Efficient and Scalable Provenance Tracking for LLM-Generated Code Snippets
Pith reviewed 2026-06-29 10:43 UTC · model grok-4.3
The pith
A hybrid vector search plus fingerprinting pipeline tracks LLM code snippet origins at scale with logarithmic query time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
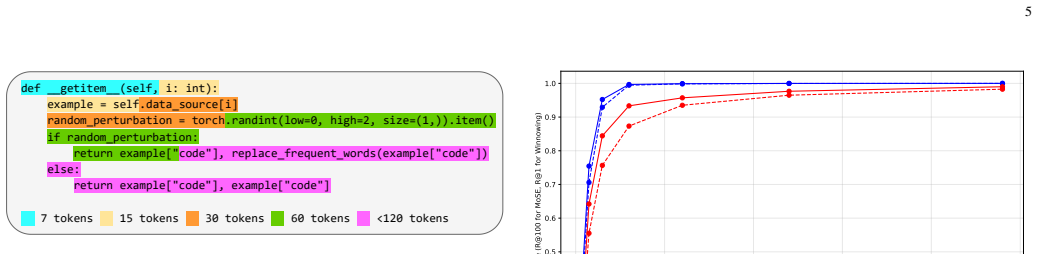
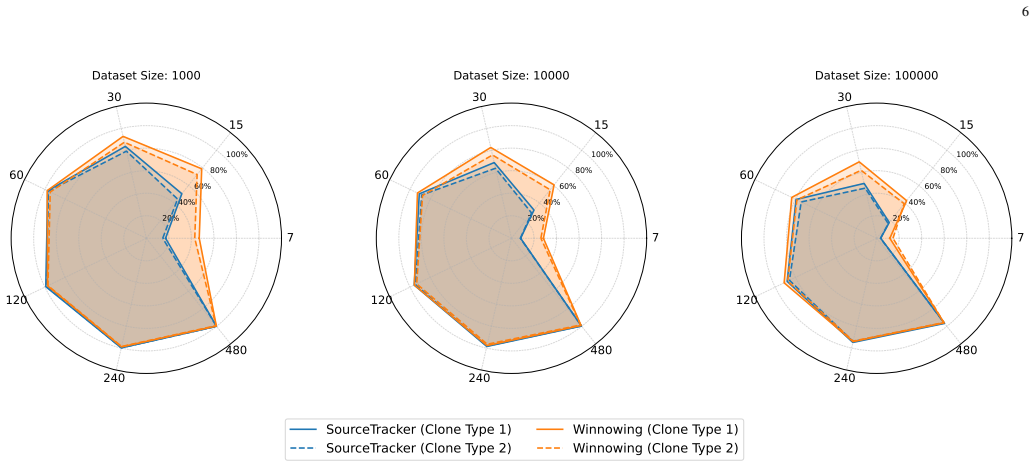
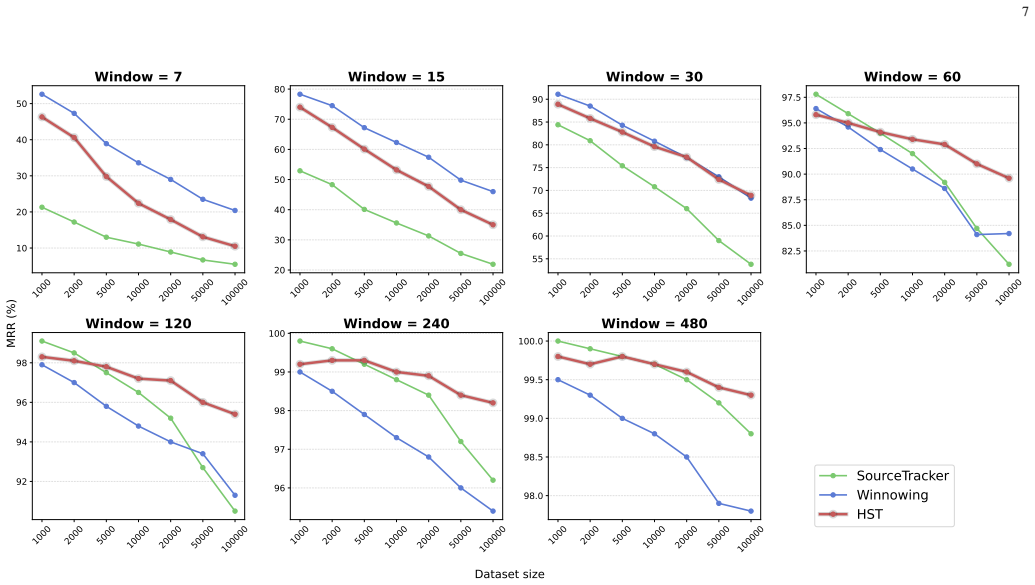
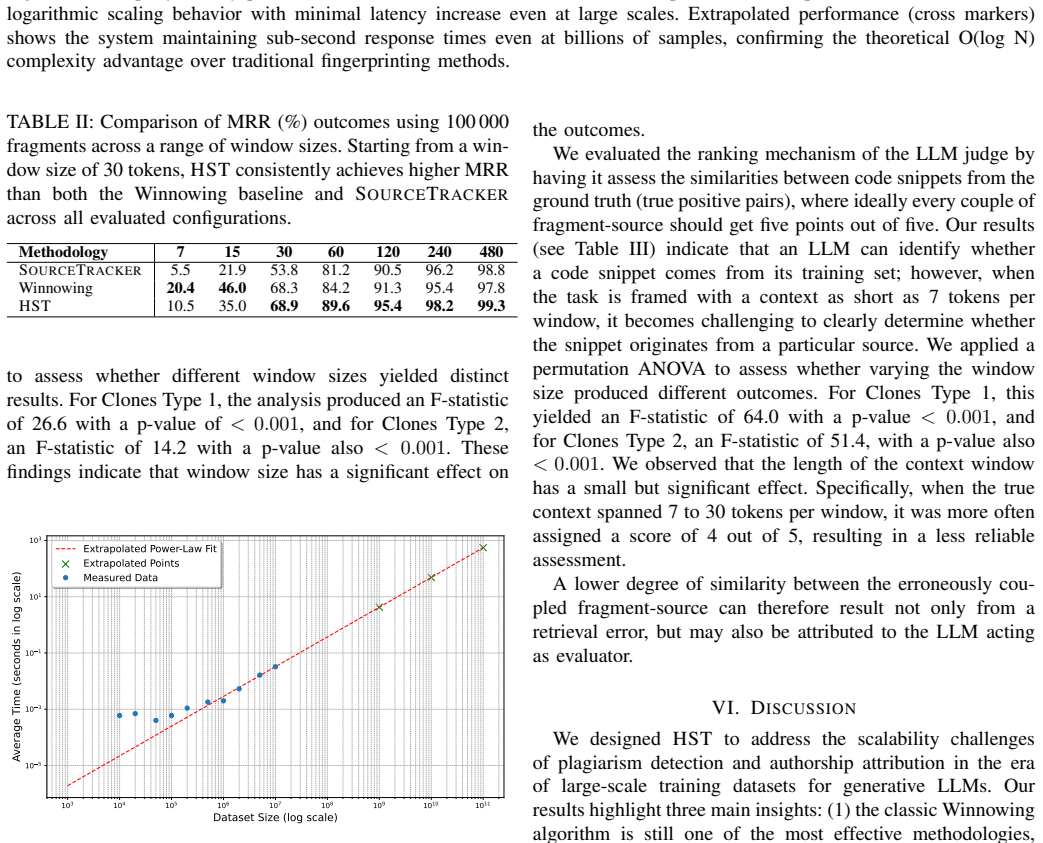
HYBRIDSOURCETRACKER first narrows candidates via vector search with a 300M-parameter code encoder, then re-ranks those candidates with Winnowing fingerprinting. On an in vitro 100k-snippet search space drawn from a 10M-snippet THESTACKV2 subset and using adapted queries that emulate identifier renaming, the hybrid reaches mean reciprocal rank comparable to Winnowing for 30-token fragments and outperforms it by up to 5.4 percent once windows reach 60 tokens or more, all while preserving logarithmic query complexity.
What carries the argument
HYBRIDSOURCETRACKER (HST), the two-stage pipeline that uses vector search for candidate selection followed by Winnowing fingerprint re-ranking.
If this is right
- Provenance tracking for verbatim and adapted code snippets becomes feasible on billion-scale training corpora.
- Query complexity stays logarithmic rather than linear, enabling checks on modern LLM training sets.
- Performance gains over pure fingerprinting appear once code fragments reach 60 tokens or longer.
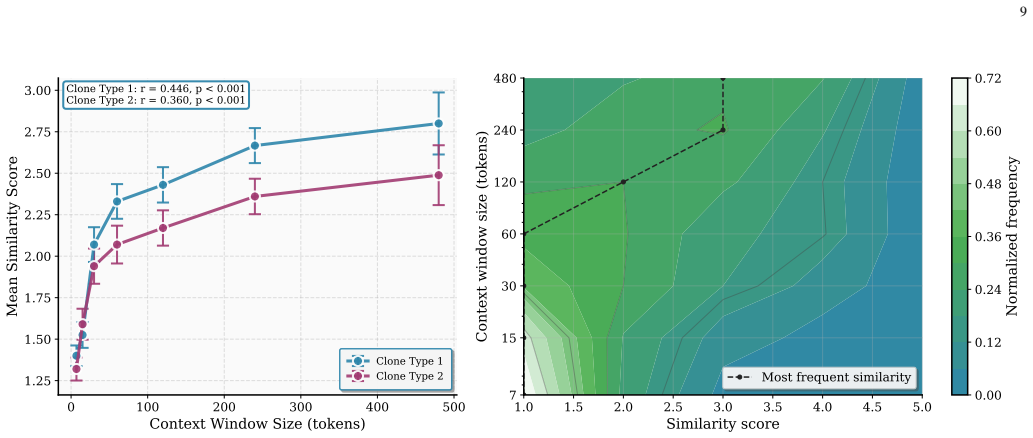
- An LLM judge finds many additional retrieved snippets remain usefully similar to expected sources.
Where Pith is reading between the lines
- Embedding the pipeline inside code-completion tools could surface source attributions to developers in real time.
- The same two-stage pattern could be tested on provenance for generated text or other non-code artifacts.
- Raising first-stage recall would improve end-to-end accuracy without altering the fingerprint stage.
Load-bearing premise
The first-stage vector search must retrieve the true source inside its small candidate set with high enough recall that the second-stage fingerprinting can still succeed.
What would settle it
Measure the first-stage recall directly by counting how often the ground-truth source appears among the top-k vector candidates returned for the 100k-snippet adapted-query test set.
Figures

read the original abstract
Large language models (LLMs) for code completion and generation are increasingly used in software development, yet they may reproduce training examples verbatim and without authorship attribution, raising legal and ethical concerns around plagiarism and license compliance. Classical fingerprint-based plagiarism detectors based on fingerprinting, such as Winnowing, remain highly effective, yet the inspection requires comparing fragments of code to the entire training set, and their linear-time search makes them impractical for the billion-scale corpora used to train modern code LLMs. To bridge this gap, we introduce SOURCETRACKER, a 300M-parameter encoder tailored for code retrieval, together with a hybrid two-stage provenance-tracking pipeline HYBRIDSOURCETRACKER (HST). HST first narrows down a small set of candidate snippets via vector search, then re-ranks those candidates using Winnowing on exact fingerprints. We train and evaluate our system on a 10M-snippet subset of the THESTACKV2 dataset, with both verbatim and adapted snippets that emulate realistic identifier renaming. On an in vitro 100k-snippet search space with adapted queries, our hybrid approach reaches a mean reciprocal rank on par with Winnowing for 30-token fragments. Then, starting from windows >= 60 tokens, it consistently over-performs by up to 5.4% while preserving logarithmic-time query complexity. In a complementary evaluation using an LLM-based judge, we find that many retrieved snippets not labeled as ground truth are still highly similar to the expected sources, particularly with longer context windows, and thus remain useful for end users. Overall, our results demonstrate that integrating vector search with fingerprinting enables scalable, high-precision provenance tracking for code produced by LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SOURCETRACKER, a 300M-parameter encoder for code retrieval, and HYBRIDSOURCETRACKER (HST), a hybrid two-stage provenance-tracking pipeline. HST first narrows candidates via vector search then re-ranks with Winnowing fingerprinting. It is trained and evaluated on a 10M-snippet subset of THESTACKV2 using both verbatim and adapted (identifier-renamed) queries. On an in-vitro 100k-snippet search space with adapted queries, the hybrid reaches MRR on par with Winnowing for 30-token fragments and outperforms by up to 5.4% for windows >=60 tokens while preserving logarithmic query time. A complementary LLM-based judge evaluation finds many non-ground-truth retrieved snippets remain highly similar to expected sources.
Significance. If the results hold after the requested clarifications, the work supplies a concrete, scalable method for provenance tracking of LLM-generated code that combines the efficiency of vector search with the precision of classical fingerprinting. This directly addresses practical needs around license compliance and attribution in billion-scale code corpora. The evaluation on real THESTACKV2 data with realistic adaptations, the explicit comparison to Winnowing, and the dual use of MRR plus LLM-judge similarity constitute measurable strengths.
major comments (2)
- [Evaluation] The reported MRR gains (on par at 30 tokens, +5.4% at >=60 tokens) rest on the premise that the first-stage 300M-parameter vector search returns the true source inside its small candidate set with high recall; the Evaluation section supplies only end-to-end MRR and LLM-judge scores and contains no recall@K, candidate-set size, or ablation isolating the vector-search stage. This omission leaves the source of the hybrid advantage unverified.
- [Evaluation] The complementary LLM-judge evaluation asserts that many non-ground-truth retrieved snippets are still highly similar, yet no inter-annotator agreement, correlation with ground-truth labels, or quantification of judge subjectivity is provided. This weakens the claim that such snippets “remain useful for end users.”
minor comments (2)
- The abstract states results on a “10M-snippet subset” and a “100k-snippet search space” but does not specify the sampling procedure or whether the 100k set is disjoint from training data.
- No error bars, number of runs, or statistical significance tests accompany the reported MRR figures or the 5.4% improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additional analyses.
read point-by-point responses
-
Referee: [Evaluation] The reported MRR gains (on par at 30 tokens, +5.4% at >=60 tokens) rest on the premise that the first-stage 300M-parameter vector search returns the true source inside its small candidate set with high recall; the Evaluation section supplies only end-to-end MRR and LLM-judge scores and contains no recall@K, candidate-set size, or ablation isolating the vector-search stage. This omission leaves the source of the hybrid advantage unverified.
Authors: We agree that the current presentation leaves the contribution of the vector-search stage implicit. In the revised manuscript we will report recall@K for the first-stage retrieval (at multiple K values matching the candidate-set size used in the hybrid), explicitly state the candidate-set size, and add an ablation that compares end-to-end MRR of the hybrid against the vector-search stage alone and against Winnowing alone. These additions will directly verify the premise underlying the reported gains. revision: yes
-
Referee: [Evaluation] The complementary LLM-judge evaluation asserts that many non-ground-truth retrieved snippets are still highly similar, yet no inter-annotator agreement, correlation with ground-truth labels, or quantification of judge subjectivity is provided. This weakens the claim that such snippets “remain useful for end users.”
Authors: We acknowledge that the LLM-judge results would be more robust with explicit validation metrics. We will expand the evaluation section to describe the judge prompt in full, report any correlation that can be computed between judge scores and ground-truth labels on the subset where both are available, and add a limitations paragraph quantifying the single-judge setup and potential subjectivity. If inter-annotator agreement cannot be obtained without new experiments, we will clearly qualify the claim accordingly. revision: partial
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper describes training a 300M-parameter encoder on THESTACKV2 and evaluating a hybrid vector-search + Winnowing pipeline on held-out 100k-snippet queries, reporting end-to-end MRR and LLM-judge similarity. No equations, first-principles derivations, or predictions appear in the abstract or described claims. The central results are direct measurements on external data rather than quantities that reduce by construction to fitted inputs or self-citation chains. Self-citations, if present in the full text, are not load-bearing for the reported performance numbers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
El Tahir Ali, Hussam M
Asim M. El Tahir Ali, Hussam M. Dahwa Abdulla, and V ´aclav Sn´asel. Overview and comparison of plagiarism detection tools. In V ´aclav Sn´asel, Jaroslav Pokorn ´y, and Karel Richta, editors,Proceedings of the Dateso 2011: Annual International Workshop on DAtabases, TExts, Specifications and Objects, Pisek, Czech Republic, April 20, 2011, volume 706 ofCEU...
2011
-
[2]
Ethical implications of chatgpt and other large language models in academia.Frontiers in Artificial Intelligence, 8:1615761, 2025
Ahmad Almufarreh, Ashfaq Ahmad, Muhammad Arshad, Choo Wou Onn, and Robinson Elechi. Ethical implications of chatgpt and other large language models in academia.Frontiers in Artificial Intelligence, 8:1615761, 2025
2025
-
[3]
code2vec: learning distributed representations of code.Proc
Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. code2vec: learning distributed representations of code.Proc. ACM Program. Lang., 3(POPL):40:1–40:29, 2019
2019
-
[4]
Do llms provide links to code similar to what they generate? A study with gemini and bing copilot
Daniele Bifolco, Pietro Cassieri, Giuseppe Scanniello, Massimiliano Di Penta, and Fiorella Zampetti. Do llms provide links to code similar to what they generate? A study with gemini and bing copilot. In22nd IEEE/ACM International Conference on Mining Software Repositories, MSR@ICSE 2025, Ottawa, ON, Canada, April 28-29, 2025, pages 223–
2025
-
[5]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tram `er, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pond ´e de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavari...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Software heritage: Why and how to preserve software source code
Roberto Di Cosmo and Stefano Zacchiroli. Software heritage: Why and how to preserve software source code. In Shoichiro Hara, Shigeo Sugimoto, and Makoto Goto, editors,Proceedings of the 14th Interna- tional Conference on Digital Preservation, iPRES 2017, Kyoto, Japan, September 25-29, 2017, 2017
2017
-
[8]
Mose: Hierarchical self-distillation enhances early layer embed- dings, 2025
Andrea Gurioli, Federico Pennino, Jo ˜ao Monteiro, and Maurizio Gab- brielli. Mose: Hierarchical self-distillation enhances early layer embed- dings, 2025
2025
-
[9]
Lemley, and Percy Liang
Peter Henderson, Xuechen Li, Dan Jurafsky, Tatsunori Hashimoto, Mark A. Lemley, and Percy Liang. Foundation models and fair use. J. Mach. Learn. Res., 24:400:1–400:79, 2023
2023
-
[10]
Large language models for software engineering: A systematic literature review.ACM Trans
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: A systematic literature review.ACM Trans. Softw. Eng. Methodol., 33(8):220:1–220:79, 2024
2024
-
[11]
Jooyoung Lee, Toshini Agrawal, Adaku Uchendu, Thai Le, Jinghui Chen, and Dongwon Lee. Plagbench: Exploring the duality of large language models in plagiarism generation and detection.CoRR, abs/2406.16288, 2024
-
[12]
Do language models plagiarize? In Ying Ding, Jie Tang, Juan F
Jooyoung Lee, Thai Le, Jinghui Chen, and Dongwon Lee. Do language models plagiarize? In Ying Ding, Jie Tang, Juan F. Sequeda, Lora Aroyo, Carlos Castillo, and Geert-Jan Houben, editors,Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, pages 3637–3647. ACM, 2023
2023
-
[13]
Lemley and Bryan Casey
Mark A. Lemley and Bryan Casey. Fair learning.Texas Law Review, 99(4):743–804, 2021. Available at SSRN: https://ssrn.com/abstract= 3528447
2021
-
[14]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, Jo˜ao Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Log...
2023
-
[15]
Smith, Sophie Lebrecht, Yejin Choi, Hannaneh Hajishirzi, Ali Farhadi, and Jesse Dodge
Jiacheng Liu, Taylor Blanton, Yanai Elazar, Sewon Min, Yen-Sung Chen, Arnavi Chheda-Kothary, Huy Tran, Byron Bischoff, Eric Marsh, Michael Schmitz, Cassidy Trier, Aaron Sarnat, Jenna James, Jon Borchardt, Bailey Kuehl, Evie Yu-Yen Cheng, Karen Farley, Sruthi Sreeram, Taira Anderson, David Albright, Carissa Schoenick, Luca Soldaini, Dirk Groeneveld, Rock Y...
-
[16]
Infini-gram: Scaling unbounded n-gram language models to a trillion tokens, 2025
Jiacheng Liu, Sewon Min, Luke Zettlemoyer, Yejin Choi, and Hannaneh Hajishirzi. Infini-gram: Scaling unbounded n-gram language models to a trillion tokens, 2025
2025
-
[17]
StarCoder 2 and The Stack v2: The Next Generation
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Z...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Malkov and Dmitry A
Yury A. Malkov and Dmitry A. Yashunin. Efficient and robust approx- imate nearest neighbor search using hierarchical navigable small world graphs.IEEE Trans. Pattern Anal. Mach. Intell., 42(4):824–836, 2020
2020
-
[19]
Rossi, and Thien Huu Nguyen
Thuat Nguyen, Chien Van Nguyen, Viet Dac Lai, Hieu Man, Nghia Trung Ngo, Franck Dernoncourt, Ryan A. Rossi, and Thien Huu Nguyen. CulturaX: A cleaned, enormous, and multilingual dataset for large language models in 167 languages. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of...
2024
-
[20]
Michael-Andrei Panaitescu-Liess, Zora Che, Bang An, Yuancheng Xu, Pankayaraj Pathmanathan, Souradip Chakraborty, Sicheng Zhu, Tom Goldstein, and Furong Huang. Can watermarking large language models prevent copyrighted text generation and hide training data?CoRR, abs/2407.17417, 2024
-
[21]
Raffel, Leandro von Werra, and Thomas Wolf
Guilherme Penedo, Hynek Kydl ´ıcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin A. Raffel, Leandro von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neura...
2024
-
[22]
Qdrant: Vector search engine, 2025
Qdrant Team. Qdrant: Vector search engine, 2025
2025
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine ...
2021
-
[24]
A survey on software clone detection research.Queen’s School of computing TR, 541(115):64–68, 2007
Chanchal Kumar Roy and James R Cordy. A survey on software clone detection research.Queen’s School of computing TR, 541(115):64–68, 2007
2007
-
[25]
Code Llama: Open Foundation Models for Code
Baptiste Rozi `ere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, J ´er´emy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre 14 D´efossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usuni...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Winnow- ing: Local algorithms for document fingerprinting
Saul Schleimer, Daniel Shawcross Wilkerson, and Alex Aiken. Winnow- ing: Local algorithms for document fingerprinting. In Alon Y . Halevy, Zachary G. Ives, and AnHai Doan, editors,Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, California, USA, June 9-12, 2003, pages 76–85. ACM, 2003
2003
-
[27]
Jeffrey Svajlenko and Chanchal K. Roy. Evaluating clone detection tools with bigclonebench. In Rainer Koschke, Jens Krinke, and Martin P. Robillard, editors,2015 IEEE International Conference on Software Maintenance and Evolution, ICSME 2015, Bremen, Germany, September 29 - October 1, 2015, pages 131–140. IEEE Computer Society, 2015
2015
-
[28]
Kakade, and Boaz Barak
Nikhil Vyas, Sham M. Kakade, and Boaz Barak. On provable copyright protection for generative models. In Andreas Krause, Emma Brun- skill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofPro- ceedings of Machine Lear...
2023
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
GitHub Copilot research recitation — parrot or crow? a first look at rote learning in GitHub Copilot suggestions
Albert Ziegler. GitHub Copilot research recitation — parrot or crow? a first look at rote learning in GitHub Copilot suggestions. https://github. blog/ai-and-ml/github-copilot/github-copilot-research-recitation/, 2021. Accessed: 2024-09-25
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.