration study across eight arXiv domains compares document representations, dimensionality reduction methods, and clustering algorithms using intrinsic clustering and topic-coherence metrics; the results support MiniLM embeddings with 10-dimensional UMAP and Agglomerative Clustering as a practical default. A scenario-based survey and expert focus group assess interpretability and use contexts: participants rated cluster labels as meaningful in 85% of scenario responses, and feedback indicated that $\texttt{Eliot}$ is most valuable for auditable overviews of rapidly changing technical areas. These results suggest that query-time clustering and temporal inspection can complement search and generation tools by helping researchers inspect and refine the evidence behind literature trends.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Eliot, a publicly deployed interactive system for traceable exploration of evolving scientific literature. Given user query terms and filters, it retrieves arXiv papers at query time, represents papers by title and abstract, clusters the corpus into themes, assigns representative keywords, and visualizes each cluster's publication-year distribution. An offline configuration study across eight arXiv domains compares document representations, dimensionality reduction, and clustering algorithms using intrinsic metrics and selects MiniLM embeddings with 10-dimensional UMAP and Agglomerative Clustering as a practical default. A scenario-based survey and expert focus group report that participants rated cluster labels as meaningful in 85% of responses and indicate value for auditable overviews of rapidly changing areas.
Significance. If the evaluation holds, the work provides a generalizable, query-time alternative to hand-built taxonomies or domain-specific scripts for literature-evolution analysis. The offline comparison supplies concrete evidence for a default pipeline, and the human evaluation suggests practical utility for inspecting temporal patterns in fast-moving fields, complementing search and generation tools.
major comments (2)
- [Offline configuration study and human evaluation] Offline configuration study: the pipeline is designated the practical default solely on the basis of intrinsic clustering and topic-coherence metrics across eight domains. The subsequent human scenario survey (85% meaningful labels) and focus group are performed exclusively on this single selected configuration; no ablation compares human interpretability ratings across alternative representation/reduction/clustering choices, and no correlation is reported between the metric scores and the human judgments. This leaves the central claim that the metric-chosen default is reliable for user-facing interpretability resting on an untested proxy assumption.
- [Human evaluation / scenario-based survey] Scenario-based survey: the abstract and evaluation section report concrete numbers (85% meaningful labels) but supply no details on participant count, exact definitions of 'meaningful', statistical tests, scenario construction, or potential confounds. These omissions prevent assessment of the robustness and generalizability of the human evaluation results.
minor comments (1)
- [Introduction / motivation] The motivation paragraph references 'two studies on LLMs and APS' but does not indicate how their specific findings shaped the system architecture or evaluation design.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, providing clarification on our evaluation design while committing to revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: Offline configuration study: the pipeline is designated the practical default solely on the basis of intrinsic clustering and topic-coherence metrics across eight domains. The subsequent human scenario survey (85% meaningful labels) and focus group are performed exclusively on this single selected configuration; no ablation compares human interpretability ratings across alternative representation/reduction/clustering choices, and no correlation is reported between the metric scores and the human judgments. This leaves the central claim that the metric-chosen default is reliable for user-facing interpretability resting on an untested proxy assumption.
Authors: Intrinsic metrics such as topic coherence are established proxies for human interpretability in the clustering and topic modeling literature, with prior studies demonstrating their correlation to human judgments across domains. Our offline study across eight arXiv domains was intended to identify a practical, generalizable default pipeline rather than to validate the metrics themselves. The human evaluation then confirmed the utility of the deployed system. We acknowledge that an explicit correlation analysis or human ablation would further strengthen the proxy link; in revision we will add a dedicated discussion section citing supporting literature on metric validity and noting this as a limitation, along with any post-hoc analysis feasible from collected data. Full human ablations across configurations remain outside the current scope due to participant recruitment costs. revision: partial
-
Referee: Scenario-based survey: the abstract and evaluation section report concrete numbers (85% meaningful labels) but supply no details on participant count, exact definitions of 'meaningful', statistical tests, scenario construction, or potential confounds. These omissions prevent assessment of the robustness and generalizability of the human evaluation results.
Authors: We will revise the human evaluation section to include the exact participant counts for both the scenario-based survey and expert focus group, the operational definition of 'meaningful' used in the rating protocol, the statistical tests applied to the reported percentages, a description of scenario construction and selection criteria, and an explicit discussion of potential confounds such as participant expertise or interface effects. These details were condensed for the initial submission but are documented in our study materials and will be reported in full to enable assessment of robustness and generalizability. revision: yes
Circularity Check
No significant circularity; empirical configuration study is independent of target claims
full rationale
The paper presents an implemented interactive system whose pipeline default is chosen via an explicit offline comparison across eight domains using intrinsic clustering and topic-coherence metrics; a separate scenario survey then rates the selected configuration. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear. The central claims rest on reported empirical results rather than any reduction of outputs to inputs by construction, making the evaluation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. Scibert: a pretrained language model for scientific text. (2019). arXiv: 1903.10676. doi:10.48550/arXiv.1903. 10676
-
[3]
Bezdek, Robert Ehrlich, and William Full
James C. Bezdek, Robert Ehrlich, and William Full. 1984. Fcm: the fuzzy c- means clustering algorithm.Computers & Geosciences, 10, 2, 191–203. doi:https: //doi.org/10.1016/0098-3004(84)90020-7
-
[4]
Jagdev Bhogal, Andrew MacFarlane, and Peter Smith. 2007. A review of on- tology based query expansion.Information processing & management, 43, 4, 866–886
2007
-
[5]
Weizhen Bian, Siyan Liu, Yubo Zhou, Dezhi Chen, Yijie Liao, Zhenzhen Fan, and Aobo Wang. 2024. Intellectseeker: a personalized literature management system with the probabilistic model and large language model. InInternational Conference on Knowledge Science, Engineering and Management. Springer, 270– 282
2024
-
[6]
Tadeusz Caliński and Jerzy Harabasz. 1974. A dendrite method for cluster analysis.Communications in Statistics-theory and Methods, 3, 1, 1–27
1974
-
[7]
Chaomei Chen. 2006. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. en.Journal of the American Society for Information Science and Technology, 57, 3, (Feb. 2006), 359–377. doi:10.1002/ asi.20317
2006
-
[8]
Mohamed Cherradi and Anass El Haddadi. 2024. Exploration of Scientific Documents through Unsupervised Learning-Based Segmentation Techniques. Seminars in Medical Writing and Education, 3, (Apr. 2024), 68. doi:10.56294/ mw202468
2024
- [9]
-
[10]
David L Davies and Donald W Bouldin. 1979. A cluster separation measure. IEEE transactions on pattern analysis and machine intelligence, 2, 224–227
1979
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understand- ing. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Compu...
-
[12]
Elicit. 2026. Systematic literature reviews. Retrieved May 13, 2026 from https: //elicit.com/solutions/literature-review
2026
-
[13]
Google Scholar. 2025. Scholar Labs: an AI powered scholar search. (Nov. 18, 2025). Retrieved May 13, 2026 from https://scholar.googleblog.com/2025/11/ scholar-labs-ai-powered-scholar-search.html
2025
-
[14]
Maarten Grootendorst. 2022. BERTopic: Neural topic modeling with a class- based TF-IDF procedure. (2022). arXiv: 2203.05794. doi:10.48550/arXiv.2203. 05794
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203 2022
-
[15]
Hanson, Pablo Gómez Barreiro, Paolo Crosetto, and Dan Brockington
Mark A. Hanson, Pablo Gómez Barreiro, Paolo Crosetto, and Dan Brockington
-
[16]
en.Quantitative Science Studies, 5, 4, 823–843
The strain on scientific publishing. en.Quantitative Science Studies, 5, 4, 823–843. doi:10.1162/qss_a_00327
-
[17]
Thomas Hartke and Joshua Ramette. 2024. Benchmarking the undermind search assistant. Retrieved Oct. 10, 2024 from https://www.undermind.ai/static/ Undermind_whitepaper.pdf
2024
-
[18]
url: https://streamlit.io
[SW] Streamlit Inc., Streamlit: A faster way to build and share data apps 2019. url: https://streamlit.io
2019
-
[19]
Uri Katz, Mosh Levy, and Yoav Goldberg. 2024. Knowledge navigator: llm- guided browsing framework for exploratory search in scientific literature. In Findings of the Association for Computational Linguistics: EMNLP 2024, 8838– 8855
2024
- [20]
-
[21]
Litmaps. 2026. Litmaps for researchers. Retrieved May 13, 2026 from https: //www.litmaps.com/about/for-researchers
2026
-
[22]
Leland McInnes, John Healy, and James Melville. 2018. UMAP: Uniform Man- ifold Approximation and Projection for Dimension Reduction. (2018). arXiv: 1802.03426. doi:10.48550/arXiv.1802.03426
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.03426 2018
-
[23]
James B McQueen. 1967. Some methods of classification and analysis of mul- tivariate observations. InProc. of 5th Berkeley Symposium on Math. Stat. and Prob.281–297
1967
-
[24]
Melkamu Abay Mersha, Mesay Gemeda yigezu, and Jugal Kalita. 2024. Semantic- Driven Topic Modeling Using Transformer-Based Embeddings and Clustering Algorithms. (2024). arXiv: 2410.00134. doi:10.48550/arXiv.2410.00134
-
[25]
George A Miller. 1995. Wordnet: a lexical database for english.Communications of the ACM, 38, 11, 39–41
1995
-
[26]
Josh M Nicholson, Milo Mordaunt, Patrice Lopez, Ashish Uppala, Domenic Rosati, Neves P Rodrigues, Peter Grabitz, and Sean C Rife. 2021. Scite: a smart citation index that displays the context of citations and classifies their intent using deep learning.Quantitative science studies, 2, 3, 882–898
2021
-
[27]
openRxiv. 2026. medRxiv: the preprint server for health sciences. Accessed 2026-05-18. (2026). https://www.medrxiv.org/
2026
-
[28]
Vishal Pallagani, Nitin Gupta, Bharath Chandra Muppasani, and Biplav Srivas- tava. 2025. Revisiting llms in planning from literature review: a semi-automated analysis approach and evolving categories representing shifting perspectives. InProceedings of the International Conference on Automated Planning and Sched- ulingnumber 1. Vol. 35, 386–390
2025
-
[29]
Vishal Pallagani et al. 2024. On the prospects of incorporating large language models (llms) in automated planning and scheduling (aps). InProceedings of the International Conference on Automated Planning and Scheduling. Vol. 34, 432–444
2024
-
[30]
Barbara Probierz, Jan Kozak, and Anita Hrabia. 2022. Clustering of scientific articles using natural language processing. en.Procedia Computer Science, 207, 3449–3458. doi:10.1016/j.procs.2022.09.403
-
[31]
Shahzad Qaiser and Ramsha Ali. 2018. Text Mining: Use of TF-IDF to Exam- ine the Relevance of Words to Documents.International Journal of Computer Applications, 181, 1, (July 2018), 25–29. doi:10.5120/ijca2018917395
-
[32]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. en. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 3980–3990....
-
[33]
ResearchGate GmbH. 2026. ResearchGate. Professional network for scientists and researchers. Accessed 2026-05-18. (2026). https://www.researchgate.net/
2026
-
[34]
ResearchRabbit. 2026. ResearchRabbit: AI tool for smarter, faster literature reviews. Retrieved May 13, 2026 from https://www.researchrabbit.ai/
2026
-
[35]
Michael Röder, Andreas Both, and Alexander Hinneburg. 2015. Exploring the space of topic coherence measures. InProceedings of the eighth ACM interna- tional conference on Web search and data mining, 399–408
2015
-
[36]
Peter J Rousseeuw. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics, 20, 53–65
1987
-
[37]
Phillip Schneider and Florian Matthes. 2024. Conversational Exploratory Search of Scholarly Publications Using Knowledge Graphs. (2024). arXiv: 2410.00427. doi:10.48550/arXiv.2410.00427
-
[38]
[SW] Lukas Schwab, arxiv.py: Python Wrapper for the arXiv API 2026.url: https://pypi.org/project/arxiv/,vcs: https://github.com/lukasschwab/arxiv.py
2026
- [39]
-
[40]
Salimkan Fatma Taşkiran and Ersin Kaya. 2022. ACADEMIC TEXT CLUSTER- ING USING NATURAL LANGUAGE PROCESSING.Konya Journal of Engineer- ing Sciences, 10, (Dec. 2022), 41–51. doi:10.36306/konjes.1081213
-
[41]
Silvia Terragni, Elisabetta Fersini, Bruno Giovanni Galuzzi, Pietro Tropeano, and Antonio Candelieri. 2021. OCTIS: Comparing and Optimizing Topic models is Simple! en. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, Online, 263–...
-
[42]
Xuefeng Wang, Shuo Zhang, and Yuqin Liu. 2022. ITGInsight–discovering and visualizing research fronts in the scientific literature. en.Scientometrics, 127, 11, (Nov. 2022), 6509–6531. doi:10.1007/s11192-021-04190-9
-
[43]
Joe H Ward Jr. 1963. Hierarchical grouping to optimize an objective function. Journal of the American statistical association, 58, 301, 236–244
1963
-
[44]
Min-Hsien Weng, Shaoqun Wu, and Mark Dyer. 2022. Identification and Vi- sualization of Key Topics in Scientific Publications with Transformer-Based Language Models and Document Clustering Methods. en.Applied Sciences, 12, 21, (Nov. 2022), 11220. doi:10.3390/app122111220
-
[45]
Changhong Zhang, Zeyu Li, and Jiawan Zhang. 2018. A survey on visualization for scientific literature topics. en.Journal of Visualization, 21, 2, (Apr. 2018), 321–335. doi:10.1007/s12650-017-0462-2. Eliot: Interactively Exploring Fast-Changing Scientific Literature Trends with Online Data and Learning
-
[46]
Zhihua Zhang. 2015. The singular value decomposition, applications and be- yond.CoRR, abs/1510.08532. http://arxiv.org/abs/1510.08532 arXiv: 1510.08532
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[47]
[SW] Zubov, Roman, arxivql: arXiv Query Language and Tools 2026.url: https://pypi.org/project/arxivql/,vcs: https://github.com/romazu/arxivql
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.