Periodic RoPE for Infinite Context LLMs
Pith reviewed 2026-06-29 12:28 UTC · model grok-4.3
The pith
Periodic RoPE combined with sliding window attention and NoPE global layers enables LLMs to handle infinite context without extrapolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
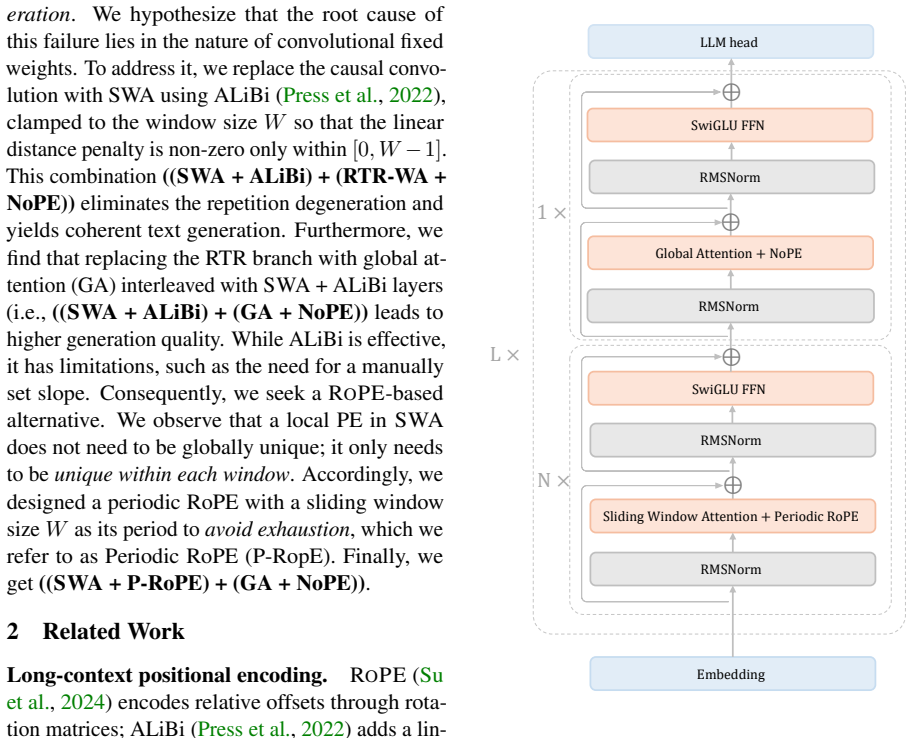
By stacking layers that apply Periodic RoPE inside sliding-window attention for local context together with global attention layers that use No Positional Encoding, the architecture removes the need for positional extrapolation and thereby supports an infinite context window in theory.
What carries the argument
Periodic RoPE (P-RoPE), a positional encoding that works with sliding window attention for local relative positions and is interleaved with NoPE global attention layers to allow unbounded cross-sequence interactions.
If this is right
- Sequence length is no longer bounded by the pre-training range of the positional encoding.
- No separate extrapolation methods are required to extend context.
- Local dependencies remain handled by sliding windows while global interactions stay unconstrained.
- Empirical long-context performance improves in both efficiency and stability compared with unmodified GPT architectures.
Where Pith is reading between the lines
- The same local-global alternation might transfer to other attention variants without requiring new training objectives.
- Real-world long-horizon tasks could benefit if the global layers prove sufficient for dependency tracking without explicit positions.
- Training dynamics may simplify because the model never encounters an explicit length ceiling during pre-training.
Load-bearing premise
Global attention layers without any positional encoding can still capture and maintain the long-range dependencies needed across the full sequence when interleaved with local positional layers.
What would settle it
A controlled test in which the global NoPE layers are replaced by standard positional layers or removed entirely, followed by evaluation on tasks that require precise long-range ordering information at lengths far beyond training, showing clear degradation if the claim holds.
Figures

read the original abstract
The ability to process ultra-long contexts is crucial for large language models (LLMs) to perform long-horizon tasks. While recent efforts have extended context windows to 1M and beyond, model performance degrades when sequence length exceeds the pre-trained range of positional encodings (e.g., RoPE), i.e., position exhaustion. This fundamental limitation must be overcome to achieve a truly infinite context. To address it, we propose Periodic RoPE (P-RoPE), a positional encoding mechanism designed to circumvent this exhaustion. It operates in conjunction with sliding window attention (SWA) to capture local dependencies and relative positions within each window. This local layer is then complemented by a global attention layer with No Positional Encoding (NoPE), enabling unbounded interaction across the entire sequence without positional constraints. By stacking these two types of layers, the model avoids the need for positional extrapolation to generalize longer and theoretically supports an infinite context window. Empirical results show that our model, MiniWin, outperforms MiniMInd with standard GPT architectures in long-context efficiency and stability. Our work provides a possible pathway toward LLMs with genuine infinite-context understanding. The code is available at \href{https://github.com/Cominder/miniwin}{https://github.com/Cominder/miniwin}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Periodic RoPE (P-RoPE) paired with sliding-window attention (SWA) for local layers and No Positional Encoding (NoPE) for global attention layers. Stacking these layer types is claimed to eliminate the need for positional extrapolation, thereby theoretically supporting an infinite context window; the resulting MiniWin model is reported to outperform standard GPT-style architectures (MiniMInd) on long-context efficiency and stability.
Significance. If the construction genuinely preserves relative-position distinguishability across arbitrary distances and the empirical gains are reproducible, the approach would constitute a substantive contribution toward unbounded-context LLMs by sidestepping RoPE exhaustion without requiring extrapolation schemes.
major comments (2)
- [Abstract] Abstract: the assertion that the P-RoPE+SWA / NoPE stacking 'theoretically supports an infinite context window' is unsupported by any derivation. Scaled dot-product attention without positional signals is permutation-invariant; nothing in the described interleaving is shown to transmit or recover relative distances between tokens separated by multiple windows after content-only global mixing.
- [Abstract] Abstract: no equations, proofs, ablation tables, or quantitative metrics (including error bars or baseline comparisons) are supplied to substantiate either the theoretical claim or the reported outperformance of MiniWin over MiniMInd.
minor comments (1)
- The GitHub link is provided, which aids reproducibility; however, the manuscript would benefit from explicit section headings and equation numbering even in a short format.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger theoretical and empirical support. We address each major comment below and will make the indicated revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the P-RoPE+SWA / NoPE stacking 'theoretically supports an infinite context window' is unsupported by any derivation. Scaled dot-product attention without positional signals is permutation-invariant; nothing in the described interleaving is shown to transmit or recover relative distances between tokens separated by multiple windows after content-only global mixing.
Authors: We agree that the current version provides no formal derivation establishing preservation of relative distances across windows. The design intuition is that P-RoPE within SWA layers supplies periodic local relative positions while global NoPE layers perform content-driven mixing without length-dependent positional limits, but this does not yet address how distinguishability is maintained after multiple global mixing steps. In revision we will add a theoretical analysis section containing equations that formalize the effective positional signal flow through the stacked layers and discuss the permutation-invariance concern explicitly. revision: yes
-
Referee: [Abstract] Abstract: no equations, proofs, ablation tables, or quantitative metrics (including error bars or baseline comparisons) are supplied to substantiate either the theoretical claim or the reported outperformance of MiniWin over MiniMInd.
Authors: The manuscript reports outperformance of MiniWin over MiniMInd but indeed supplies neither equations for P-RoPE, proofs, ablation tables, nor quantitative metrics with error bars in the abstract or main text. We will expand the abstract with key performance numbers, add a section presenting the P-RoPE equations, include ablation studies, report results with error bars, and provide explicit baseline comparisons with standard deviations. revision: yes
Circularity Check
No circularity; architectural proposal with empirical support, no self-referential derivations or fitted predictions
full rationale
The paper describes an architectural design (P-RoPE + SWA local layers interleaved with NoPE global layers) and asserts that this construction 'theoretically supports an infinite context window' without providing any equations, derivations, or parameter-fitting steps that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are renamed as new predictions. The central claim is a hypothesis about layer stacking, backed by empirical comparison of MiniWin vs. MiniMind, which remains externally falsifiable and does not loop back on fitted values defined inside the paper. This is the common case of a self-contained design paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CMMLU: Measuring massive multitask language understanding in Chinese
The impact of positional encoding on length generalization in transformers.Advances in Neural Information Processing Systems, 36:24892–24928. Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2023. Cmmlu: Measuring massive mul- titask language understanding in chinese.Preprint, arXiv:2306.09212. Zhenyu L...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
This makes sense as an example of a specific model
**Personalized Queries**: An AI system can be trained on large amounts of data, enabling tasks like recommendation, fraud detection, or text generation. This makes sense as an example of a specific model
-
[3]
This helps researchers extract and understand complex information and insights into new applications
**New Data Experience**: AI algorithms can analyze large amounts of data in multiple datasets, helping identify patterns and trends. This helps researchers extract and understand complex information and insights into new applications
-
[4]
This could help researchers develop new solutions for complex problems
**Automated Larger Costs**: The ability to predict whether to generate more accurate predictions, especially if data has high variability compared to human-based systems. This could help researchers develop new solutions for complex problems
-
[5]
This could potentially improve patient outcomes, including overall well-being and improved overall health outcomes
**Conservation**: A machine learning process can lead to a more accurate statement in healthcare, education, and other fields. This could potentially improve patient outcomes, including overall well-being and improved overall health outcomes
-
[6]
This would likely require more advanced tools such as natural language processing, image recognition, and deep neural networks
**Limitedness and Best Efficiency**: Alternatively, AI models can also be used in areas where decisions were made to prevent losses. This would likely require more advanced tools such as natural language processing, image recognition, and deep neural networks
-
[7]
This could be seen as an exponential or unavoidable technology used in manufacturing, healthcare, education, and social media
**Opportunities in Productivity**: While there may be potential risks, AI models must be considered a technological innovation rather than a personal idea. This could be seen as an exponential or unavoidable technology used in manufacturing, healthcare, education, and social media
-
[8]
— ## Important Factors - Defining and expanding learning patterns, providing relevant resources, and training to perform tasks efficiently
**Global Concerns**: Some AI technologies have proposed significant impacts on global economies and fossilization efforts. — ## Important Factors - Defining and expanding learning patterns, providing relevant resources, and training to perform tasks efficiently. - Implementing decision-making processes based on input data and analysis, making learning dec...
-
[9]
** 光反应**:在光反应过程中,叶绿体中的叶绿素吸收太阳光,将其转化为化学能(如葡萄糖),同时释放出氧 气。这个过程称为 “光反应”。在这个过程中,叶绿素分子激发电子,从而产生 ATP(三磷酸腺苷),这些有机物将 二氧化碳和水转化为糖类和氧气。
-
[10]
**暗反应**:在暗反应阶段,叶绿体中的CO2被释放到大气中,进入紫外线(UV)或X射线辐射中。这有助于调 节地球的气候,维持生命活动。
-
[11]
** 光合作用的分解与生长**:一旦植物获得足够的光能,它们就会通过光合作用从太阳的能量中提取能量,这个 过程称为“光合作用”。在光合作用的过程中,叶绿体中的叶绿素能够吸收太阳光,进行光合作用,从而实现光合作 用的高效行。
-
[12]
** 光合作用的监测与管理**:光合作用的实施需要专业的波及光照条件,以确保光合作用的有效性和安全性。波 及光能也需在环境条件下进行,避免过量的光照干扰,以保证植物生长的健康。
-
[13]
** 营养循环**:光合作用的最终目标是将阳光转化为植物所需的能量,同时维持大气中的氧气含量。光合作用是 地球生命维持生命活动的基础。 光合作用对于地球上的许多生物来说是一个独特的过程,它不仅为植物提供了必要的能量,还促进了生态系统的结 构和功能,包括空气净化、土壤保持、气候调节等关键环节。 6
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.