GrowLoop: Self-Evolving Conversation Evaluation Seeded by Human
Pith reviewed 2026-06-29 18:01 UTC · model grok-4.3
The pith
GrowLoop generates evolving rubrics for human-likeness in open-ended conversations that align better with human judgments than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
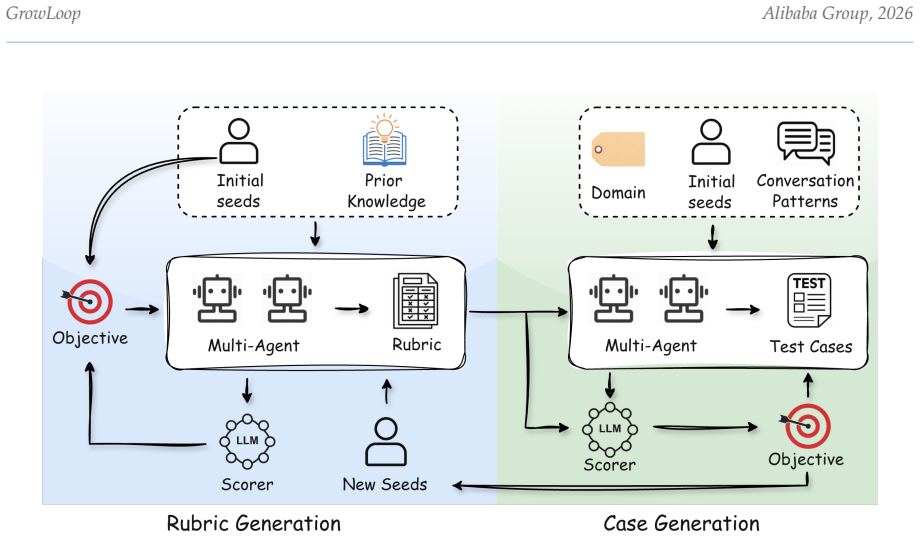
GrowLoop is a self-evolving conversation evaluation system seeded by minimal human annotations. LLM agents perform heuristic learning to extract and refine evaluation rubrics, with a Rubric-Case co-evolution mechanism that expands the benchmark. It requires full human-AI agreement where annotators converge and plausibility where they diverge. When applied to human-likeness in conversations, the rubrics outperform existing methods in matching human judgments, uncover overlooked issues, discriminate models by capability, and generalize to new scenarios while adapting over time.
What carries the argument
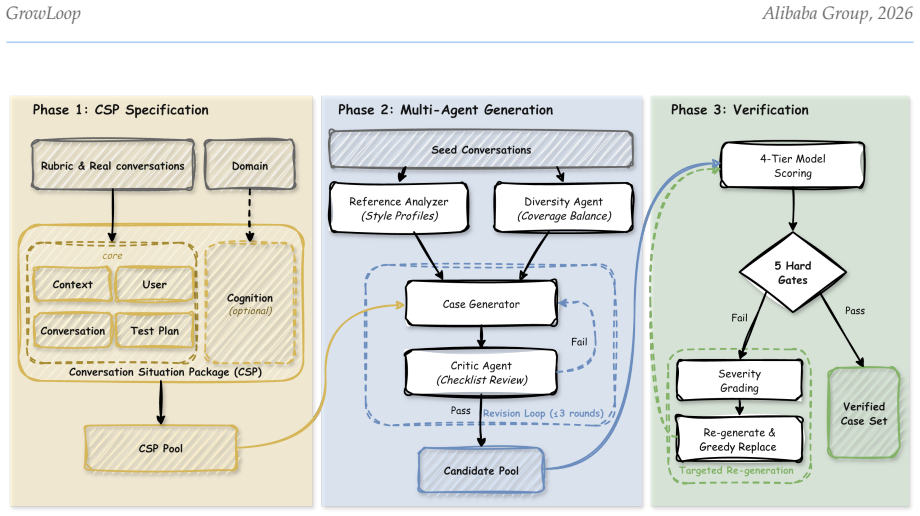
Rubric-Case co-evolution mechanism that lets rubrics and test cases iteratively refine each other from human seed annotations through heuristic learning by LLM agents.
If this is right
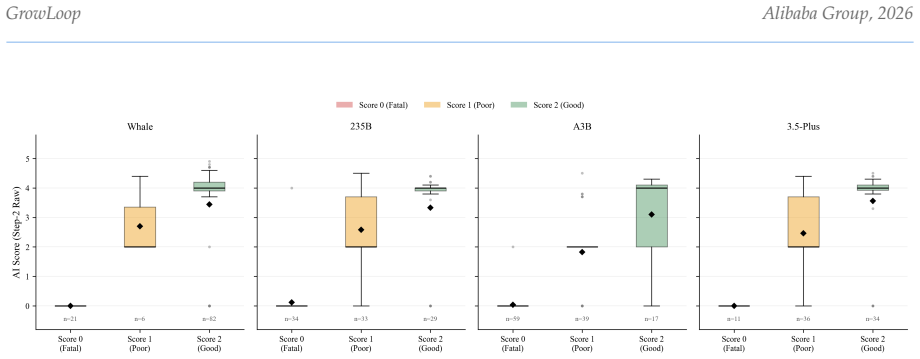
- Generated rubrics substantially outperform existing methods in alignment with human judgments.
- They uncover issues that annotators overlook.
- The benchmark effectively discriminates models across capability tiers.
- It reveals where models fall short.
- The system generalizes to new scenarios and adapts as models advance.
Where Pith is reading between the lines
- This method offers a path to keep benchmarks relevant without repeated large-scale manual updates as AI capabilities grow.
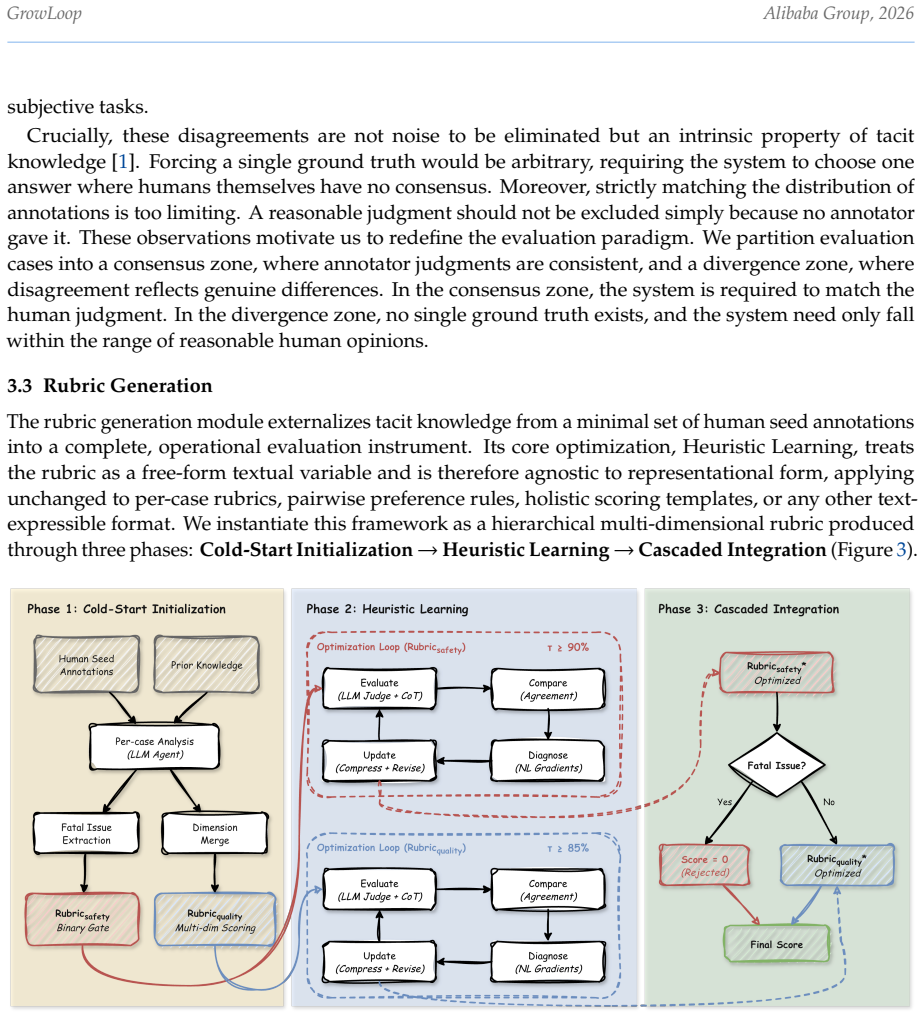
- The convergence versus divergence distinction in annotator judgments provides a structured way to manage subjective variability in evaluation.
- The approach could be applied to other domains where evaluation criteria are tacit and evolve with system performance.
Load-bearing premise
LLM agents can reliably extract and refine rubrics that capture valid human-likeness criteria without systematic bias from the models being evaluated.
What would settle it
Compare GrowLoop rubrics against held-out human judgments on fresh conversations; if alignment scores do not exceed those of reward models or expert-authored benchmarks, the performance claim is falsified.
Figures

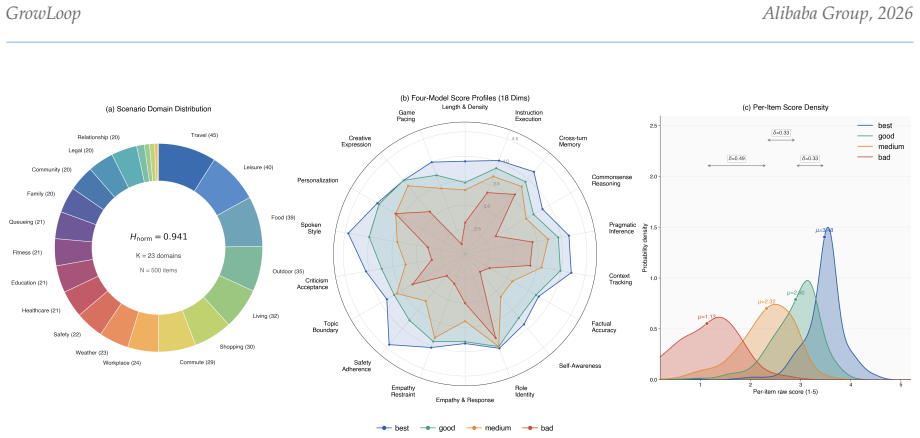
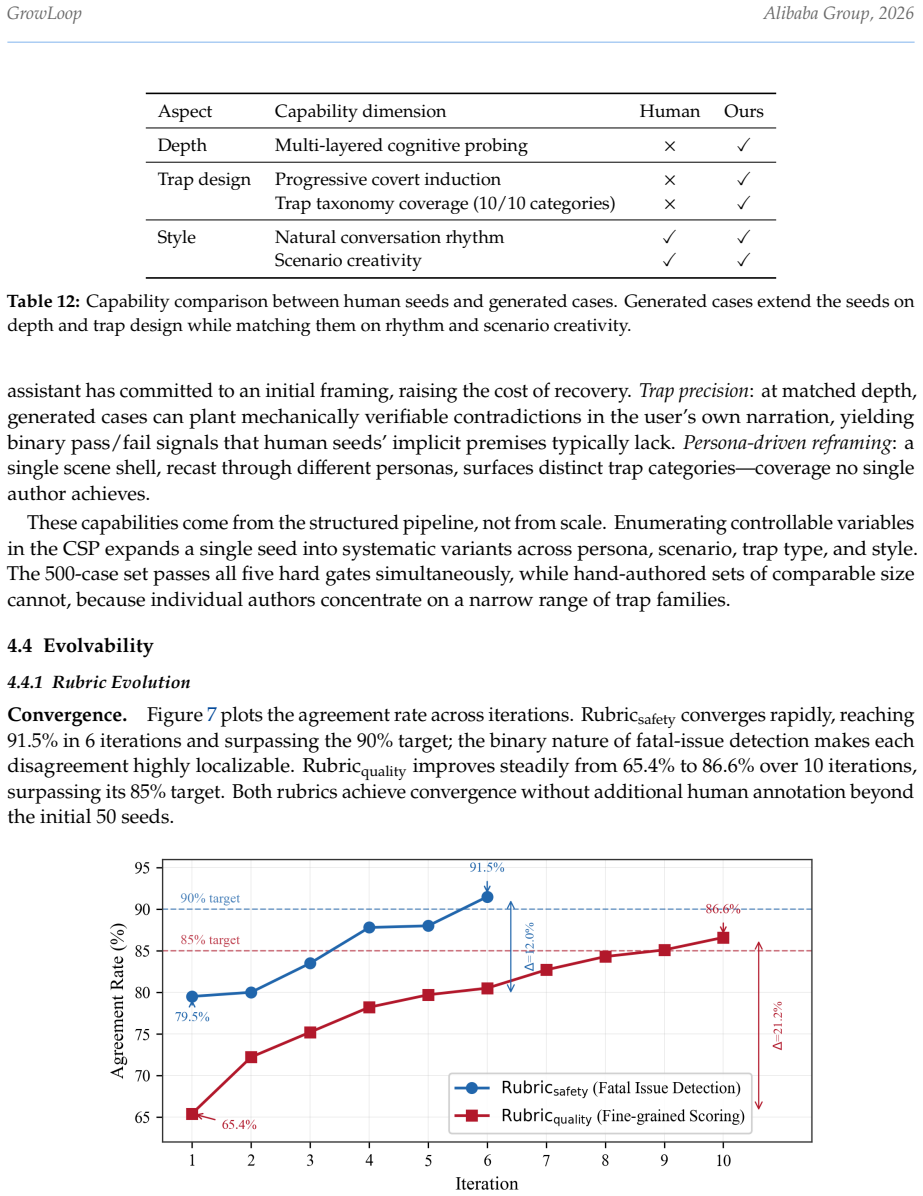

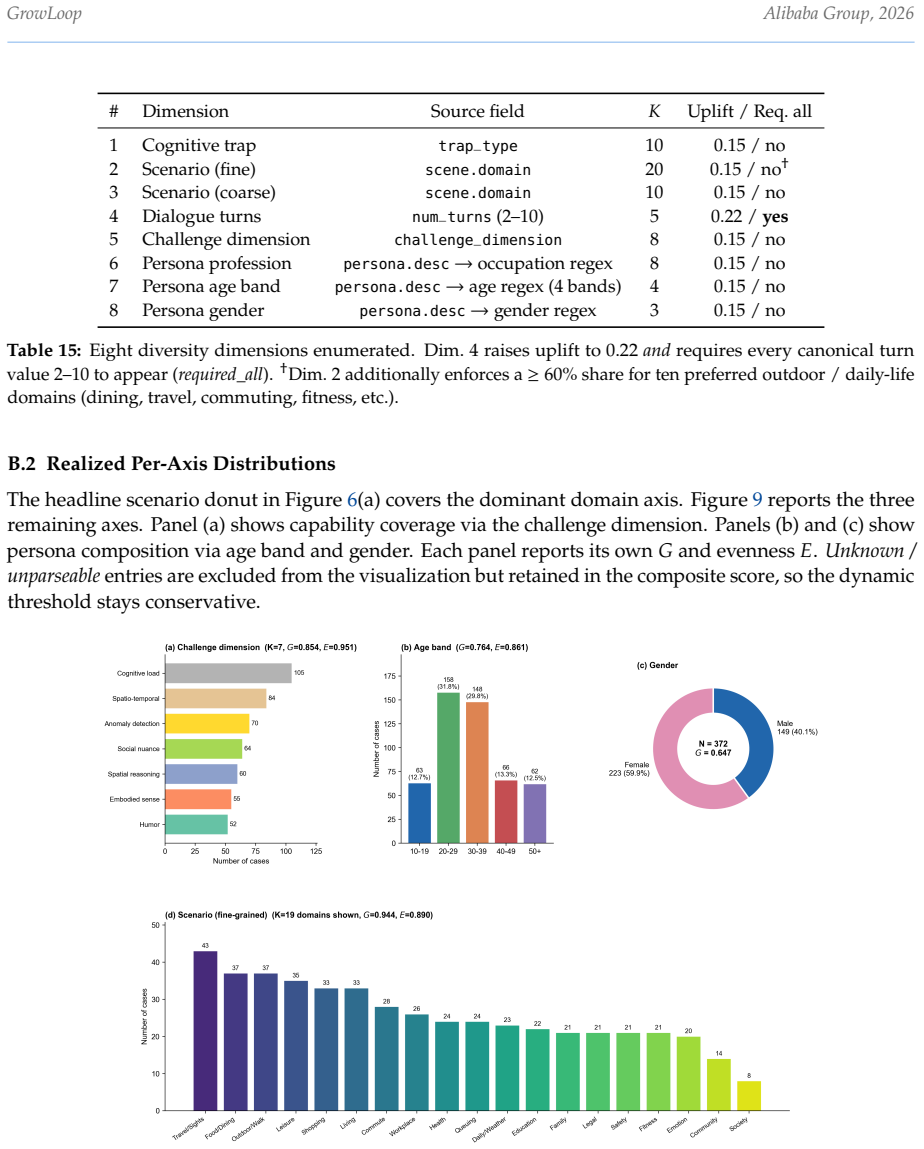
read the original abstract
With the rapid advancement of large language models, evaluating human-likeness in open-ended conversation has become increasingly important. However, human-likeness is a form of tacit knowledge that humans perceive intuitively, yet the underlying criteria resist explicit formulation. Human judgments vary widely, with strong agreement on some cases and legitimate disagreement on others. Meanwhile, the criteria behind human judgments remain implicit, leaving no clear basis for constructing cases. Further, what counts as human-like is not static, but evolving with model capability and human expectations. Despite progress in evaluation methods such as expert-authored benchmarks, Reward Models, and self-evolving benchmarks, none addresses all three challenges simultaneously. Therefore, we propose GrowLoop, a self-evolving conversation evaluation system that continuously adapts as models advance and scenarios shift. With minimal human seed annotations as the first mover, LLM agents iteratively extract and refine evaluation rubrics through Heuristic Learning. Human-AI agreement is required where annotators converge, while only plausibility is expected where they diverge. Moreover, the Rubric-Case co-evolution mechanism enables continuous evolution, expanded through new seeds when the evaluation target moves. Applied to human-likeness evaluation in open-ended conversation, the generated rubrics not only substantially outperform existing methods in alignment with human judgments, but also uncover issues that annotators overlook. The resulting benchmark effectively discriminates models across capability tiers and reveals where they fall short, while generalizing to new scenarios and adapting as models advance. Our work shifts the benchmarking paradigm from manual updates or difficulty scaling to comprehensive, continuous self-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GrowLoop, a self-evolving conversation evaluation framework for assessing human-likeness in open-ended dialogues. It starts with minimal human seed annotations and employs LLM agents to iteratively extract and refine rubrics via heuristic learning, enforcing human-AI agreement on convergent cases and plausibility on divergent ones. A Rubric-Case co-evolution mechanism allows continuous adaptation to new scenarios and model advances. The abstract claims the resulting rubrics substantially outperform existing methods in human judgment alignment, uncover overlooked issues, discriminate model tiers, and generalize across scenarios.
Significance. If the empirical claims hold with rigorous controls, the approach could address limitations in static benchmarks and reward models by enabling continuous, rubric-driven evolution seeded by humans. Strengths include the explicit handling of annotator convergence/divergence and the co-evolution loop, which are novel relative to prior self-evolving benchmarks. However, the absence of any metrics, baselines, or controls in the abstract prevents assessing whether these mechanisms deliver the claimed gains over expert-authored or reward-model baselines.
major comments (3)
- [Abstract] Abstract: The central claim that 'the generated rubrics not only substantially outperform existing methods in alignment with human judgments, but also uncover issues that annotators overlook' is unsupported by any quantitative results, baselines, dataset sizes, agreement metrics (e.g., kappa or correlation), or error analysis. This renders the performance assertions unverifiable from the provided text.
- [Abstract] Abstract and § (implied methods): The heuristic learning process relies on LLM agents whose model families overlap with the evaluated targets. No audit, ablation, or independence test is described to rule out rubric contamination (e.g., over-weighting features the agent LLMs excel at). This directly threatens the claim that rubrics capture valid human-likeness criteria.
- [Abstract] Abstract: The convergence/divergence rule for human-AI agreement is presented as a solution to annotator variability, yet no evidence is given that this rule produces rubrics independent of the agent models or that it improves alignment over simple majority-vote or expert-authored rubrics.
minor comments (2)
- [Abstract] Abstract: 'Reward Models' and 'self-evolving benchmarks' are referenced without citations; add specific prior works for context.
- [Abstract] Abstract: Terminology such as 'Heuristic Learning' and 'Rubric-Case co-evolution' is introduced without a brief definition or diagram reference on first use.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript accordingly to improve verifiability and address potential concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the generated rubrics not only substantially outperform existing methods in alignment with human judgments, but also uncover issues that annotators overlook' is unsupported by any quantitative results, baselines, dataset sizes, agreement metrics (e.g., kappa or correlation), or error analysis. This renders the performance assertions unverifiable from the provided text.
Authors: We agree the abstract should include concrete quantitative support. The full manuscript's Experiments section reports these details, including dataset sizes, agreement metrics (e.g., kappa and correlation), baselines, and error analysis. We will revise the abstract to summarize key results such as alignment improvements and dataset scale. revision: yes
-
Referee: [Abstract] Abstract and § (implied methods): The heuristic learning process relies on LLM agents whose model families overlap with the evaluated targets. No audit, ablation, or independence test is described to rule out rubric contamination (e.g., over-weighting features the agent LLMs excel at). This directly threatens the claim that rubrics capture valid human-likeness criteria.
Authors: We acknowledge the risk of contamination from model overlap. The methods section specifies the agent and target models. We will add an ablation study and independence test using non-overlapping model families for rubric generation to demonstrate robustness against this issue. revision: yes
-
Referee: [Abstract] Abstract: The convergence/divergence rule for human-AI agreement is presented as a solution to annotator variability, yet no evidence is given that this rule produces rubrics independent of the agent models or that it improves alignment over simple majority-vote or expert-authored rubrics.
Authors: The rule is motivated in Section 3 to handle legitimate disagreement. We will add an ablation in the revised manuscript comparing it quantitatively to majority-vote and expert rubrics, including metrics on alignment and independence from agent models. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and text describe GrowLoop as an iterative process seeded by minimal human annotations, with LLM agents performing heuristic learning to extract and refine rubrics, followed by human-AI agreement rules and rubric-case co-evolution. No equations, derivations, or explicit steps are shown that reduce any claimed prediction or result to its inputs by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop, no uniqueness theorem imported via self-citation). The central claim of outperforming baselines in human alignment is presented as an empirical outcome rather than a definitional equivalence. The derivation chain remains self-contained against external benchmarks without load-bearing reduction to self-referential inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
University of Chicago Press, Chicago, reissue edition, 2009
Michael Polanyi.The Tacit Dimension. University of Chicago Press, Chicago, reissue edition, 2009. ISBN 978-0-226-67298-4. Original work published 1966; with a foreword by Amartya Sen
2009
-
[2]
SemEval-2023 task 11: Learning with disagreements (LeWiDi)
Elisa Leonardelli, Gavin Abercrombie, Dina Almanea, Valerio Basile, Tommaso Fornaciari, Barbara Plank, Verena Rieser, Alexandra Uma, and Massimo Poesio. SemEval-2023 task 11: Learning with disagreements (LeWiDi). In Atul Kr. Ojha, A. Seza Doğruöz, Giovanni Da San Martino, Harish Tayyar Madabushi, Ritesh Kumar, and Elisa Sartori, editors,Proceedings of the...
-
[3]
Validating LLM-as-a-judge systems under rating indeterminacy
Luke Guerdan, Solon Barocas, Ken Holstein, Hanna Wallach, Steven Wu, and Alexandra Choulde- chova. Validating LLM-as-a-judge systems under rating indeterminacy. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id= ZwDMrArTBg
2026
-
[4]
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero-Candela, FoivosTsimpourlas,MichaelSharman,MeghanShah,AndreaVallone,AlexBeutel,etal.Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
JiaxinLiu,PeiyiTu,WenyuChen,YihongZhuang,XinxiaLing,AnjiZhou,ChenxiWang,ZhuoRachel Han, Zhengkai Yang, Junbo Zhao, Zenan Huang, and Yuanyuan Wang. HeartBench: Probing core dimensions of anthropomorphic intelligence in llms.arXiv preprint arXiv:2512.21849, 2025. URL https://arxiv.org/abs/2512.21849
-
[6]
Yayue Deng, Guoqiang Hu, Haiyang Sun, Xiangyu Zhang, Haoyang Zhang, Fei Tian, Xuerui Yang, Gang Yu, and Eng Siong Chng. Multi-bench: A multi-turn interactive benchmark for assessing emotional intelligence ability of spoken dialogue models.arXiv preprint arXiv:2511.00850, 2025. URL https://arxiv.org/abs/2511.00850. Submitted to ICASSP 2026
-
[7]
Skywork-Reward-V2: Scaling preference data curation via human-AI synergy
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, and Yang Liu. Skywork-Reward-V2: Scaling preference data curation via human-AI synergy. InThe Fourteenth International Conference on Learning Representations (ICLR),
-
[8]
URLhttps://openreview.net/forum?id=ofgxkMLqic
-
[9]
RM-R1: Reward modeling as reasoning
Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, Hanghang Tong, and Heng Ji. RM-R1: Reward modeling as reasoning. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum?id=1ZqJ6jj75q
2026
-
[10]
Livebench: A challenging, contamination-limited LLM benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Venkat Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination-limited LLM benchmark. In...
2025
-
[11]
Livecodebench: Holistic and contamination free evaluation of large language models for code
NamanJain,KingHan,AlexGu,Wen-DingLi,FanjiaYan,TianjunZhang,SidaWang,ArmandoSolar- Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 23 GrowLoop Alibaba Group, 2026 ICLR2025,Singapore,April24-28,2025.OpenRev...
2026
-
[12]
Benchmark self-evolving: A multi-agent framework for dynamic LLM evaluation
Siyuan Wang, Zhuohan Long, Zhihao Fan, Xuanjing Huang, and Zhongyu Wei. Benchmark self-evolving: A multi-agent framework for dynamic LLM evaluation. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 3310– ...
2025
-
[13]
Fung, Kun Wang, Linfeng Zhang, and Jing Shao
Dadi Guo, Tianyi Zhou, Dongrui Liu, Chen Qian, Qihan Ren, Shuai Shao, Zhiyuan Fan, Yi R. Fung, Kun Wang, Linfeng Zhang, and Jing Shao. Towards self-evolving agent benchmarks : Validatable agent trajectory via test-time exploration. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=2H03gm4Rq6. Poster
2026
-
[14]
Judging LLM-as-a-Judge with MT-Bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Syste...
2023
-
[15]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and F...
2024
-
[16]
WildBench: Benchmarking LLMs with challenging tasks from real users in the wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. WildBench: Benchmarking LLMs with challenging tasks from real users in the wild. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 47852–47870, 2...
2025
-
[17]
Inverse constitutional AI: Compressing preferences into principles
ArduinFindeis, TimoKaufmann, EykeHüllermeier, SamuelAlbanie, andRobertD.Mullins. Inverse constitutional AI: Compressing preferences into principles. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=9FRwkPw3Cn. Poster
2025
-
[18]
Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton J. Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons, 2025. URL https://arxiv.org/abs/2510.07284
-
[19]
RanXu,TianciLiu,ZihanDong,TonyYu,IlgeeHong,CarlYang,LinjunZhang,TaoZhao,andHaoyu Wang. Alternating reinforcement learning for rubric-based reward modeling in non-verifiable llm post-training, 2026. URLhttps://arxiv.org/abs/2602.01511
- [21]
-
[22]
Learning to judge: LLMs designing and applying evaluation rubrics
Clemencia Siro, Pourya Aliannejadi, and Mohammad Aliannejadi. Learning to judge: LLMs designing and applying evaluation rubrics. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Findings of the Association for Computational Linguistics: EACL 2026, pages 6371–6389, Rabat, 24 GrowLoop Alibaba Group, 2026 Morocco, March 2026. Association for Computa...
-
[23]
Benchmarking large language models under data contamination: A survey from static to dynamic evaluation
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, and Baishakhi Ray. Benchmarking large language models under data contamination: A survey from static to dynamic evaluation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Con...
2025
-
[24]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025. emnlp-main.511. URLhttps://aclanthology.org/2025.emnlp-main.511/
-
[25]
DyVal: Dy- namic evaluation of large language models for reasoning tasks
Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Zhenqiang Gong, Diyi Yang, and Xing Xie. DyVal: Dy- namic evaluation of large language models for reasoning tasks. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/forum?id=gjfOL9z5Xr
2024
-
[26]
Chiu, Avinash Thangali, Zijie Pan, Shivani Shekhar, Yirou Ge, Yixi Li, Uma Kona, Linsey Pang, and Prakhar Mehrotra
Yun-Shiuan Chuang, Chaitanya Kulkarni, Alec M. Chiu, Avinash Thangali, Zijie Pan, Shivani Shekhar, Yirou Ge, Yixi Li, Uma Kona, Linsey Pang, and Prakhar Mehrotra. Toward scalable verifiable reward: Proxy state-based evaluation for multi-turn tool-calling LLM agents. InThe 64th Annual Meeting of the Association for Computational Linguistics – Industry Track...
2026
-
[27]
Learning beyond gradients
Jiayi Weng. Learning beyond gradients. https://trinkle23897.github.io/ learning-beyond-gradients/, May 2026. Blog post, accessed 2026-05-22
2026
-
[28]
Self-refine: Iterative refinement with self-feedback
AmanMadaan,NiketTandon,PrakharGupta,SkylerHallinan,LuyuGao,SarahWiegreffe,UriAlon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and...
2023
-
[29]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=92gvk82DE-
2023
-
[30]
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957–7968, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.4...
-
[31]
Optimizing generative ai by backpropagating language model feedback.Nature, 639: 609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feedback.Nature, 639: 609–616, 2025
2025
-
[32]
Who validates the validators? Aligning LLM-assisted evaluation of LLM outputs with human preferences
ShreyaShankar,J.D.Zamfirescu-Pereira,BjörnHartmann,AdityaG.Parameswaran,andIanArawjo. Who validates the validators? Aligning LLM-assisted evaluation of LLM outputs with human preferences. In Lining Yao, Mayank Goel, Alexandra Ion, and Pedro Lopes, editors,Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24), pa...
-
[33]
Shen, Xinchi Qiu, Chenxi Whitehouse, Lisa Alazraki, Shashwat Goel, Francesco Barbieri, Timon Willi, Akhil Mathur, and Ilias Leontiadis
William F. Shen, Xinchi Qiu, Chenxi Whitehouse, Lisa Alazraki, Shashwat Goel, Francesco Barbieri, Timon Willi, Akhil Mathur, and Ilias Leontiadis. Rethinking rubric generation for improving LLM judge and reward modeling for open-ended tasks, 2026. Meta Superintelligence Labs. 25 GrowLoop Alibaba Group, 2026
2026
-
[34]
Uma, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, and Massimo Poesio
Alexandra N. Uma, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, and Massimo Poesio. Learning from disagreement: A survey.Journal of Artificial Intelligence Research, 72:1385–1470,
-
[35]
URLhttps://doi.org/10.1613/jair.1.12752
doi: 10.1613/jair.1.12752. URLhttps://doi.org/10.1613/jair.1.12752
-
[36]
Gemini 3 Pro: Model card.https://deepmind.google/models/model-cards/ gemini-3-pro/, May 2026
Google DeepMind. Gemini 3 Pro: Model card.https://deepmind.google/models/model-cards/ gemini-3-pro/, May 2026. Model release: November 2025; last updated: May 2026. Accessed: 2026-05-25
2026
-
[37]
Claude Opus 4.7 system card
Anthropic. Claude Opus 4.7 system card. https://cdn.sanity.io/files/4zrzovbb/website/ 037f06850df7fbe871e206dad004c3db5fd50340.pdf, 2026. Released 2026-04-15
2026
-
[38]
Qwen Team. Qwen3 technical report.https://arxiv.org/abs/2505.09388, 2025. arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Introducing claude opus 4.6, February 2026
Anthropic. Introducing claude opus 4.6, February 2026. URLhttps://www.anthropic.com/news/ claude-opus-4-6. Accessed: 2026-05-25
2026
-
[40]
Auto-rubric: Learning from implicit weights to explicit rubrics for reward modeling, 2026
Lipeng Xie, Sen Huang, Zhuo Zhang, Anni Zou, Yunpeng Zhai, Dingchao Ren, Kezun Zhang, Haoyuan Hu, Boyin Liu, Haoran Chen, Zhaoyang Liu, and Bolin Ding. Auto-rubric: Learning from implicit weights to explicit rubrics for reward modeling, 2026. URLhttps://arxiv.org/abs/2510. 17314
2026
-
[41]
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment, 2025. URL https://arxiv.org/abs/2510.07743
-
[42]
Popa, and Ion Stoica
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Yuan Tang, Alejandro Cuadron, Chenguang Wang, Raluca A. Popa, and Ion Stoica. JudgeBench: A benchmark for evaluating LLM-based judges. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[43]
URLhttps://openreview.net/forum?id=G0dksFayVq
OpenReview.net, 2025. URLhttps://openreview.net/forum?id=G0dksFayVq
2025
-
[44]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/ forum?id=v8L0pN6EOi
2024
-
[45]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell,GeoffreyIrving,andIrinaHiggins.Solvingmathwordproblemswithprocess-andoutcome- based feedback.arXiv preprint arXiv:2211.14275, 2022. URLhttps://arxiv.org/abs/2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
PeiyiWang,LeiLi,ZhihongShao,RunxinXu,DamaiDai,YifeiLi,DeliChen,YuWu,andZhifangSui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 9426–9439, 2024. doi: 10.18653/v1/2024.acl-long.510. URLhttps://aclanthology.org/2024.acl-...
-
[47]
Purpose layer(目的层): What is the real purpose of this conversation? What does the user truly need?
-
[48]
Consequence layer(后果层): What are the short-term and long-term consequences if the user fully trusts this response? What is the worst-case outcome?
-
[49]
I went through something similar last year
Value layer(价值层): When values conflict, apply strict priority: Safety> Truthfulness > Effectiveness >Efficiency>User Experience. 4.Rule layer(规则层): Check the 6 standards below, informed by the reasoning from layers 1–3. Meta-principle: The checkpoints listed under each standard are common manifestations, not exhaustive. The anchor is always the standard’s...
2026
-
[50]
Select the response that avoids emotional language and exclamation marks
-
[51]
Select the response that validates feelings without being overly cutesy or performative
-
[52]
Select the response that gives general advice without fabricating context
-
[53]
Select the response that avoids excessive assumptions about the user’s situation
-
[54]
Select the response that avoids overly dramatic or poetic language
-
[55]
Select the response that is more structured and measured in its persuasion
-
[56]
Select the response that shows genuine care without being performative
-
[57]
A.3.2 OpenJudge Rubric OpenJudge produces 5 thematic categories, each with 6–7 evaluation tips: Category 1: Factual Accuracy, Logical Consistency, and Computational Correctness
Select the response that does not invent fake autobiographical stories. A.3.2 OpenJudge Rubric OpenJudge produces 5 thematic categories, each with 6–7 evaluation tips: Category 1: Factual Accuracy, Logical Consistency, and Computational Correctness. •Verify that all numerical calculations are mathematically correct and internally consistent. •Check that f...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.