AlphaTransit: Learning to Design City-scale Transit Routes
Pith reviewed 2026-06-29 11:52 UTC · model grok-4.3
The pith
AlphaTransit uses Monte Carlo Tree Search guided by a neural policy-value network to design bus routes that maximize service rate under delayed feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
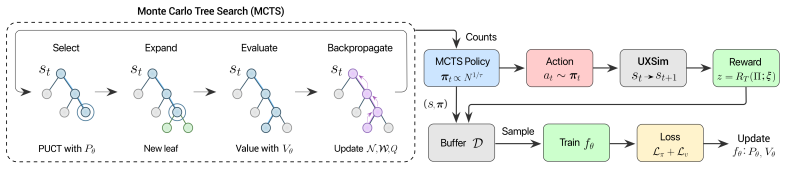
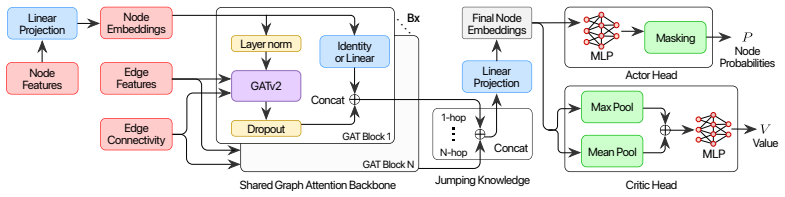
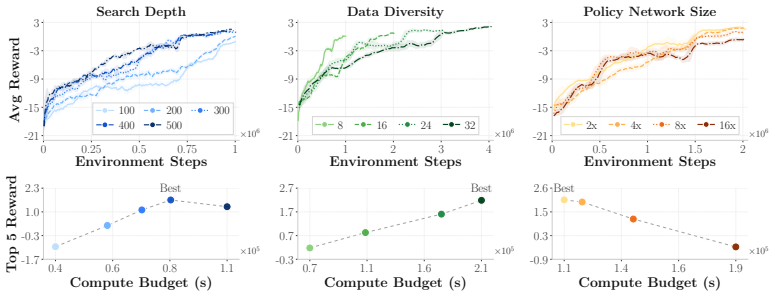
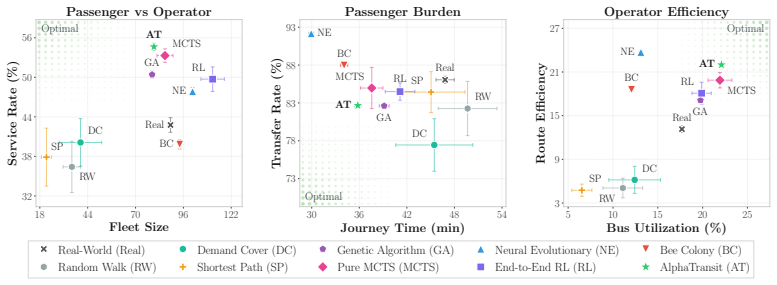
AlphaTransit couples Monte Carlo Tree Search with a neural policy-value network so that the policy proposes route extensions while the value head estimates downstream network quality; this supplies decision-time lookahead during route construction without running simulator rollouts inside the search tree, and on the Bloomington network it produces the highest service rates of 54.6 percent and 82.1 percent under mixed and full transit demand.
What carries the argument
Monte Carlo Tree Search guided by a neural policy-value network that estimates final design quality without internal simulator rollouts.
If this is right
- Coupling learned guidance with MCTS is more effective for transit network design than using either approach alone.
- Route construction can proceed with lookahead predictions that avoid running full simulations at every search node.
- Service rate improvements of roughly 10 to 11 percent are attainable on realistic city networks with census-derived demand.
Where Pith is reading between the lines
- The same hybrid guidance pattern could be tested on other sequential network-design tasks that share delayed feedback, such as power-grid or water-system layout.
- Performance on larger metropolitan areas would reveal whether the current neural estimates remain reliable when route interactions grow more complex.
- Replacing the fixed Bloomington topology with dynamic traffic or construction data would test whether the value estimates can be updated online.
Load-bearing premise
The neural policy-value network supplies sufficiently accurate estimates of final network quality to guide MCTS decisions without any simulator rollouts inside the search tree.
What would settle it
A head-to-head comparison on the same Bloomington benchmark in which AlphaTransit without the value network or with deliberately noisy value estimates fails to exceed the service rates of plain reinforcement learning or unguided MCTS.
Figures

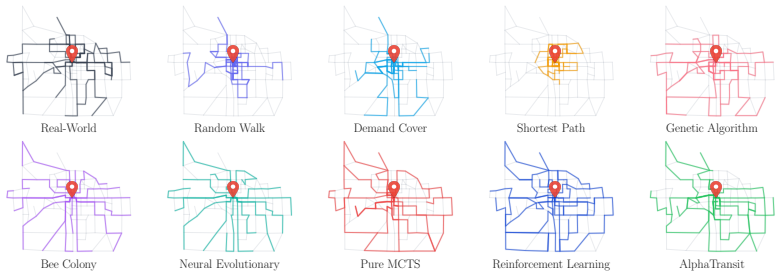
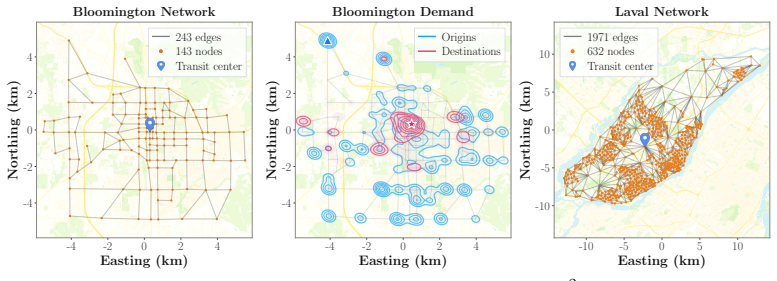
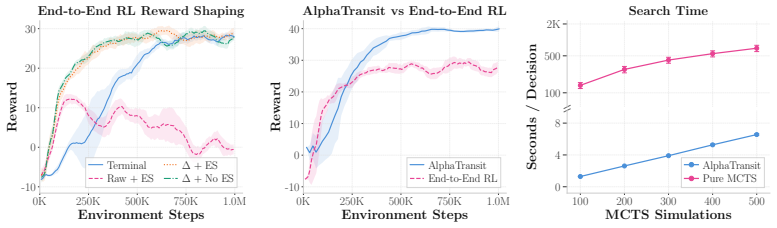


read the original abstract
Designing a transit network requires many sequential route extension decisions, but their quality is often visible only after the full network is assembled. This delayed-feedback challenge lies at the heart of the Transit Route Network Design Problem (TRNDP), where route interactions can be deceptive: an extension that appears useful locally can create transfer bottlenecks, produce redundant overlap, or reduce overall throughput. To guide route construction under delayed simulator feedback, we introduce AlphaTransit, a search-based planning framework for cityscale bus network design. AlphaTransit couples Monte Carlo Tree Search (MCTS) with a neural policy-value network: the policy proposes route extensions, the value estimates downstream design quality, and search uses these predictions to refine each decision. This provides decision-time lookahead during route construction without running simulator rollouts inside the search tree. We evaluate AlphaTransit on a new Bloomington TRNDP benchmark with realistic road topology and censusderived demand, under mixed and full transit demand settings. In the Bloomington network, AlphaTransit attains the highest service rate in both demand settings, reaching 54.6% and 82.1%, respectively. Relative to reinforcement learning without search, these correspond to 9.9% and 11.4% service rate gains; relative to MCTS without learned guidance, they correspond to 2.5% and 11.2% gains. These results suggest that coupling learned guidance with MCTS is more effective than using either approach alone for transit network design. Our code and data are publicly available in https://github.com/poudel-bibek/AlphaTransit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AlphaTransit, a framework that couples Monte Carlo Tree Search (MCTS) with a neural policy-value network to solve the Transit Route Network Design Problem (TRNDP). The policy proposes route extensions while the value head estimates final network quality, enabling lookahead during sequential route construction without simulator rollouts inside the search tree. On a new Bloomington benchmark with realistic topology and census-derived demand, AlphaTransit reports the highest service rates (54.6% mixed demand, 82.1% full demand), yielding 9.9–11.4% gains over RL without search and 2.5–11.2% gains over MCTS without learned guidance. Code and data are released publicly.
Significance. If the central performance claims hold after verification, the work demonstrates that learned value estimates can usefully substitute for rollouts in MCTS for delayed-feedback network design tasks, outperforming either component alone. The public release of code and benchmark data is a clear strength that supports reproducibility and further research on TRNDP variants.
major comments (2)
- [Abstract] Abstract: The headline service-rate gains (54.6%/82.1%, 9.9–11.4% over RL, 2.5–11.2% over plain MCTS) rest on the claim that the learned value head supplies sufficiently accurate estimates of final network quality to replace simulator rollouts inside the MCTS tree. No diagnostics of value prediction quality—such as correlation between predicted value and realized service rate on held-out partial networks, calibration plots, or error statistics—are reported anywhere in the manuscript.
- [Abstract] Abstract: The reported percentage gains are presented without error bars, confidence intervals, or statistical significance tests across multiple random seeds or demand realizations. This makes it impossible to assess whether the observed improvements over the two baselines are robust or could be explained by hyperparameter choices or benchmark-specific tuning.
minor comments (1)
- [Abstract] Abstract and methods: No description of the training procedure for the policy-value network (e.g., loss functions, data generation, or hyperparameter settings) or any ablation isolating the contribution of the value head is provided.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for value-head diagnostics and statistical reporting. We address each major comment below and will incorporate the suggested analyses in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline service-rate gains (54.6%/82.1%, 9.9–11.4% over RL, 2.5–11.2% over plain MCTS) rest on the claim that the learned value head supplies sufficiently accurate estimates of final network quality to replace simulator rollouts inside the MCTS tree. No diagnostics of value prediction quality—such as correlation between predicted value and realized service rate on held-out partial networks, calibration plots, or error statistics—are reported anywhere in the manuscript.
Authors: We agree that explicit diagnostics would strengthen the evidence for the value head's utility. In the revised manuscript we will add a dedicated subsection reporting (i) Pearson/Spearman correlation between value predictions and realized service rates on held-out partial networks, (ii) calibration plots, and (iii) mean absolute error and other error statistics. These will be computed from the publicly released code and data. revision: yes
-
Referee: [Abstract] Abstract: The reported percentage gains are presented without error bars, confidence intervals, or statistical significance tests across multiple random seeds or demand realizations. This makes it impossible to assess whether the observed improvements over the two baselines are robust or could be explained by hyperparameter choices or benchmark-specific tuning.
Authors: We acknowledge the limitation. The revised version will rerun all methods (AlphaTransit, RL, and plain MCTS) across at least five random seeds, reporting mean service rates with standard deviations. We will also include paired statistical significance tests (e.g., Wilcoxon) between AlphaTransit and each baseline. Updated tables and abstract will reflect these results. revision: yes
Circularity Check
No significant circularity; results are empirical comparisons on held-out data
full rationale
The paper reports service-rate gains (54.6%/82.1% on Bloomington under two demand settings) from direct simulation-based evaluation of AlphaTransit against RL-without-search and MCTS-without-guidance baselines. These metrics are measured externally on held-out demand instances and do not reduce, via any equation or self-citation in the provided text, to quantities defined by the fitted network parameters or by construction. The value-network substitution for rollouts is an unverified modeling assumption (more relevant to correctness than circularity), but the derivation chain itself remains self-contained and non-tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and hyperparameters
axioms (1)
- domain assumption A neural network trained on past route-construction trajectories can generalize to predict final service rate for unseen partial networks.
Reference graph
Works this paper leans on
-
[1]
Khalid Alkilane and Der-Horng Lee. MetroZero: Deep reinforcement learning and Monte Carlo tree search for optimized metro network expansion.IEEE Transactions on Intelligent Transportation Systems, 26(1):810–823, 2025
2025
-
[2]
Saeid Amiri, Parisa Zehtabi, Danial Dervovic, and Michael Cashmore. Surrogate assisted monte carlo tree search in combinatorial optimization.arXiv preprint arXiv:2403.09925, 2024
-
[3]
Public transportation ridership update
American Public Transportation Association. Public transportation ridership update. Policy brief, APTA, 2025
2025
-
[4]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combina- torial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Data-driven transit network design at scale
Dimitris Bertsimas, Yee Sian Ng, and Julia Yan. Data-driven transit network design at scale. Operations Research, 69(4):1118–1133, 2021
2021
-
[6]
Gtfs schedule dataset.https://bloomingtontransit.com/gtfs/
Bloomington Transit. Gtfs schedule dataset.https://bloomingtontransit.com/gtfs/
-
[7]
How Attentive are Graph Attention Networks?
Shaked Brody, Uri Alon, and Eran Yahav. How attentive are graph attention networks?arXiv preprint arXiv:2105.14491, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012
2012
-
[9]
Ralph Buehler, John Pucher, and Oliver Dümmler. Verkehrsverbund: The evolution and spread of fully integrated regional public transport in germany, austria, and switzerland.International Journal of Sustainable Transportation, 13(1):36–50, 2019
2019
-
[10]
and Texas Transportation Institute
Cambridge Systematics, Inc. and Texas Transportation Institute. Traffic congestion and reliabil- ity: Trends and advanced strategies for congestion mitigation. Final Report FHW A-HOP-05-064, Federal Highway Administration, Washington, DC, September 2005
2005
-
[11]
CRC press, 2016
Avishai Ceder.Public transit planning and operation: Modeling, practice and behavior. CRC press, 2016
2016
-
[12]
A bag of tricks for deep reinforcement learning, 2023
Jeremiah Coholich. A bag of tricks for deep reinforcement learning, 2023
2023
-
[13]
Efficient selectivity and backup operators in monte-carlo tree search
Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. In International conference on computers and games, pages 72–83. Springer, 2006
2006
-
[14]
Planning spatial networks with Monte Carlo tree search.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 479(2269):20220383, 2023
Victor-Alexandru Darvariu, Stephen Hailes, and Mirco Musolesi. Planning spatial networks with Monte Carlo tree search.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 479(2269):20220383, 2023
2023
-
[15]
Optimising public bus transit networks using deep reinforcement learning
Ahmed Darwish, Momen Khalil, and Karim Badawi. Optimising public bus transit networks using deep reinforcement learning. In2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), pages 1–7. IEEE, 2020
2020
-
[16]
A survey on the transit network design and frequency setting problem.Public transport, 14(1):155–190, 2022
Javier Durán-Micco and Pieter Vansteenwegen. A survey on the transit network design and frequency setting problem.Public transport, 14(1):155–190, 2022
2022
-
[17]
The University of Texas at Austin, 2004
Wei Fan.Optimal transit route network design problem: Algorithms, implementations, and numerical results. The University of Texas at Austin, 2004
2004
-
[18]
Optimal transit route network design problem with variable transit demand: genetic algorithm approach.Journal of transportation engineering, 132(1):40– 51, 2006
Wei Fan and Randy B Machemehl. Optimal transit route network design problem with variable transit demand: genetic algorithm approach.Journal of transportation engineering, 132(1):40– 51, 2006
2006
-
[19]
Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al
Alhussein Fawzi, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Francisco J R. Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al. Discovering faster matrix multiplication algorithms with reinforcement learning.Nature, 610(7930):47–53, 2022. 11
2022
-
[20]
Setting frequencies on bus routes: Theory and practice
Peter G Furth and Nigel HM Wilson. Setting frequencies on bus routes: Theory and practice. Transportation Research Record, 818(1981):1–7, 1981
1981
-
[21]
An adaptive scaled network for public transport route optimisation.Public Transport, 11(2):379–412, 2019
Philipp Heyken Soares, Christine L Mumford, Kwabena Amponsah, and Yong Mao. An adaptive scaled network for public transport route optimisation.Public Transport, 11(2):379–412, 2019
2019
-
[22]
Augmenting transit network design algorithms with deep learning
Andrew Holliday and Gregory Dudek. Augmenting transit network design algorithms with deep learning. In2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), pages 2343–2350. IEEE, 2023
2023
-
[23]
A neural-evolutionary algorithm for autonomous transit network design
Andrew Holliday and Gregory Dudek. A neural-evolutionary algorithm for autonomous transit network design. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4457–4464. IEEE, 2024
2024
-
[24]
Learning heuristics for transit network design and improvement with deep reinforcement learning.Transportmetrica B: Transport Dynamics, 13(1):2561863, 2025
Andrew Holliday, Ahmed El-Geneidy, and Gregory Dudek. Learning heuristics for transit network design and improvement with deep reinforcement learning.Transportmetrica B: Transport Dynamics, 13(1):2561863, 2025
2025
-
[25]
The 37 implementation details of proximal policy optimization.The ICLR Blog Track 2023, 2022
Shengyi Huang, Rousslan Fernand Julien Dossa, Antonin Raffin, Anssi Kanervisto, and Weixun Wang. The 37 implementation details of proximal policy optimization.The ICLR Blog Track 2023, 2022
2023
-
[26]
Shengyi Huang and Santiago Ontañón. A closer look at invalid action masking in policy gradient algorithms.arXiv preprint arXiv:2006.14171, 2020
-
[27]
Marco Kemmerling, Daniel Lütticke, and Robert H Schmitt. Beyond games: a systematic review of neural monte carlo tree search applications.arXiv preprint arXiv:2303.08060, 2023
-
[28]
Transit route network design problem
Konstantinos Kepaptsoglou and Matthew Karlaftis. Transit route network design problem. Journal of transportation engineering, 135(8):491–505, 2009
2009
-
[29]
Attention, learn to solve routing problems! In International Conference on Learning Representations, 2019
Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! In International Conference on Learning Representations, 2019
2019
-
[30]
Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in neural information processing systems, 33:21188–21198, 2020
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in neural information processing systems, 33:21188–21198, 2020
2020
-
[31]
The traveling salesman problem: a guided tour of combinatorial optimization
Eugene L Lawler. The traveling salesman problem: a guided tour of combinatorial optimization. Wiley-Interscience Series in Discrete Mathematics, 1985
1985
-
[32]
A transit network design and frequency setting model with graph neural network and deep reinforcement learning
Junjun Li, Hao Dong, Xuedong Zhao, Hao Tang, Aimin Yin, and Ruchen Xue. A transit network design and frequency setting model with graph neural network and deep reinforcement learning. InSixth International Conference on Computer Information Science and Application Technology (CISAT 2023), volume 12800, page 128005Y . SPIE, 2023
2023
-
[33]
Microscopic traffic simulation using SUMO
Pablo Alvarez Lopez, Michael Behrisch, Laura Bieker-Walz, Jakob Erdmann, Yun-Pang Flöt- teröd, Robert Hilbrich, Leonhard Lücken, Johannes Rummel, Peter Wagner, and Evamarie Wießner. Microscopic traffic simulation using SUMO. In2018 21st International Conference on Intelligent Transportation Systems (ITSC), pages 2575–2582. IEEE, November 2018
2018
-
[34]
Evaluation and optimization of urban public transportation networks
Christoph E Mandl. Evaluation and optimization of urban public transportation networks. European Journal of Operational Research, 5(6):396–404, 1980
1980
-
[35]
Faster sorting algorithms discovered using deep reinforcement learning.Nature, 618(7964):257–263, 2023
Daniel J Mankowitz, Andrea Michi, Anton Zhernov, Marco Gelmi, Marco Selvi, Cosmin Paduraru, Edouard Leurent, Shariq Iqbal, Jean-Baptiste Lespiau, Alex Ahern, et al. Faster sorting algorithms discovered using deep reinforcement learning.Nature, 618(7964):257–263, 2023
2023
-
[36]
Designing a large-scale public transport network using agent-based microsimulation.Transportation Research Part A: Policy and Practice, 137:1–15, 2020
Patrick Manser, Henrik Becker, Sebastian Hörl, and Kay W Axhausen. Designing a large-scale public transport network using agent-based microsimulation.Transportation Research Part A: Policy and Practice, 137:1–15, 2020. 12
2020
-
[37]
Summary of travel trends: 2017 national household travel survey
Nancy McGuckin, Anthony Fucci, et al. Summary of travel trends: 2017 national household travel survey. Technical report, United States. Department of Transportation. Federal Highway Administration, 2018
2017
-
[38]
New heuristic and evolutionary operators for the multi-objective urban transit routing problem
Christine L Mumford. New heuristic and evolutionary operators for the multi-objective urban transit routing problem. In2013 IEEE congress on evolutionary computation, pages 939–946. IEEE, 2013
2013
-
[39]
Transit network design by genetic algorithm with elitism.Transportation Research Part C: Emerging Technologies, 46:30–45, 2014
Muhammad Ali Nayeem, Md Khaledur Rahman, and M Sohel Rahman. Transit network design by genetic algorithm with elitism.Transportation Research Part C: Emerging Technologies, 46:30–45, 2014
2014
-
[40]
A simplified car-following theory: a lower order model.Transportation Research Part B: Methodological, 36(3):195–205, 2002
Gordon Frank Newell. A simplified car-following theory: a lower order model.Transportation Research Part B: Methodological, 36(3):195–205, 2002
2002
-
[41]
Transit network design by bee colony optimization
Miloš Nikoli´c and Dušan Teodorovi´c. Transit network design by bee colony optimization. Expert Systems with Applications, 40(15):5945–5955, 2013
2013
-
[42]
A simulation-based optimization approach for designing transit networks.Public Transport, 15(2):377–409, 2023
Obiora A Nnene, Johan W Joubert, and Mark HP Zuidgeest. A simulation-based optimization approach for designing transit networks.Public Transport, 15(2):377–409, 2023
2023
-
[43]
Transit network design problem: a half century of methodological research
Mahmoud Owais. Transit network design problem: a half century of methodological research. Innovative Infrastructure Solutions, 11(1):3, 2026
2026
-
[44]
Roess, E.S
R.P. Roess, E.S. Prassas, and W.R. McShane.Traffic Engineering. Pearson, 2011
2011
-
[45]
Multi-armed bandits with episode context.Annals of Mathematics and Artificial Intelligence, 61(3):203–230, 2011
Christopher D Rosin. Multi-armed bandits with episode context.Annals of Mathematics and Artificial Intelligence, 61(3):203–230, 2011
2011
-
[46]
Planning and optimizing transit lines.arXiv preprint arXiv:2405.10074, 2024
Marie Schmidt and Anita Schöbel. Planning and optimizing transit lines.arXiv preprint arXiv:2405.10074, 2024
-
[47]
Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[48]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Uxsim: lightweight mesoscopic traffic flow simulator in pure python.Journal of Open Source Software, 10(106):7617, 2025
Toru Seo. Uxsim: lightweight mesoscopic traffic flow simulator in pure python.Journal of Open Source Software, 10(106):7617, 2025
2025
-
[51]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the...
2016
-
[52]
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play.Science, 362(6419):1140–1144, 2018
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play.Science, 362(6419):1140–1144, 2018
2018
-
[53]
Mastering the game of Go without human knowledge.Nature, 550:354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of Go without human knowledge.Nature, 550:354–359, 2017
2017
-
[54]
MIT press, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, 2018. 13
2018
-
[55]
SIAM, 2014
Paolo Toth and Daniele Vigo.Vehicle routing: problems, methods, and applications. SIAM, 2014
2014
-
[56]
Who’s on board 2019: How to win back america’s transit riders
TransitCenter. Who’s on board 2019: How to win back america’s transit riders. Technical report, TransitCenter, New York, 2019
2019
-
[57]
Bloomington transit (bt) — operator details
Transitland. Bloomington transit (bt) — operator details. https://www.transit.land/ operators/o-dnfq-bloomingtontransit
-
[58]
World urbanization prospects: The 2018 revision
United Nations Department of Economic and Social Affairs. World urbanization prospects: The 2018 revision. Technical report, United Nations, 2019
2018
-
[59]
Census Bureau
U.S. Census Bureau. Tiger/line shapefiles. https://www.census.gov/cgi-bin/geo/ shapefiles/index.php, 2025. Accessed: 2025-10-06
2025
-
[60]
Census Bureau, Center for Economic Studies
U.S. Census Bureau, Center for Economic Studies. Lehd origin-destination employment statistics (lodes).https://lehd.ces.census.gov/data, 2025. Accessed: 2025-10-06
2025
-
[61]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[62]
An exact solution approach for the bus line planning problem with integrated passenger routing.Journal of Advanced Transportation, 2021(1):6684795, 2021
Evert Vermeir, Wouter Engelen, Johan Philips, and Pieter Vansteenwegen. An exact solution approach for the bus line planning problem with integrated passenger routing.Journal of Advanced Transportation, 2021(1):6684795, 2021
2021
-
[63]
Pointer networks.Advances in neural information processing systems, 28, 2015
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks.Advances in neural information processing systems, 28, 2015
2015
-
[64]
John Wiley & Sons, 2007
Vukan R Vuchic.Urban transit systems and technology. John Wiley & Sons, 2007
2007
-
[65]
John Wiley & Sons, 2017
Vukan R Vuchic.Urban transit: operations, planning, and economics. John Wiley & Sons, 2017
2017
-
[66]
Pareto-optimal transit route planning with multi-objective monte-carlo tree search.IEEE Transactions on Intelligent Transportation Systems, 22(2):1185–1195, 2021
Di Weng, Ran Chen, Jianhui Zhang, Jie Bao, Yu Zheng, and Yingcai Wu. Pareto-optimal transit route planning with multi-objective monte-carlo tree search.IEEE Transactions on Intelligent Transportation Systems, 22(2):1185–1195, 2021
2021
-
[67]
Promoting livable cities by investing in urban mobility
World Bank. Promoting livable cities by investing in urban mobility. Results brief, World Bank Group, 2024
2024
-
[68]
Representation learning on graphs with jumping knowledge networks
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In International Conference on Machine Learning (ICML), 2018
2018
-
[69]
Graph pointer neural networks
Tianmeng Yang, Yujing Wang, Zhihan Yue, Yaming Yang, Yunhai Tong, and Jing Bai. Graph pointer neural networks. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 8832–8839, 2022
2022
-
[70]
A reinforcement learning approach for bus network design and frequency setting optimisation.Public Transport, 15(2):503–534, 2023
Sunhyung Yoo, Jinwoo Brian Lee, and Hoon Han. A reinforcement learning approach for bus network design and frequency setting optimisation.Public Transport, 15(2):503–534, 2023
2023
-
[71]
Simulated annealing–genetic algorithm for transit network optimization.Journal of Computing in Civil Engineering, 20(1):57–68, 2006
Fang Zhao and Xiaogang Zeng. Simulated annealing–genetic algorithm for transit network optimization.Journal of Computing in Civil Engineering, 20(1):57–68, 2006. 14 A Size of the search space The scope of the design problem is to choose K= 16 routes, each visiting 14 distinct nodes, on the Bloomington network graph G= (V, E) . Computing the exact size of ...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.