AndroidDaily: A Verifiable Benchmark for Mobile GUI Agents on Real-World Closed-Source Applications
Pith reviewed 2026-06-29 17:49 UTC · model grok-4.3
The pith
AndroidDaily benchmark enables verifiable evaluation of GUI agents on 94 closed-source Android apps via visual guidelines alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
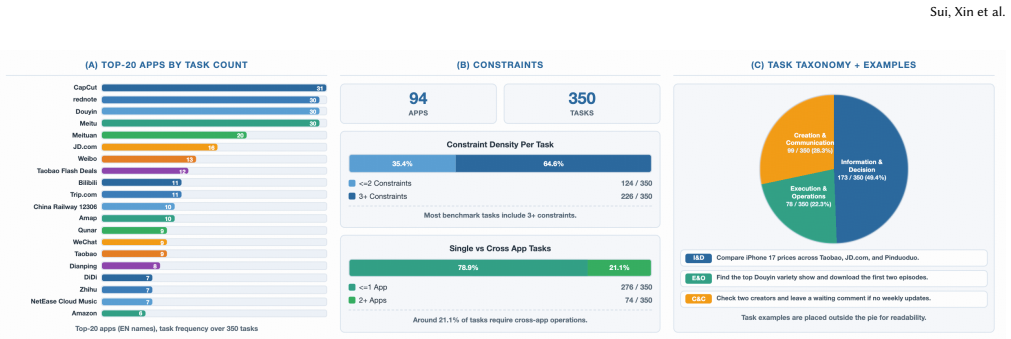
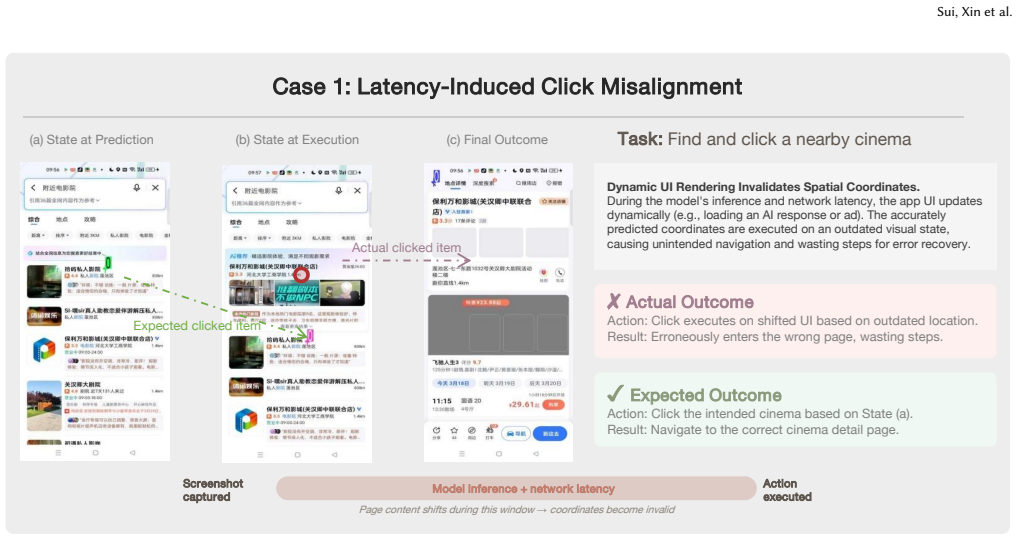
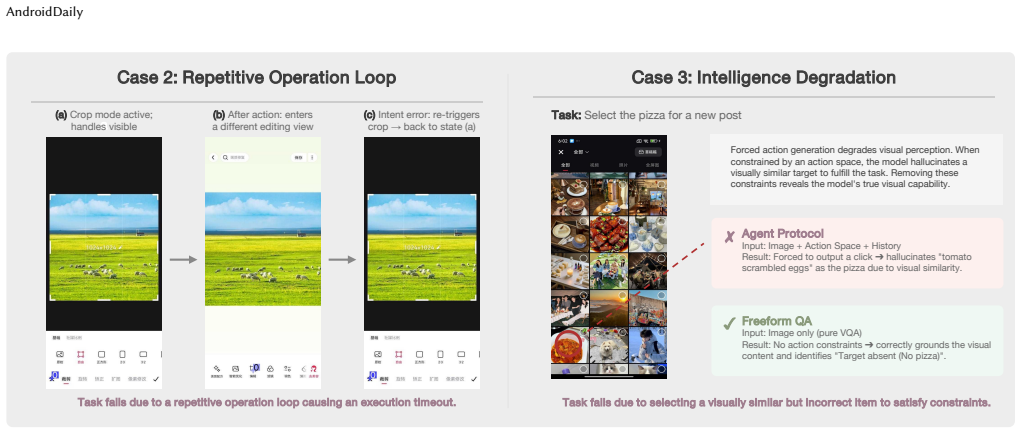
The central claim is that by defining tasks through external observable guidelines in three categories—operational obligations, output quality, and negative constraints—GRADE can automatically and reliably evaluate whether an agent's sequence of screen actions completes a task on closed-source apps, matching human judgment at 87.37 percent while revealing that leading models achieve at most 62 percent success.
What carries the argument
GRADE, a process-aware evaluator that applies three-tiered external guidelines (operational obligations, output quality, negative constraints) to visual trajectories for step-level diagnostic judgments.
If this is right
- Real-world closed-source apps become usable for benchmarking GUI agents in daily categories like shopping and transportation.
- Evaluation of long-horizon mobile interactions becomes automatic without needing hidden states.
- The 62 percent success rate identifies a measurable gap in current model capabilities for practical workflows.
- Step-level diagnostic judgments allow targeted identification of where agents fail.
Where Pith is reading between the lines
- GRADE could be adapted to provide feedback signals during agent training on similar tasks.
- The benchmark structure may extend to other closed platforms such as iOS applications.
- Collecting more tasks in underrepresented categories would test whether the evaluation method holds at larger scale.
Load-bearing premise
The three-tiered external guidelines suffice to judge task success accurately from visual trajectories without access to any internal application state.
What would settle it
A calculation showing systematic disagreement between GRADE and humans on tasks whose success depends on unobservable internal changes such as account balances or order confirmations.
Figures



read the original abstract
The rapid development of GUI foundation models and mobile GUI agents has spurred numerous evaluation benchmarks, yet most rely on simulated environments or open-source applications, leaving real-world closed-source applications largely unevaluated. The core difficulty is that closed-source applications do not expose internal states, making traditional automatic verification inapplicable. To bridge this gap, we introduce AndroidDaily, a large-scale benchmark comprising 350 realistic daily-use tasks across 94 high-frequency Android applications spanning transportation, shopping, local services, entertainment, content creation, social media, and everyday utilities. To enable automatic and verifiable assessment in these opaque environments, we propose Guideline-grounded Reviewer for Automatic Diagnostic Evaluation (GRADE), a process-aware evaluator built on a three-tiered system of observable external guidelines: operational obligations, output quality, and negative constraints. GRADE tracks the agent's visual trajectory against these criteria and produces step-level diagnostic judgments, turning long-horizon, open-ended mobile interactions into verifiable evaluation without relying on hidden internal states. Experiments show that GRADE achieves 87.37\% agreement with human evaluators. The strongest model reaches a 62.0\% success rate on AndroidDaily, highlighting a substantial gap between current reasoning capabilities and practical execution in realistic mobile workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AndroidDaily, a benchmark comprising 350 realistic daily-use tasks across 94 closed-source Android applications in categories including transportation, shopping, local services, entertainment, content creation, social media, and utilities. It proposes GRADE, a process-aware evaluator that uses a three-tiered system of observable external guidelines (operational obligations, output quality, and negative constraints) to generate step-level diagnostic judgments from visual trajectories alone, without access to internal application states. The central empirical results are that GRADE achieves 87.37% agreement with human evaluators and that the strongest tested model attains a 62.0% success rate, indicating a gap between current capabilities and practical mobile workflows.
Significance. If the results hold, this work would be significant for GUI agent and mobile automation research by addressing the longstanding limitation that prior benchmarks rely on simulated environments or open-source apps with accessible internal states. The empirical human-agreement validation of GRADE supplies direct evidence that external visual criteria can support verifiable evaluation on opaque real-world apps, which could enable more realistic and scalable benchmarking. The scale (350 tasks, 94 apps) and focus on daily-use scenarios add practical value if the evaluation protocol is fully documented.
major comments (2)
- [Abstract] Abstract: The abstract reports concrete numbers (87.37% agreement, 62% success) but supplies no details on task curation, human rater protocol, statistical tests, or inter-rater reliability. These omissions are load-bearing for the central claim that the three-tiered guidelines suffice to determine task success from visual trajectories alone.
- [GRADE description] The premise that the three-tiered external guidelines are sufficient to determine task success from visual trajectories alone (without internal state) is stated as the foundation of GRADE, yet the manuscript provides no concrete examples of guideline application, disagreement resolution, or edge cases across the 350 tasks. This makes it difficult to assess whether the 87.37% agreement generalizes beyond the reported sample.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity of our claims regarding GRADE's evaluation protocol. We address each major comment below and commit to revisions where the manuscript can be improved without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports concrete numbers (87.37% agreement, 62% success) but supplies no details on task curation, human rater protocol, statistical tests, or inter-rater reliability. These omissions are load-bearing for the central claim that the three-tiered guidelines suffice to determine task success from visual trajectories alone.
Authors: We agree that the abstract's brevity omits these details, which are load-bearing for the central claim. The full manuscript details task curation in Section 3, the human rater protocol and inter-rater reliability metrics (including Fleiss' kappa) in Section 4.2, and statistical significance tests in Section 4.3. In the revision, we will expand the abstract with one additional sentence summarizing the human validation protocol and evaluation methodology while remaining within length constraints. revision: yes
-
Referee: [GRADE description] The premise that the three-tiered external guidelines are sufficient to determine task success from visual trajectories alone (without internal state) is stated as the foundation of GRADE, yet the manuscript provides no concrete examples of guideline application, disagreement resolution, or edge cases across the 350 tasks. This makes it difficult to assess whether the 87.37% agreement generalizes beyond the reported sample.
Authors: We acknowledge that the absence of concrete examples limits the reader's ability to evaluate generalization. The manuscript reports aggregate agreement but does not illustrate individual guideline applications or disagreement cases. In the revised version, we will add a new subsection (or appendix) with 4-5 representative examples drawn from the 350 tasks, covering guideline application, resolution of disagreements between GRADE and humans, and edge cases such as partial completions or ambiguous visual outcomes. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a benchmark (AndroidDaily) and an evaluator (GRADE) based on observable external guidelines, then reports direct empirical measurements: 87.37% agreement between GRADE and human evaluators on the same visual trajectories, plus a 62.0% success rate for the strongest model. No equations, fitted parameters, derivations, or self-citation chains appear in the load-bearing claims. The central premise that the three-tiered guidelines suffice for verifiable judgments is tested by the agreement metric itself rather than assumed or reduced to prior inputs by construction. The work is therefore self-contained empirical benchmark construction with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption External visual guidelines (operational obligations, output quality, negative constraints) are sufficient to determine task success from screen trajectories alone
invented entities (1)
-
GRADE evaluator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reyna Abhyankar, Qi Qi, and Yiying Zhang. 2025. Osworld-human: Bench- marking the efficiency of computer-use agents.arXiv preprint arXiv:2506.16042 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
2026.System Card: Claude Opus 4.6
Anthropic. 2026.System Card: Claude Opus 4.6. Technical Report. Anthropic. https://www-cdn.anthropic.com/6a5fa276ac68b9aeb0c8b6af5fa36326e0e166dd. pdf
2026
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sağnak Taşırlar. 2023. Introducing our Multimodal Models. https://www.adept.ai/blog/fuyu-8b
2023
-
[6]
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al
- [7]
-
[8]
ByteDance Seed. 2026. Seed1.8 Model Card: Towards Generalized Real-World Agency.arXiv preprint arXiv:2603.20633(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
2026.Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
ByteDance Seed. 2026.Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity. Technical Report. ByteDance. https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/ seed2/0214/Seed2.0%20Model%20Card.pdf
2026
-
[10]
Jingxuan Chen, Derek Yuen, Bin Xie, Yuhao Yang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, et al . 2024. Spa-bench: A comprehensive benchmark for smartphone agent evaluation. InNeurIPS 2024 Workshop on Open-World Agents
2024
-
[11]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. 2024. Seeclick: Harnessing gui grounding for advanced visual gui agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9313–9332
2024
-
[12]
Xu, Siva Reddy, Graham Neubig, Quentin Cappart, Russ Salakhutdinov, and Nicolas Chapados
Thibault Le Sellier de Chezelles, Maxime Gasse, Alexandre Lacoste, Massimo Caccia, Alexandre Drouin, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han Lù, Ori Yoran, De- han Kong, Frank F. Xu, Siva Reddy, Graham Neubig, Quentin Cappart, Russ Salakhutdinov, and Nicolas Chapados. 2025. The BrowserGym Ec...
2025
-
[13]
Biplab Deka, Zifeng Huang, Chad Franzen, Joshua Hibschman, Daniel Afergan, Yang Li, Jeffrey Nichols, and Ranjitha Kumar. 2017. Rico: A mobile app dataset for building data-driven design applications. InProceedings of the 30th annual ACM symposium on user interface software and technology. 845–854
2017
-
[14]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems36 (2023), 28091–28114
2023
- [15]
- [16]
-
[17]
2025.Gemini 3 Flash
Google DeepMind. 2025.Gemini 3 Flash. Technical Report. Google DeepMind. https://deepmind.google/models/gemini/flash/
2025
-
[18]
2025.Gemini 3 Pro Model Card
Google DeepMind. 2025.Gemini 3 Pro Model Card. Technical Report. Google DeepMind. https://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-Pro-Model-Card.pdf
2025
-
[19]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al . 2024. A survey on llm-as-a-judge.The Innovation(2024)
2024
-
[20]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6864–6890
2024
-
[21]
GLM-V Team: Wenyi Hong, Wenmeng Yu, Xiaotao Gu, et al. 2025. GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning.arXiv preprint arXiv:2507.01006(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. 2024. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14281–14290
2024
-
[23]
Yu-Chung Hsiao, Fedir Zubach, Gilles Baechler, Srinivas Sunkara, Victor Cărbune, Jason Lin, Maria Wang, Yun Zhu, and Jindong Chen. 2025. Screenqa: Large- scale question-answer pairs over mobile app screenshots. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Techn...
2025
-
[24]
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem AlShikh, and Ruslan Salakhutdinov. 2024. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. InEuropean Conference on Computer Vision. Springer, 161–178
2024
-
[25]
Pei Ke, Bosi Wen, Andrew Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan Wang, Aohan Zeng, Yuxiao Dong, Hongning Wang, et al. 2024. Critiquellm: To- wards an informative critique generation model for evaluation of large language model generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long P...
2024
-
[26]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 881–905
2024
-
[27]
Quyu Kong, Xu Zhang, Zhenyu Yang, Nolan Gao, Chen Liu, Panrong Tong, Chenglin Cai, Hanzhang Zhou, Jianan Zhang, Liangyu Chen, et al. 2025. Mo- bileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive and MCP-Augmented Environments.arXiv preprint arXiv:2512.19432(2025)
- [28]
-
[29]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. 2025. Screenspot-pro: Gui grounding for professional high-resolution computer use. InProceedings of the 33rd ACM International Conference on Multimedia. 8778–8786
2025
-
[31]
Yang Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhiwei Guan. 2020. Widget captioning: Generating natural language description for mobile user AndroidDaily interface elements. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 5495–5510
2020
- [32]
-
[33]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2017. Droidbot: a lightweight ui-guided test input generator for android. In2017 IEEE/ACM 39th international conference on software engineering companion (ICSE-C). IEEE, 23–26
2017
-
[34]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. InThe twelfth international conference on learning representations
2023
-
[35]
Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang
-
[36]
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration. InInternational Conference on Learning Representations (ICLR). https://arxiv.org/abs/1802.08802
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. 2025. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al . 2024. Androidworld: A dynamic benchmarking envi- ronment for autonomous agents.arXiv preprint arXiv:2405.14573(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lilli- crap. 2023. Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems36 (2023), 59708–59728
2023
- [40]
- [41]
-
[42]
Jianqiang Wan, Sibo Song, Wenwen Yu, Yuliang Liu, Wenqing Cheng, Fei Huang, Xiang Bai, Cong Yao, and Zhibo Yang. 2024. Omniparser: A unified framework for text spotting key information extraction and table recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15641–15653
2024
-
[43]
Bryan Wang, Gang Li, Xin Zhou, Zhourong Chen, Tovi Grossman, and Yang Li. 2021. Screen2words: Automatic mobile ui summarization with multimodal learning. InThe 34th Annual ACM Symposium on User Interface Software and Technology. 498–510
2021
-
[44]
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration.Advances in Neural Information Processing Systems37 (2024), 2686–2710
2024
- [45]
-
[46]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. Autodroid: Llm-powered task automation in android. InProceedings of the 30th annual international conference on Mobile computing and networking. 543–557
2024
- [47]
-
[48]
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al . 2024. OS- ATLAS: A Foundation Action Model for Generalist GUI Agents.arXiv preprint arXiv:2410.23218(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [49]
-
[50]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. 2024. Os- world: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems37 (2024), 52040–52094
2024
- [51]
-
[52]
Tianqi Xu, Linyao Chen, Dai-Jie Wu, Yanjun Chen, Zecheng Zhang, Xiang Yao, Zhiqiang Xie, Yongchao Chen, Shilong Liu, Bochen Qian, Philip Torr, Bernard Ghanem, and Guohao Li. 2024. CRAB: Cross-environment Agent Benchmark for Multimodal Language Model Agents. arXiv:2407.01511 [cs.AI] https://arxiv.org/ abs/2407.01511
- [53]
- [54]
- [55]
- [56]
-
[57]
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. 2025. Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. 2024. Ferret-ui: Grounded mobile ui understanding with multimodal llms. InEuropean Conference on Computer Vision. Springer, 240–255
2024
- [59]
-
[60]
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, et al. 2025. Ufo: A ui-focused agent for windows os interaction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
2025
-
[61]
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. 2025. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–20
2025
-
[62]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
- [63]
-
[64]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. 2023. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [65]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.