HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Body Planning
Pith reviewed 2026-06-29 16:33 UTC · model grok-4.3
The pith
HumanoidMimicGen generates large sets of stable whole-body loco-manipulation demonstrations from a small number of source examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
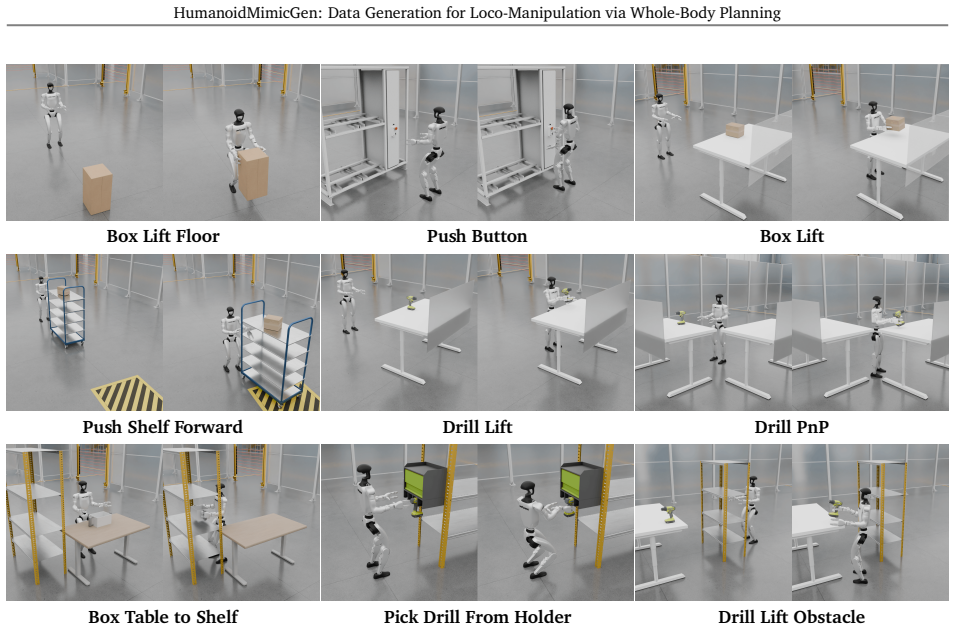
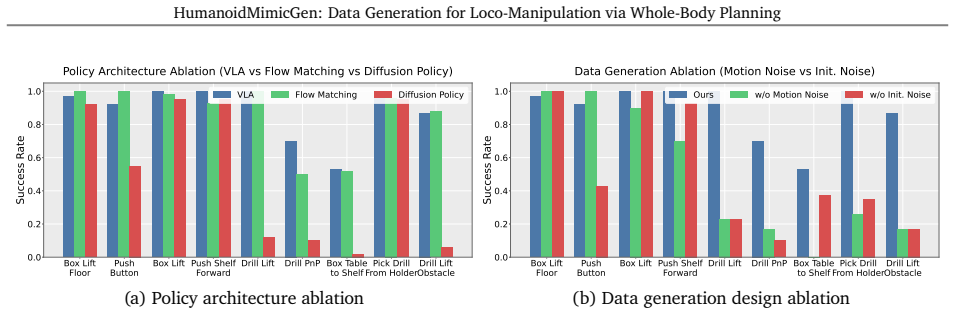
HumanoidMimicGen adapts contact-rich whole-body skills from a handful of source demonstrations to new states, generalizing across changes in object pose. By interleaving single- and dual-arm skills with whole-body locomotion and manipulation planning, the method generates stable, collision-free data across diverse scenes and layouts. Whole-body visuomotor policies co-trained with this generated data outperform those trained only on real-world data by 20 percent on a new simulated loco-manipulation benchmark containing nine tasks.
What carries the argument
HumanoidMimicGen, a whole-body planning procedure that adapts contact-rich arm skills to new states and interleaves them with locomotion planning to synthesize stable loco-manipulation trajectories.
If this is right
- Large numbers of loco-manipulation demonstrations become available without additional teleoperation.
- Whole-body policies can be trained that succeed on tasks requiring coordinated locomotion and manipulation in changing layouts.
- A systematic comparison of data-generation choices and policy architectures is now possible on the nine-task benchmark.
- Co-training with automatically generated data improves policy performance beyond what real demonstrations alone achieve.
Where Pith is reading between the lines
- If the generated trajectories transfer to physical robots, the volume of real teleoperation needed for humanoid training could drop substantially.
- The same adaptation-plus-planning loop might extend to multi-object or long-horizon tasks once the benchmark is expanded.
- The nine-task benchmark supplies a concrete testbed for measuring how much simulation-to-real gap remains after co-training.
- Similar data-generation pipelines could be applied to other high-dimensional platforms such as mobile manipulators.
Load-bearing premise
The generated demonstrations are realistic, stable, and diverse enough that adding them to training produces a measurable performance gain over real data alone.
What would settle it
Train identical whole-body visuomotor policies on the nine-task benchmark using only the real demonstrations versus the real demonstrations plus the HumanoidMimicGen data and check whether the success-rate difference remains at or above 20 percent.
Figures



read the original abstract
Imitation learning is a promising approach for training humanoid robots to both walk and manipulate, but it requires a large number of demonstrations, which are time-intensive and difficult to collect via teleoperation. Existing data-generation algorithms can automatically synthesize demonstrations for manipulators, but they are ineffective on humanoids because their high-dimensional composite action spaces involve arms, legs, and torsos. We present HumanoidMimicGen, a method for generating humanoid legged loco-manipulation data. Our method adapts contact-rich whole-body skills from a handful of source demonstrations to new states, generalizing across changes in object pose. By interleaving these single- and dual-arm skills with whole-body locomotion and manipulation planning, the method generates stable, collision-free data across diverse scenes and layouts. To evaluate our approach, we introduce a new simulated loco-manipulation benchmark containing nine diverse tasks that test humanoid loco-manipulation capabilities. There, we demonstrate that HumanoidMimicGen automatically generates large datasets for imitation learning and enables a systematic study of how data generation and policy learning decisions impact model performance. We show that whole-body visuomotor policies co-trained with data generated by HumanoidMimicGen outperform those trained only on real-world data by 20%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HumanoidMimicGen, a method for automatically generating large-scale whole-body loco-manipulation demonstrations for humanoids. It adapts contact-rich single- and dual-arm skills from a small set of source demonstrations to new object poses via whole-body planning, then interleaves these with locomotion and manipulation primitives to produce stable, collision-free trajectories across varied scenes. The authors introduce a new simulated benchmark consisting of nine diverse loco-manipulation tasks and report that whole-body visuomotor policies co-trained on real-world data augmented with HumanoidMimicGen data outperform policies trained on real-world data alone by 20%.
Significance. If the reported performance gains prove robust after proper controls, the work would meaningfully advance scalable data generation for humanoid imitation learning, addressing the high cost of teleoperated whole-body demonstrations. The new benchmark is a constructive contribution that could support systematic study of data and policy decisions in loco-manipulation. The core technical idea of combining skill adaptation with interleaved whole-body planning is a reasonable direction for composite action spaces.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation section: the central claim of a 20% performance improvement for co-trained policies is stated without reference to the number of tasks evaluated, the precise baselines, data volumes, error bars, or statistical tests. This detail is load-bearing for assessing whether the result supports the method.
- [Benchmark evaluation] Benchmark evaluation: the real-only versus real + HumanoidMimicGen comparison does not report ablations that isolate data volume (e.g., real + random simulated trajectories of matched length) or domain shift (e.g., dynamics or sensor mismatch between real collection and the simulation used for generation). Without these controls the attribution of any lift specifically to the quality and diversity of the generated loco-manipulation sequences remains unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the presentation and evaluation of our results.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the central claim of a 20% performance improvement for co-trained policies is stated without reference to the number of tasks evaluated, the precise baselines, data volumes, error bars, or statistical tests. This detail is load-bearing for assessing whether the result supports the method.
Authors: We agree that additional detail in the abstract would improve clarity. The evaluation is performed across all nine tasks in the benchmark. The comparison uses real-world data only versus real-world data augmented with HumanoidMimicGen trajectories, with total demonstration counts matched between conditions. We will revise the abstract to explicitly state the nine-task scope, the matched data volumes, and the precise baselines. In the evaluation section we will also add error bars (standard deviation over three random seeds) and note the results of paired statistical tests. revision: yes
-
Referee: [Benchmark evaluation] Benchmark evaluation: the real-only versus real + HumanoidMimicGen comparison does not report ablations that isolate data volume (e.g., real + random simulated trajectories of matched length) or domain shift (e.g., dynamics or sensor mismatch between real collection and the simulation used for generation). Without these controls the attribution of any lift specifically to the quality and diversity of the generated loco-manipulation sequences remains unverified.
Authors: We acknowledge that the current manuscript lacks explicit controls for data volume and domain shift. We will add an ablation that augments the real dataset with an equal number of randomly sampled simulated trajectories (without HumanoidMimicGen planning) to isolate the contribution of data volume. Regarding domain shift, HumanoidMimicGen generates trajectories inside a simulation whose dynamics and sensor models were calibrated to the real robot; we will expand the manuscript to quantify residual mismatch via a small set of real-to-sim transfer experiments and discuss this calibration explicitly. These additions will be included in the revised version. revision: yes
Circularity Check
No circularity: empirical method with no fitted predictions or self-referential derivations
full rationale
The paper describes an algorithmic pipeline for generating loco-manipulation demonstrations via whole-body planning and reports an empirical 20% policy improvement on a simulated benchmark. No equations, parameter-fitting steps, uniqueness theorems, or ansatzes appear in the provided text. The performance delta is framed as a direct experimental outcome of co-training on real versus generated data rather than any quantity derived from or equivalent to the method's own inputs by construction. The central claim therefore remains externally falsifiable via the benchmark results and does not reduce to self-definition or self-citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Whole-body motion and footstep planning for humanoid robots with multi-heuristic search.Robotics and Autonomous Systems, 116:51–63,
Rizwan Asif, Ali Athar, Faisal Mehmood, Fahad Islam, and Yasar Ayaz. Whole-body motion and footstep planning for humanoid robots with multi-heuristic search.Robotics and Autonomous Systems, 116:51–63,
-
[2]
doi: 10.1016/j.robot.2019.03.007. 3
-
[3]
A framework for behavioural cloning
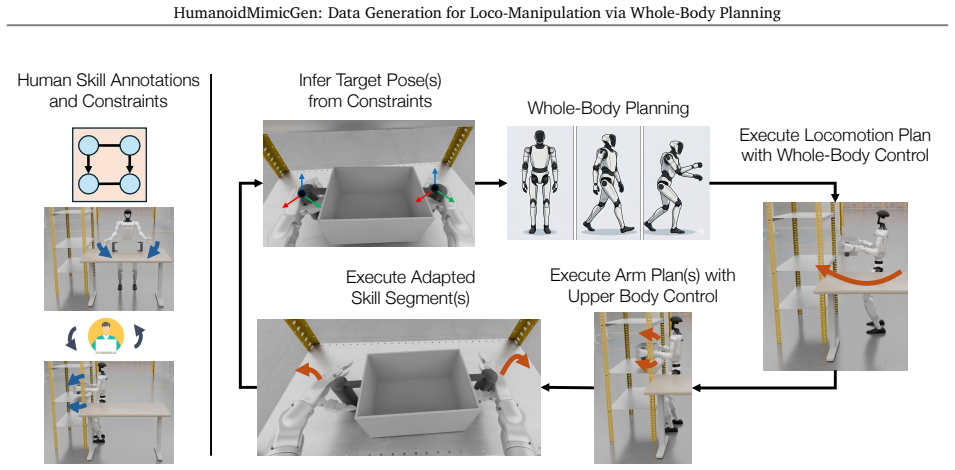
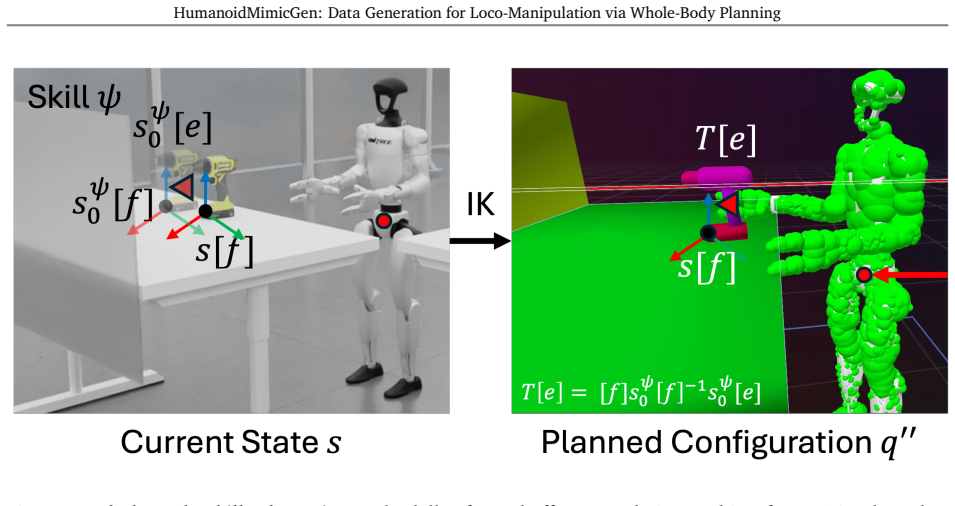
Michael Bain and Claude Sammut. A framework for behavioural cloning. InMachine intelligence 15, pages 103–129, 1995. 4
1995
-
[4]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit,
Qingwei Ben, Feiyu Jia, Jia Zeng, Junting Dong, Dahua Lin, and Jiangmiao Pang. Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit.arXiv preprint arXiv:2502.13013, 2025. 3, 5
-
[6]
Robot programming by demonstra- tion
Aude Billard, Sylvain Calinon, Rüdiger Dillmann, and Stefan Schaal. Robot programming by demonstra- tion. InSpringer Handbook of Robotics, 2008. 3
2008
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 1, 3, 7, 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.𝜋0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Whole-body motion planning for manipulation of articulated objects
Felix Burget, Armin Hornung, and Maren Bennewitz. Whole-body motion planning for manipulation of articulated objects. In2013 IEEE International Conference on Robotics and Automation, pages 1656–1662. IEEE, 2013. doi: 10.1109/ICRA.2013.6630792. 3 10 HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Body Planning
-
[12]
Sauser, Darwin G
Sylvain Calinon, Florent D’halluin, Eric L. Sauser, Darwin G. Caldwell, and Aude Billard. Learning and reproduction of gestures by imitation.IEEE Robotics and Automation Magazine, 17, 2010. 3
2010
-
[13]
Shuo Cheng, Liqian Ma, Zhenyang Chen, Ajay Mandlekar, Caelan Garrett, and Danfei Xu. Generalizable domain adaptation for sim-and-real policy co-training.arXiv preprint arXiv:2509.18631, 2025. 2, 3
-
[14]
Diffusion policy: Visuomotor policy learning via action diffusion.The Int’l Journal of Robotics Research, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The Int’l Journal of Robotics Research, 2023. 3, 8
2023
-
[15]
Imitating task and motion planning with visuomotor transformers.arXiv preprint arXiv:2305.16309,
Murtaza Dalal, Ajay Mandlekar, Caelan Garrett, Ankur Handa, Ruslan Salakhutdinov, and Dieter Fox. Imitating task and motion planning with visuomotor transformers.arXiv preprint arXiv:2305.16309,
-
[16]
Manipulation of documented objects by a walking humanoid robot
Sébastien Dalibard, Alireza Nakhaei, Florent Lamiraux, and Jean-Paul Laumond. Manipulation of documented objects by a walking humanoid robot. In2010 10th IEEE-RAS International Conference on Humanoid Robots, pages 518–523. IEEE, 2010. doi: 10.1109/ICHR.2010.5686827. 3
-
[17]
Dynamic walking and whole-body motion planning for humanoid robots: an integrated approach.The International Journal of Robotics Research, 32(9-10):1089–1103, 2013
Sébastien Dalibard, Antonio El Khoury, Florent Lamiraux, Alireza Nakhaei, Michel Taïx, and Jean-Paul Laumond. Dynamic walking and whole-body motion planning for humanoid robots: an integrated approach.The International Journal of Robotics Research, 32(9-10):1089–1103, 2013. doi: 10.1177/ 0278364913481250. 3
2013
-
[18]
Bridge Data: Boosting Generalization of Robotic Skills with Cross- Domain Datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge Data: Boosting Generalization of Robotic Skills with Cross- Domain Datasets. InRobotics: Science and Systems, 2022. 1
2022
-
[19]
Tsagarakis, and Enrico Mingo Hoffman
Paolo Ferrari, Luca Rossini, Francesco Ruscelli, Arturo Laurenzi, Giuseppe Oriolo, Nikos G. Tsagarakis, and Enrico Mingo Hoffman. Multi-contact planning and control for humanoid robots: Design and validation of a complete framework.Robotics and Autonomous Systems, 166:104448, 2023. doi: 10.1016/j.robot. 2023.104448. 3
-
[20]
Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4:265–293, 2021
Caelan Reed Garrett, Rohan Chitnis, Rachel Holladay, Beomjoon Kim, Tom Silver, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4:265–293, 2021. 3
2021
-
[21]
Skillgen: Automated demonstration generation for efficient skill learning and deployment
Caelan Reed Garrett, Ajay Mandlekar, Bowen Wen, and Dieter Fox. Skillgen: Automated demonstration generation for efficient skill learning and deployment. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=YOFrRTDC6d. 2, 4, 6, 9
2024
-
[22]
Humanoid manipulation planning using backward-forward search
Michael X Grey, Caelan R Garrett, C Karen Liu, Aaron D Ames, and Andrea L Thomaz. Humanoid manipulation planning using backward-forward search. In2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5467–5473. IEEE, 2016. 3
2016
-
[23]
Zhaoyuan Gu, Junheng Li, Wenlan Shen, Wenhao Yu, Zhaoming Xie, Stephen McCrory, Xianyi Cheng, Abdulaziz Shamsah, Robert Griffin, C Karen Liu, et al. Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning.arXiv preprint arXiv:2501.02116, 2025. 3
-
[24]
Siddhant Haldar, Lars Johannsmeier, Lerrel Pinto, Abhishek Gupta, Dieter Fox, Yashraj Narang, and Ajay Mandlekar. Point bridge: 3d representations for cross domain policy learning.arXiv preprint arXiv:2601.16212, 2026. 2, 3
-
[25]
Randomized multi-modal motion planning for a humanoid robot manipulation task.International Journal of Robotics Research (IJRR), 30(6):676–698, 2011
Kris Hauser and Victor Ng-Thow-Hing. Randomized multi-modal motion planning for a humanoid robot manipulation task.International Journal of Robotics Research (IJRR), 30(6):676–698, 2011. 3 11 HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Body Planning
2011
-
[26]
Multi-modal motion planning for a humanoid robot manipulation task
Kris Hauser, Victor Ng-Thow-Hing, and Hector Gonzalez-Baños. Multi-modal motion planning for a humanoid robot manipulation task. InRobotics Research, pages 307–317. Springer, 2011. 3
2011
-
[27]
Hover: Versatile neural whole-body controller for humanoid robots
Tairan He, Wenli Xiao, Toru Lin, Zhengyi Luo, Zhenjia Xu, Zhenyu Jiang, Jan Kautz, Changliu Liu, Guanya Shi, Xiaolong Wang, et al. Hover: Versatile neural whole-body controller for humanoid robots. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9989–9996. IEEE, 2025. 3
2025
-
[28]
Xixi Hu, Bo Liu, Xingchao Liu, and Qiang Liu. Adaflow: Imitation learning with variance-adaptive flow-based policies.arXiv preprint arXiv:2402.04292, 2024. 8
-
[29]
Movement imitation with nonlinear dynamical systems in humanoid robots.Proceedings 2002 IEEE Int’l Conf on Robotics and Automation, 2, 2002
Auke Jan Ijspeert, Jun Nakanishi, and Stefan Schaal. Movement imitation with nonlinear dynamical systems in humanoid robots.Proceedings 2002 IEEE Int’l Conf on Robotics and Automation, 2, 2002. 3
2002
-
[30]
Shrinking sphere: A parallel algorithm for computing the thickness of 3d objects.Computer-Aided Design and Applications, 13(2):199–207, 2016
Masatomo Inui, Nobuyuki Umezu, and Ryohei Shimane. Shrinking sphere: A parallel algorithm for computing the thickness of 3d objects.Computer-Aided Design and Applications, 13(2):199–207, 2016. 16
2016
-
[31]
doi:10.48550/arXiv.2410.24185 , abstract =
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Fan, and Yuke Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning. arXiv preprint arXiv:2410.24185, 2024. 2, 4, 6, 7, 8, 9, 18
-
[32]
A unified approach for motion and force control of robot manipulators: The operational space formulation.IEEE Journal on Robotics and Automation, 3(1):43–53, 1987
Oussama Khatib. A unified approach for motion and force control of robot manipulators: The operational space formulation.IEEE Journal on Robotics and Automation, 3(1):43–53, 1987. 4
1987
-
[33]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, SoroushNasiriany, MohanKumarSrirama, LawrenceYunliangChen, KirstyEllis, etal. Droid: Alarge-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Chengshu Li, Mengdi Xu, Arpit Bahety, Hang Yin, Yunfan Jiang, Huang Huang, Josiah Wong, Sujay Garlanka, Cem Gokmen, Ruohan Zhang, et al. Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation.arXiv preprint arXiv:2510.18316, 2025. 2
-
[35]
Constraint-preserving data generation for visuomotor policy generalization
Kevin Lin, Varun Ragunath, Andrew McAlinden, Aaditya Prasad, Jimmy Wu, Yuke Zhu, and Jeannette Bohg. Constraint-preserving data generation for visuomotor policy generalization. In9th Annual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum?id=KSKzA1mwKs. 2, 6, 9
2025
-
[36]
Minghuan Liu, Zhengbang Zhu, Xiaoshen Han, Peng Hu, Haotong Lin, Xinyao Li, Jingxiao Chen, Jiafeng Xu, Yichu Yang, Yunfeng Lin, et al. Manipulation as in simulation: Enabling accurate geometry perception in robots.arXiv preprint arXiv:2509.02530, 2025. 2
-
[37]
Smplolympics: Sports environments for physically simulated humanoids,
Zhengyi Luo, Jiashun Wang, Kangni Liu, Haotian Zhang, Chen Tessler, Jingbo Wang, Ye Yuan, Jinkun Cao, Zihui Lin, Fengyi Wang, et al. Smplolympics: Sports environments for physically simulated humanoids. arXiv preprint arXiv:2407.00187, 2024. 3
-
[38]
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castañeda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Abhiram Maddukuri, Zhenyu Jiang, Lawrence Yunliang Chen, Soroush Nasiriany, Yuqi Xie, Yu Fang, Wenqi Huang, Zu Wang, Zhenjia Xu, Nikita Chernyadev, et al. Sim-and-real co-training: A simple recipe for vision-based robotic manipulation.arXiv preprint arXiv:2503.24361, 2025. 2, 3, 8
-
[40]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning ( CoRL), 2021. 2, 3 12 HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Bo...
2021
-
[41]
Human-in-the-loop task and motion planning for imitation learning
Ajay Mandlekar, Caelan Garrett, Danfei Xu, and Dieter Fox. Human-in-the-loop task and motion planning for imitation learning. In7th Annual Conference on Robot Learning, 2023. 3
2023
-
[42]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. In7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/ forum?id=dk-2R1f_LR. 1, 2, 4, 6
2023
-
[43]
Guided imitation of task and motion planning
Michael James McDonald and Dylan Hadfield-Menell. Guided imitation of task and motion planning. In Conference on Robot Learning, pages 630–640. PMLR, 2022. 3
2022
-
[44]
Masaki Murooka, Iori Kumagai, Mitsuharu Morisawa, Fumio Kanehiro, and Abderrahmane Kheddar. Humanoid loco-manipulation planning based on graph search and reachability maps.IEEE Robotics and Automation Letters, 6(2):1840–1847, 2021. doi: 10.1109/LRA.2021.3060728. 3
-
[45]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE Int’l Conf on Robotics and Automation (ICRA), 2024. 1
2024
-
[46]
Alvinn: An autonomous land vehicle in a neural network
Dean A Pomerleau. Alvinn: An autonomous land vehicle in a neural network. InAdvances in neural information processing systems, pages 305–313, 1989. 3, 4
1989
-
[47]
Vaibhav Saxena, Matthew Bronars, Nadun Ranawaka Arachchige, Kuancheng Wang, Woo Chul Shin, Soroush Nasiriany, Ajay Mandlekar, and Danfei Xu. What matters in learning from large-scale datasets for robot manipulation.arXiv preprint arXiv:2506.13536, 2025. 2
-
[48]
Is imitation learning the route to humanoid robots?Trends in cognitive sciences, 3, 1999
Stefan Schaal. Is imitation learning the route to humanoid robots?Trends in cognitive sciences, 3, 1999. 3
1999
-
[49]
Humanoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation, 2024
Carmelo Sferrazza, Dun-Ming Huang, Xingyu Lin, Youngwoon Lee, and Pieter Abbeel. Humanoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation, 2024. 3
2024
-
[50]
Balakumar Sundaralingam, Siva Kumar Sastry Hari, Adam Fishman, Caelan Garrett, Karl Van Wyk, Valts Blukis, Alexander Millane, Helen Oleynikova, Ankur Handa, Fabio Ramos, Nathan Ratliff, and Dieter Fox. Curobo: Parallelized collision-free robot motion generation. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8112–8119, 2023....
-
[51]
curobo: Parallelized collision-free minimum-jerk robot motion generation, 2023
Balakumar Sundaralingam, Siva Kumar Sastry Hari, Adam Fishman, Caelan Garrett, Karl Van Wyk, Valts Blukis, Alexander Millane, Helen Oleynikova, Ankur Handa, Fabio Ramos, Nathan Ratliff, and Dieter Fox. curobo: Parallelized collision-free minimum-jerk robot motion generation, 2023. 16
2023
-
[52]
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy. arXiv preprint arXiv:2511.16651, 2025. 3
-
[53]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033, 2012. 7, 17
2012
-
[54]
Empirical analysis of sim-and-real cotraining of diffusion policies for planar pushing from pixels,
Adam Wei, Abhinav Agarwal, Boyuan Chen, Rohan Bosworth, Nicholas Pfaff, and Russ Tedrake. Empirical analysis of sim-and-real cotraining of diffusion policies for planar pushing from pixels.arXiv preprint arXiv:2503.22634, 2025. 2, 3, 8
-
[55]
Lujie Yang, Xiaoyu Huang, Zhen Wu, Angjoo Kanazawa, Pieter Abbeel, Carmelo Sferrazza, C Karen Liu, Rocky Duan, and Guanya Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025. 3 13 HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Bod...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Lujie Yang, HJ Suh, Tong Zhao, Bernhard Paus Graesdal, Tarik Kelestemur, Jiuguang Wang, Tao Pang, and Russ Tedrake. Physics-driven data generation for contact-rich manipulation via trajectory optimization. arXiv preprint arXiv:2502.20382, 2025. 2
-
[57]
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Chenghao Yin, Da Huang, Di Yang, Jichao Wang, Nanshu Zhao, Chen Xu, Wenjun Sun, Linjie Hou, Zhijun Li, Junhui Wu, et al. Genie sim 3.0: A high-fidelity comprehensive simulation platform for humanoid robot.arXiv preprint arXiv:2601.02078, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Zihan Zhou, Animesh Garg, Ajay Mandlekar, and Caelan Garrett. Reinforcegen: Hybrid skill policies with automated data generation and reinforcement learning.arXiv preprint arXiv:2512.16861, 2025. 2
-
[59]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, and Roberto Martín-Martín. robosuite: A modular simulation framework and benchmark for robot learning. InarXiv preprint arXiv:2009.12293, 2020. 7, 17 14 HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Body Planning Overview The appendix contains the following content. •Skill Planning Example(Appendi...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[60]
We manually annotate source demonstration subtasks that will require locomotion
-
[61]
Thewhole-inv-kinematicsprocedure does not consider collisions, and all joints apart from the legs are unlocked and free to move from the current configuration
For each subtask that requires locomotion, we invokewhole-inv-kinematicsto infer a target base pose for one (or both) arm poses at the start of each subtask. Thewhole-inv-kinematicsprocedure does not consider collisions, and all joints apart from the legs are unlocked and free to move from the current configuration
-
[62]
To move from a current base configuration to a new base configuration, a straight-line interpolated path is used (similar to interpolation segments for the arms in DexMimicGen [30]). This baseline lacks several crucial features introduced by HumanoidMimicGen, including the use of skill reasoning, motion planning for locomotion and arm movement, and collis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.