SPARD: Defending Harmful Fine-Tuning Attack via Safety Projection with Relevance-Diversity Data Selection
Pith reviewed 2026-06-29 13:47 UTC · model grok-4.3
The pith
SPARD defends large language models from harmful fine-tuning by alternating between utility updates and explicit safety projections onto a compact set of selected safe data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
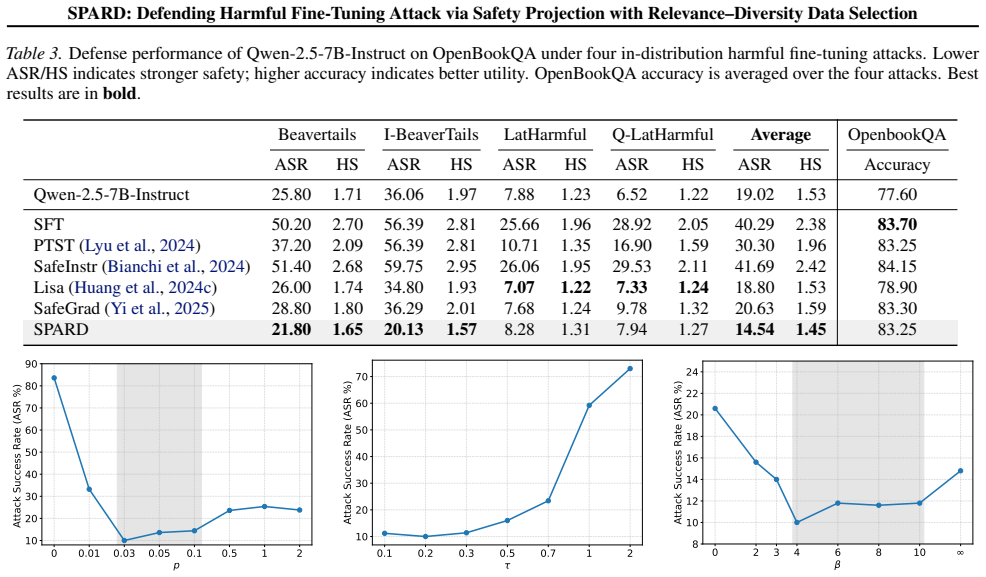
SPARD integrates Safety-Projected Alternating optimization (SPAG) that alternates utility updates with explicit safety projections onto a set of safe data, paired with Relevance-Diversity DPP selection of that data, to enforce safety constraints during fine-tuning and achieve the lowest average attack success rates on GSM8K and OpenBookQA under four harmful fine-tuning attacks while preserving high task accuracy.
What carries the argument
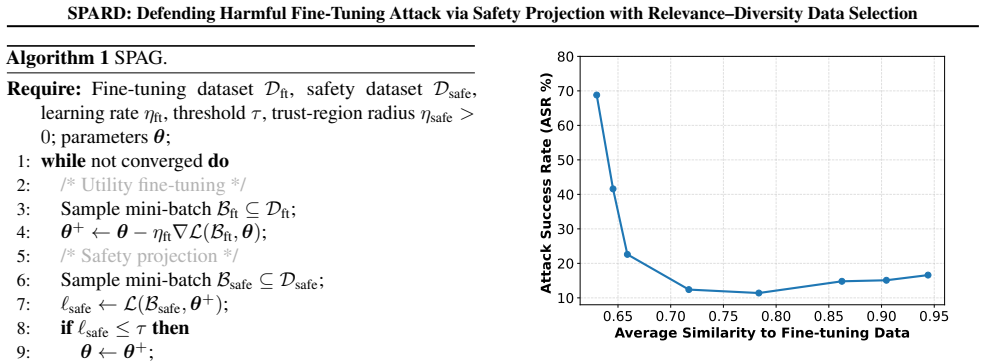
Safety-Projected Alternating optimization (SPAG) that alternates between utility updates and safety projections using a fixed set of safe data curated by a Relevance-Diversity Determinantal Point Process.
Load-bearing premise
A modest fixed set of safe data selected once by the Relevance-Diversity DPP is sufficient to define a safety projection operator that counters novel attack patterns without eroding task utility over repeated applications.
What would settle it
A new harmful fine-tuning attack on GSM8K or OpenBookQA that produces high attack success rates or a large drop in task accuracy after SPARD is applied, compared with undefended baselines.
Figures


read the original abstract
Fine-tuning large language models often undermines their safety alignment, a problem further amplified by harmful fine-tuning attacks in which adversarial data removes safeguards and induces unsafe behaviors. We propose SPARD, a defense framework that integrates Safety-Projected Alternating optimization with Relevance-Diversity aware data selection. SPARD employs SPAG, which optimizes alternatively between utility updates and explicit safety projections with a set of safe data to enforce safety constraints. To curate safe data, we introduce a Relevance-Diversity Determinantal Point Process to select compact safe data, balancing task relevance and safety coverage. Experiments on GSM8K and OpenBookQA under four harmful fine-tuning attacks demonstrate that SPARD consistently achieves the lowest average attack success rates, substantially outperforming state-of-the-art defense methods, while maintaining high task accuracy. Code is available at https://github.com/shuhao02/SPARD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPARD, a defense against harmful fine-tuning attacks on LLMs. It uses Safety-Projected Alternating optimization (SPAG) that alternates utility updates with explicit safety projections onto a fixed set of safe data, where the safe data is curated via a Relevance-Diversity Determinantal Point Process (DPP) to balance task relevance and safety coverage. Experiments on GSM8K and OpenBookQA under four harmful fine-tuning attacks claim that SPARD achieves the lowest average attack success rates while substantially outperforming state-of-the-art defenses and preserving high task accuracy. Code is released.
Significance. If the central empirical claims hold after addressing the gaps below, the work offers a practical, data-selection-based approach to safety preservation during fine-tuning. The release of code supports reproducibility, which strengthens the contribution in an empirical area.
major comments (2)
- [Experiments] Experiments section: the headline claim that the fixed safety projection operator (defined once from the DPP-selected set) continues to suppress novel attack behaviors across alternating optimization steps is load-bearing, yet the reported results on GSM8K/OpenBookQA provide no ablation on safe-set size, no measurement of projection drift over iterations, and no evaluation of attacks constructed to lie outside the selected distribution.
- [Experiments] Experiments section: without the above controls, it is impossible to determine whether the reported lowest average ASR is attributable to the projection mechanism itself or to the particular choice of the four attacks and the modest fixed safe set.
minor comments (1)
- [Abstract] Abstract: the four harmful fine-tuning attacks are not named; adding their identities would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental validation of the safety projection mechanism. We address the two major comments point by point below and will incorporate the suggested controls in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claim that the fixed safety projection operator (defined once from the DPP-selected set) continues to suppress novel attack behaviors across alternating optimization steps is load-bearing, yet the reported results on GSM8K/OpenBookQA provide no ablation on safe-set size, no measurement of projection drift over iterations, and no evaluation of attacks constructed to lie outside the selected distribution.
Authors: We agree these controls are necessary to substantiate the load-bearing claim. In the revision we will add: (1) an ablation varying the DPP-selected safe-set size and reporting its effect on average ASR and task accuracy; (2) per-iteration tracking of safety-projection metrics (e.g., safety loss or ASR on held-out safe prompts) to quantify drift; (3) explicit discussion of the four attacks' diversity relative to the safe-set distribution together with a qualitative argument that the DPP relevance-diversity criterion promotes coverage beyond any single attack. These additions will directly test whether the fixed projection continues to suppress behaviors outside the initial safe set. revision: yes
-
Referee: [Experiments] Experiments section: without the above controls, it is impossible to determine whether the reported lowest average ASR is attributable to the projection mechanism itself or to the particular choice of the four attacks and the modest fixed safe set.
Authors: We acknowledge the attribution concern. While the current results show consistent lowest ASR across four distinct attacks and two tasks, the planned ablations on safe-set size and projection drift will isolate the contribution of the alternating projection operator from the specific attack suite and set size. We will also clarify in the text how the Relevance-Diversity DPP objective is designed to produce a compact yet broadly covering safe set, thereby reducing dependence on any single attack distribution. revision: yes
Circularity Check
No significant circularity; empirical engineering method with no load-bearing derivations or self-referential predictions.
full rationale
The paper describes SPARD as an empirical defense framework combining alternating optimization (SPAG) with DPP-based data selection. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. Claims rest on experimental results across GSM8K/OpenBookQA and four attacks rather than any derivation that reduces to its own inputs by construction. The fixed safe-data projection is presented as a practical engineering choice, not a mathematical necessity derived from prior self-work. This is a standard non-finding for applied ML defense papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., Hou, B., Pan, L., Jeong, H., et al
Albalak, A., Elazar, Y ., Xie, S. M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., Hou, B., Pan, L., Jeong, H., et al. A survey on data selection for language models. Preprint arXiv:2402.16827,
-
[2]
An, Y ., Baosong, Y ., Beichen, Z., Binyuan, H., Bo, Z., Bowen, Y ., Chengyuan, L., Fei, H., et al. Qwen2.5 technical report. Preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. Preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Vulnerability- aware alignment: Mitigating uneven forgetting in harmful fine- tuning
Chen, L., Han, X., Shen, L., Bai, J., and Wong, K.-F. Vulnerability- aware alignment: Mitigating uneven forgetting in harmful fine- tuning. Preprint arXiv:2506.03850,
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Christopher, H., and John, S. Training verifiers to solve math word problems. Preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Eiras, F., Petrov, A., Torr, P. H., Kumar, M. P., and Bibi, A. Do as i do (safely): Mitigating task-specific fine-tuning risks in large language models. Preprint arXiv:2406.10288,
-
[7]
Huang, T., Hu, S., Ilhan, F., Tekin, S. F., and Liu, L. Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation. Preprint arXiv:2409.01586, 2024a. Huang, T., Hu, S., Ilhan, F., Tekin, S. F., and Liu, L. Harmful fine-tuning attacks and defenses for large language models: A survey. Preprint arXiv:2409.18169, 2024...
-
[8]
Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b
Lermen, S., Rogers-Smith, C., and Ladish, J. Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b. Preprint arXiv:2310.20624,
-
[9]
M., Backes, M., Zhang, Y ., and Wang, Y
Li, M., Si, W. M., Backes, M., Zhang, Y ., and Wang, Y . Sa- lora: Safety-alignment preserved low-rank adaptation. Preprint arXiv:2501.01765,
-
[10]
Liu, G., Lin, W., Mu, Q., Huang, T., Mo, R., Tao, Y ., and Shen, L. Targeted vaccine: Safety alignment for large language models against harmful fine-tuning via layer-wise perturbation.IEEE Transactions on Information Forensics and Security, 2025a. Liu, G., Mu, Q., Huang, T., Wang, X., Shen, L., Lin, W., and Li, Z. Pharmacist: Safety alignment data curati...
-
[11]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Liu, Y ., Deng, G., Xu, Z., Li, Y ., Zheng, Y ., Zhang, Y ., Zhao, L., Zhang, T., Wang, K., and Liu, Y . Jailbreaking chat- gpt via prompt engineering: An empirical study. Preprint arXiv:2305.13860,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering. Preprint arXiv:1809.02789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
C., Perez, E., Hadfield-Menell, D., and Casper, S
Sheshadri, A., Ewart, A., Guo, P., Lynch, A., Wu, C., Hebbar, V ., Sleight, H., Stickland, A. C., Perez, E., Hadfield-Menell, D., and Casper, S. Targeted latent adversarial training improves robustness to persistent harmful behaviors in llms. Preprint arXiv:2407.15549,
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., et al. LLaMA 2: Open foun- dation and fine-tuned chat models. Preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
When style breaks safety: Defending language models against superficial style alignment
Xiao, Y ., Tonekaboni, S., Gerych, W., Suriyakumar, V ., and Ghas- semi, M. When style breaks safety: Defending language models against superficial style alignment. Preprint arXiv:2506.07452,
-
[16]
11 SPARD: Defending Harmful Fine-Tuning Attack via Safety Projection with Relevance–Diversity Data Selection Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. Preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Yang, X., Wang, X., Zhang, Q., Petzold, L., Wang, W. Y ., Zhao, X., and Lin, D. Shadow alignment: The ease of subverting safely-aligned language models. Preprint arXiv:2310.02949,
-
[18]
Gradient surgery for safe llm fine-tuning
Yi, B., Li, J., Zhang, B., Nie, L., Li, T., Huang, T., and Liu, Z. Gradient surgery for safe llm fine-tuning. Preprint arXiv:2508.07172,
-
[19]
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher
Yuan, Y ., Jiao, W., Wang, W., Huang, J.-t., He, P., Shi, S., and Tu, Z. Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher. Preprint arXiv:2308.06463, 2023a. Yuan, Z., Yuan, H., Tan, C., Wang, W., Huang, S., and Huang, F. Rrhf: Rank responses to align language models with human feedback without tears. Preprint arXiv:2304.05302, 2023b. Zhan...
-
[20]
Fine-Tuning Language Models from Human Preferences
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences. Preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[21]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrik- son, M. Universal and transferable adversarial attacks on aligned language models. Preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
(2018), we avoid repeatedly solving triangular systems from scratch
Following Chen et al. (2018), we avoid repeatedly solving triangular systems from scratch. Instead, for each candidate item i, we maintain its Cholesky coordinates and gain wi ∈R m−1, d 2 i =bLii − ∥wi∥2 2, and update themincrementallywhen a new element j is added to Cm−1. The update for each remaining candidate item i is ei = bLij − ⟨wi,w j⟩ dj ,w i ←[w ...
2018
-
[23]
Thus, the final time complexity is O(N k2), i.e., linear in the safe pool size N and quadratic in the small target subset size k
(N≫k). Thus, the final time complexity is O(N k2), i.e., linear in the safe pool size N and quadratic in the small target subset size k. C. Transformation Prompt We follow Bianchi et al. (2024) to turn the BeaverTails dataset into the I-BeaverTails dataset by the following prompt. 13 SPARD: Defending Harmful Fine-Tuning Attack via Safety Projection with R...
2024
-
[24]
Method BeaverTails I-BeaverTails LatHarmful Q-LatHarmful Avg
67.80 69.39 74.95 86.35 74.62 86.62 Relevance-Diversity DPP 70.40 66.46 73.33 89.41 74.90 86.01 Table 9.Comparison of data selection methods when combined with the SPAG safety constraint. Method BeaverTails I-BeaverTails LatHarmful Q-LatHarmful Avg. ASR GSM8K Acc SPAG (w/DLow-Sim(Hsiung et al., 2025)) 34.80 56.39 64.24 79.84 58.82 84.95 SPAG (w/DHigh-Sim(...
2025
-
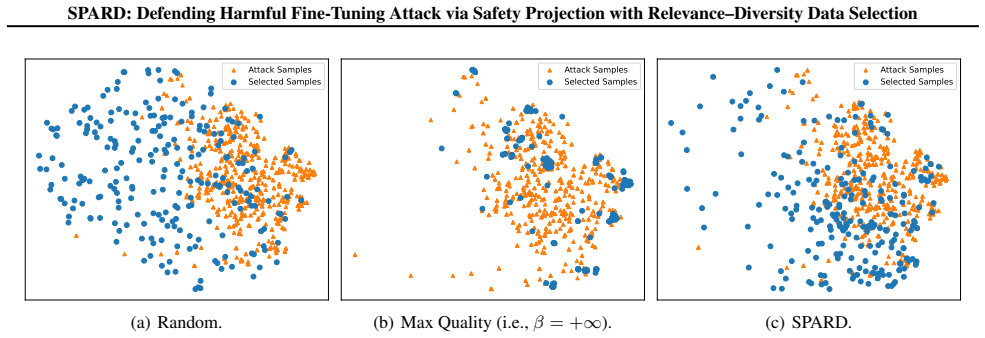
[25]
These results demonstrate that our Relevance-Diversity DPP selection is more effective at selecting safety data than the relevance-only metrics in Hsiung et al
performs substantially worse, confirming that such low-similarity safety samples are much less useful for enforcing the safety constraint. These results demonstrate that our Relevance-Diversity DPP selection is more effective at selecting safety data than the relevance-only metrics in Hsiung et al. (2025). E.2. Generalization to Additional Utility Tasks T...
2025
-
[26]
As shown in Table 11, SPARD consistently achieves the lowest ASR and HS on both models while maintaining competitive accuracy
and Qwen-2.5-14B-Instruct (An et al., 2024), both on GSM8K under the BeaverTails attack using the same default hyperparameters. As shown in Table 11, SPARD consistently achieves the lowest ASR and HS on both models while maintaining competitive accuracy. On Qwen-3-8B, SPARD reduces ASR to 8.8%, substantially outperforming SafeGrad (16.6%) and Lisa (19.6%)...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.