MemCog: From Memory-as-Tool to Memory-as-Cognition in Conversational Agents
Pith reviewed 2026-06-29 12:48 UTC · model grok-4.3
The pith
MemCog makes memory access an active part of an agent's reasoning instead of a one-shot tool call.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
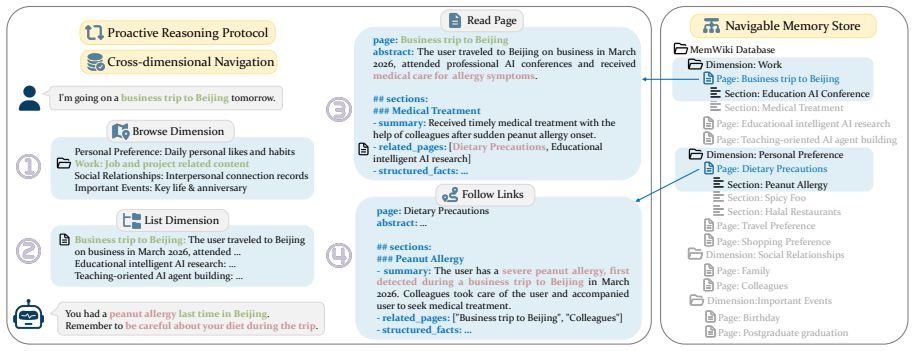
MemCog organizes user knowledge as a Navigable Memory Store with associative link graphs, exposes a Cross-Dimensional Navigation Interface for multi-step reasoning-driven traversal, and employs a Proactive Reasoning Protocol that drives agents to spontaneously initiate memory exploration from conversational context.
What carries the argument
The Navigable Memory Store with associative link graphs, together with the Cross-Dimensional Navigation Interface and Proactive Reasoning Protocol, which embed memory traversal directly into the agent's reasoning loop.
If this is right
- Agents perform multi-step memory navigation as part of ongoing reasoning rather than isolated retrieval.
- Spontaneous memory access from context improves handling of long, open-ended conversations.
- Performance gains appear on both passive QA tasks and new proactive memory tests.
- The same memory organization supports both existing benchmark formats and the new proactive evaluation.
Where Pith is reading between the lines
- The same navigation mechanism could be tested in multi-turn planning agents that must recall constraints across sessions.
- Real-world deployment logs could measure whether users notice more natural recall compared with tool-based baselines.
- The link-graph structure might be adapted to other knowledge sources such as tool-use histories or code repositories.
Load-bearing premise
The specific components of the navigable store, navigation interface, and proactive protocol actually resolve the problems of passive invocation, reasoning-retrieval decoupling, and structural mismatch.
What would settle it
A controlled comparison in which MemCog shows no gain or a loss on ProactiveMemBench relative to standard retrieval baselines would falsify the claimed advantage.
Figures

read the original abstract
Existing agent memory systems universally follow what we term a Memory-as-Tool paradigm where a single query triggers one-shot retrieval of flat passage lists, suffering from passive invocation, reasoning-retrieval decoupling, and structural mismatch between retrieved fragments and the agent's navigational needs. We propose MemCog, a Memory-as-Cognition system that makes memory access an integral part of the reasoning process. MemCog organizes user knowledge as Navigable Memory Store with associative link graphs, exposes Cross-Dimensional Navigation Interface for multi-step reasoning-driven traversal, and employs Proactive Reasoning Protocol that drives agents to spontaneously initiate memory exploration from conversational context. We additionally construct ProactiveMemBench, the first benchmark for evaluating proactive memory triggering. Experiments show that MemCog achieves state-of-the-art on passive QA benchmarks (92.98 on LoCoMo, 95.8 on LongMemEval) while substantially outperforming baselines on ProactiveMemBench, demonstrating the advantage of Memory-as-Cognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that existing conversational agent memory systems follow a Memory-as-Tool paradigm limited by passive invocation, reasoning-retrieval decoupling, and structural mismatch. It proposes MemCog as a Memory-as-Cognition alternative that integrates memory access into reasoning via a Navigable Memory Store with associative link graphs, a Cross-Dimensional Navigation Interface for multi-step traversal, and a Proactive Reasoning Protocol for spontaneous exploration from context. The authors introduce ProactiveMemBench as the first benchmark for proactive memory triggering and report SOTA results on passive QA benchmarks (92.98 on LoCoMo, 95.8 on LongMemEval) plus outperformance on the new benchmark.
Significance. If the performance gains can be isolated to the proposed components through ablations, this could meaningfully advance agent memory research by shifting from passive retrieval tools to integrated cognitive processes, with the new ProactiveMemBench filling an evaluation gap for proactive behaviors in long-context conversations.
major comments (2)
- [Abstract] Abstract: The SOTA claims on passive benchmarks (LoCoMo 92.98, LongMemEval 95.8) are presented without ablation experiments that isolate the Navigable Memory Store, Cross-Dimensional Navigation Interface, or Proactive Reasoning Protocol (e.g., by replacing the navigation interface with standard one-shot retrieval while holding the base LLM and memory store fixed). Without such isolation, the results cannot be attributed to the claimed paradigm shift.
- [Experiments] Experiments section: No details are supplied on baselines, error bars, statistical tests, dataset splits, or implementation choices for the reported numeric results, preventing assessment of whether the passive-benchmark wins support the central claim.
minor comments (1)
- [Abstract] Abstract: The three stated problems (passive invocation, reasoning-retrieval decoupling, structural mismatch) are listed but not explicitly mapped to the three proposed components with even a brief illustrative example.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects for strengthening the manuscript. We will revise the paper to include the requested ablations and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA claims on passive benchmarks (LoCoMo 92.98, LongMemEval 95.8) are presented without ablation experiments that isolate the Navigable Memory Store, Cross-Dimensional Navigation Interface, or Proactive Reasoning Protocol (e.g., by replacing the navigation interface with standard one-shot retrieval while holding the base LLM and memory store fixed). Without such isolation, the results cannot be attributed to the claimed paradigm shift.
Authors: We agree that ablation studies are essential to isolate the effects of the proposed components and attribute performance improvements to the Memory-as-Cognition paradigm. In the revised manuscript, we will add comprehensive ablation experiments. These will include variants where the Cross-Dimensional Navigation Interface is replaced with standard one-shot retrieval, while fixing the base LLM and memory store, as suggested. Similar ablations will be performed for the other components. revision: yes
-
Referee: [Experiments] Experiments section: No details are supplied on baselines, error bars, statistical tests, dataset splits, or implementation choices for the reported numeric results, preventing assessment of whether the passive-benchmark wins support the central claim.
Authors: We acknowledge the lack of sufficient experimental details in the current version. The revised manuscript will include an expanded Experiments section providing full information on the baselines used, error bars computed from multiple independent runs, results of statistical tests, details on dataset splits, and implementation choices including model versions, hyperparameters, and prompting strategies. revision: yes
Circularity Check
No circularity: results on external benchmarks with no definitional or fitted reductions
full rationale
The paper reports SOTA numbers on established external benchmarks (LoCoMo at 92.98, LongMemEval at 95.8) and introduces ProactiveMemBench as an additional evaluation. No equations, parameter-fitting steps, self-citations, or ansatzes appear in the abstract that reduce any claimed prediction or result to the inputs by construction. The derivation chain relies on empirical comparisons against prior benchmarks rather than self-referential definitions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Navigable Memory Store
no independent evidence
-
Cross-Dimensional Navigation Interface
no independent evidence
-
Proactive Reasoning Protocol
no independent evidence
-
ProactiveMemBench
no independent evidence
Forward citations
Cited by 1 Pith paper
-
PROJECTMEM: A Local-First, Event-Sourced Memory and Judgment Layer for AI Coding Agents
ProjectMem implements a local event-sourced memory and judgment layer for AI coding agents that logs typed events, projects them to MCP summaries, and applies deterministic pre-action gates to avoid known failures.
Reference graph
Works this paper leans on
-
[1]
Technical report, Supermemory Inc
Supermemory: State-of-the-art agent memory. Technical report, Supermemory Inc. Accessed: 2026- 05-21. Yang Deng, Wenqiang Lei, Wai Lam, and Tat-Seng Chua. 2023. A survey on proactive dialogue sys- tems: Problems, methods, and prospects.Preprint, arXiv:2305.02750. Xingbo Du, Loka Li, Duzhen Zhang, and Le Song. 2025. Memr3: Memory retrieval via reflective r...
-
[2]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand. Association for Compu- tational Linguistics. Sena Makel and tinyhumansai. 2026. Openhuman: Your personal AI super intelligence. https:// git...
2026
-
[3]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interac- tive simulacra of human behavior.Preprint, arXiv:2304.03442. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Cha...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
Raptor: Recursive abstractive processing for tree-organized retrieval.Preprint, arXiv:2401.18059. Sahil Sen, Elias Lumer, Anmol Gulati, and Vamse Ku- mar Subbiah. 2026. Chronos: Temporal-aware con- versational agents with structured event retrieval for long-term memory.Preprint, arXiv:2603.16862. 9 Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Corrective Retrieval Augmented Generation
Corrective retrieval augmented generation. Preprint, arXiv:2401.15884. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations. Juwei Yue, Chuanrui Hu, Jiawei Sheng, Zuyi Zhou, Wenyuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
It’s almost New Year, anything I should do?
Temporal Association User message: “It’s almost New Year, anything I should do?” Triggered memories: [ {“memory_unit”: “Promised kid a year-end trip”, “reason”: “Association path: user says it’s almost New Year→find promise of year-end trip with kid”} ]
-
[7]
How is Tim doing lately?
Entity Association User message: “How is Tim doing lately?” Triggered memories: [ {“memory_unit”: “AI startup project progress”, “reason”: “Association path: user mentions Tim→find co-founded startup in Hangzhou→ find AI startup project progress”} ]
-
[8]
Feeling terrible, don’t want to do anything
Emotional Association User message: “Feeling terrible, don’t want to do anything.” Triggered memories: [ {“memory_unit”: “User likes running to relieve stress”, “reason”: “Association path: user expresses negative emotion→scan relaxation/hobby pages→find user likes running to relieve stress”} ]
-
[9]
Just improvised on the piano and recorded it
Behavioral Pattern Association User message: “Just improvised on the piano and recorded it.” Triggered memories: [ {“memory_unit”: “Architecture proposal ambient music material”, “reason”: “Association path: user mentions improvising piano and recording→find user previously used recordings as ambient music material for architecture proposals→ suggest addi...
-
[10]
Where is Joe’s hometown?
Multi-hop Association User message: “Where is Joe’s hometown?” Triggered memories: [ {“memory_unit”: “Yantai”, 15 “reason”: “Association path: user asks about Joe’s hometown→find Joe once gifted hometown specialty Yantai apples→answer is Yantai”} ] B.4 Evaluation Metrics: Recall@k The Recall@k metric evaluates whether the model’s retrieved memory units se...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.