Explicit Critic Guidance for Aligning Diffusion Models
Pith reviewed 2026-06-29 18:16 UTC · model grok-4.3
The pith
Diffusion models can serve as their own timestep-conditioned value functions to enable stable PPO alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
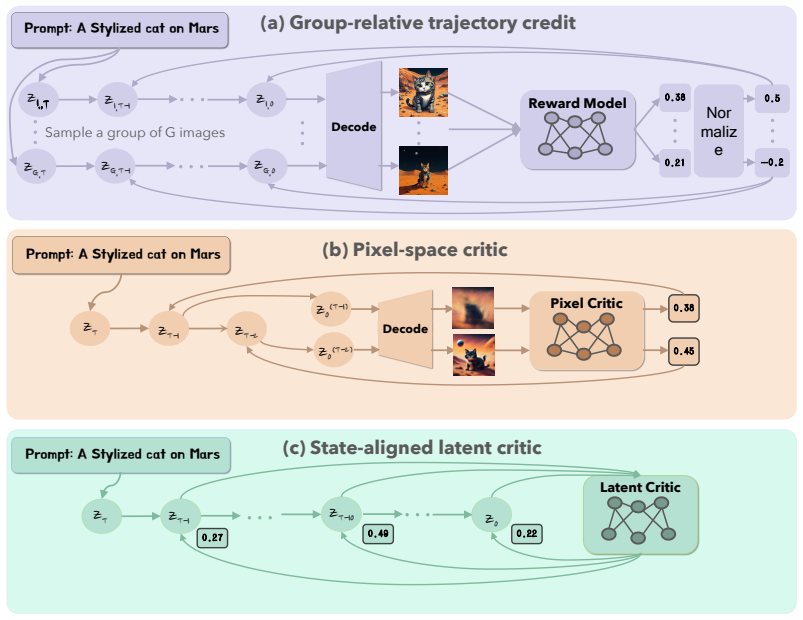
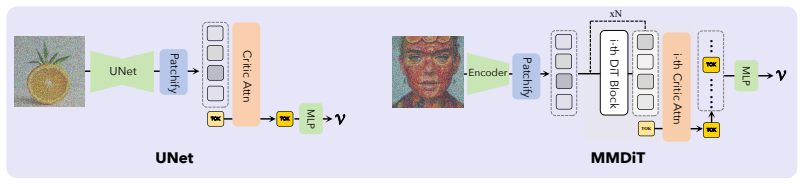
We propose a state-aligned latent actor-critic framework for diffusion post-training in which the diffusion model serves as its own timestep-conditioned value function and predicts values directly on noisy latent states. This enables trajectory-level PPO training, supports stable actor-critic optimization with simple conditioning and value pretraining strategies, and naturally allows the learned critic to be reused for inference-time steering. The framework further extends to multi-reward optimization where joint training with complementary rewards helps alleviate reward hacking.
What carries the argument
state-aligned latent actor-critic framework in which the diffusion model itself predicts values on noisy latent states as a timestep-conditioned critic
If this is right
- Trajectory-level PPO becomes feasible for diffusion post-training without separate value networks.
- Stable actor-critic optimization is achieved through simple conditioning and value pretraining.
- The learned critic can be directly reused to steer sampling at inference time.
- Joint training on complementary rewards reduces reward hacking in multi-objective alignment.
- The method outperforms prior group-relative RL and actor-critic baselines on both UNet and DiT backbones.
Where Pith is reading between the lines
- The same value-prediction approach could be tested on non-diffusion generative models that operate on noisy or latent states.
- If value predictions remain accurate across noise levels, the framework might simplify credit assignment in other sequential generative tasks.
- Inference-time steering with the critic offers a low-cost way to combine multiple learned objectives without retraining.
- The method invites direct comparison of value-prediction accuracy against ground-truth rewards at each timestep to verify the state-alignment premise.
Load-bearing premise
The diffusion model can reliably predict values directly on noisy latent states to act as its own timestep-conditioned value function without separate networks or complex credit assignment.
What would settle it
Training runs in which the diffusion model's value predictions on noisy states show no correlation with final trajectory rewards or produce unstable PPO updates would falsify the central claim.
Figures








read the original abstract
Online reinforcement learning is becoming increasingly important for aligning diffusion models with non-differentiable objectives. However, existing methods still face limitations in assigning fine-grained credit along denoising trajectories and in realizing stable value-based optimization. We propose a state-aligned latent actor-critic framework for diffusion post-training, in which the diffusion model serves as its own timestep-conditioned value function and predicts values directly on noisy latent states. This enables trajectory-level PPO training, supports stable actor-critic optimization with simple conditioning and value pretraining strategies, and naturally allows the learned critic to be reused for inference-time steering. We further extend the framework to multi-reward optimization, where joint training with complementary rewards helps alleviate reward hacking. Across both UNet- and DiT-based backbones, our method consistently outperforms prior group-relative RL and actor-critic baselines on single-reward and multi-reward benchmarks, while test-time steering provides additional gains in generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a state-aligned latent actor-critic framework for diffusion post-training in which the diffusion model itself serves as a timestep-conditioned value function by predicting values directly on noisy latent states. This is claimed to enable trajectory-level PPO training, support stable actor-critic optimization via simple conditioning and value pretraining strategies, allow reuse of the learned critic for inference-time steering, and extend naturally to multi-reward optimization to mitigate reward hacking. The authors state that the method consistently outperforms prior group-relative RL and actor-critic baselines on single- and multi-reward benchmarks for both UNet- and DiT-based backbones, with further gains from test-time steering.
Significance. If the empirical claims hold, the work would be significant for RL-based alignment of diffusion models. By eliminating the need for separate value networks and enabling direct value prediction on noisy states, the framework could improve stability and credit assignment in trajectory-level optimization. The multi-reward extension and inference-time critic reuse offer practical advantages for handling complex or multiple objectives without reward hacking.
major comments (2)
- [Abstract] Abstract: the central empirical claim that the method 'consistently outperforms prior group-relative RL and actor-critic baselines' on single- and multi-reward benchmarks is stated without any quantitative results, metrics, error bars, ablation studies, or tables. This absence is load-bearing because the outperformance and stability assertions are the primary evidence offered for the framework's effectiveness.
- [Abstract] Abstract: the core modeling assumption that 'the diffusion model serves as its own timestep-conditioned value function and predicts values directly on noisy latent states' is presented as sufficient for stable trajectory-level PPO without separate value networks, yet the text provides no analysis, derivation, or preliminary evidence addressing potential inaccuracies in value estimates on highly noisy states or resulting credit-assignment issues.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. Below we respond point-by-point to the two major comments and indicate the revisions we will make in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that the method 'consistently outperforms prior group-relative RL and actor-critic baselines' on single- and multi-reward benchmarks is stated without any quantitative results, metrics, error bars, ablation studies, or tables. This absence is load-bearing because the outperformance and stability assertions are the primary evidence offered for the framework's effectiveness.
Authors: We agree that the abstract, as a concise summary, does not contain specific quantitative results. The full manuscript provides these details in Sections 4 and 5, including tables reporting metrics with error bars across UNet and DiT backbones, ablation studies on conditioning and pretraining, and comparisons against group-relative RL and actor-critic baselines on both single- and multi-reward tasks. To address the concern directly in the abstract, we will revise it to include one or two key quantitative highlights (e.g., average improvement margins) while respecting length limits. revision: yes
-
Referee: [Abstract] Abstract: the core modeling assumption that 'the diffusion model serves as its own timestep-conditioned value function and predicts values directly on noisy latent states' is presented as sufficient for stable trajectory-level PPO without separate value networks, yet the text provides no analysis, derivation, or preliminary evidence addressing potential inaccuracies in value estimates on highly noisy states or resulting credit-assignment issues.
Authors: The abstract states the modeling choice at a high level. The manuscript contains the requested analysis in Section 3.2 (including the derivation of the state-aligned critic objective and how timestep conditioning plus value pretraining mitigate credit-assignment problems) and preliminary experiments in Appendix B that quantify value-prediction accuracy across noise levels. Because the abstract is not the appropriate location for derivations, we will not expand it substantially on this point but can add a short clause noting the stability mechanisms if space permits. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present a novel framework design in which the diffusion model is explicitly repurposed as its own timestep-conditioned value function on noisy latents to enable trajectory-level PPO. No equations, derivations, or claims reduce the central result to a fitted parameter renamed as prediction, a self-citation chain, or a self-definitional loop. The method is introduced as an enabling architectural choice supported by conditioning strategies and empirical benchmarks, remaining self-contained without load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=YCWjhGrJFD
2024
-
[5]
Kevin Clark, Paul Vicol, Kevin Swersky, and David J. Fleet. Directly fine-tuning diffusion models on differentiable rewards. InThe Twelfth International Conference on Learning Repre- sentations, 2024. URLhttps://openreview.net/forum?id=1vmSEVL19f
2024
-
[6]
Paddleocr 3.0 technical report,
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr 3.0 technical report,
-
[7]
URLhttps://arxiv.org/abs/2507.05595
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Haoyou Deng, Keyu Yan, Chaojie Mao, Xiang Wang, Yu Liu, Changxin Gao, and Nong Sang. Densegrpo: From sparse to dense reward for flow matching model alignment.arXiv preprint arXiv:2601.20218, 2026
-
[9]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[10]
TreeGRPO: Tree-advantage GRPO for online RL post-training of diffusion models
Zheng Ding and Weirui Ye. TreeGRPO: Tree-advantage GRPO for online RL post-training of diffusion models. InThe Fourteenth International Conference on Learning Representations,
-
[11]
URLhttps://openreview.net/forum?id=3rZdp4TmUb
-
[12]
Springer
Arnaud Doucet et al.Sequential Monte Carlo methods in practice, volume 1. Springer
-
[13]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[14]
Online reward-weighted fine-tuning of flow matching with wasserstein regularization
Jiajun Fan, Shuaike Shen, Chaoran Cheng, Yuxin Chen, Chumeng Liang, and Ge Liu. Online reward-weighted fine-tuning of flow matching with wasserstein regularization. InThe Thirteenth International Conference on Learning Representations, 2025. 10
2025
-
[15]
Truncated proximal policy optimization, 2025
Tiantian Fan, Lingjun Liu, Yu Yue, Jiaze Chen, Chengyi Wang, Qiying Yu, Chi Zhang, Zhiqi Lin, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Bole Ma, Mofan Zhang, Gaohong Liu, Ru Zhang, Haotian Zhou, Cong Xie, Ruidong Zhu, Zhi Zhang, Xin Liu, Mingxuan Wang, Lin Yan, and Yonghui Wu. Truncated proximal policy optimization, 2025. URLhttps://arxiv.org/abs/ 2506.15050
-
[16]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
2023
-
[17]
Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback
Hiroki Furuta, Heiga Zen, Dale Schuurmans, Aleksandra Faust, Yutaka Matsuo, Percy Liang, and Sherry Yang. Improving dynamic object interactions in text-to-video generation with ai feedback.arXiv preprint arXiv:2412.02617, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Murphy, and Tim Salimans
Ruiqi Gao, Emiel Hoogeboom, Jonathan Heek, Valentin De Bortoli, Kevin P. Murphy, and Tim Salimans. Diffusion meets flow matching: Two sides of the same coin. 2024. URL https://diffusionflow.github.io/
2024
-
[19]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[20]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Shashank Gupta, Chaitanya Ahuja, Tsung-Yu Lin, Sreya Dutta Roy, Harrie Oosterhuis, Maarten de Rijke, and Satya Narayan Shukla. A simple and effective reinforcement learning method for text-to-image diffusion fine-tuning.arXiv preprint arXiv:2503.00897, 2025
-
[23]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. URL https:// arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[25]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models.arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
T2i-compbench: A compre- hensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A compre- hensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
2023
-
[27]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
A natural policy gradient.Advances in neural information processing systems, 14, 2001
Sham M Kakade. A natural policy gradient.Advances in neural information processing systems, 14, 2001
2001
-
[29]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[30]
Onactor-critic algorithms.SIAM journal on Control and Optimization, 42(4):1143–1166, 2003
Vijay R Konda and John N Tsitsiklis. Onactor-critic algorithms.SIAM journal on Control and Optimization, 42(4):1143–1166, 2003
2003
-
[31]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InICML, 2022
2022
-
[34]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde, 2025. URL https: //arxiv.org/abs/2507.21802
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Align- ing diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Yusuke Kato, and Kazuki Kozuka. Align- ing diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
2024
-
[36]
Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion models.arXiv preprint arXiv:2509.06040, 2025
-
[37]
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models.arXiv preprint arXiv:2310.10505, 2023
-
[38]
Aesthetic post-training diffusion models from generic preferences with step-by-step preference optimization
Zhanhao Liang, Yuhui Yuan, Shuyang Gu, Bohan Chen, Tiankai Hang, Mingxi Cheng, Ji Li, and Liang Zheng. Aesthetic post-training diffusion models from generic preferences with step-by-step preference optimization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13199–13208, 2025
2025
-
[39]
Scaling laws for diffusion transformers
Zhengyang Liang, Hao He, Ceyuan Yang, and Bo Dai. Scaling laws for diffusion transformers. arXiv preprint arXiv:2410.08184, 2024
-
[40]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation.arXiv preprint arXiv:2501.08316, 2025
-
[42]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[43]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code,
-
[44]
URLhttps://arxiv.org/abs/2412.06264
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Jiashun Liu, Johan Obando-Ceron, Han Lu, Yancheng He, Weixun Wang, Wenbo Su, Bo Zheng, Pablo Samuel Castro, Aaron Courville, and Ling Pan. Asymmetric proximal policy optimization: mini-critics boost llm reasoning.arXiv preprint arXiv:2510.01656, 2025
-
[46]
Flow-GRPO: Training flow matching models via online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=oCBKGw5HNf
2025
-
[47]
Videodpo: Omni-preference alignment for video diffusion generation
Runtao Liu, Haoyu Wu, Ziqiang Zheng, Chen Wei, Yingqing He, Renjie Pi, and Qifeng Chen. Videodpo: Omni-preference alignment for video diffusion generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8009–8019, 2025
2025
-
[48]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=XVjTT1nw5z. 12
2023
-
[49]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[50]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
2025
-
[51]
M., Weber, E., Choi, H., Feng, H., and Kanazawa, A
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients, 2025. URL https: //arxiv.org/abs/2507.21053
-
[52]
Training diffusion models towards diverse image generation with reinforcement learning
Zichen Miao, Jiang Wang, Ze Wang, Zhengyuan Yang, Lijuan Wang, Qiang Qiu, and Zicheng Liu. Training diffusion models towards diverse image generation with reinforcement learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10844–10853, 2024
2024
-
[53]
Asynchronous methods for deep reinforce- ment learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforce- ment learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
1928
-
[54]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[55]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[56]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[57]
Aligning text-to- image diffusion models with reward backpropagation, 2023
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text-to- image diffusion models with reward backpropagation, 2023
2023
-
[58]
Video diffusion alignment via reward gradients, 2024
Mihir Prabhudesai, Russell Mendonca, Zheyang Qin, Katerina Fragkiadaki, and Deepak Pathak. Video diffusion alignment via reward gradients, 2024. URL https://arxiv.org/abs/2407. 08737
2024
-
[59]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[60]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[61]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[62]
High- dimensional continuous control using generalized advantage estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InProceedings of the International Conference on Learning Representations (ICLR), 2016
2016
-
[63]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[64]
Team Seawead, Ceyuan Yang, Zhijie Lin, Yang Zhao, Shanchuan Lin, Zhibei Ma, Haoyuan Guo, Hao Chen, Lu Qi, Sen Wang, et al. Seaweed-7b: Cost-effective training of video generation foundation model.arXiv preprint arXiv:2504.08685, 2025. 13
- [65]
-
[66]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Dingyuan Shi, Yong Wang, Hangyu Li, and Xiangxiang Chu. Preference alignment for diffusion model via explicit denoised distribution estimation.arXiv preprint arXiv:2411.14871, 2024
-
[68]
Deterministic policy gradient algorithms
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. In Eric P. Xing and Tony Jebara, editors,Proceedings of the 31st International Conference on Machine Learning, volume 32 ofProceedings of Machine Learning Research, pages 387–395, Bejing, China, 22–24 Jun 2014. PMLR. URL h...
2014
-
[69]
A general framework for inference-time scaling and steering of diffusion models
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models. InForty-second International Conference on Machine Learning, 2025. URL https: //openreview.net/forum?id=Jp988ELppQ
2025
-
[70]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=St1giarCHLP
2021
-
[71]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[72]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[73]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[74]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
1992
-
[77]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Prac- tical and asymptotically exact conditional sampling in diffusion models.Advances in Neural Information Processing Systems, 2023
Luhuan Wu, Brian L Trippe, Christian Naesseth, David Blei, and John P Cunningham. Prac- tical and asymptotically exact conditional sampling in diffusion models.Advances in Neural Information Processing Systems, 2023
2023
-
[79]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023. 14
2096
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.