AURA: Action-Gated Memory for Robot Policies at Constant VRAM
Pith reviewed 2026-06-28 14:28 UTC · model grok-4.3
The pith
A learned action gate lets robot policies use constant memory by writing only when observations change the next action.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
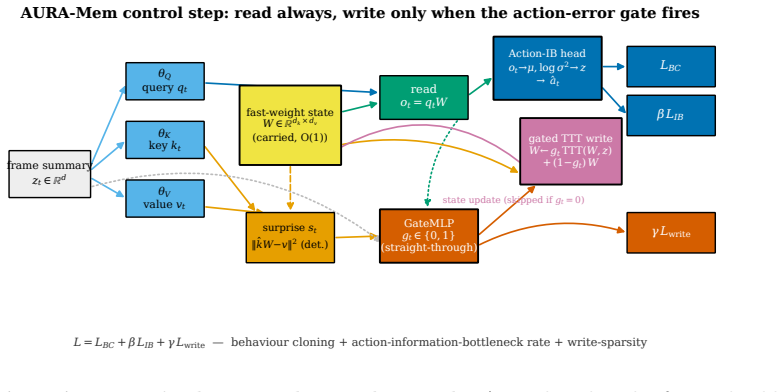
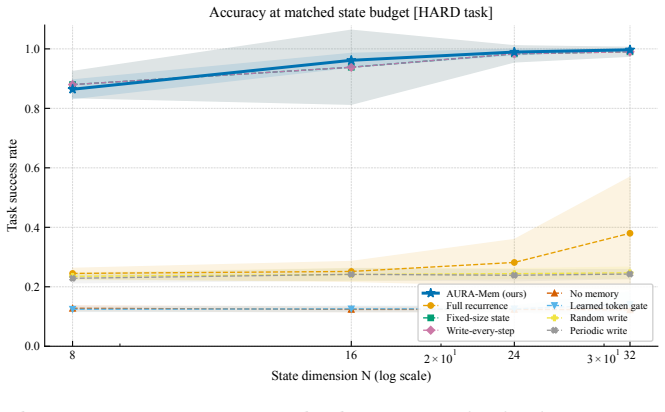
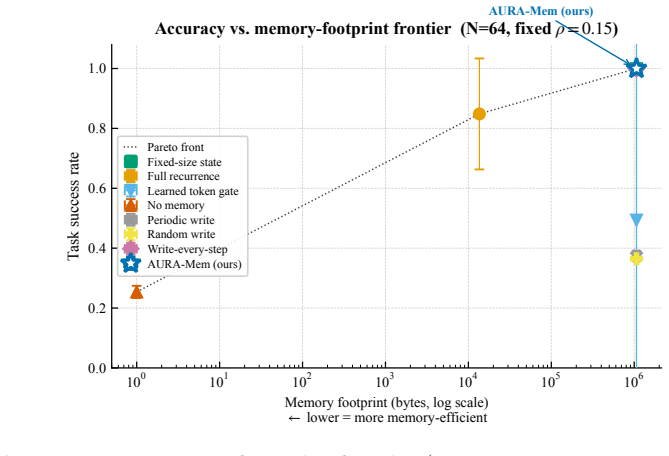
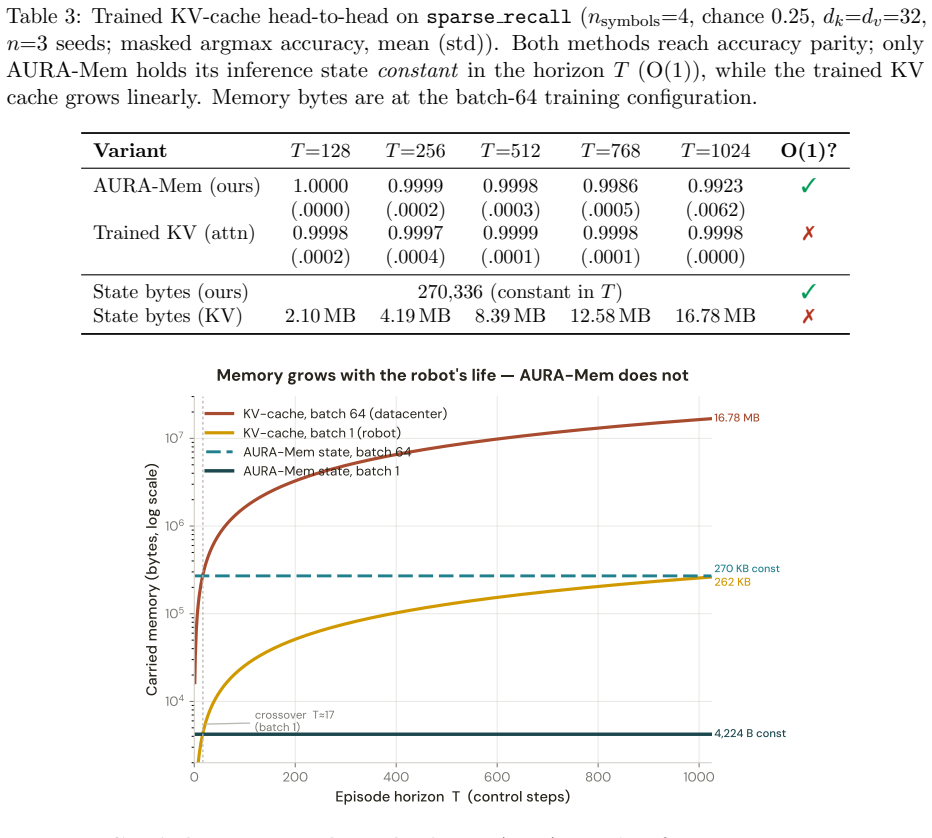
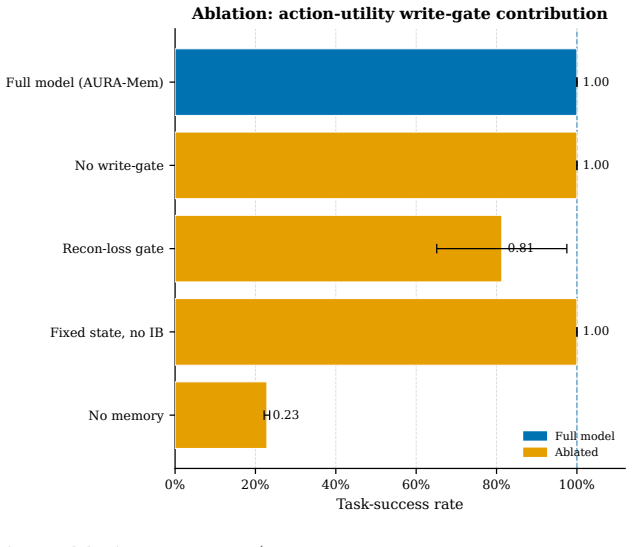
AURA-Mem is a constant-size recurrent memory with an action-utility gate that updates only on observations predicted to change the next action, trained directly against closed-loop action-error rather than reconstruction. On a synthetic benchmark it matches the accuracy of the best constant-memory baselines with five to nine times fewer writes. On the LIBERO-Long benchmark with a 7B OpenVLA-OFT policy it preserves the base success rate of 0.233 while using seven times fewer writes and fixed memory footprint.
What carries the argument
The action-surprise gate trained on closed-loop action-error that decides writes to a fixed 4,224-byte recurrent memory.
If this is right
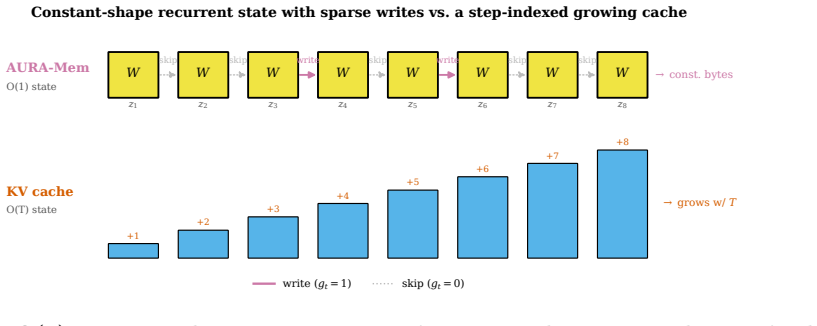
- Memory footprint remains fixed at 4,224 bytes for any episode length up to at least 100,000 steps.
- Success rate on LIBERO-Long stays at 0.233, matching the ungated policy and exceeding the always-write KV version at 0.217.
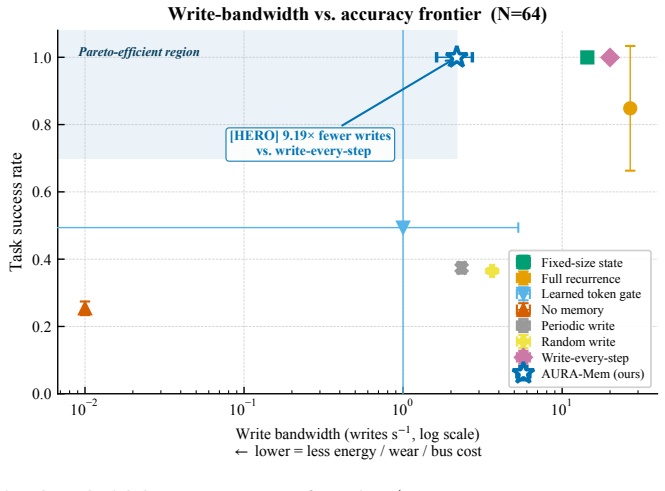
- Synthetic benchmark accuracy matches the best O(1) baseline while requiring 5.19 to 9.19 times fewer writes.
- Budget-matched random and periodic write schedules fail to match the performance of the action-surprise gate.
Where Pith is reading between the lines
- The gate may generalize to other long-running embodied agents where flash endurance limits total writes.
- Training the gate on action error rather than reconstruction could apply to other memory compression problems in sequential decision making.
- Constant memory enables deployment on hardware with strict VRAM constraints that growing caches cannot meet.
Load-bearing premise
That training the gate on closed-loop action-error signals will maintain policy performance when applied to new tasks and real robot episodes.
What would settle it
Running the AURA-Mem policy on a longer or different robot task where its success rate falls below the ungated baseline while memory stays constant.
Figures


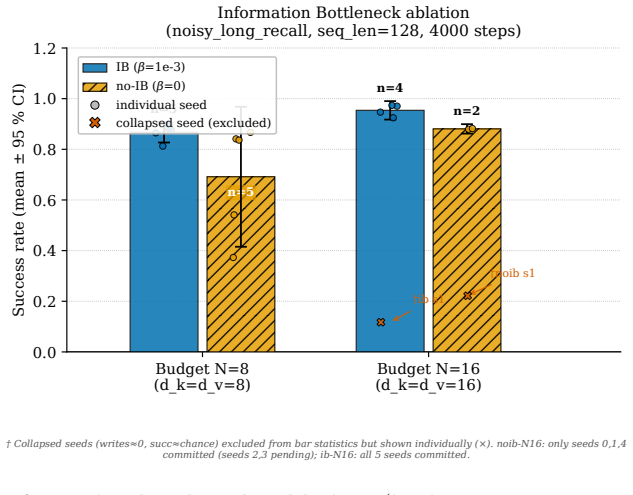
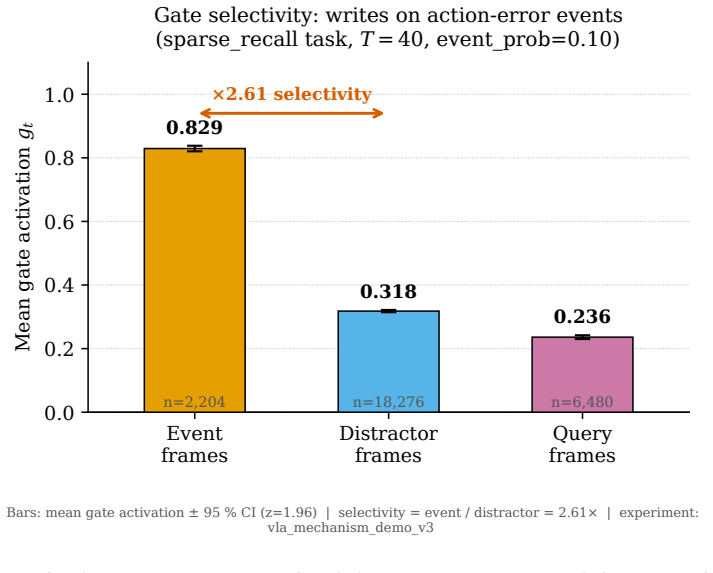


read the original abstract
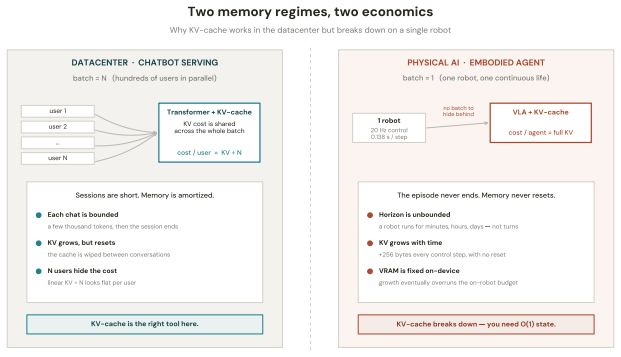
The KV-cache is the right memory for datacenters but the wrong memory for robots. Datacenter inference batches many short requests and resets them, amortizing an attention cache across a crowd. Embodied agents instead run one long, non-resetting episode on bandwidth-limited edge hardware, where high-bandwidth memory and flash are scarce, flash has finite write endurance, and memory writes rather than compute can become the binding constraint. AURA-Mem (Action-Utility Recurrent Adaptive Memory) targets this regime. It wraps a frozen vision-language-action backbone with a constant-size recurrent memory and a learned gate that writes only when the current observation would change the next action: memory that knows when to stay silent. Unlike reconstruction-based memory, the gate is trained directly against a closed-loop action-error signal. Its inference state is fixed at 4,224 bytes regardless of horizon, while a KV-cache grows to 6,061 times larger at 100,000 steps. On a controlled synthetic benchmark, AURA-Mem matches the best O(1) baseline in accuracy while using 5.19-6.13 times fewer writes, and up to 9.19 times fewer writes on easier configurations. Budget-matched random and periodic schedules do not recover this gain, isolating the benefit to the action-surprise signal. On a trained closed-loop OpenVLA-OFT 7B panel on LIBERO-Long (n=60 episodes per arm), the gate does not hurt success: AURA-Mem matches the ungated base policy (0.233) and slightly exceeds an always-write KV arm (0.217), while using 7.0 times fewer writes and constant memory. We also instantiate an approximate-information-state value-loss bound as a methodology demonstration; at this scale, the bound is vacuous rather than a guarantee.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AURA-Mem, a constant-size (4,224 bytes) recurrent memory wrapper around a frozen vision-language-action backbone. A learned gate writes to memory only when the current observation would change the next action, trained directly on a closed-loop action-error signal rather than reconstruction. On a synthetic benchmark it matches the best O(1) baseline accuracy while using 5.19-9.19 times fewer writes; on LIBERO-Long (n=60 episodes) with OpenVLA-OFT 7B it matches the ungated baseline success rate of 0.233 (vs. 0.217 for always-write KV) with 7 times fewer writes and fixed memory versus a KV-cache that grows 6,061 times larger at 100k steps. The approximate information-state bound is noted as vacuous at this scale.
Significance. If the empirical results hold, the work addresses a practical constraint for long-horizon robot policies on edge hardware where memory writes and bandwidth, rather than FLOPs, are binding. Training the gate on action-surprise isolates the benefit from reconstruction-based alternatives and from budget-matched random/periodic schedules. The explicit statement that the bound is vacuous rather than a guarantee is a positive transparency note. Concrete, falsifiable numbers (success rate 0.233, 7.0x write reduction, constant 4,224 bytes) are reported against explicit baselines.
major comments (2)
- [Abstract] Abstract: success rates (0.233 for AURA-Mem and ungated baseline, 0.217 for always-write) are stated without error bars, standard deviations, or any statistical test despite n=60 episodes per arm; this directly affects whether the central claim of 'matches' performance can be assessed as reliable rather than within sampling noise.
- [Abstract] Abstract: no architecture details, loss formulation, optimizer, or hyperparameters are given for the gate trained on the closed-loop action-error signal; because the write-reduction benefit is attributed entirely to this learned gate, the absence of these elements is load-bearing for evaluating or reproducing the result.
minor comments (2)
- [Abstract] Abstract: the phrase 'up to 9.19 times fewer writes on easier configurations' does not identify the configurations or report the per-configuration numbers.
- [Abstract] Abstract: the exact definition of a 'write' (e.g., per-step memory update count) and the precise baseline used for the 7.0x reduction factor should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical reporting and reproducibility. Both points are valid and we will revise the manuscript to strengthen these aspects while preserving the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: success rates (0.233 for AURA-Mem and ungated baseline, 0.217 for always-write) are stated without error bars, standard deviations, or any statistical test despite n=60 episodes per arm; this directly affects whether the central claim of 'matches' performance can be assessed as reliable rather than within sampling noise.
Authors: We agree that error bars and a statistical test are necessary to substantiate the 'matches' claim. The 0.233 and 0.217 figures are success rates over 60 episodes. In the revision we will report the binomial standard error for each rate and include a two-proportion z-test (p > 0.4), confirming that the observed difference is consistent with sampling noise. This addition will be placed in both the abstract and the experimental section. revision: yes
-
Referee: [Abstract] Abstract: no architecture details, loss formulation, optimizer, or hyperparameters are given for the gate trained on the closed-loop action-error signal; because the write-reduction benefit is attributed entirely to this learned gate, the absence of these elements is load-bearing for evaluating or reproducing the result.
Authors: The gate architecture (two-layer MLP with 128 hidden units), binary cross-entropy loss on action-error labels, Adam optimizer (lr=1e-4), and training hyperparameters are specified in Section 3.2 and Appendix B. To address the abstract's self-containment, we will insert a concise clause summarizing the gate's input, loss, and key hyperparameters while respecting length limits. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method: a gate trained directly on an external closed-loop action-error signal to decide memory writes, with results compared against explicit baselines (ungated policy, always-write KV, random/periodic schedules) on LIBERO-Long and a synthetic benchmark. No derivation chain, equation, or prediction reduces to its own inputs by construction. The approximate information-state bound is explicitly called vacuous at the reported scale rather than used as a guarantee. No self-citation is load-bearing for the central performance claims, and the work is self-contained against the stated falsifiable metrics.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
Flash endurance is priced via shadow price η making placement cost-optimal for any sign of value-write correlation χ, with χ positive only in recurrent long-horizon manipulation and the budget binding only on low-endu...
-
AEGIS: A Backup Reflex for Physical AI
AEGIS uses activation probes for early-warning detection of high-risk steps in weak policies and selectively escalates to stronger policies, recovering 10.1% of lost trajectories on LIBERO-Spatial while activating the...
Reference graph
Works this paper leans on
-
[1]
A. A. Alemi, I. Fischer, J. V. Dillon, and K. Murphy. Deep variational information bottleneck. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[2]
CSR: Cache-state reuse for infinite-horizon robot policies.arXiv preprint arXiv:2605.07325, 2026
Anonymous. CSR: Cache-state reuse for infinite-horizon robot policies.arXiv preprint arXiv:2605.07325, 2026. URL https://arxiv.org/abs/2605.07325. KV-cache reuse via prefix stability; asymptotically growing cache
Pith/arXiv arXiv 2026
-
[3]
Arora, S
S. Arora, S. Eyuboglu, M. Zhang, A. Timalsina, S. Alberti, D. Zinsley, J. Zou, A. Rudra, and C. R´ e. Simple linear attention language models balance the recall-throughput tradeoff. arXiv preprint, 2024
2024
-
[4]
Micron, SK hynix commit over$45 billion to boost HBM supply, May 2026
Auton AI News. Micron, SK hynix commit over$45 billion to boost HBM supply, May 2026. URL https://autonainews.com/ micron-sk-hynix-commit-over-45-billion-to-boost-hbm-supply/. May 20, 2026
2026
-
[5]
J. Ba, G. Hinton, V. Mnih, J. Z. Leibo, and C. Ionescu. Using fast weights to attend to the recent past. InAdvances in Neural Information Processing Systems (NeurIPS), 2016
2016
-
[6]
A. Behrouz, Z. Li, P. Kacham, M. Daliri, Y. Deng, P. Zhong, M. Razaviyayn, and V. Mir- rokni. ATLAS: Learning to optimally memorize the context at test time.arXiv preprint arXiv:2505.23735, 2025
arXiv 2025
-
[7]
A. Behrouz, M. Razaviyayn, P. Zhong, and V. Mirrokni. It’s all connected: A journey through test-time memorization, attentional bias, retention, and online optimization.arXiv preprint arXiv:2504.13173, 2025
arXiv 2025
-
[8]
A. Behrouz, P. Zhong, and V. Mirrokni. Titans: Learning to memorize at test time.arXiv preprint arXiv:2501.00663, 2025
Pith/arXiv arXiv 2025
-
[9]
Burda, H
Y. Burda, H. Edwards, A. Storkey, and O. Klimov. Exploration by random network distillation. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[10]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision transformer: Reinforcement learning via sequence modeling. In Advances in Neural Information Processing Systems (NeurIPS), 2021. 29
2021
-
[11]
E. Cherepanov, A. K. Kovalev, and A. I. Panov. ELMUR: External layer memory with update/rewrite for long-horizon RL.arXiv preprint arXiv:2510.07151, 2025. CoRL 2025 RemembeRL Workshop
arXiv 2025
-
[12]
Choromanski, V
K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarl´ os, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, D. Belanger, L. Colwell, and A. Weller. Rethinking attention with performers. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[13]
Y. Dai, H. Fu, J. Lee, Y. Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. RoboMME: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026. URLhttps://arxiv.org/abs/2603.04639. ICML 2026
Pith/arXiv arXiv 2026
-
[14]
Dao and A
T. Dao and A. Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[15]
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. R´ e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[16]
Y. Duan, J. Schulman, X. Chen, P. L. Bartlett, I. Sutskever, and P. Abbeel. RL 2: Fast reinforcement learning via slow reinforcement learning.arXiv preprint, 2016
2016
-
[17]
Y. Feng, J. Lv, Y. Cao, X. Xie, and S. K. Zhou. Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference.arXiv preprint arXiv:2407.11550, 2024
Pith/arXiv arXiv 2024
-
[18]
Y. Gao, J. Liu, S. Li, and S. Song. Gated memory policy.arXiv preprint arXiv:2604.18933, 2026
Pith/arXiv arXiv 2026
-
[19]
S. Ge, Y. Zhang, L. Liu, M. Zhang, J. Han, and J. Gao. Model tells you what to discard: Adaptive KV cache compression for LLMs.arXiv preprint, 2023
2023
-
[20]
Gelada, S
C. Gelada, S. Kumar, J. Buckman, O. Nachum, and M. G. Bellemare. DeepMDP: Learning continuous latent space models for representation learning. InInternational Conference on Machine Learning (ICML), 2019
2019
-
[21]
A. Gholami, Z. Yao, S. Kim, C. Hooper, M. W. Mahoney, and K. Keutzer. AI and memory wall.IEEE Micro, 44(3):33–39, 2024. doi: 10.1109/mm.2024.3373763
-
[22]
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[23]
A. Gu, K. Goel, and C. R´ e. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations (ICLR), 2022. URL https://arxiv.org/abs/2111.00396
Pith/arXiv arXiv 2022
-
[24]
G. Gupta et al. Memo: Training memory-efficient embodied agents with reinforcement learning.arXiv preprint arXiv:2510.19732, 2025
arXiv 2025
-
[25]
Hafner, T
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[26]
A. Hatamizadeh, Y. Choi, and J. Kautz. Gated DeltaNet-2: Decoupling erase and write in linear attention.arXiv preprint arXiv:2605.22791, 2026. URL https://arxiv.org/ abs/2605.22791. Per-step channel-wise erase+write gates in linear attention; LM-only; no certificate. 30
Pith/arXiv arXiv 2026
-
[27]
Hooper, S
C. Hooper, S. Kim, H. Mohammadzadeh, M. W. Mahoney, Y. S. Shao, K. Keutzer, and A. Gholami. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[28]
Ivanov, N
A. Ivanov, N. Dryden, T. Ben-Nun, S. Li, and T. Hoefler. Data movement is all you need: A case study on optimizing transformers. InConference on Machine Learning and Systems (MLSys), 2021
2021
-
[29]
Kapturowski, G
S. Kapturowski, G. Ostrovski, J. Quan, R. Munos, and W. Dabney. Recurrent experience replay in distributed reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2019. URLhttps://openreview.net/forum?id=r1lyTjAqYX
2019
-
[30]
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. InRobotics: Science and Systems (RSS), 2021. doi: 10.15607/RSS.2021.XVII.011. URL https://doi.org/10.15607/RSS.2021.XVII.011
-
[31]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with PagedAttention. InACM Symposium on Operating Systems Principles (SOSP), 2023
2023
-
[32]
Y. Li, Y. Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen. SnapKV: LLM knows what you are looking for before generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[33]
M. L. Littman, R. S. Sutton, and S. Singh. Predictive representations of state. InAdvances in Neural Information Processing Systems (NIPS), 2001. URL https://proceedings.neurips. cc/paper/2001
2001
-
[34]
J. Liu, M. Liu, Z. Wang, et al. RoboMamba: Efficient vision-language-action model for robotic reasoning and manipulation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[35]
Z. Liu, A. Desai, F. Liao, W. Wang, V. Xie, Z. Xu, A. Kyrillidis, and A. Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[36]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V. Braverman, B. Chen, and X. Hu. KIVI: A tuning-free asymmetric 2bit quantization for KV cache. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[38]
URL https://arxiv.org/abs/2605.22596. Trajectory-tube closed-loop certificate for diffusion policy composition; certifies composition NOT memory sufficiency
-
[39]
Morad, R
S. Morad, R. Kortvelesy, M. Bettini, S. Liwicki, and A. Prorok. POPGym: Benchmark- ing partially observable reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[40]
L. Moschella, L. Manduchi, and O. Sener. Learning to evict from key-value cache.arXiv preprint arXiv:2602.10238, 2026
arXiv 2026
-
[41]
B. Moyer. Flash getting stacked high-bandwidth version. Semicon- ductor Engineering, May 2026. URL https://semiengineering.com/ flash-getting-stacked-high-bandwidth-version/. May 14, 2026. 31
2026
-
[42]
Pathak, P
D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell. Curiosity-driven exploration by self- supervised prediction. InInternational Conference on Machine Learning (ICML), 2017
2017
-
[43]
B. Peng, E. Alcaide, Q. Anthony, et al. RWKV: Reinventing RNNs for the trans- former era. InFindings of the Association for Computational Linguistics: EMNLP 2023,
2023
-
[44]
URL https://aclanthology.org/2023
doi: 10.18653/v1/2023.findings-emnlp.936. URL https://aclanthology.org/2023. findings-emnlp.936
-
[45]
W. Qiu, T. Huang, and R. Ying. Efficient long-horizon vision-language-action models via static-dynamic disentanglement.arXiv preprint arXiv:2602.03983, 2026
Pith/arXiv arXiv 2026
-
[46]
Ramsauer, B
H. Ramsauer, B. Sch¨ afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi´ c, G. K. Sandve, V. Greiff, D. Kreil, M. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter. Hopfield networks is all you need. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[47]
N. Roy, G. Gordon, and S. Thrun. Finding approximate POMDP solutions through belief compression.Journal of Artificial Intelligence Research, 23:1–40, 2005. URL http://www. cs.cmu.edu/~ggordon/roy-gordon-thrun.belief-compression-jair.pdf
2005
-
[48]
Schlag, K
I. Schlag, K. Irie, and J. Schmidhuber. Linear transformers are secretly fast weight program- mers. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[49]
J. T. Smith, A. Warrington, and S. W. Linderman. Simplified state space layers for sequence modeling.arXiv preprint, 2023. URLhttps://arxiv.org/abs/2208.04933
Pith/arXiv arXiv 2023
-
[50]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. MemER: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
-
[51]
Subramanian, A
J. Subramanian, A. Sinha, R. Seraj, and A. Mahajan. Approximate information state for approximate planning and reinforcement learning in partially observed systems.Journal of Machine Learning Research, 23(12):1–83, 2022. URL https://jmlr.org/papers/v23/ 20-1165.html
2022
-
[52]
Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, F. Wei, et al. Retentive network: A successor to Transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
Pith/arXiv arXiv 2023
-
[53]
Y. Sun, X. Li, K. Dalal, J. Xu, A. Vikram, G. Zhang, Y. Dubois, X. Chen, X. Wang, S. Koyejo, T. Hashimoto, and C. Guestrin. Learning to (learn at test time): RNNs with expressive hidden states.arXiv preprint arXiv:2407.04620, 2024
Pith/arXiv arXiv 2024
-
[54]
K. Swain, S. Han, D. K. I. Weidele, M. Martino, and A. Torralba. Tensor cache: Eviction- conditioned associative memory for transformers.arXiv preprint arXiv:2605.22884, 2026. URL https://arxiv.org/abs/2605.22884. MIT/Torralba group; bounded fast-weight prior; LM-only, eviction-triggered write, no certificate
Pith/arXiv arXiv 2026
-
[55]
K. Swain, S. Han, D. K. I. Weidele, M. Martino, and A. Torralba. Tensor memory: Fixed-size recurrent state for long-horizon transformers.arXiv preprint arXiv:2605.27686, 2026. URL https://arxiv.org/abs/2605.27686. Fixed-size 3D recurrent tensor; spatial soft-write; perception loss; no control-rate, no certificate
Pith/arXiv arXiv 2026
-
[56]
DRAM prices reach all-time high at$20: Q2 increase slows as PC deals close, May 2026
TechTimes. DRAM prices reach all-time high at$20: Q2 increase slows as PC deals close, May 2026. URL http://www.techtimes.com/articles/317403/20260530/ dram-prices-reach-all-time-high-20-q2-increase-slows-pc-deals-close.htm . May 30, 2026; TrendForce / DRAMeXchange data. 32
2026
-
[57]
Tishby, F
N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method. InProceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, pages 368–377, 1999
1999
-
[58]
M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, H. Wang, J. Tang, K. Stachowicz, K. Dhabalia, M. Equi, Q. Vuong, J. T. Springenberg, S. Levine, C. Finn, and D. Driess. MEM: Multi-scale embodied memory for vision language action models.arXiv preprint arXiv:2603.03596, 2026. URL https://arxiv.org/abs/2603.03596. Mixed-modal embodie...
arXiv 2026
-
[59]
D. Tu, D. Vashchilenko, Y. Lu, and P. Xu. VL-Cache: Sparsity and modality-aware KV cache compression for vision-language model inference acceleration.arXiv preprint arXiv:2410.23317, 2024
arXiv 2024
-
[60]
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[61]
S. Xu, Y. Wang, C. Xia, D. Zhu, T. Huang, and C. Xu. VLA-Cache: Efficient vision- language-action manipulation via adaptive token caching. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[62]
W. Xu, L. Zhuang, and L. Shan. KV-Efficient VLA: A method of speed up vision language model with RNN-gated chunked KV cache.arXiv preprint arXiv:2509.21354, 2025
arXiv 2025
-
[63]
S. Yang, B. Wang, Y. Shen, R. Panda, and Y. Kim. Gated linear attention transformers with hardware-efficient training. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[64]
Y. Yang, Y. Wang, Z. Wen, Z. Luo, C. Zou, Z. Zhang, C. Wen, and L. Zhang. EfficientVLA: Training-free acceleration and compression for vision-language-action models.arXiv preprint arXiv:2506.10100, 2025
arXiv 2025
-
[65]
Micron stock slips despite blowout earnings, up- beat guidance, May 2026
Zacks Investment Research. Micron stock slips despite blowout earnings, up- beat guidance, May 2026. URL https://www.zacks.com/commentary/2886800/ micron-stock-slips-despite-blowout-earnings-upbeat-guidance. May 22, 2026
arXiv 2026
-
[66]
Zhang, R
A. Zhang, R. McAllister, R. Calandra, Y. Gal, and S. Levine. Learning invariant represen- tations for reinforcement learning without reconstruction. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[67]
T. Zhang et al. Test-time training done right.arXiv preprint arXiv:2505.23884, 2025. Also available at OpenReview Tb9qAxT3xv
Pith/arXiv arXiv 2025
-
[68]
ours = write-every-step minus the gate
Z. Zhang, Y. Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y. Tian, C. R´ e, C. Barrett, Z. Wang, and B. Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. A Proofs (full detail) A.1 Proof of Theorem 4.3 (full detail) We reproduce the full f...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.