SCDBench: A Benchmark for LLM-Based Smart Contract Decompilers
Pith reviewed 2026-06-29 10:24 UTC · model grok-4.3
The pith
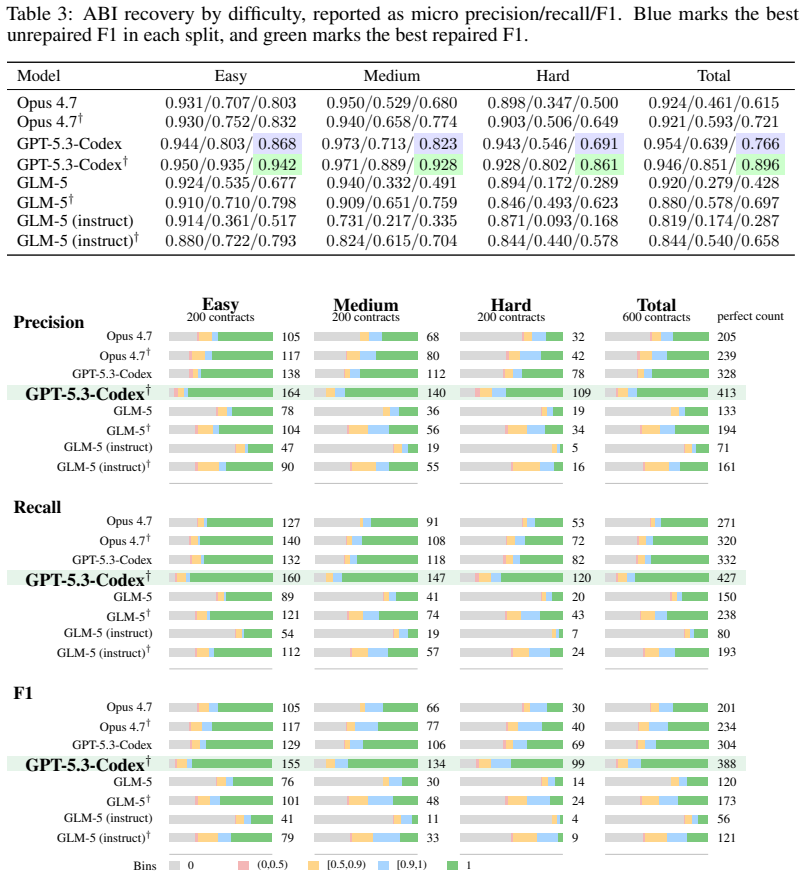
Frontier LLMs produce compilable smart contract code yet match original semantics in only 42 of 600 cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCDBench supplies 600 contracts with bytecode inputs, ground-truth source, and replayable checkpoints. Decompiler outputs are scored cumulatively on format completeness, compilability, ABI recovery, and semantic consistency via differential replay. In zero-shot settings the strongest frontier model reaches perfect semantic consistency on only 42 contracts, while inserting a compilation-repair stage improves that count without large extra cost.
What carries the argument
The four cumulative evaluation stages that terminate in differential replay of semantic checkpoints to test behavioral equivalence between original and decompiled contracts.
If this is right
- Semantic consistency, not merely compilability, must serve as the decisive quality metric for smart-contract decompilers.
- A compilation-repair step can be inserted after initial generation to raise the fraction of semantically faithful outputs.
- Reproducible multi-stage benchmarks enable direct comparison of future decompilation methods on the same contracts.
- Applications that depend on recovered source for security analysis require higher semantic fidelity than current models deliver.
Where Pith is reading between the lines
- The staged benchmark could be reused to measure whether larger models or different training regimes close the remaining semantic gap.
- Low semantic-consistency rates suggest that decompiled code cannot yet substitute for source in high-stakes contract audits without additional verification.
- The same cumulative-check approach may transfer to other domains where generated code must preserve original observable behavior.
Load-bearing premise
The 600 contracts and their checkpoints represent the broader population of deployed smart contracts sufficiently well for performance numbers to generalize.
What would settle it
A decompiler that passes the semantic-consistency stage on substantially more than 42 of the 600 contracts under the identical four-stage protocol.
Figures

read the original abstract
Smart contract decompilation aims to recover high-level source code from bytecode, but evaluating decompilers remains difficult because existing studies use narrow datasets, inconsistent metrics, and limited semantic consistency checks. This gap is increasingly important as large language models (LLMs) begin to generate source-like Solidity that may compile and appear plausible, even when its semantics diverge from the original contract. We introduce SCDBench, a dataset and benchmark methodology for LLM-based smart contract decompilation. The dataset contains 600 real-world Solidity contracts with paired bytecode inputs, ground-truth source code, and replayable semantic checkpoints. SCDBench evaluates decompiler outputs through four cumulative stages: format completeness, compilability, Application Binary Interface (ABI) recovery, and semantic consistency via differential replay. We evaluate Claude Opus 4.7, GPT-5.3-Codex, and GLM-5 in a zero-shot decompilation setting, including GLM-5 variants with and without extended reasoning and a zero-shot compilation-repair setting. The results show that frontier LLMs can often produce structured and compilable Solidity, but achieving semantic consistency remains far from solved: the best-performing frontier model perfectly decompiles only 42/600 contracts. We further show that introducing same-model compilation repair substantially improves performance at modest additional cost. SCDBench establishes a common ground for rigorous, reproducible evaluation and aims to accelerate the development of reliable smart contract decompilers for blockchain security and transparency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCDBench, a benchmark dataset of 600 real-world Solidity contracts with paired bytecode, ground-truth source, and replayable semantic checkpoints. It proposes a four-stage cumulative evaluation (format completeness, compilability, ABI recovery, semantic consistency via differential replay) and reports zero-shot results for frontier LLMs (Claude Opus 4.7, GPT-5.3-Codex, GLM-5 variants) plus a compilation-repair setting, concluding that while structured and compilable output is often achieved, perfect semantic decompilation occurs for only 42/600 contracts in the best case.
Significance. SCDBench supplies a structured, multi-stage protocol with replayable checkpoints that supports reproducible assessment of semantic fidelity, a clear strength for the field. The demonstration that same-model compilation repair yields gains at modest cost is a practical contribution. The central generalization that semantic consistency remains far from solved, however, rests on the unverified representativeness of the 600-contract set.
major comments (1)
- [Dataset Construction] Dataset Construction section: explicit selection criteria, diversity statistics (contract complexity, opcode patterns, state-machine structure), and coverage arguments for the replayable semantic checkpoints are not provided. This is load-bearing for the headline claim, because the 42/600 figure and the generalization that semantic consistency is unsolved can be interpreted only if the contracts reflect the distribution of deployed Solidity usage.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of dataset transparency. We address the major comment below and will revise the manuscript to strengthen the presentation of the dataset.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset Construction section: explicit selection criteria, diversity statistics (contract complexity, opcode patterns, state-machine structure), and coverage arguments for the replayable semantic checkpoints are not provided. This is load-bearing for the headline claim, because the 42/600 figure and the generalization that semantic consistency is unsolved can be interpreted only if the contracts reflect the distribution of deployed Solidity usage.
Authors: We agree that additional detail on dataset construction is warranted to support the generalizability claims. In the revised manuscript we will expand the Dataset Construction section with: (1) explicit selection criteria (sourcing from verified Etherscan contracts meeting minimum transaction and verification thresholds, with exclusion rules for trivial or duplicate contracts); (2) diversity statistics including histograms or tables for contract complexity (LOC, function count), opcode pattern distributions, and state-machine characteristics (e.g., number of state variables and external calls); and (3) coverage arguments showing how the 600 contracts and their replayable checkpoints sample common deployed patterns (ERC standards, DeFi primitives, access-control logic). These additions will directly address the load-bearing concern for interpreting the 42/600 semantic-consistency result. revision: yes
Circularity Check
No circularity: benchmark results are direct empirical measurements on a newly introduced dataset with no fitted predictions or self-referential derivations.
full rationale
The paper presents SCDBench as an independent evaluation artifact consisting of 600 real-world contracts and a four-stage methodology (format completeness, compilability, ABI recovery, semantic consistency via differential replay). The headline result (42/600 perfect decompilations for the best model) is obtained by applying this methodology to frontier LLMs in a zero-shot setting. No equations, parameters fitted to subsets then re-predicted, or load-bearing self-citations appear in the provided text. The dataset construction and representativeness assumptions are stated explicitly as scope limitations rather than derived claims. The derivation chain is therefore self-contained as a measurement exercise and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Decompiling smart contracts with a large language model.arXiv preprint arXiv:2506.19624,
Isaac David, Liyi Zhou, Dawn Song, Arthur Gervais, and Kaihua Qin. Decompiling smart contracts with a large language model.arXiv preprint arXiv:2506.19624,
-
[2]
An empirical study of smart contract decompilers
Xia Liu, Baojian Hua, Yang Wang, and Zhizhong Pan. An empirical study of smart contract decompilers. In 2023 IEEE international conference on Software Analysis, Evolution and Reengineering (SANER), pages 1–12. IEEE,
2023
-
[3]
Ethereum: A secure decentralised generalised transaction ledger.Ethereum project yellow paper, 151(2014):1–32,
Gavin Wood et al. Ethereum: A secure decentralised generalised transaction ledger.Ethereum project yellow paper, 151(2014):1–32,
2014
-
[4]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: From vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.