From paper to benchmark: agentic, framework-based reproduction of under-specified methods in machine health intelligence
Pith reviewed 2026-06-29 12:11 UTC · model grok-4.3
The pith
Coupling an agent with a shared PHM benchmark framework turns under-specified paper methods into executable, assumption-aware, and cross-comparable implementations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An agent translates each paper into a shared PHM benchmark framework by mapping equations and protocol descriptions into structured components (task definitions, dataset adapters, windowing, targets, models, evaluators) via a slot-binding interface that explicitly records unresolved assumptions; the resulting implementations are validated against standardized task contracts, turning isolated code synthesis into assumption-aware and systematically comparable benchmark code.
What carries the argument
The slot-binding interface, which maps paper elements (equations, preprocessing steps, evaluation protocols) into shared framework components while logging open assumptions.
If this is right
- Reproductions become directly executable inside the same benchmark harness and can be validated against fixed task contracts.
- Assumptions about windowing, targets, and splits are recorded explicitly, so later users know exactly what was chosen.
- Cross-paper comparisons become possible under one set of standardized evaluation hooks instead of each paper's private protocol.
- The same agent-plus-framework pattern can be applied to any domain where papers leave critical design choices under-specified.
Where Pith is reading between the lines
- If the binding step proves reliable, the method could reduce the need for manual re-implementation when new papers appear in the same field.
- Domains outside PHM that also suffer from restricted data access and incomplete reporting might adopt the slot-binding pattern to create their own shared benchmarks.
- The recorded assumptions could themselves become a research output, showing which paper elements most often require human judgment.
Load-bearing premise
The slot-binding interface can translate incomplete paper descriptions into framework components without adding new inconsistencies or biases that would undermine fair comparison across papers.
What would settle it
Run the same 16 papers through the agent once with the shared framework and once without it, then measure whether performance rankings or absolute scores change when the only difference is the binding step rather than the original method.
Figures

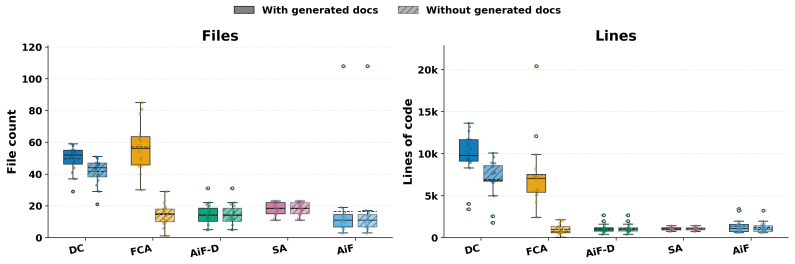

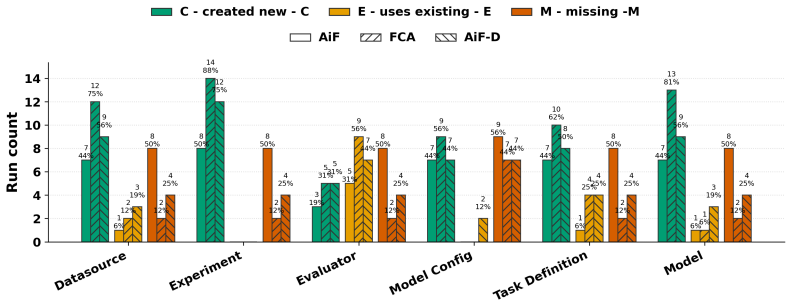


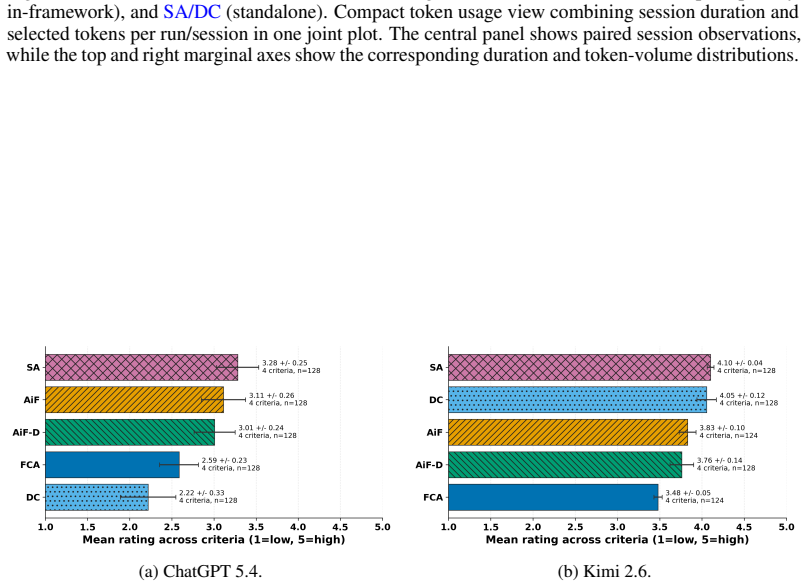












read the original abstract
Industrial Prognostics and Health Management (PHM) provides a representative case study for a broader challenge in applied machine learning: translating published papers into executable, benchmark-ready implementations. Reproducing under-specified methods in PHM is particularly difficult due to restricted access to industrial datasets, incomplete reporting of preprocessing and evaluation protocols, and implicit design choices (e.g., windowing, target construction, data splits) that critically affect performance. Existing paper-to-code systems generate implementations for individual papers, but these artifacts are often not directly comparable due to inconsistencies in assumptions and evaluation settings. We introduce \emph{agentic, framework-based PHM paper reproduction}, where an agent translates a paper into a shared PHM benchmark framework via a \emph{slot-binding interface}. This interface maps equations and protocol descriptions into structured components (task definitions, dataset adapters, windowing, targets, models, and evaluators), while explicitly recording unresolved assumptions. The resulting implementations are validated against standardized task contracts and evaluation hooks, enabling consistent and comparable benchmarking. We evaluate this approach on 16 PHM papers, comparing framework-enhanced, skill-based and prompt-based agentic reproduction against a recent framework-free paper-reproduction agent. We assess reproduction success, model-based code evaluation, framework binding of paper assumptions, and cross-paper benchmark comparability under standardized protocols. Our results show that coupling agentic generation with a shared framework transforms paper reproduction from isolated code synthesis into executable, assumption-aware, and systematically comparable benchmark implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic, framework-based approach to reproducing under-specified methods from PHM papers. An agent uses a slot-binding interface to map paper elements (equations, protocols, implicit choices like windowing/targets/splits) into components of a shared PHM benchmark framework while recording unresolved assumptions. The resulting implementations are validated against task contracts, and the work claims this transforms isolated code synthesis into executable, assumption-aware, and systematically comparable benchmarks. Evaluation is described on 16 PHM papers, comparing framework-enhanced agents against framework-free baselines on reproduction success, code evaluation, binding fidelity, and cross-paper comparability.
Significance. If the empirical claims hold, the work would offer a practical advance in reproducibility for applied ML domains with restricted data and under-specified protocols. The shared-framework strategy directly targets the comparability problem that isolated paper-to-code systems leave unsolved, and the explicit recording of assumptions is a constructive step toward falsifiable benchmarks.
major comments (2)
- [Abstract] Abstract: the claim that results on 16 papers show improvement in reproduction success and comparability is unsupported by any quantitative metrics, baselines, or error analysis. Without these data the central empirical assertion cannot be evaluated.
- [Abstract / method description] Slot-binding interface description: the interface is asserted to map under-specified elements (windowing, targets, splits) into framework components while preserving intent and avoiding new biases. No mechanism, example, or validation is supplied to show that binding decisions remain consistent across papers or do not introduce systematic shifts that would invalidate the 'systematically comparable' conclusion.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence reporting the key quantitative outcomes (e.g., success rates or comparability scores) rather than a qualitative summary.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the major comments point-by-point below and will revise the manuscript to strengthen the abstract and method sections with additional details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that results on 16 papers show improvement in reproduction success and comparability is unsupported by any quantitative metrics, baselines, or error analysis. Without these data the central empirical assertion cannot be evaluated.
Authors: The full evaluation section reports quantitative metrics on the 16 papers, including reproduction success rates with framework-enhanced agents versus the framework-free baseline, model-based code evaluation scores, binding fidelity measures, and cross-paper comparability statistics under standardized protocols, along with baseline comparisons and error analysis. We will revise the abstract to include specific quantitative results and references to these analyses. revision: yes
-
Referee: [Abstract / method description] Slot-binding interface description: the interface is asserted to map under-specified elements (windowing, targets, splits) into framework components while preserving intent and avoiding new biases. No mechanism, example, or validation is supplied to show that binding decisions remain consistent across papers or do not introduce systematic shifts that would invalidate the 'systematically comparable' conclusion.
Authors: We agree that the current description is high-level. We will expand the method section to include the explicit slot-binding mechanism and rules, a worked example from a PHM paper showing binding of windowing/targets/splits, and validation results demonstrating cross-paper consistency (e.g., agreement metrics) and lack of systematic bias (e.g., performance sensitivity analysis). revision: yes
Circularity Check
No circularity; empirical proposal evaluated against external baseline
full rationale
The paper introduces an agentic framework-based reproduction method for PHM papers and reports an empirical evaluation on 16 papers, comparing framework-enhanced agents against a framework-free baseline. No equations, fitted parameters, or derivations are present. The central claim rests on described experimental outcomes rather than any self-referential reduction or self-citation chain. The slot-binding interface is presented as a design choice whose effects are assessed via the reported experiments, not assumed by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Under-specified methods in PHM papers can be mapped to structured components (task definitions, dataset adapters, windowing, targets, models, evaluators) via slot-binding while recording unresolved assumptions.
invented entities (1)
-
slot-binding interface
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Towards Unified and Data-Efficient Prognostics and Health Management with Tabular Foundation Models
Tabular foundation models applied to PHM via signal-to-table conversion achieve the best average ranks across prognostic and diagnostic tasks and remain competitive in low-data regimes.
Reference graph
Works this paper leans on
-
[1]
Picid: A modular evaluation infrastructure for reproducible phm across tasks and domains,
Anonymous. Picid: A modular evaluation infrastructure for reproducible phm across tasks and domains,
-
[2]
Under anonymous review; citation details blinded for double-blind compliance
-
[3]
Michael Bosello, Carlo Falcomer, Claudio Rossi, and Giovanni Pau. To charge or to sell? EV pack useful life estimation via LSTMs, CNNs, and autoencoders.Energies, 16(6):2837, 2023. doi: 10.3390/ en16062837. URLhttps://doi.org/10.3390/en16062837
-
[4]
Joseph Cohen, Xun Huan, and Jun Ni. Fault prognosis of turbofan engines: Eventual failure prediction and remaining useful life estimation.International Journal of Prognostics and Health Management, 14(2), 2023. doi: 10.36001/ijphm.2023.v14i2.3486. URL https://doi.org/10.36001/ijphm.2023.v14i2.3486
-
[5]
Marker: Convert documents to markdown, JSON, chunks, and HTML
Datalab. Marker: Convert documents to markdown, JSON, chunks, and HTML. https://github.com/ datalab-to/marker, 2026. URL https://github.com/datalab-to/marker. Software repository; accessed 2026-05-27
2026
-
[6]
Ingeborg de Pater and Mihaela Mitici. Developing health indicators and RUL prognostics for systems with few failure instances and varying operating conditions using a LSTM autoencoder.Engineering Applications of Artificial Intelligence, 117:105582, 2023. doi: 10.1016/j.engappai.2022.105582. URL https://doi.org/10.1016/j.engappai.2022.105582
-
[7]
Causal inference-based fault diagnosis and abnormal degradation detection for aero-engine
Kunyu Dong, Dan Xu, Zhaoyang Zeng, and Qingyu Zhu. Causal inference-based fault diagnosis and abnormal degradation detection for aero-engine. InProceedings of the 2025 International Conference on Equipment Intelligent Operation and Maintenance, pages 1422–1428, 2025. doi: 10.1109/ICEIOM65271. 2025.11239779. URLhttps://doi.org/10.1109/ICEIOM65271.2025.11239779
-
[8]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Kuruvilla, Rachel Johnson, and Michio Inoue
Russell Graves, Peeyush Pankaj, Vineet J. Kuruvilla, Rachel Johnson, and Michio Inoue. Data-driven prognostics and diagnostics of industrial machinery – a turbofan engine case study. InProceedings of the Asia Pacific Conference of the PHM Society, 2023. doi: 10.36001/phmap.2023.v4i1.3690. URL https://doi.org/10.36001/phmap.2023.v4i1.3690
-
[10]
Yile Gu et al. Argos: Agentic time-series anomaly detection with autonomous rule generation via large language models, 2025. URLhttps://arxiv.org/abs/2501.14170
-
[11]
A comparison of residual-based methods on fault detection
Chi-Ching Hsu, Gaetan Frusque, and Olga Fink. A comparison of residual-based methods on fault detection. InAnnual Conference of the PHM Society, 2023. doi: 10.36001/phmconf.2023.v15i1.3444. URLhttps://doi.org/10.36001/phmconf.2023.v15i1.3444
-
[12]
Truong, Weixin Liang, Fan-Yun Sun, and Nick Haber
Tianyu Hua, Harper Hua, Violet Xiang, Benjamin Klieger, Sang T. Truong, Weixin Liang, Fan-Yun Sun, and Nick Haber. Researchcodebench: Benchmarking llms on implementing novel machine learning research code, 2025. URLhttps://arxiv.org/abs/2506.02314
-
[13]
AutoIAD: Manager-driven multi-agent collaboration for automated industrial anomaly detection, 2025
Dongwei Ji, Bingzhang Hu, and Yi Zhou. AutoIAD: Manager-driven multi-agent collaboration for automated industrial anomaly detection, 2025. URLhttps://arxiv.org/abs/2508.05503
-
[14]
AIDE: AI-Driven Exploration in the Space of Code
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. AIDE: AI-Driven Exploration in the Space of Code, February 2025. URL http://arxiv.org/abs/ 2502.13138. arXiv:2502.13138
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
A recipe for training neural networks
Andrej Karpathy. A recipe for training neural networks. https://karpathy.github.io/2019/04/ 25/recipe/, 2019. Blog post; accessed 2026-04-28. 10
2019
-
[16]
From reproduction to replication: Evaluating research agents with progressive code masking, 2025
Gyeongwon James Kim, Alex Wilf, Louis-Philippe Morency, and Daniel Fried. From reproduction to replication: Evaluating research agents with progressive code masking, 2025. URL https://arxiv. org/abs/2506.19724
- [17]
-
[18]
PHM-Vibench: A unified and factory-style vibration benchmarking framework for the foundation model era
Qi Li, Bojian Chen, Xuan Li, Qitong Chen, Liang Chen, Changqing Shen, Lu Lu, Zhaoye Qin, and Fulei Chu. PHM-Vibench: A unified and factory-style vibration benchmarking framework for the foundation model era. InProceedings of the Asia Pacific Conference of the PHM Society 2025, 2025. URL https: //papers.phmsociety.org/index.php/phmap/article/view/4303
2025
-
[19]
Deepcode: Open agentic coding,
Zongwei Li, Zhonghang Li, Zirui Guo, Xubin Ren, and Chao Huang. Deepcode: Open agentic coding,
- [20]
-
[21]
Lin Lin, Jinlei Wu, Song Fu, Sihao Zhang, Changsheng Tong, and Lizheng Zu. Channel attention & temporal attention based temporal convolutional network: A dual attention framework for remaining useful life prediction of the aircraft engines.Advanced Engineering Informatics, 60:102372, 2024. doi: 10.1016/j.aei.2024.102372. URLhttps://doi.org/10.1016/j.aei.2...
-
[22]
Zijie Lin, Yiqing Shen, Qilin Cai, He Sun, Jinrui Zhou, and Mingjun Xiao. Autop2c: An llm-based agent framework for code repository generation from multimodal content in academic papers, 2025. URL https://arxiv.org/abs/2504.20115
-
[23]
TS-Agent: Understanding and Reasoning Over Raw Time Series via Iterative Insight Gathering
Penghang Liu, Elizabeth Fons, Annita Vapsi, Mohsen Ghassemi, Svitlana Vyetrenko, Daniel Borrajo, Vamsi K. Potluru, and Manuela Veloso. Ts-agent: Understanding and reasoning over raw time series via iterative insight gathering, 2026. URLhttps://arxiv.org/abs/2510.07432
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, September 2024. URLhttp://arxiv.org/ abs/2408.06292. arXiv:2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Prbench: End-to-end paper reproduction in physics research, 2026
Shi Qiu, Junyi Deng, Yiwei Deng, Haoran Dong, Jieyu Fu, Mao Li, Zeyu Li, Zhaolong Zhang, Huiwen Zheng, Leidong Bao, Anqi Lv, Zihan Mo, Yadi Niu, Yiyang Peng, Yu Tian, Yili Wang, Ziyu Wang, Zi-Yu Wang, Jiashen Wei, Liuheng Wu, Aoran Xue, Leyi Yang, Guanglu Yuan, Xiarui Zhan, Jingjun Zhang, Zifan Zheng, Pengfei Liu, Linrui Zhen, Kaiyang Li, Qichang Li, Zihe...
-
[26]
Darius Roman, Saurabh Saxena, Valentin Robu, Michael Pecht, and David Flynn. Machine learning pipeline for battery state-of-health estimation.Nature Machine Intelligence, 3(5):447–456, 2021. doi: 10.1038/s42256-021-00312-3. URLhttps://doi.org/10.1038/s42256-021-00312-3
-
[27]
Agent Laboratory: Using LLM Agents as Research Assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent Laboratory: Using LLM Agents as Research Assistants, June 2025. URLhttp://arxiv.org/abs/2501.04227. arXiv:2501.04227
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Paper2Code: Automating code generation from scientific papers in machine learning, 2025
Minju Seo, Jinheon Baek, Seongyun Lee, and Sung Ju Hwang. Paper2Code: Automating code generation from scientific papers in machine learning, 2025. URL https://arxiv.org/abs/2504.17192. To appear in ICLR 2026
-
[29]
Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan. Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark,
-
[30]
URLhttps://arxiv.org/abs/2409.11363
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
PaperBench: Evaluating AI's Ability to Replicate AI Research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. PaperBench: Evaluating AI’s ability to replicate AI research, 2025. URL https://arxiv.org/abs/ 2504.01848
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Meghana Sudarshan, Jaya Vikeswara Rao Vajja, and Vikas Tomar. DegradAI: A scalable framework for early battery health diagnosis from limited data.npj Clean Energy, 1(1):8, 2025. doi: 10.1038/ s44406-025-00008-2. URLhttps://doi.org/10.1038/s44406-025-00008-2. 11
-
[33]
Pei Tang, Zetao Qiu, Zhongran Yao, Jiahao Pan, Dashuai Cheng, Xiaoyong Gu, and Changcheng Sun. Lithium-ion battery RUL prediction based on optimized VMD-SSA-PatchTST algorithm.Scientific Reports, 15:26824, 2025. doi: 10.1038/s41598-025-11934-7. URL https://doi.org/10.1038/ s41598-025-11934-7
-
[34]
Daigle, Shankar Sankararaman, Kai Goebel, and Jason Watkins
Christopher Teubert, Matthew J. Daigle, Shankar Sankararaman, Kai Goebel, and Jason Watkins. A Generic Software Architecture for Prognostics (GSAP).International Journal of Prognostics and Health Management, 8(2), November 2020. ISSN 2153-2648, 2153-2648. doi: 10.36001/ijphm.2017.v8i2.2618. URLhttps://papers.phmsociety.org/index.php/ijphm/article/view/2618
-
[35]
Christopher Teubert, Katelyn Jarvis, Matteo Corbetta, Chetan Kulkarni, and Matthew Daigle. ProgPy: Python packages for prognostics and health management of engineering systems.Journal of Open Source Software, 8(87):5099, 2023. doi: 10.21105/joss.05099. URL https://doi.org/10.21105/joss. 05099
-
[36]
Minyang Tian et al. SciCode: A research coding benchmark curated by scientists, 2024. URL https: //arxiv.org/abs/2407.13168
-
[37]
CodeRefine: A pipeline for enhancing LLM- generated code implementations of research papers, 2024
Ekaterina Trofimova, Emil Sataev, and Abhijit Singh Jowhari. CodeRefine: A pipeline for enhancing LLM- generated code implementations of research papers, 2024. URL https://arxiv.org/abs/2408.13366
-
[38]
Tim von Hahn and Chris K. Mechefske. Computational reproducibility within prognostics and health management, 2022. URLhttps://arxiv.org/abs/2205.15489
-
[39]
Fujin Wang, Quanquan Zhi, Zhibin Zhao, Zhi Zhai, Yingkai Liu, Huan Xi, Shibin Wang, and Xuefeng Chen. Inherently interpretable physics-informed neural network for battery modeling and prognosis.IEEE Transactions on Neural Networks and Learning Systems, 36(1):1145–1159, 2025. doi: 10.1109/TNNLS. 2023.3329368. URLhttps://doi.org/10.1109/TNNLS.2023.3329368
-
[40]
Zili Wang, Yiming Zhang, Lemiao Qiu, Shuyou Zhang, Joo-Ho Choi, and Feifan Xiang. Bayesian gated- transformer model for risk-aware prediction of aero-engine remaining useful life.Expert Systems with Applications, 238(Part B):121859, 2024. doi: 10.1016/j.eswa.2023.121859. URL https://doi.org/10. 1016/j.eswa.2023.121859
-
[41]
Xingjian Wu, Junkai Lu, Zhengyu Li, Xiangfei Qiu, Jilin Hu, Chenjuan Guo, Christian S. Jensen, and Bin Yang. TimeART: Towards Agentic Time Series Reasoning via Tool-Augmentation, January 2026. URL http://arxiv.org/abs/2601.13653. arXiv:2601.13653
-
[42]
Yanzheng Xiang, Hanqi Yan, Shuyin Ouyang, Lin Gui, and Yulan He. SciReplicate-Bench: Benchmarking LLMs in agent-driven algorithmic reproduction from research papers, 2025. URL https://arxiv.org/ abs/2504.00255
-
[43]
Zhaofan Xu, Zewang Chen, Lin Yang, and Songyuan Zhang. State of health estimation for lithium-ion batteries based on incremental capacity analysis and transformer modeling.Applied Soft Computing, 165:112072, 2024. doi: 10.1016/j.asoc.2024.112072. URL https://doi.org/10.1016/j.asoc.2024. 112072
-
[44]
V olkan Yamacli. Battery usage-profile classification via multimodal vision transformer with feature-level fusion and ensemble method.IEEE Access, 13:174664–174683, 2025. doi: 10.1109/ACCESS.2025. 3618776. URLhttps://doi.org/10.1109/ACCESS.2025.3618776
-
[45]
TS-Reasoner: Domain-Oriented Time Series Inference Agents for Reasoning and Automated Analysis.Transactions on Machine Learning Research, December 2025
Wen Ye, Wei Yang, Defu Cao, Yizhou Zhang, Lumingyuan Tang, Jie Cai, and Yan Liu. TS-Reasoner: Domain-Oriented Time Series Inference Agents for Reasoning and Automated Analysis.Transactions on Machine Learning Research, December 2025. ISSN 2835-8856. URL https://openreview.net/ forum?id=yhy7Vigjcf
2025
-
[46]
Yujie Zhang, Mingyang Du, and Qiang Miao. CART-Net: A causal adaptive residual time network for remaining useful life prediction of aeroengines under varying operating conditions.IEEE Internet of Things Journal, 12(23):50291–50303, 2025. doi: 10.1109/JIOT.2025.3610545. URL https://doi.org/ 10.1109/JIOT.2025.3610545
-
[47]
Zhiyao Zhang, Pengpeng Chen, Chenguang Xing, Bo Liu, Ruo Wang, Longxiao Li, Xiaohui Chen, and Enrico Zio. A data augmentation boosted dual informer framework for the performance degradation prediction of aero-engines.IEEE Sensors Journal, 2023. doi: 10.1109/JSEN.2023.3269030. URL https://doi.org/10.1109/JSEN.2023.3269030
-
[48]
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
Xuanle Zhao, Zilin Sang, Yuxuan Li, Qi Shi, Shuo Wang, Duzhen Zhang, Xu Han, Zhiyuan Liu, and Maosong Sun. Autoreproduce: Automatic ai experiment reproduction with paper lineage, 2025. URL https://arxiv.org/abs/2505.20662. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Jiahui Zhou, Dan Li, Boxin Li, Xiao Zhang, Erli Meng, Lin Li, Zhuomin Chen, Jian Lou, and See-Kiong Ng. Time Series Reasoning via Process-Verifiable Thinking Data Synthesis and Scheduling for Tailored LLM Reasoning, February 2026. URLhttp://arxiv.org/abs/2602.07830. arXiv:2602.07830. 13 A Paper corpus summary Our corpus contains 16 PHM papers selected to ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.