ADWIN: Adaptive Windows for Horizon-Aware On-Policy Distillation
Pith reviewed 2026-06-29 14:34 UTC · model grok-4.3
The pith
ADWIN shortens teacher-anchored prefixes in on-policy distillation via online alignment audits while preserving update direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
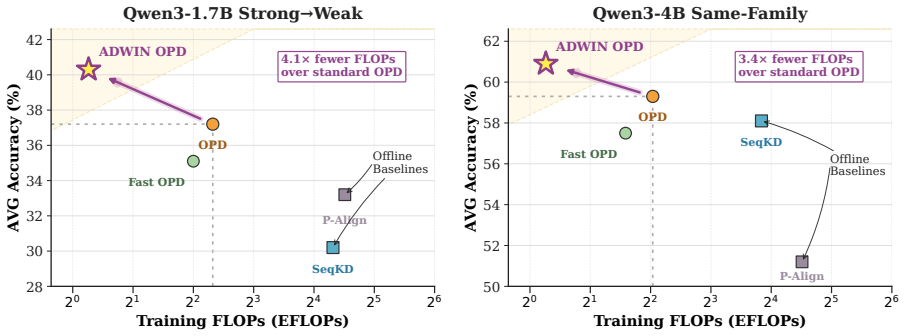
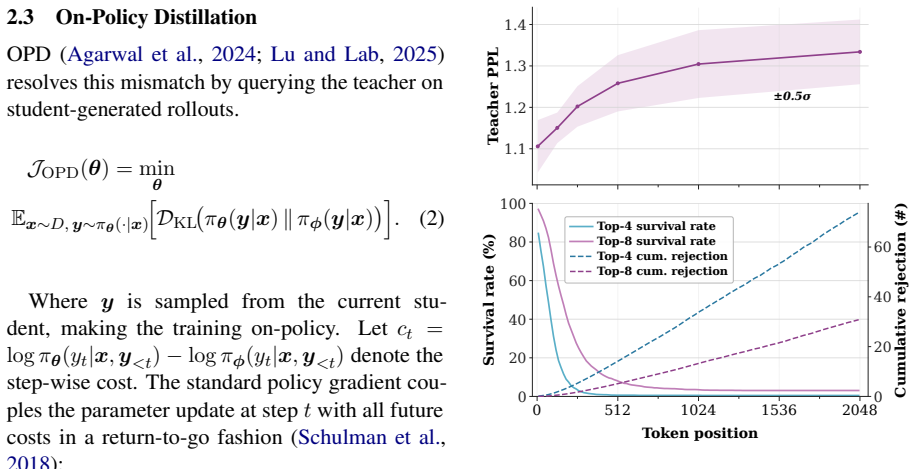
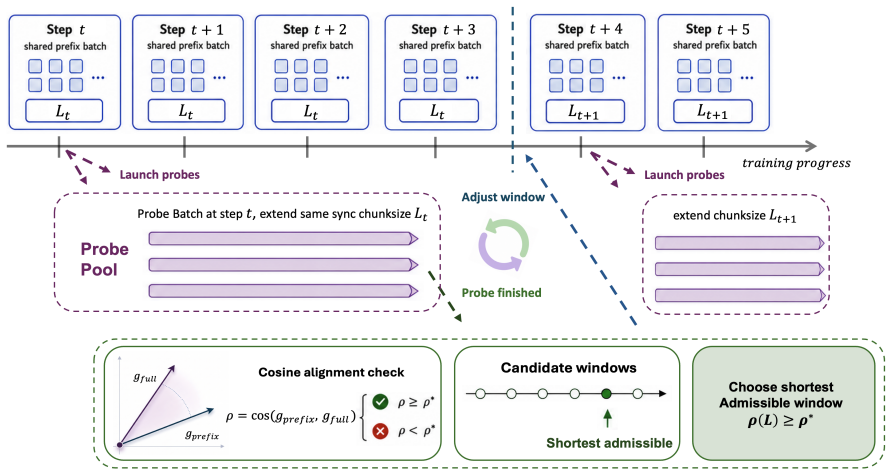
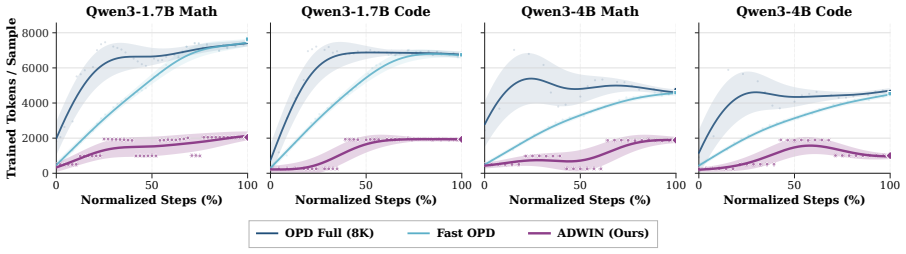
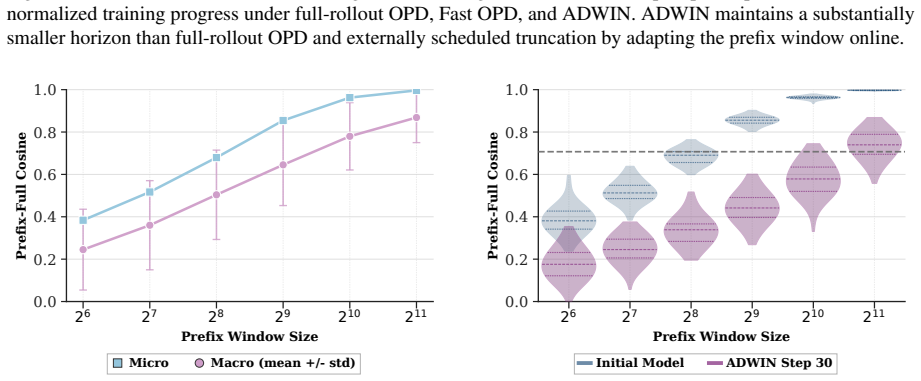
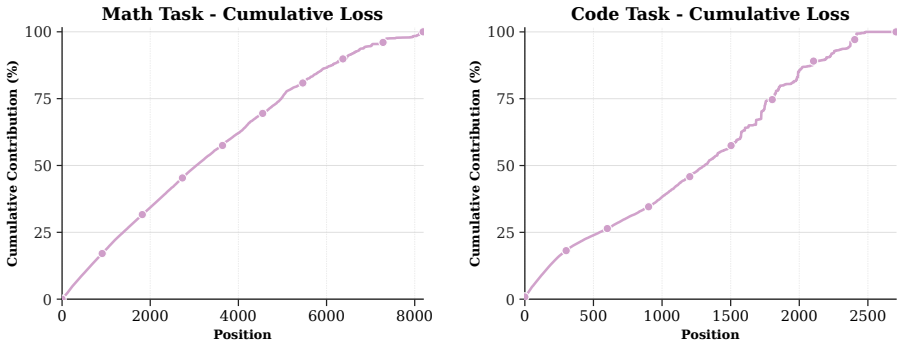
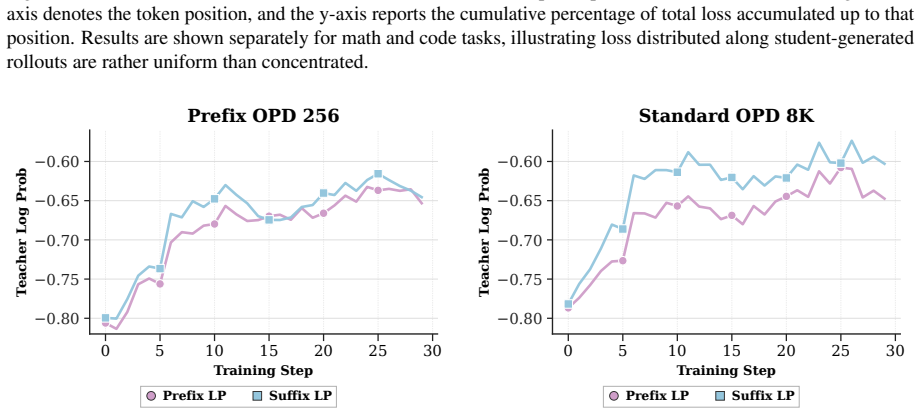
ADWIN is an adaptive-window framework for on-policy distillation that decides rollout lengths online as an admissibility question. Training occurs on short teacher-anchored prefixes while delayed full-rollout probes audit whether those prefixes preserve the long-horizon OPD update direction; the horizon is then adapted with staleness control. Across math and code reasoning benchmarks the approach improves the accuracy-compute trade-off relative to both full-rollout OPD and fixed-prefix baselines.
What carries the argument
ADWIN, an adaptive-window framework that treats rollout length as an online admissibility decision audited by delayed full-rollout probes.
If this is right
- End-to-end training cost drops by up to 4.1 times compared with full-rollout OPD.
- Accuracy stays comparable or improves on math and code reasoning benchmarks.
- The gains hold in single-task, multi-task, and strong-to-weak distillation settings.
- The method outperforms both full-rollout OPD and fixed prefix-based baselines on the accuracy-compute frontier.
Where Pith is reading between the lines
- The useful-supervision-horizon idea could be tested in non-reasoning domains such as general language modeling where trajectory drift may behave differently.
- If the alignment audit cost stays low, the same windowing logic might reduce memory pressure during very long context distillation.
- Repeated application across successive student generations might compound the compute savings beyond the single-generation numbers reported.
Load-bearing premise
Short aligned prefixes can substitute for full rollouts without changing the direction of the on-policy distillation update.
What would settle it
An experiment that measures end-to-end accuracy and total compute when ADWIN is forced to use only its short prefixes versus forced full rollouts on the same math and code benchmarks; a large accuracy drop or loss of the reported cost reduction would falsify the claim.
Figures

read the original abstract
On-policy distillation (OPD) transfers reasoning behavior by training a student on teacher feedback along student-generated trajectories, but standard full-rollout training ties every update to a costly completion and can over-allocate supervision to late positions with low marginal value for the current student. We revisit this assumption through the useful supervision horizon: student-induced rollouts can drift from teacher-preferred continuations, while aligned prefixes may already preserve the long-horizon OPD update direction. We propose ADWIN, an adaptive-window framework for OPD that treats rollout length as an online admissibility decision, training on short teacher-anchored prefixes while using delayed full-rollout probes to audit prefix--full alignment and adapt the next horizon with staleness control. Across math and code reasoning benchmarks in single-task, multi-task, and strong-to-weak settings, ADWIN improves the accuracy--compute trade-off over full-rollout OPD and prefix-based baselines, reducing end-to-end training cost by up to 4.1 times while achieving comparable or better accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ADWIN, an adaptive-window framework for on-policy distillation (OPD) that treats rollout length as an online admissibility decision. It trains on short teacher-anchored prefixes while using delayed full-rollout probes to audit prefix-full alignment and adapt the horizon with staleness control. The central empirical claim is that this improves the accuracy-compute trade-off over full-rollout OPD and prefix-based baselines, achieving up to 4.1x reduction in end-to-end training cost with comparable or better accuracy on math and code reasoning benchmarks across single-task, multi-task, and strong-to-weak settings.
Significance. If the empirical results hold, ADWIN offers a practical method for reducing the computational cost of distilling reasoning behavior by dynamically identifying the useful supervision horizon, which could scale OPD to larger models and datasets where full rollouts are prohibitive.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work and for recommending acceptance. We are glad that the core contribution of treating rollout length as an online admissibility decision, together with the reported accuracy-compute improvements, was viewed as significant.
Circularity Check
No significant circularity detected
full rationale
The paper proposes an algorithmic framework (ADWIN) for adaptive rollout horizons in on-policy distillation and validates it via empirical benchmarks across math/code tasks. No mathematical derivation chain, fitted-parameter-as-prediction, or self-citation load-bearing step is present; the central efficiency claim rests on reported accuracy-compute measurements rather than reducing to a definitional identity or prior self-citation. The useful-supervision-horizon premise is motivational and externally falsifiable via the experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Student-induced rollouts can drift from teacher-preferred continuations while aligned prefixes may preserve the long-horizon OPD update direction.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. 2024. On-policy distillation of language models: Learning from self-generated mistakes. In The twelfth international conference on learning representations
2024
-
[4]
AI-MO. 2024. Aime 2024. https://huggingface.co/datasets/AI-MO/aimo-validation-aime
2024
-
[5]
Chenxin An, Zhihui Xie, Xiaonan Li, Lei Li, Jun Zhang, Shansan Gong, Ming Zhong, Jingjing Xu, Xipeng Qiu, Mingxuan Wang, and Lingpeng Kong. 2025. https://hkunlp.github.io/blog/2025/Polaris Polaris: A post-training recipe for scaling reinforcement learning on advanced reasoning models
2025
-
[6]
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. 2015. Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information processing systems, 28
2015
-
[7]
ByteDance-Seed. 2025. Beyondaime: Advancing math reasoning evaluation beyond high school olympiads. [https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME](https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME)
2025
-
[8]
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, and 1 others. 2025. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, and 1 others. 2023. Faith and fate: Limits of transformers on compositionality. Advances in neural information processing systems, 36:70293--70332
2023
-
[10]
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao. 2026. Revisiting on-policy distillation: Empirical failure modes and simple fixes. arXiv preprint arXiv:2603.25562
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
GLM-5-Team . 2026. https://arxiv.org/abs/2602.15763 Glm-5: from vibe coding to agentic engineering . Preprint, arXiv:2602.15763
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2024. Minillm: Knowledge distillation of large language models. In International Conference on Learning Representations, volume 2024, pages 32694--32717
2024
-
[13]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [14]
-
[15]
Jonas H \"u botter, Frederike L \"u beck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and 1 others. 2026. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.2080Is your code generated by chatGPT2
-
[16]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. https://openreview.net/forum?id=chfJJYC3iL Livecodebench: Holistic and contamination free evaluation of large language models for code . In The Thirteenth International Conference on Learning Representations
2025
-
[17]
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. 2026. Stable on-policy distillation through adaptive target reformulation. arXiv preprint arXiv:2601.07155
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
- [19]
-
[20]
Yoon Kim and Alexander M Rush. 2016. Sequence-level knowledge distillation. In Proceedings of the 2016 conference on empirical methods in natural language processing, pages 1317--1327
2016
-
[21]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. https://openreview.net/forum?id=1qvx610Cu7 Is your code generated by chat GPT really correct? rigorous evaluation of large language models for code generation . In Thirty-seventh Conference on Neural Information Processing Systems
2023
- [22]
- [23]
-
[24]
Kevin Lu and Thinking Machines Lab. 2025. https://doi.org/10.64434/tml.20251026 On-policy distillation . Thinking Machines Lab: Connectionism. Https://thinkingmachines.ai/blog/on-policy-distillation
- [25]
-
[26]
OpenCompass. 2025. Aime 2025. https://huggingface.co/datasets/opencompass/AIME2025
2025
-
[27]
Marc'Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. 2015. Sequence level training with recurrent neural networks. arXiv preprint arXiv:1511.06732
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. 2011. https://proceedings.mlr.press/v15/ross11a.html A reduction of imitation learning and structured prediction to no-regret online learning . In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 of Proceedings of Machine Learning Research, pages 6...
2011
- [29]
-
[30]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 2018. https://arxiv.org/abs/1506.02438 High-dimensional continuous control using generalized advantage estimation . Preprint, arXiv:1506.02438
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Guanghui Wang, Zhiyong Yang, Zitai Wang, Shi Wang, Qianqian Xu, and Qingming Huang. 2025. ABKD : Pursuing a proper allocation of the probability mass in knowledge distillation via - -divergence. In International Conference on Machine Learning, pages 65167--65212. PMLR
2025
-
[33]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024. https://doi.org/10.18653/v1/2024.acl-long.510 Math-shepherd: Verify and reinforce LLM s step-by-step without human annotations . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
- [34]
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. 2026 a . https://arxiv.org/abs/2604.03128 Self-distilled rlvr . Preprint, arXiv:2604.03128
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. 2026 b . https://arxiv.org/abs/2602.12125 Learning beyond teacher: Generalized on-policy distillation with reward extrapolation . Preprint, arXiv:2602.12125
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [38]
-
[39]
Zhaoyang Zhang, Shuli Jiang, Yantao Shen, Yuting Zhang, Dhananjay Ram, Shuo Yang, Zhuowen Tu, Wei Xia, and Stefano Soatto. 2026 b . https://arxiv.org/abs/2602.22495 Reinforcement-aware knowledge distillation for llm reasoning . Preprint, arXiv:2602.22495
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. 2026. Self-distilled reasoner: On-policy self-distillation for large language models. arXiv preprint arXiv:2601.18734
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.