ClothTransformer: Unified Latent-Space Transformers for Scalable Cloth Simulation
Pith reviewed 2026-06-29 09:47 UTC · model grok-4.3
The pith
A single Transformer architecture simulates cloth across body-driven, robotic, and collision scenarios by operating in a fixed-size latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
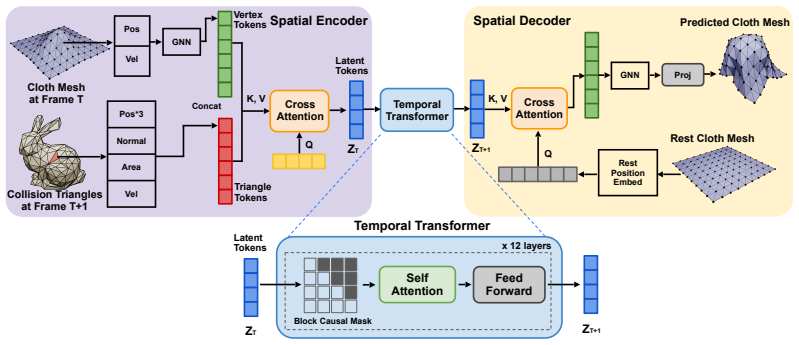
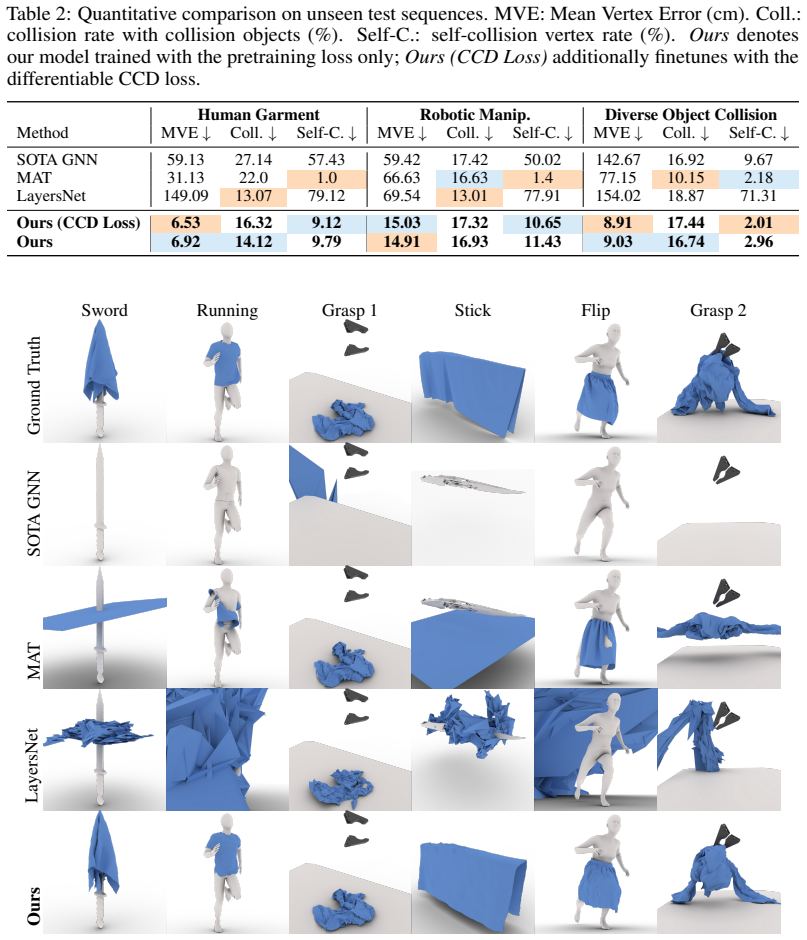
ClothTransformer reformulates cloth simulation as autoregressive sequence modeling inside a learned latent space. A unified Transformer processes a fixed set of latent tokens that compress arbitrary-resolution meshes, allowing the same weights to drive body-driven garments, robotic manipulation, and free-fall collisions. The model reports 4–9× lower error than prior state-of-the-art methods on all three tasks and suppresses penetrations through a differentiable continuous collision detection module trained on a new 493.4 k frame multi-scenario dataset.
What carries the argument
Autoregressive Transformer operating on a fixed-size set of latent tokens that compress the input mesh.
If this is right
- One set of weights suffices for body-driven garments, robotic manipulation, and free-fall collisions.
- Computation time for dynamics stays constant when mesh resolution increases.
- A differentiable CCD module removes penetration artifacts across all three scenarios.
- Error drops by a factor of roughly four to nine relative to earlier specialized networks.
Where Pith is reading between the lines
- The same latent-token approach could extend to other thin-shell or volumetric deformable objects without redesigning the architecture.
- Because dynamics are computed at fixed latent size, real-time applications could raise mesh detail without raising frame cost.
- The multi-scenario dataset may expose shared low-level motion patterns that current single-scenario models overlook.
Load-bearing premise
A single learned compression into latent tokens can capture the full range of cloth dynamics, contacts, and collisions without missing physical inaccuracies that appear only outside the training distribution.
What would settle it
Train on the provided multi-scenario dataset, then evaluate penetration count and error on a held-out high-resolution mesh or an unseen combination of body motion and external forces.
Figures







read the original abstract
Unified and scalable Transformers have recently achieved remarkable success in modeling diverse phenomena traditionally associated with computer graphics, such as 3D visual effects, rendering processes, and motion in videos. In this work, we take a step further by investigating whether modern Transformer techniques can tackle the challenging task of cloth simulation. To this end, we present ClothTransformer, a framework that reformulates cloth simulation as autoregressive sequence modeling in a learned latent space. Existing neural cloth simulators are largely specialized to single scenarios, intrinsically coupled to the mesh discretization, and lack robust collision handling. Our approach addresses these limitations through three contributions: (1) a unified Transformer architecture that handles diverse scenarios -- body-driven garments, robotic manipulation, and free-fall collisions -- under a single model and achieves approximately $4$--$9{\times}$ lower error than prior state-of-the-art methods across all scenarios; (2) a scalable latent-space formulation that compresses arbitrary-resolution meshes into a fixed-size set of latent tokens, making temporal dynamics computation independent of mesh resolution; and (3) a diverse-scenario high-fidelity penetration-free dataset of ${\sim}$493.4k frames spanning all three settings, which enables a differentiable Continuous Collision Detection (CCD) module to suppress penetration artifacts. Project Page: https://yucrazing.github.io/clothtransformer/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ClothTransformer, a Transformer-based framework that reformulates cloth simulation as autoregressive sequence modeling in a learned latent space. It claims a single unified architecture handles body-driven garments, robotic manipulation, and free-fall collisions, achieving 4–9× lower error than prior SOTA methods; a scalable formulation compresses arbitrary-resolution meshes to a fixed set of latent tokens (making dynamics computation resolution-independent); and a new ~493.4k-frame penetration-free dataset enables a differentiable CCD module to suppress artifacts.
Significance. If the central claims on error reduction and collision fidelity hold under rigorous validation, the work would represent a meaningful advance in neural cloth simulation by demonstrating a unified, resolution-independent latent-space approach that could reduce reliance on scenario-specific models and improve robustness in graphics and robotics applications.
major comments (2)
- [Contribution (2)] Contribution (2): the central claim that a single fixed-size latent compression faithfully encodes all information needed for contacts and collisions across the three scenarios (including high-frequency free-fall dynamics) is load-bearing for the unified-architecture result, yet the manuscript provides no ablation on latent dimensionality, no proof that the compression objective preserves fine-scale geometry required by the downstream differentiable CCD, and no quantitative check that decoded states remain physically valid outside the training distribution.
- [Contribution (1)] The 4–9× error reduction (Contribution (1)) is presented as evidence that one model suffices for all scenarios, but without reported baselines, per-scenario breakdowns, or controls for mesh resolution in the quantitative results, it is impossible to determine whether the improvement stems from the latent formulation or from dataset-specific advantages.
minor comments (2)
- The abstract states the dataset spans all three settings but does not specify the distribution of frames across scenarios or the exact mesh resolutions used; adding this breakdown would clarify the scope of the unified claim.
- Notation for the latent tokens and the autoregressive modeling objective should be introduced with explicit equations in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify important gaps in validation that we can address through targeted additions to the experiments and text. We outline our responses below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Contribution (2)] the central claim that a single fixed-size latent compression faithfully encodes all information needed for contacts and collisions across the three scenarios (including high-frequency free-fall dynamics) is load-bearing for the unified-architecture result, yet the manuscript provides no ablation on latent dimensionality, no proof that the compression objective preserves fine-scale geometry required by the downstream differentiable CCD, and no quantitative check that decoded states remain physically valid outside the training distribution.
Authors: We agree that an explicit ablation on latent token count would strengthen the central claim. In the revision we will add a table reporting reconstruction error, collision metrics, and downstream simulation error for 32/64/128/256 latent tokens on all three scenarios. For fine-scale geometry preservation we will add a quantitative comparison of edge-length and curvature statistics between input meshes and decoded outputs before and after the CCD step. Regarding out-of-distribution physical validity, we will report penetration counts and energy drift on a held-out test split drawn from each scenario (distinct sequences, not just frames) and include a short discussion of failure modes. These additions directly address the load-bearing nature of the claim. revision: yes
-
Referee: [Contribution (1)] The 4–9× error reduction (Contribution (1)) is presented as evidence that one model suffices for all scenarios, but without reported baselines, per-scenario breakdowns, or controls for mesh resolution in the quantitative results, it is impossible to determine whether the improvement stems from the latent formulation or from dataset-specific advantages.
Authors: We will revise Section 4 to include (i) a per-scenario error table that lists mean and max vertex error for each of the three scenarios against every baseline, (ii) explicit mesh-resolution values used for each baseline (noting that our method is resolution-independent while baselines are not), and (iii) a short control experiment that trains separate per-scenario models on the same data to isolate the benefit of unified training. The 4–9× figure already aggregates across scenarios; the new table will make the per-scenario contributions transparent. revision: yes
Circularity Check
No circularity: empirical ML framework with no derivations or self-referential reductions
full rationale
The provided abstract and text describe a neural architecture (Transformer in learned latent space) and empirical contributions: unified model across scenarios, latent compression for scalability, and a new dataset with differentiable CCD. No equations, first-principles derivations, or predictions that reduce to fitted inputs by construction are present. Performance claims (4-9x lower error) are experimental, not derived from self-definition or self-citation chains. The latent-token compression is presented as a design choice, not a tautological renaming of inputs. This is a standard non-circular ML methods paper; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
David Baraff and Andrew P. Witkin. Large steps in cloth simulation. In Steve Cunningham, Walt Bransford, and Michael F. Cohen, editors,Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 1998, Orlando, FL, USA, July 19-24, 1998, pages 43–54. ACM, 1998. doi: 10.1145/280814.280821. URL https: //doi.org/10.1145...
-
[2]
Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation
Hugo Bertiche, Meysam Madadi, Emilio Tylson, and Sergio Escalera. Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 5451–5460. IEEE, 2021. doi: 10.1109/ICCV48922.2021.00542. URL https://doi.org/10.1109...
-
[3]
Neural cloth simulation.ACM Transac- tions on Graphics (TOG), 41(6):1–14, 2022
Hugo Bertiche, Meysam Madadi, and Sergio Escalera. Neural cloth simulation.ACM Transac- tions on Graphics (TOG), 41(6):1–14, 2022
2022
-
[4]
Robust treatment of collisions, contact and friction for cloth animation.ACM Trans
Robert Bridson, Ronald Fedkiw, and John Anderson. Robust treatment of collisions, contact and friction for cloth animation.ACM Trans. Graph., 21(3):594–603, 2002. doi: 10.1145/ 566654.566623. URLhttps://doi.org/10.1145/566654.566623
-
[5]
Efficient learning of mesh-based physical simulation with bi-stride multi-scale graph neural network
Yadi Cao, Menglei Chai, Minchen Li, and Chenfanfu Jiang. Efficient learning of mesh-based physical simulation with bi-stride multi-scale graph neural network. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu...
2023
-
[6]
Chiaramonte, Kevin Carlberg, and Eitan Grinspun
Yue Chang, Peter Yichen Chen, Zhecheng Wang, Maurizio M. Chiaramonte, Kevin Carlberg, and Eitan Grinspun. Licrom: Linear-subspace continuous reduced order modeling with neural fields. In June Kim, Ming C. Lin, and Bernd Bickel, editors,SIGGRAPH Asia 2023 Conference Papers, SA 2023, Sydney, NSW, Australia, December 12-15, 2023, pages 111:1–111:12. ACM, 202...
-
[7]
Peter Yichen Chen, Jinxu Xiang, Dong Heon Cho, Yue Chang, G. A. Pershing, Henrique Teles Maia, Maurizio M. Chiaramonte, Kevin T. Carlberg, and Eitan Grinspun. CROM: continuous reduced-order modeling of pdes using implicit neural representations. InThe Eleventh Interna- tional Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023...
2023
-
[8]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
2023
-
[9]
Artur Grigorev, Michael J. Black, and Otmar Hilliges. HOOD: hierarchical graphs for generalized modelling of clothing dynamics. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 16965–16974. IEEE, 2023. doi: 10.1109/CVPR52729.2023.01627. URL https: //doi.org/10.1109/CVPR52729.2023.01627
-
[10]
Black, Otmar Hilliges, and Bernhard Thomaszewski
Artur Grigorev, Giorgio Becherini, Michael J. Black, Otmar Hilliges, and Bernhard Thomaszewski. Contourcraft: Learning to resolve intersections in neural multi-garment simula- tions. In Andres Burbano, Denis Zorin, and Wojciech Jarosz, editors,ACM SIGGRAPH 2024 Conference Papers, SIGGRAPH 2024, Denver, CO, USA, 27 July 2024- 1 August 2024, page 81. ACM, 2...
-
[11]
Make-it- animatable: An efficient framework for authoring animation-ready 3d characters
Zhiyang Guo, Jinxu Xiang, Kai Ma, Wengang Zhou, Houqiang Li, and Ran Zhang. Make-it- animatable: An efficient framework for authoring animation-ready 3d characters. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10783–10792, 2025. 10
2025
-
[12]
Predicting physics in mesh- reduced space with temporal attention
Xu Han, Han Gao, Tobias Pfaff, Jian-Xun Wang, and Liping Liu. Predicting physics in mesh- reduced space with temporal attention. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=XctLdNfCmP
2022
-
[13]
Jing He, Yuanjie Cao, TangSheng Guo, Wei Liang, Jin Huang, Qian Liu, Huaiyuan Yang, Sen Liu, and Ruhan He. From physically-based to learning-based in cloth simulation: evolution and future - a scoping review.Vis. Comput., 41(15):12711–12742, 2025. doi: 10.1007/ S00371-025-04182-3. URLhttps://doi.org/10.1007/s00371-025-04182-3
-
[14]
Holzschuh, Qiang Liu, Georg Kohl, and Nils Thuerey
Benjamin J. Holzschuh, Qiang Liu, Georg Kohl, and Nils Thuerey. Pde-transformer: Efficient and versatile transformers for physics simulations. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025. OpenReview.net,
2025
-
[15]
URLhttps://openreview.net/forum?id=3BaJMRaPSx
-
[16]
Chitalu, Huancheng Lin, and Taku Komura
Kemeng Huang, Floyd M. Chitalu, Huancheng Lin, and Taku Komura. GIPC: fast and stable gauss-newton optimization of IPC barrier energy.ACM Trans. Graph., 43(2):23:1–23:18, 2024. doi: 10.1145/3643028. URLhttps://doi.org/10.1145/3643028
-
[17]
Generating datasets of 3d garments with sewing patterns
Maria Korosteleva and Sung-Hee Lee. Generating datasets of 3d garments with sewing patterns. arXiv preprint arXiv:2109.05633, 2021
-
[18]
Langlois, Denis Zorin, Daniele Panozzo, Chenfanfu Jiang, and Danny M
Minchen Li, Zachary Ferguson, Teseo Schneider, Timothy R. Langlois, Denis Zorin, Daniele Panozzo, Chenfanfu Jiang, and Danny M. Kaufman. Incremental potential contact: intersection- and inversion-free, large-deformation dynamics.ACM Trans. Graph., 39(4):49, 2020. doi: 10.1145/3386569.3392425. URLhttps://doi.org/10.1145/3386569.3392425
-
[19]
Wang, Timur Levent Kesdogan, Duygu Ceylan, and Olga Sorkine- Hornung
Peizhuo Li, Tuanfeng Y . Wang, Timur Levent Kesdogan, Duygu Ceylan, and Olga Sorkine- Hornung. Neural garment dynamics via manifold-aware transformers.Comput. Graph. Forum, 43(2):i–iii, 2024. doi: 10.1111/CGF.15028. URLhttps://doi.org/10.1111/cgf.15028
-
[20]
Swingar: Spectrum-inspired neural dynamic deformation for free-swinging garments.IEEE Trans
Tianxing Li, Rui Shi, Qing Zhu, and Takashi Kanai. Swingar: Spectrum-inspired neural dynamic deformation for free-swinging garments.IEEE Trans. Vis. Comput. Graph., 30(10): 6913–6927, 2024. doi: 10.1109/TVCG.2023.3346055. URL https://doi.org/10.1109/ TVCG.2023.3346055
-
[21]
Gartrans: Transformer-based archi- tecture for dynamic and detailed garment deformation.Comput
Tianxing Li, Zhi Qiao, Zihui Li, Rui Shi, and Qing Zhu. Gartrans: Transformer-based archi- tecture for dynamic and detailed garment deformation.Comput. Vis. Media, 11(6):1209–1226,
-
[22]
URL https://doi.org/10.26599/cvm.2025
doi: 10.26599/CVM.2025.9450448. URL https://doi.org/10.26599/cvm.2025. 9450448
-
[23]
Spectrum-enhanced graph attention network for garment mesh deformation.IEEE Trans
Tianxing Li, Rui Shi, Qing Zhu, Liguo Zhang, and Takashi Kanai. Spectrum-enhanced graph attention network for garment mesh deformation.IEEE Trans. Pattern Anal. Mach. Intell., 47(8):7153–7170, 2025. doi: 10.1109/TPAMI.2025.3570523. URL https://doi.org/10. 1109/TPAMI.2025.3570523
-
[24]
SENC: handling self-collision in neural cloth simulation
Zhouyingcheng Liao, Sinan Wang, and Taku Komura. SENC: handling self-collision in neural cloth simulation. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part IX, volume 15067 ofLecture No...
-
[25]
Meshgraphnetrp: Improving generalization of gnn-based cloth simulation
Emmanuel Ian Libao, Myeongjin Lee, Sumin Kim, and Sung-Hee Lee. Meshgraphnetrp: Improving generalization of gnn-based cloth simulation. In Julien Pettré, Barbara Solenthaler, Rachel McDonnell, and Christopher Peters, editors,Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games, MIG 2023, Rennes, France, November 15-17, 2023, pa...
-
[26]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2023. 11
2023
-
[27]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
2023
-
[28]
Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, and Michael J. Black. Learning to dress 3d people in generative clothing. In2020 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 6468–6477. Computer Vision Foundation / IEEE, 2020. doi: 10.1109/CVPR4260...
-
[29]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Chaitanya Patel, Zhouyingcheng Liao, and Gerard Pons-Moll. Tailornet: Predict- ing clothing in 3d as a function of human pose, shape and garment style. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 7363–7373. Computer Vi- sion Foundation / IEEE, 2020. doi: 10.1109/CVPR42600.202...
-
[30]
Battaglia
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter W. Battaglia. Learning mesh-based simulation with graph networks. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URLhttps://openreview.net/forum?id=roNqYL0_XP
2021
-
[31]
Cristian Romero, Dan Casas, Jesús Pérez, and Miguel A. Otaduy. Learning contact corrections for handle-based subspace dynamics.ACM Trans. Graph., 40(4):131:1–131:12, 2021. doi: 10.1145/3450626.3459875. URLhttps://doi.org/10.1145/3450626.3459875
-
[32]
Cristian Romero, Dan Casas, Maurizio M. Chiaramonte, and Miguel A. Otaduy. Contact-centric deformation learning.ACM Trans. Graph., 41(4):70:1–70:11, 2022. doi: 10.1145/3528223. 3530182. URLhttps://doi.org/10.1145/3528223.3530182
-
[33]
Battaglia
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter W. Battaglia. Learning to simulate complex physics with graph networks. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, pages 8459–8468. PMLR,
2020
-
[34]
URLhttp://proceedings.mlr.press/v119/sanchez-gonzalez20a.html
-
[35]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Igor Santesteban, Nils Thuerey, Miguel A. Otaduy, and Dan Casas. Self-supervised collision handling via generative 3d garment models for virtual try-on. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 11763– 11773. Computer Vision Foundation / IEEE, 2021. doi: 10.1109/CVPR46437.2021.01159. URL http...
-
[36]
Igor Santesteban, Miguel A. Otaduy, and Dan Casas. SNUG: self-supervised neural dynamic garments. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 8130–8140. IEEE, 2022. doi: 10.1109/ CVPR52688.2022.00797. URLhttps://doi.org/10.1109/CVPR52688.2022.00797
-
[37]
Transformer with implicit edges for particle-based physics simulation
Yidi Shao, Chen Change Loy, and Bo Dai. Transformer with implicit edges for particle-based physics simulation. In Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XIX, volume 13679 ofLecture N...
-
[38]
Yidi Shao, Chen Change Loy, and Bo Dai. Towards multi-layered 3d garments animation. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 14315–14324. IEEE, 2023. doi: 10.1109/ICCV51070.2023.01321. URL https://doi.org/10.1109/ICCV51070.2023.01321. 12
-
[39]
Wang, Duygu Ceylan, Xin Sun, and Dinesh Manocha
Qingyang Tan, Yi Zhou, Tuanfeng Y . Wang, Duygu Ceylan, Xin Sun, and Dinesh Manocha. A repulsive force unit for garment collision handling in neural networks. In Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors, Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022...
2022
-
[40]
doi: 10.1007/978-3-031-20062-5\_26
Springer, 2022. doi: 10.1007/978-3-031-20062-5\_26. URL https://doi.org/10. 1007/978-3-031-20062-5_26
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[42]
Fully convolutional graph neural networks for parametric virtual try-on.Comput
Raquel Vidaurre, Igor Santesteban, Elena Garces, and Dan Casas. Fully convolutional graph neural networks for parametric virtual try-on.Comput. Graph. Forum, 39(8):145–156, 2020. doi: 10.1111/CGF.14109. URLhttps://doi.org/10.1111/cgf.14109
-
[43]
A fast & robust solution for cubic & higher-order polynomials
Cem Yuksel. A fast & robust solution for cubic & higher-order polynomials. InACM SIGGRAPH 2022 Talks, pages 1–2. 2022
2022
-
[44]
Chong Zeng, Yue Dong, Pieter Peers, Hongzhi Wu, and Xin Tong. Renderformer: Transformer- based neural rendering of triangle meshes with global illumination. In Ginger Alford, Hao (Richard) Zhang, and Adriana Schulz, editors,Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference, SIGGRAPH Conference Pa- pers 20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.