SARAD: LLM-Based Safety-Aware Hybrid Reinforcement Learning with Collision Prediction for Autonomous Driving
Pith reviewed 2026-06-29 11:47 UTC · model grok-4.3
The pith
SARAD combines large language models with deep reinforcement learning to replace random exploration and add collision prediction for autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
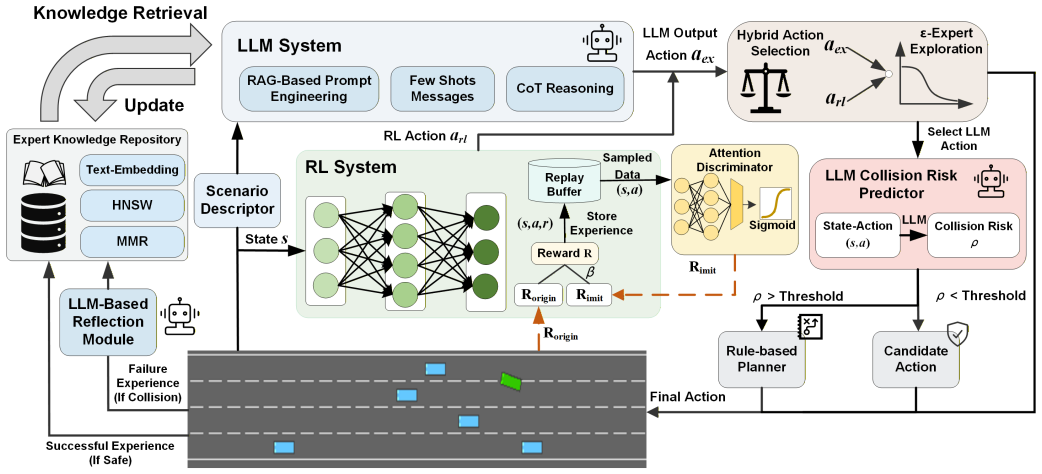
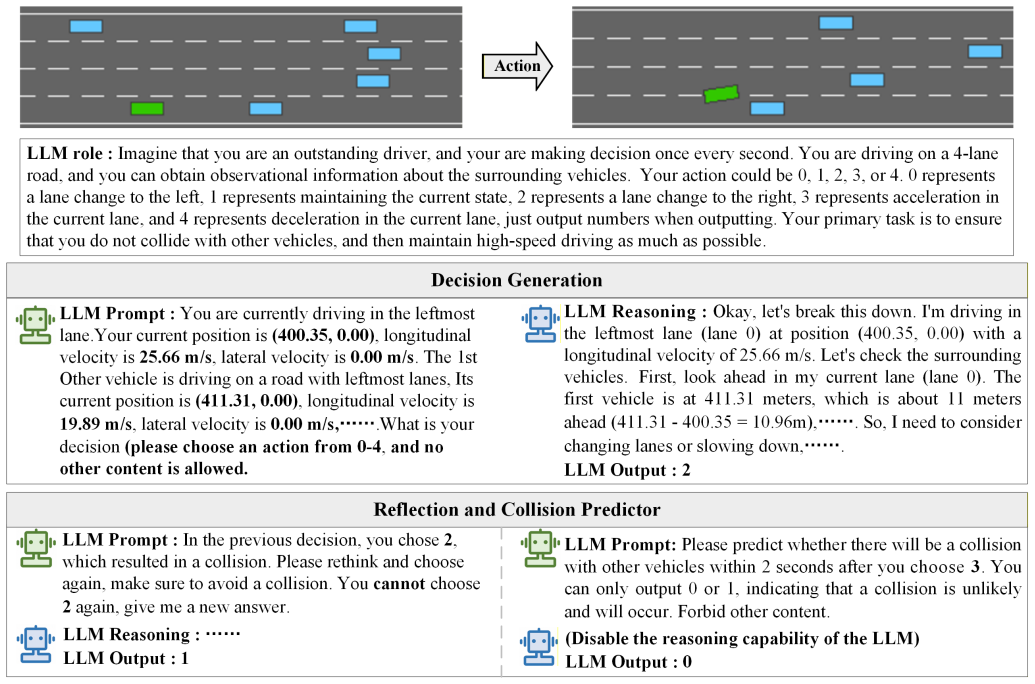
SARAD substitutes the random exploration of DRL with Retrieval-Augmented Generation (RAG)-enhanced, LLM-guided decisions sourced from a dynamic expert knowledge repository. An attention discriminator is proposed to integrate the prior knowledge of LLMs into DRL policy optimization. A collision predictor module, fine-tuned with historical collision data, is further designed to improve vehicle safety.
What carries the argument
The attention discriminator that folds LLM prior knowledge into DRL policy updates, backed by RAG-sourced decisions and a collision predictor trained on historical data.
If this is right
- Training becomes safer because random unsafe actions are replaced by retrieved expert guidance.
- Safety improves through explicit prediction of collisions drawn from recorded incidents.
- Policy convergence accelerates as language model priors steer learning away from poor regions.
- Overall driving metrics rise in the tested highway simulation environment.
Where Pith is reading between the lines
- If latency stays low, the approach could shrink the volume of real-world trial-and-error needed before deployment.
- The same retrieval-plus-prediction pattern might transfer to other sequential decision tasks that mix learned policies with external knowledge.
- Hardware-specific tuning would be required to confirm the method scales to vehicle onboard processors.
Load-bearing premise
The RAG-enhanced LLM decisions and collision predictor can be fused with DRL without creating unacceptable real-time delays or restricting success to the exact simulator and data used in testing.
What would settle it
A timing measurement on embedded hardware showing decision latency above real-time thresholds, or a test run in a new driving scenario where SARAD performs no better than plain DRL, would undermine the central claim.
Figures

read the original abstract
Ensuring both safety and efficiency in decision-making for autonomous driving systems remains a fundamental challenge. Traditional Deep Reinforcement Learning (DRL) suffers from unsafe random exploration and slow convergence, while Large Language Models (LLMs) demonstrate inherent latency in real-time inference operations. To address these limitations, this paper proposes SARAD, a novel safety-aware hybrid framework that synergizes LLMs and DRL for autonomous driving. SARAD substitutes the random exploration of DRL with Retrieval-Augmented Generation (RAG)-enhanced, LLM-guided decisions sourced from a dynamic expert knowledge repository. An attention discriminator is proposed to integrate the prior knowledge of LLMs into DRL policy optimization. A collision predictor module, fine-tuned with historical collision data, is further designed to improve vehicle safety. Extensive experiments show that SARAD achieves significant performance improvements in the Highway-Env simulator, validating the effectiveness of the proposed model in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SARAD, a hybrid framework integrating RAG-enhanced LLM-guided decisions with DRL via an attention discriminator for policy optimization, plus a fine-tuned collision predictor module using historical data, to improve safety and efficiency over pure DRL or LLM approaches in autonomous driving; experiments in the Highway-Env simulator are reported to show significant performance improvements.
Significance. If the empirical gains hold under rigorous evaluation, the work could contribute a practical method for injecting expert knowledge into DRL exploration while mitigating LLM latency, advancing hybrid neuro-symbolic approaches for safety-critical control tasks.
major comments (2)
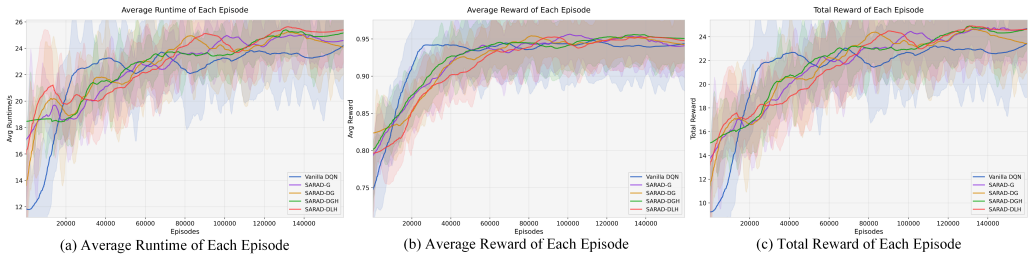
- [§4] §4 (Experiments): The central claim of 'significant performance improvements' is unsupported because the section provides no quantitative metrics (e.g., success rate, collision rate, reward values), no baselines (e.g., standard DQN, PPO, or LLM-only variants), no error bars, and no statistical tests, leaving the effectiveness of the attention discriminator and collision predictor unverified.
- [§3.2, §3.3] §3.2 (Attention Discriminator) and §3.3 (Collision Predictor): The integration mechanism and fine-tuning procedure are described at a high level without equations for the attention weighting or loss function, making it impossible to assess whether the hybrid architecture introduces circularity or requires extensive hyperparameter tuning that undermines the 'safety-aware' claim.
minor comments (2)
- [Abstract, §1] The abstract and §1 repeat the same high-level motivation without distinguishing the novel contribution of the RAG repository from prior LLM-DRL hybrids.
- [§3] Notation for the discriminator output and predictor probability is introduced without a consolidated table of symbols.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We will revise the manuscript to address the concerns raised regarding the experimental evaluation and the technical details of the proposed components.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central claim of 'significant performance improvements' is unsupported because the section provides no quantitative metrics (e.g., success rate, collision rate, reward values), no baselines (e.g., standard DQN, PPO, or LLM-only variants), no error bars, and no statistical tests, leaving the effectiveness of the attention discriminator and collision predictor unverified.
Authors: We agree with the referee that Section 4 currently lacks the necessary quantitative details to fully support the claims. In the revised version, we will include specific metrics such as success rates, collision rates, and reward values. We will also add comparisons to baselines including DQN, PPO, and LLM-only variants, along with error bars from repeated experiments and appropriate statistical tests to verify the significance of the improvements. revision: yes
-
Referee: [§3.2, §3.3] §3.2 (Attention Discriminator) and §3.3 (Collision Predictor): The integration mechanism and fine-tuning procedure are described at a high level without equations for the attention weighting or loss function, making it impossible to assess whether the hybrid architecture introduces circularity or requires extensive hyperparameter tuning that undermines the 'safety-aware' claim.
Authors: We acknowledge that the descriptions in Sections 3.2 and 3.3 are high-level. We will expand these sections in the revision to include the mathematical equations for the attention weighting in the discriminator and the loss function for the collision predictor. Additionally, we will provide more details on the integration mechanism and fine-tuning procedure to clarify that there is no circularity and to discuss the hyperparameter tuning process. revision: yes
Circularity Check
No significant circularity; empirical validation only
full rationale
The paper proposes a hybrid SARAD architecture (RAG-enhanced LLM decisions, attention discriminator, collision predictor module) and reports simulator performance gains in Highway-Env. No derivation chain, equations, or first-principles predictions are presented that could reduce to inputs by construction. All load-bearing claims rest on experimental results rather than self-referential fitting or self-citation of uniqueness theorems. This is the expected non-finding for an applied systems paper without mathematical derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. Al Sallab, S. Yo- gamani, and P. P ´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4909–4926, 2021
2021
-
[2]
L. Wen, D. Fu, X. Li, X. Cai, T. Ma, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “Dilu: A knowledge-driven approach to autonomous driving with large language models,”arXiv preprint arXiv:2309.16292, 2023
-
[3]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
1901
-
[4]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”arXiv preprint arXiv:2310.01412, 2023
-
[5]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
2020
-
[6]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[7]
Deep reinforcement learning with double q-learning,
H. v. Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” inProceedings of the Thirtieth AAAI Conference on Artificial Intelligence, 2016, pp. 2094–2100
2016
-
[8]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,”arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Highway decision-making and motion planning for autonomous driving via soft actor-critic,
X. Tang, B. Huang, T. Liu, and X. Lin, “Highway decision-making and motion planning for autonomous driving via soft actor-critic,”IEEE Transactions on Vehicular Technology, vol. 71, no. 5, pp. 4706–4717, 2022
2022
-
[10]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational Conference on Machine Learning. PMLR, 2017, pp. 1126–1135
2017
-
[11]
Generative adversarial imitation learning,
J. Ho and S. Ermon, “Generative adversarial imitation learning,”Ad- vances in Neural Information Processing Systems, vol. 29, p. 4565–4573, 2016
2016
-
[12]
Learning driving styles for autonomous vehicles from demonstration,
M. Kuderer, S. Gulati, and W. Burgard, “Learning driving styles for autonomous vehicles from demonstration,” in2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 2641–2646
2015
-
[13]
Drivelm: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 256–274
2024
-
[14]
A Language Agent for Autonomous Driving,
J. Mao, J. Ye, Y . Qian, M. Pavone, and Y . Wang, “A language agent for autonomous driving,”arXiv preprint arXiv:2311.10813, 2023
-
[15]
Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles,
C. Cui, Y . Ma, X. Cao, W. Ye, and Z. Wang, “Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles,” IEEE Intelligent Transportation Systems Magazine, vol. 16, no. 4, pp. 81–94, 2024
2024
-
[16]
H. Sha, Y . Mu, Y . Jiang, L. Chen, C. Xu, P. Luo, S. Li, M. Tomizuka, W. Zhan, and M. Ding, “Languagempc: Large language models as deci- sion makers for autonomous driving,”arXiv preprint arXiv:2310.03026, 2023
-
[17]
Planagent: A multi-modal large language agent for closed-loop vehicle motion planning,
Y . Zheng, Z. Xing, Q. Zhang, B. Jin, P. Li, Y . Zheng, Z. Xia, K. Zhan, X. Lang, Y . Chenet al., “Planagent: A multi-modal large language agent for closed-loop vehicle motion planning,”arXiv preprint arXiv:2406.01587, 2024
-
[18]
Grounding large language models in interactive environments with online reinforcement learning,
T. Carta, C. Romac, T. Wolf, S. Lamprier, O. Sigaud, and P.-Y . Oudeyer, “Grounding large language models in interactive environments with online reinforcement learning,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 3676–3713
2023
-
[19]
Guiding pretraining in reinforcement learning with large language models,
Y . Du, O. Watkins, Z. Wang, C. Colas, T. Darrell, P. Abbeel, A. Gupta, and J. Andreas, “Guiding pretraining in reinforcement learning with large language models,” inInternational Conference on Machine Learn- ing. PMLR, 2023, pp. 8657–8677
2023
-
[20]
Large language model guided deep reinforcement learning for decision making in autonomous driving,
H. Pang, Z. Wang, and G. Li, “Large language model guided deep reinforcement learning for decision making in autonomous driving,” arXiv preprint arXiv:2412.18511, 2024
-
[21]
Optimizing autonomous driving for safety: A human-centric approach with llm-enhanced rlhf,
Y . Sun, N. Salami Pargoo, P. Jin, and J. Ortiz, “Optimizing autonomous driving for safety: A human-centric approach with llm-enhanced rlhf,” inCompanion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2024, pp. 76–80
2024
-
[22]
An environment for autonomous driving decision- making,
E. Leurentet al., “An environment for autonomous driving decision- making,” 2018
2018
-
[23]
Q. Team, “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [24]
-
[25]
Probabilistic latent maximal marginal relevance,
S. Guo and S. Sanner, “Probabilistic latent maximal marginal relevance,” inProceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2010, pp. 833– 834
2010
-
[26]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Proceedings of the International Conference on Learning Representa- tions (ICLR), vol. 1, no. 2, p. 3, 2022
2022
-
[28]
Gbdt-lr: A willingness data analysis and prediction model based on machine learning,
H. Xu, “Gbdt-lr: A willingness data analysis and prediction model based on machine learning,” in2022 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA). IEEE, 2022, pp. 396–401
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.