KVoiceBench, KOpenAudioBench, and KMMAU: Agent-Driven Korean Speech Benchmarks for Evaluating SpeechLMs
Pith reviewed 2026-06-29 13:38 UTC · model grok-4.3
The pith
Two agent-driven frameworks transfer English speech benchmarks to Korean while preserving instructions, constraints, and audio properties, enabling evaluation of eight SpeechLMs that uncovers varying gaps and diverging task rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
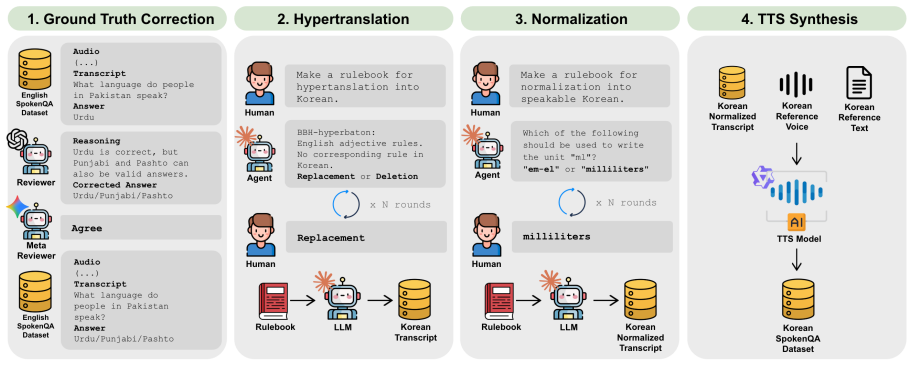
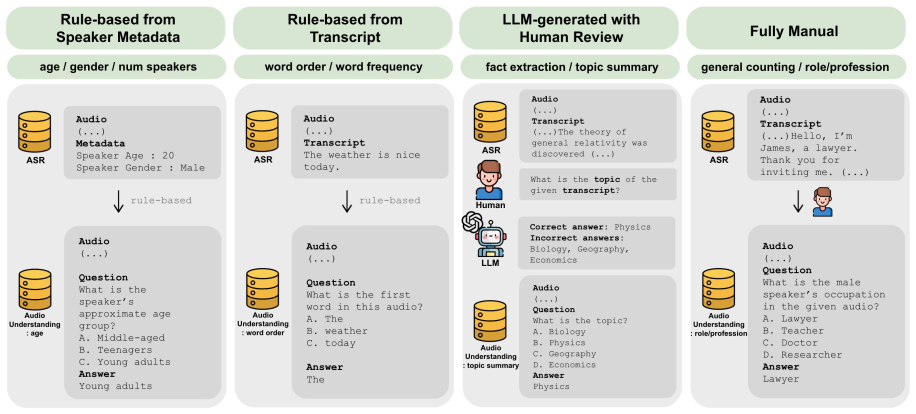
We propose two human-agent benchmark-construction frameworks: one transfers source-language SpokenQA benchmarks into target-language SpokenQA benchmarks, and the other converts target-language ASR corpora into audio understanding benchmarks using transcriptions and speaker metadata. Using these frameworks, we construct and publicly release three Korean speech benchmarks: KVoiceBench and KOpenAudioBench for Korean SpokenQA, and KMMAU for Korean audio understanding, comprising 12,345 samples in total. We evaluate eight recent SpeechLMs and find that English-Korean performance gaps vary substantially across models and task families, and that SpokenQA and audio understanding rankings diverge, re
What carries the argument
Two human-agent benchmark-construction frameworks that transfer SpokenQA benchmarks and convert ASR corpora into audio understanding tasks while aiming to preserve language-specific instructions, answer constraints, spoken forms, speaker attributes, accents, and paralinguistic properties.
If this is right
- English-Korean performance gaps vary substantially across models and task families.
- SpokenQA and audio understanding rankings diverge across the evaluated SpeechLMs.
- The divergence reveals complementary weaknesses that English-only evaluation cannot detect.
- The three released benchmarks provide a total of 12,345 Korean samples for future SpeechLM assessment.
Where Pith is reading between the lines
- The frameworks could be adapted to create benchmarks in additional languages beyond Korean.
- Diverging task rankings suggest SpeechLMs may require separate training objectives for question answering versus audio understanding.
- Public availability of the benchmarks enables direct comparison of new models against the eight evaluated here.
- The approach highlights a general need for language-specific construction methods rather than simple translation pipelines.
Load-bearing premise
The agent-driven frameworks successfully transfer benchmarks while preserving language-specific instructions, answer constraints, spoken forms, speaker attributes, accents, and paralinguistic properties.
What would settle it
A direct comparison where human evaluators rate the transferred Korean benchmarks as having lost original answer constraints or speaker attributes, or where model rankings on the new benchmarks match English rankings exactly with no divergence between SpokenQA and audio understanding.
Figures


read the original abstract
Speech language models (SpeechLMs) have achieved substantial progress by extending large language models (LLMs) to the speech modality. However, SpeechLM evaluation remains heavily centered on English, limiting reliable assessment of multilingual speech capabilities. Straightforward benchmark transfer through ASR, translation, normalization, and TTS can corrupt language-specific instructions, answer constraints, and spoken forms; for audio understanding, transferring source-language audio also fails to preserve target-language speaker attributes, accents, and paralinguistic properties. To address these limitations, we propose two human-agent benchmark-construction frameworks: one transfers source-language SpokenQA benchmarks into target-language SpokenQA benchmarks, and the other converts target-language ASR corpora into audio understanding benchmarks using transcriptions and speaker metadata. Using these frameworks, we construct and publicly release three Korean speech benchmarks: KVoiceBench and KOpenAudioBench for Korean SpokenQA, and KMMAU for Korean audio understanding, comprising 12,345 samples in total. We evaluate eight recent SpeechLMs and find that English-Korean performance gaps vary substantially across models and task families, and that SpokenQA and audio understanding rankings diverge, revealing complementary weaknesses invisible to English-only evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two human-agent benchmark-construction frameworks to transfer English SpokenQA benchmarks and convert target-language ASR corpora into Korean equivalents while aiming to preserve language-specific instructions, answer constraints, spoken forms, speaker attributes, accents, and paralinguistic properties. It constructs and releases three Korean speech benchmarks (KVoiceBench, KOpenAudioBench for SpokenQA; KMMAU for audio understanding) totaling 12,345 samples, then evaluates eight recent SpeechLMs to report varying English-Korean performance gaps across models and task families, plus divergent rankings between SpokenQA and audio understanding that reveal complementary weaknesses not visible in English-only evaluation.
Significance. If the transfer frameworks are shown to preserve the targeted properties, the work supplies publicly released Korean benchmarks that can support more reliable multilingual SpeechLM assessment and highlight model limitations invisible to English-centric testing. The public release of the benchmarks and the empirical evaluation across multiple models and task types are concrete contributions to the field.
major comments (1)
- [Abstract, motivation and construction sections] Abstract and construction sections: the central claim that the agent-driven frameworks successfully transfer benchmarks while preserving language-specific instructions, answer constraints, spoken forms, speaker attributes, accents, and paralinguistic properties lacks supporting quantitative validation such as inter-annotator agreement scores, error rates on transferred constraints, or acoustic fidelity metrics; without this, the superiority over straightforward transfer methods cannot be assessed and the evaluation results rest on an unverified assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point-by-point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract, motivation and construction sections] Abstract and construction sections: the central claim that the agent-driven frameworks successfully transfer benchmarks while preserving language-specific instructions, answer constraints, spoken forms, speaker attributes, accents, and paralinguistic properties lacks supporting quantitative validation such as inter-annotator agreement scores, error rates on transferred constraints, or acoustic fidelity metrics; without this, the superiority over straightforward transfer methods cannot be assessed and the evaluation results rest on an unverified assumption.
Authors: We agree that quantitative validation would strengthen the central claim and allow direct comparison to straightforward transfer. The manuscript describes the human-agent frameworks and states that human verification steps are used to preserve the listed properties, but does not report inter-annotator agreement, sampled error rates, or acoustic metrics. In the revised version we will add a dedicated subsection under 'Benchmark Construction' that reports (1) inter-annotator agreement scores from the human verification stage on a random sample of 500 instances per benchmark, (2) error rates on language-specific instructions and answer constraints for the same sample, and (3) a brief discussion of why objective acoustic fidelity metrics for accents and paralinguistic cues are difficult to obtain without large-scale perceptual listening tests (which we flag as future work). These additions will make the superiority claim empirically testable. revision: yes
Circularity Check
No significant circularity; empirical benchmark construction
full rationale
The paper proposes human-agent frameworks for transferring/constructing Korean speech benchmarks from existing sources, releases three new datasets (KVoiceBench, KOpenAudioBench, KMMAU), and reports evaluation results on eight SpeechLMs. No equations, parameter fitting, predictions derived from inputs, or self-citations appear in the provided text. The central claims concern the construction process and observed performance gaps; these rest on the described methodology and external model evaluations rather than reducing to self-definitional steps or fitted inputs. This is standard empirical work with no load-bearing circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Straightforward benchmark transfer through ASR, translation, normalization, and TTS corrupts language-specific instructions, answer constraints, and spoken forms; transferring source-language audio fails to preserve target-language speaker attributes, accents, and paralinguistic properties.
Reference graph
Works this paper leans on
-
[1]
A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594. Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. 2026. Qwen3-TTS technical report.Preprint, arXiv:2601.15621. Ailin Huang and 1 others. 2025. Step-audio:...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Association for Computational Linguistics. Chia-Hsuan Li, Szu-Lin Wu, Chi-Liang Liu, and Hung yi Lee. 2018. Spoken SQuAD: A study of mitigating the impact of speech recognition errors on listening comprehension.Preprint, arXiv:1804.00320. Tianpeng Li, Jun Liu, Tao Zhang, Yuanbo Fang, Da Pan, Mingrui Wang, Zheng Liang, Zehuan Li, Mingan Lin, Guosheng Dong,...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
MMAU: A massive multi-task audio un- derstanding and reasoning benchmark.Preprint, arXiv:2410.19168. Richard Sproat, Alan W. Black, Stanley Chen, Shankar Kumar, Mari Ostendorf, and Christopher Richards
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
RNN Approaches to Text Normalization: A Challenge
Normalization of non-standard words.Com- puter Speech & Language, 15(3):287–333. Richard Sproat and Navdeep Jaitly. 2017. RNN approaches to text normalization: A challenge. Preprint, arXiv:1611.00068. Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2024. SALMONN: Towards generic hear- ing abilities f...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.