OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
Pith reviewed 2026-06-29 12:58 UTC · model grok-4.3
The pith
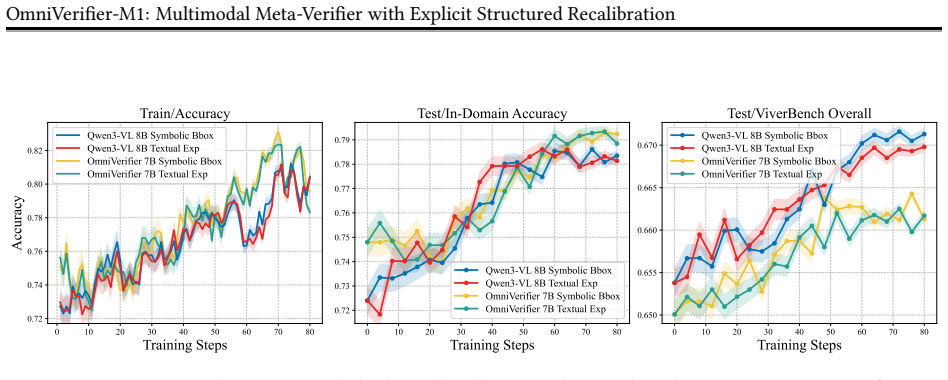
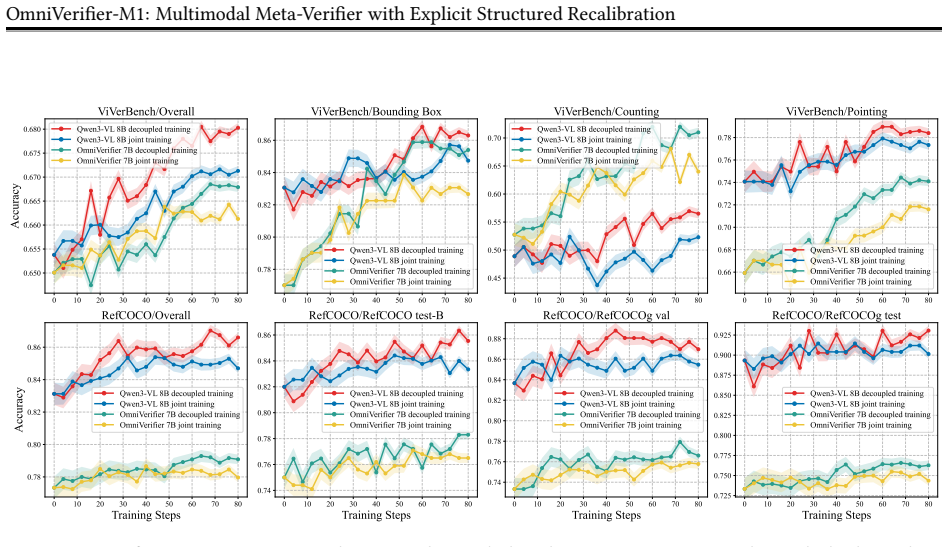
Symbolic outputs like bounding boxes outperform text as meta-verification rationales, and decoupling reinforcement learning objectives for judgment and rationale training improves results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Symbolic verifier outputs outperform textual explanations as meta-verification rationales, enabling efficient rule-based reinforcement learning rewards, while decoupling reinforcement learning objectives for binary judgment and meta-verification substantially outperforms joint reward optimization due to differences in output structure and learning dynamics.
What carries the argument
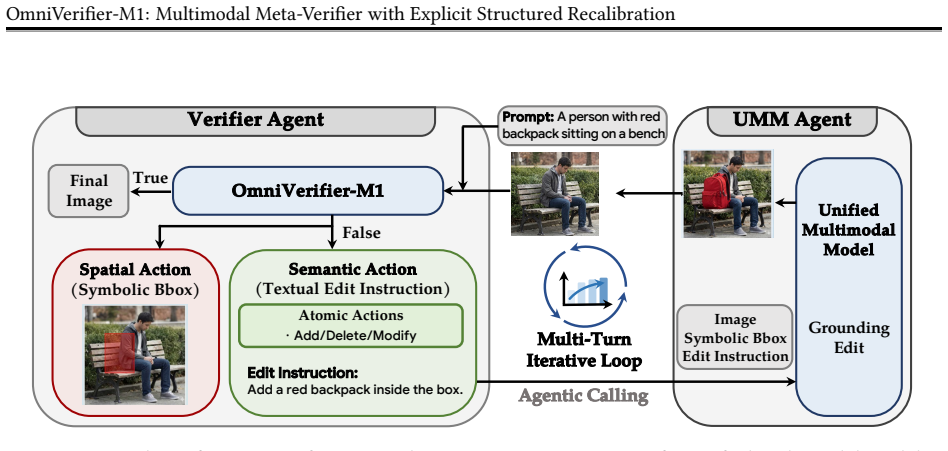
Symbolic meta-verification rationales (such as bounding boxes) combined with separate reinforcement learning objectives for binary judgment versus rationale generation.
If this is right
- Rule-based rewards replace the need for auxiliary judge models during training.
- Fine-grained error localization becomes available as a direct output of the verifier.
- A verifier-driven system can perform dynamic region-level self-correction during generation.
- Verification becomes more interpretable and controllable for foundation model use.
Where Pith is reading between the lines
- The same separation of judgment and explanation objectives could help reinforcement learning in other settings where the two outputs differ in format.
- If symbolic equivalents exist in text or audio, the approach might transfer to non-visual modalities.
- Wider testing across model scales would show whether the performance gap remains stable.
Load-bearing premise
The advantages of symbolic rationales and decoupled objectives will hold for other multimodal models and tasks beyond the training setup used here.
What would settle it
A controlled comparison on a diverse set of multimodal verification benchmarks in which textual rationales match or exceed symbolic ones, or joint optimization matches or exceeds the decoupled approach.
Figures


read the original abstract
Visual outcomes are increasingly central to multimodal large language models, making reliable and fine-grained verification essential for scaling generalist foundation models. In this work, we investigate multimodal meta-verification, which leverages verifier-generated rationales rather than decision-only signals, and explore how to effectively incorporate meta-verification feedback into multimodal verifier training. We identify two key findings. First, symbolic verifier outputs (e.g., bounding boxes) outperform textual explanations as meta-verification rationales, enabling efficient rule-based reinforcement learning rewards while avoiding reliance on model-based rewards from auxiliary judge models. Second, decoupling reinforcement learning objectives for binary judgment and meta-verification substantially outperforms joint reward optimization, due to intrinsic differences in output structure and learning dynamics. Based on these insights, we train OmniVerifier-M1, a generalist visual verifier leveraging symbolic meta-verification and decoupled reinforcement learning. OmniVerifier-M1 provides robust verification and fine-grained error localization, and further enables M1-TTS, a verifier-driven agentic generation system achieving dynamic region-level self-correction. This approach paves the way for more reliable, interpretable, and fine-grained multimodal verification, supporting safer and more controllable foundation model deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify two key findings in multimodal meta-verification: symbolic verifier outputs such as bounding boxes outperform textual explanations as rationales for meta-verification, enabling rule-based RL rewards without auxiliary judge models; and decoupling RL objectives for binary judgment and meta-verification outperforms joint reward optimization due to differences in output structure and learning dynamics. Based on these, they introduce OmniVerifier-M1, a generalist visual verifier, and M1-TTS, a verifier-driven agentic generation system for dynamic region-level self-correction.
Significance. If the empirical findings hold after controlling for potential confounds in reward mechanisms, this work could contribute to more reliable and interpretable verification in multimodal foundation models. The emphasis on symbolic rationales for efficient rule-based rewards is a promising direction for avoiding model-based reward dependencies. However, the lack of detailed experimental results, error bars, or ablation controls in the provided abstract limits assessment of broader impact.
major comments (2)
- [Abstract] The claim that symbolic outputs outperform textual explanations is tied to enabling rule-based rewards. However, the ablation comparing symbolic and textual rationales may confound the rationale format with the reward type (rule-based vs model-based), as the abstract explicitly links the advantage to avoiding model-based rewards from auxiliary judges. This needs explicit isolation in the experimental design to attribute the gain to output structure.
- [Abstract] The second finding on decoupling RL objectives outperforming joint optimization lacks supporting details on matched optimization setups (e.g., policy heads, reward scaling, gradient interference). Without these, it is unclear if the outperformance stems from intrinsic differences or implementation choices.
minor comments (1)
- The abstract mentions 'M1-TTS' but does not define the acronym or provide details on how it achieves self-correction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our abstract. The comments highlight important aspects of experimental design and clarity that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] The claim that symbolic outputs outperform textual explanations is tied to enabling rule-based rewards. However, the ablation comparing symbolic and textual rationales may confound the rationale format with the reward type (rule-based vs model-based), as the abstract explicitly links the advantage to avoiding model-based rewards from auxiliary judges. This needs explicit isolation in the experimental design to attribute the gain to output structure.
Authors: We agree that the abstract phrasing links the performance advantage directly to the reward mechanism, which could be read as a potential confound. The manuscript's core claim is that symbolic outputs (e.g., bounding boxes) uniquely enable reliable rule-based rewards, whereas textual explanations generally require auxiliary model-based judges. To isolate the contribution of output structure itself, we will add a controlled ablation in the revised manuscript that applies model-based rewards to both symbolic and textual rationales under matched conditions. This will allow clearer attribution of gains to rationale format versus reward type. revision: yes
-
Referee: [Abstract] The second finding on decoupling RL objectives outperforming joint optimization lacks supporting details on matched optimization setups (e.g., policy heads, reward scaling, gradient interference). Without these, it is unclear if the outperformance stems from intrinsic differences or implementation choices.
Authors: We acknowledge that the abstract does not include these implementation details. The full manuscript describes the separate policy heads and reward formulations for binary judgment versus meta-verification, but we will expand the methods and experimental sections in revision to explicitly document matched setups, including reward scaling factors, gradient flow analysis, and controls for interference. These additions will strengthen the evidence that the observed gains arise from differences in output structure and learning dynamics rather than implementation artifacts. revision: yes
Circularity Check
No circularity: empirical findings from ablations, not derivations
full rationale
The paper reports two empirical findings from comparative experiments (symbolic vs. textual rationales; decoupled vs. joint RL objectives) and then trains OmniVerifier-M1 on the basis of those observations. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The claims rest on falsifiable performance differences rather than any step that reduces by construction to its own inputs. This is the standard case of an empirical methods paper whose central results are independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025a. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Judgelrm: Large reasoning models as a judge.arXiv preprint arXiv:2504.00050, 2025a
Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, and Bingsheng He. Judgelrm: Large reasoning models as a judge.arXiv preprint arXiv:2504.00050,
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yufeng Cui, Honghao Chen, Haoge Deng, Xu Huang, Xinghang Li, Jirong Liu, Yang Liu, Zhuoyan Luo, Jinsheng Wang, Wenxuan Wang, et al. Emu3. 5: Native multimodal models are world learners.arXiv preprint arXiv:2510.26583,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Jiawei Gu, Yunzhuo Hao, Huichen Will Wang, Linjie Li, Michael Qizhe Shieh, Yejin Choi, Ranjay Krishna, and Yu Cheng. Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning. arXiv preprint arXiv:2510.27492,
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025a. Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Interleaving reasoning for better text-to-image generation
Wenxuan Huang, Shuang Chen, Zheyong Xie, Shaosheng Cao, Shixiang Tang, Yufan Shen, Qingyu Yin, Wenbo Hu, Xiaoman Wang, Yuntian Tang, et al. Interleaving reasoning for better text-to-image generation. arXiv preprint arXiv:2509.06945, 2025a. Yuzhen Huang, Weihao Zeng, Xingshan Zeng, Qi Zhu, and Junxian He. From accuracy to robustness: A study of rule- and m...
-
[9]
OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration Dongzhi Jiang, Renrui Zhang, Haodong Li, Zhuofan Zong, Ziyu Guo, Jun He, Claire Guo, Junyan Ye, Rongyao Fang, Weijia Li, et al. Draco: Draft as cot for text-to-image preview and rare concept generation. arXiv preprint arXiv:2512.05112,
-
[10]
Ouxiang Li, Yuan Wang, Xinting Hu, Huijuan Huang, Rui Chen, Jiarong Ou, Xin Tao, Pengfei Wan, Xiaojuan Qi, and Fuli Feng. Easier painting than thinking: Can text-to-image models set the stage, but not direct the play?arXiv preprint arXiv:2509.03516,
-
[11]
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
Chao Liao, Liyang Liu, Xun Wang, Zhengxiong Luo, Xinyu Zhang, Wenliang Zhao, Jie Wu, Liang Li, Zhi Tian, and Weilin Huang. Mogao: An omni foundation model for interleaved multi-modal generation. arXiv preprint arXiv:2505.05472,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Inference-time scaling for generalist reward modeling.arXiv preprint arXiv:2504.02495,
Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, and Yu Wu. Inference-time scaling for generalist reward modeling.arXiv preprint arXiv:2504.02495,
-
[13]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation. arXiv preprint arXiv:2503.07265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision,
Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, and Hao Li. Uni-cot: Towards unified chain-of-thought reasoning across text and vision.arXiv preprint arXiv:2508.05606,
-
[15]
Tianyuan Qu, Lei Ke, Xiaohang Zhan, Longxiang Tang, Yuqi Liu, Bohao Peng, Bei Yu, Dong Yu, and Jiaya Jia. Replan: Reasoning-guided region planning for complex instruction-based image editing.arXiv preprint arXiv:2512.16864,
-
[16]
Bytedance Seed. Seed1. 8 model card: Towards generalized real-world agency.arXiv preprint arXiv:2603.20633,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570,
Zhihong Shao, Yuxiang Luo, Chengda Lu, ZZ Ren, Jiewen Hu, Tian Ye, Zhibin Gou, Shirong Ma, and Xiaokang Zhang. Deepseekmath-v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570,
-
[19]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025a. Zhaokai Wang, Penghao Yin, Xiangyu Zhao, Changyao Tian, Yu Qiao, Wenhai Wang, Jifeng Dai, and Gen Luo. Genexam: A multidisciplinary text-to-image exam.arXiv preprint arXiv:2509.14232, 2025b. Z...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration Chenxi Whitehouse, Tianlu Wang, Ping Yu, Xian Li, Jason Weston, Ilia Kulikov, and Swarnadeep Saha. J1: Incentivizing thinking in llm-as-a-judge via reinforcement learning.arXiv preprint arXiv:2505.10320,
-
[21]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, et al. Rewarddance: Reward scaling in visual generation.arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation.arXiv preprint arXiv:2412.21059,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Cheng Yang, Chufan Shi, Yaxin Liu, Bo Shui, Junjie Wang, Mohan Jing, Linran Xu, Xinyu Zhu, Siheng Li, Yuxiang Zhang, et al. Chartmimic: Evaluating lmm’s cross-modal rea...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction.arXiv preprint arXiv:2408.15240, 2024a. Xinchen Zhang, Ling Yang, Yaqi Cai, Zhaochen Yu, Kai-Ni Wang, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui, et al. Realcompo: Balancing realism and compo...
-
[26]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deep- eyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631,
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631,
-
[28]
As shown in Table 5, rule-based symbolic point rewards also serve as an effective alternative to model-based textual explanations for meta-verification under the joint training setting. B.2 Evaluation of the Verifier’s Localization Accuracy To directly evaluate the verifier’s ability to localize errors, we carefully construct a test set of 400 False sampl...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.