Tensor Memory: Fixed-Size Recurrent State for Long-Horizon Transformers
Pith reviewed 2026-06-29 18:06 UTC · model grok-4.3
The pith
A fixed-size 3D memory tensor lets Transformers keep constant state capacity across arbitrarily long image or video sequences while retaining spatial structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
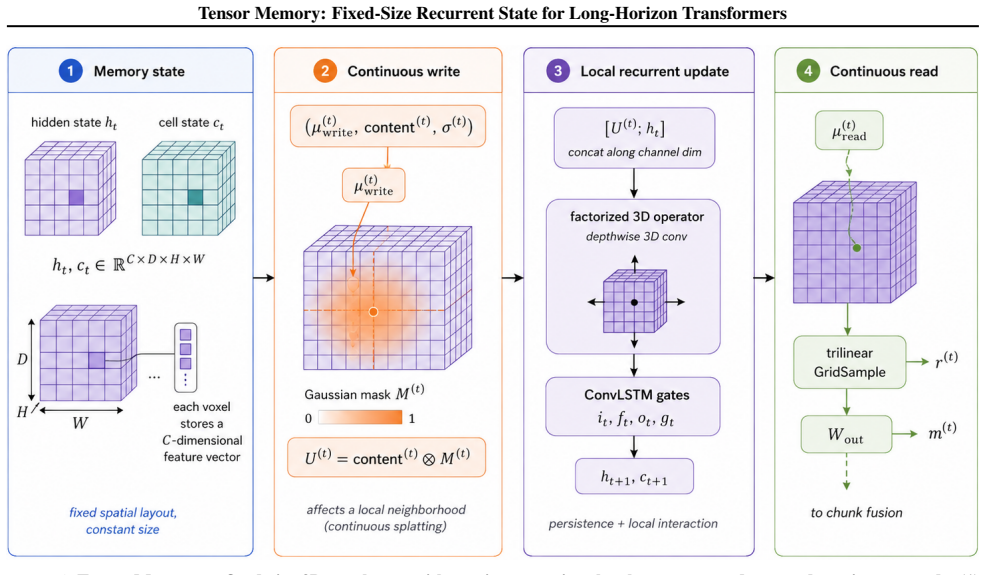
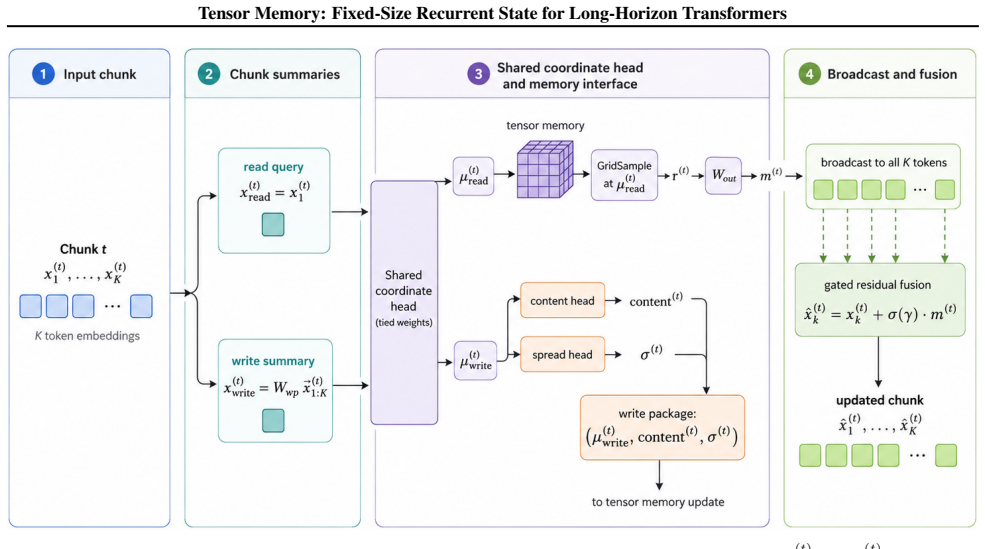
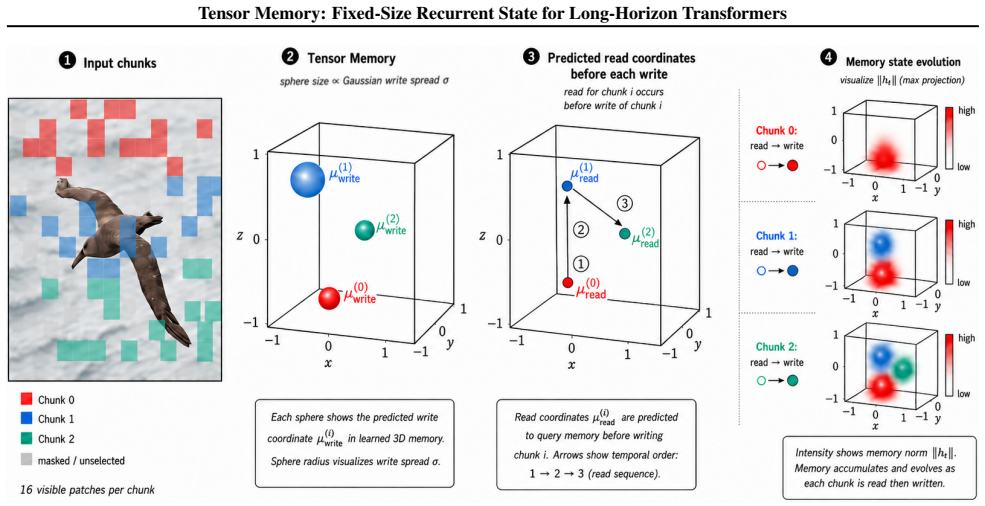
Tensor Memory augments Transformer blocks with a constant-size recurrent 3D memory tensor whose content is written by differentiable soft deposits of Gaussian volumes at predicted continuous 3D locations, updated by local interaction operators and gated recurrent dynamics, and read by continuous sampling with gated residual fusion; the fixed size therefore decouples state capacity from sequence length while preserving spatial inductive bias.
What carries the argument
The fixed-size recurrent 3D memory tensor that receives soft Gaussian-weighted writes at predicted continuous locations, applies local interaction and gated recurrence, and supplies context via continuous reads with residual fusion.
If this is right
- Memory footprint stays constant even when input sequences become arbitrarily long.
- The module can be inserted into or removed from standard Transformer blocks without altering other architecture or training code.
- Spatial inductive bias is retained because writes and reads operate on a 3D grid rather than a flat token list.
- The same module works for language, static images, and video without task-specific redesign.
Where Pith is reading between the lines
- The continuous 3D location prediction may allow the memory to represent objects that move smoothly between discrete voxel centers, something a fixed grid without soft writes would lose.
- Because reads use gated residual fusion, the memory can act as an optional spatial prior rather than a mandatory replacement for attention.
- The design could be tested on tasks that require explicit 3D world modeling, such as multi-view reconstruction from video, even though the paper evaluates only 2D benchmarks.
Load-bearing premise
That the soft Gaussian write combined with gated updates can keep the fixed 3D grid carrying useful spatial details across many time steps without quick loss or blurring.
What would settle it
Measure whether models using the module maintain higher accuracy than baseline Transformers on long video sequences that require tracking the same objects through repeated occlusions; equal or worse performance would falsify the claim of useful persistent spatial state.
Figures
read the original abstract
Transformers process images and videos by flattening space and time into long token sequences. While attention and KV caching preserve past features, their memory grows with sequence length and they lack an explicit, persistent spatial state, making long-horizon video understanding and occlusion-sensitive reasoning difficult. We propose Tensor Memory, a lightweight module that augments Transformer blocks with a fixed-size recurrent 3D memory tensor: tokens write into a voxel grid via a differentiable soft write that deposits content as a Gaussian-weighted volume around a predicted continuous 3D location, the memory is updated with an efficient local interaction operator and gated recurrent dynamics, and tokens read back context via continuous sampling with gated residual fusion. Because the memory tensor has a constant size, Tensor Memory decouples state capacity from input length while preserving a spatial inductive bias. We evaluate the module on standard language, image, and video benchmarks and on a controlled toy diagnostic suite designed to isolate when persistent state is beneficial; it integrates with standard Transformer training pipelines and can be attached to or removed from existing blocks without other architectural changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Tensor Memory, a module augmenting Transformer blocks with a fixed-size recurrent 3D memory tensor. Tokens perform differentiable soft writes that deposit content as Gaussian-weighted volumes around predicted continuous 3D locations into a voxel grid; the memory is updated via an efficient local interaction operator and gated recurrent dynamics; tokens read context via continuous sampling with gated residual fusion. The fixed tensor size decouples state capacity from input length while retaining a spatial inductive bias. The module is evaluated on language, image, and video benchmarks plus a controlled toy diagnostic suite for isolating persistent-state benefits, and integrates with standard training pipelines without other architectural changes.
Significance. The core architectural property—that a constant-size 3D tensor guarantees capacity independent of sequence length—is achieved by construction and directly addresses the stated limitations of growing KV caches and absent explicit spatial state. The toy diagnostic suite is a positive design choice for testing when persistent state matters. If the empirical results on the benchmarks confirm stable long-horizon retention without rapid degradation, the module would be a practical, attachable addition for video and long-context tasks.
minor comments (2)
- [Abstract] The abstract states that the module 'can be attached to or removed from existing blocks without other architectural changes,' but does not specify the exact insertion points or any required hyper-parameter retuning; a short paragraph in §3 or §4 clarifying this would improve reproducibility.
- [Abstract] Notation for the soft-write operator, local interaction, and gated dynamics is introduced in the abstract without symbols; defining them with consistent symbols in the methods section would aid readers.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of the fixed-size 3D memory property, and recommendation to accept.
Circularity Check
No significant circularity
full rationale
The paper's core statement that a fixed-size 3D memory tensor decouples capacity from sequence length follows directly from the explicit design choice of constant tensor size and is presented as a descriptive property of the module rather than a derived prediction or theorem. No equations, fitted parameters, self-citations, or uniqueness claims are invoked in the abstract or described architecture to support the claim; the spatial bias is likewise supplied by the voxel grid and continuous read/write operations by construction. The derivation chain is self-contained with no reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
AURA: Action-Gated Memory for Robot Policies at Constant VRAM
AURA-Mem uses an action-gated recurrent memory trained on closed-loop action error to deliver constant 4,224-byte state and 5-9x fewer writes than baselines while matching base policy success on LIBERO-Long.
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points.arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Is space-time attention all you need for video understanding?arXiv preprint arXiv:2102.05095,
Bertasius, G., Wang, H., and Torresani, L. Is space-time attention all you need for video understanding?arXiv preprint arXiv:2102.05095,
-
[4]
Improving language models by retrieving from trillions of tokens
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., van den Driessche, G., Lespiau, J.-B., Damoc, B., Clark, A., et al. Improving language models 8 Tensor Memory: Fixed-Size Recurrent State for Long-Horizon Transformers by retrieving from trillions of tokens.arXiv preprint arXiv:2112.04426,
work page internal anchor Pith review Pith/arXiv arXiv
- [5]
-
[6]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Cheng, X., Zeng, W., Dai, D., Chen, Q., Wang, B., Xie, Z., Huang, K., Yu, X., Hao, Z., Li, Y ., Zhang, H., Zhang, H., Zhao, D., and Liang, W. Conditional memory via scalable lookup: A new axis of sparsity for large language models. Technical Report arXiv:2601.07372, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Rethinking Attention with Performers
Choromanski, K., Likhosherstov, V ., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., Belanger, D., Colwell, L., and Weller, A. Rethinking attention with performers.arXiv preprint arXiv:2009.14794,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Dai, Z., Yang, Z., Yang, Y ., Carbonell, J., Le, Q. V ., and Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. Technical Report arXiv:1901.02860, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[9]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Dao, T., Fu, D. Y ., Ermon, S., Rudra, A., and R´e, C. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.arXiv preprint arXiv:2205.14135,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Fedus, W., Zoph, B., and Shazeer, N. Switch transform- ers: Scaling to trillion parameter models with simple and efficient sparsity.arXiv preprint arXiv:2101.03961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Graves, A., Wayne, G., and Danihelka, I. Neural turing ma- chines. Technical Report arXiv:1410.5401, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., and Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861,
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
-
[16]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Jaegle, A., Borgeaud, S., Alayrac, J.-B., Doersch, C., Ionescu, C., Ding, D., Koppula, S., Zoran, D., Brock, A., Shelhamer, E., H´enaff, O., Botvinick, M., Zisserman, A., Vinyals, O., and Carreira, J. Perceiver io: A general architecture for structured inputs & outputs. Technical Report arXiv:2107.14795, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Karami, M., Behrouz, A., Kacham, P., and Mirrokni, V . Trel- lis: Learning to compress key-value memory in attention models.arXiv preprint arXiv:2512.23852,
-
[18]
Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., and Lewis, M. Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172,
-
[19]
Reformer: The Efficient Transformer
Kitaev, N., Kaiser, L., and Levskaya, A. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[20]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, W., Li, Z., Zhuang, C., Sheng, Y ., Zheng, L., Yu, C., Gonzalez, J. E., and Stoica, I. Efficient memory management for large language model serving with page- dattention.arXiv preprint arXiv:2309.06180,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., K¨uttler, H., Lewis, M., Yih, W.-t., Stoy- anov, V ., and Riedel, S. Retrieval-augmented genera- tion for knowledge-intensive nlp tasks.arXiv preprint arXiv:2005.11401,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[22]
Liu, A. et al. Deepseek-v3 technical report. Technical Report arXiv:2412.19437, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Video swin transformer.arXiv preprint arXiv:2106.13230,
Liu, Z., Ning, J., Cao, Y ., Wei, Y ., Zhang, Z., Lin, S., and Hu, H. Video swin transformer.arXiv preprint arXiv:2106.13230,
-
[24]
Malhotra, A. and Seghouani, N. Neural field turing ma- chine: A differentiable spatial computer.arXiv preprint arXiv:2509.03370,
-
[25]
Pointer Sentinel Mixture Models
URL https: //arxiv.org/abs/1609.07843. Munkhdalai, T., Faruqui, M., and Gopal, S. Leave no con- text behind: Efficient infinite context transformers with infini-attention.arXiv preprint arXiv:2404.07143,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Neural Map: Structured Memory for Deep Reinforcement Learning
Parisotto, E. and Salakhutdinov, R. Neural map: Struc- tured memory for deep reinforcement learning. Technical Report arXiv:1702.08360, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Compressive Transformers for Long-Range Sequence Modelling
Rae, J. W., Potapenko, A., Jayakumar, S. M., and Lillicrap, T. P. Compressive transformers for long-range sequence modelling. Technical Report arXiv:1911.05507, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[28]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[29]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., and Hinton, G. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
Shi, X., Chen, Z., Wang, H., Yeung, D.-Y ., Wong, W.-k., and Woo, W.-c. Convolutional lstm network: A machine learning approach for precipitation nowcasting.arXiv preprint arXiv:1506.04214,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
DeepVoxels: Learning Persistent 3D Feature Embeddings
Sitzmann, V ., Thies, J., Heide, F., Nießner, M., Wetzstein, G., and Zollh¨ofer, M. Deepvoxels: Learning persistent 3d feature embeddings. Technical Report arXiv:1812.01024, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K., Zamir, A. R., and Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Sukhbaatar, S., Weston, J., Fergus, R., et al. End-to-end memory networks.arXiv preprint arXiv:1503.08895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and J ´egou, H. Training data-efficient image trans- formers & distillation through attention.arXiv preprint arXiv:2012.12877,
-
[35]
The caltech-ucsd birds-200-2011 dataset
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The caltech-ucsd birds-200-2011 dataset. Technical report, California Institute of Technology,
2011
-
[36]
Linformer: Self-Attention with Linear Complexity
Wang, S., Li, B. Z., Khabsa, M., Fang, H., and Ma, H. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[37]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Big Bird: Transformers for Longer Sequences
Zaheer, M., Guruganesh, G., Dubey, A., Ainslie, J., Alberti, C., Onta˜n´on, S., Pham, P., Ravula, A., Wang, Q., Yang, L., and Ahmed, A. Big bird: Transformers for longer sequences.arXiv preprint arXiv:2007.14062,
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[39]
Neural slam: Learning to explore with external memory
Zhang, J., Tai, L., Liu, M., Boedecker, J., and Burgard, W. Neural slam: Learning to explore with external memory. arXiv preprint arXiv:1706.09520,
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.