Robust and Efficient Guardrails with Latent Reasoning
Pith reviewed 2026-06-29 12:04 UTC · model grok-4.3
The pith
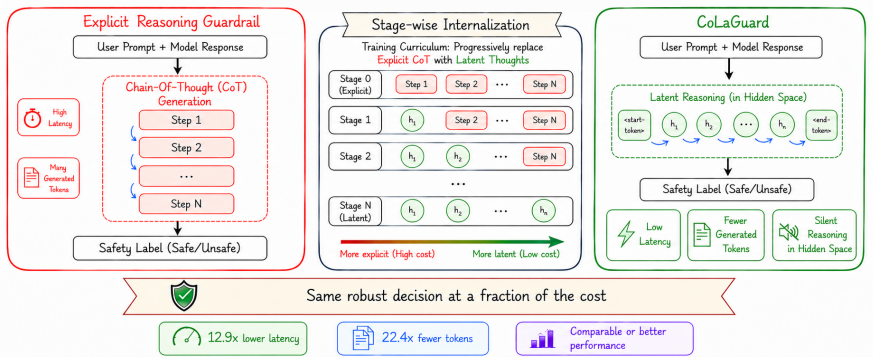
COLAGUARD compresses multi-step safety reasoning into latent space to match explicit reasoning performance with 12.9X speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
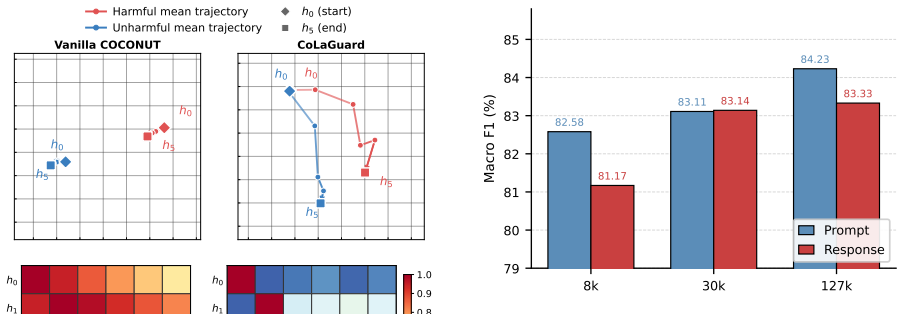
COLAGUARD transfers multi-step safety reasoning into a continuous latent space through a stage-wise training curriculum, enabling direct hidden-state propagation at inference. Evaluated on ten prompt- and response-moderation settings spanning eight safety benchmarks, COLAGUARD improves macro-F1 by 8.24 points over Llama Guard 3 and matches our explicit reasoning baseline, GuardReasoner, in macro-F1 while delivering a 12.9X speedup and 22.4X reduction in token usage.
What carries the argument
Stage-wise training curriculum that compresses multi-step safety reasoning into continuous latent representations for direct hidden-state propagation at inference.
If this is right
- Safety guardrails can achieve high robustness without generating explicit rationales at inference time.
- Inference latency and token cost no longer need to trade off against detection quality in high-throughput settings.
- Direct hidden-state propagation becomes a viable mechanism for practical safety moderation.
- Stage-wise curricula can be used to embed other multi-step decision processes in latent space.
Where Pith is reading between the lines
- The same curriculum approach could be tested on non-safety tasks that currently rely on explicit chain-of-thought for accuracy.
- Lower token usage at inference may reduce energy and monetary cost for large-scale moderation pipelines.
- If latent states reliably carry reasoning, future guardrail models might be trained on smaller explicit-reasoning datasets while retaining performance.
Load-bearing premise
The stage-wise training curriculum successfully compresses multi-step safety reasoning into the continuous latent space such that direct hidden-state propagation at inference preserves the detection performance of explicit reasoning.
What would settle it
A test showing that COLAGUARD's macro-F1 falls substantially below GuardReasoner's on any of the eight safety benchmarks when explicit reasoning is removed would falsify the claim that latent propagation preserves performance.
Figures
read the original abstract
Maintaining the safety of large language models (LLMs) is crucial as they are increasingly deployed in real-world applications. Existing safety guardrails typically rely on single-pass classification or, more recently, distilled reasoning. Reasoning-based guardrails significantly outperform classification-only baselines, but they incur substantial query latency and token overhead that make them impractical for highthroughput deployment. To address this challenge, we propose COLAGUARD, a guardrail model that transfers multi-step safety reasoning into a continuous latent space through a stage-wise training curriculum, enabling direct hidden-state propagation at inference. Evaluated on ten prompt- and response-moderation settings spanning eight safety benchmarks, COLAGUARD improves macro-F1 by 8.24 points over Llama Guard 3 and matches our explicit reasoning baseline, GuardReasoner, in macroF1 while delivering a 12.9X speedup and 22.4X reduction in token usage. Our results suggest that latent reasoning offers a practical alternative to explicit rationale generation for deployable guardrails, jointly improving safety robustness and inference efficiency rather than treating them as competing objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes COLAGUARD, a safety guardrail that uses a stage-wise training curriculum to embed multi-step explicit safety reasoning into continuous latent representations. At inference, it performs direct hidden-state propagation rather than generating explicit rationales. On ten prompt- and response-moderation settings across eight benchmarks, it reports an 8.24-point macro-F1 gain over Llama Guard 3, parity with the explicit-reasoning baseline GuardReasoner, a 12.9X speedup, and a 22.4X reduction in token usage.
Significance. If the central claim holds, the work would demonstrate that latent-space compression of reasoning can simultaneously improve robustness and inference efficiency for guardrails, addressing a practical deployment bottleneck. The reported parity with explicit reasoning plus large efficiency gains would be a notable contribution if supported by ablations and mechanistic evidence.
major comments (3)
- [Abstract and §3] Abstract and §3 (method): the stage-wise curriculum is asserted to compress multi-step safety reasoning into hidden states such that direct propagation preserves GuardReasoner macro-F1, yet no description of the curriculum stages, alignment objectives, loss terms, or how explicit rationales are aligned to latent states is provided. This is load-bearing for the claim that the efficiency gains arise from latent reasoning rather than other factors.
- [§4] §4 (experiments): no dataset splits, statistical significance tests, or ablations isolating the latent-reasoning component (e.g., curriculum vs. standard classification training, or vs. auxiliary losses) are reported. Without these, the 8.24-point macro-F1 improvement and parity with GuardReasoner cannot be attributed to the proposed mechanism.
- [§4 and Table 2] §4 and Table 2: the claim of matching explicit reasoning performance while achieving 12.9X speedup rests on end-to-end F1 equivalence, but no mechanistic validation (e.g., probing whether hidden states encode the same reasoning steps) is supplied, leaving open the possibility that performance gains come from data or architecture rather than latent reasoning transfer.
minor comments (2)
- [Abstract] Abstract: the phrase 'matches our explicit reasoning baseline' should clarify whether GuardReasoner was trained on the same data distribution as COLAGUARD to rule out data-leakage confounds.
- [§2] Notation: the term 'latent reasoning' is used without a precise definition distinguishing it from standard hidden-state classification; a short formalization in §2 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify important areas where additional detail and validation are needed. We address each major comment below and commit to revisions that provide the requested methodological descriptions, experimental controls, and analyses.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the stage-wise curriculum is asserted to compress multi-step safety reasoning into hidden states such that direct propagation preserves GuardReasoner macro-F1, yet no description of the curriculum stages, alignment objectives, loss terms, or how explicit rationales are aligned to latent states is provided. This is load-bearing for the claim that the efficiency gains arise from latent reasoning rather than other factors.
Authors: We agree that the original manuscript provides only a high-level description of the stage-wise curriculum in §3. In revision we will expand this section with the full curriculum stages (initial supervised explicit-reasoning training followed by latent-alignment distillation), the alignment objectives and loss terms (including the specific regression or contrastive losses used to map rationale embeddings to hidden states), and the precise procedure for aligning explicit rationales to latent representations. These additions will make explicit how the efficiency gains derive from the latent transfer mechanism. revision: yes
-
Referee: [§4] §4 (experiments): no dataset splits, statistical significance tests, or ablations isolating the latent-reasoning component (e.g., curriculum vs. standard classification training, or vs. auxiliary losses) are reported. Without these, the 8.24-point macro-F1 improvement and parity with GuardReasoner cannot be attributed to the proposed mechanism.
Authors: We acknowledge the omission of these controls. The revised manuscript will report the exact train/validation/test splits for each benchmark, include statistical significance tests (bootstrap or paired tests) on the macro-F1 differences, and add ablations that isolate the curriculum (full stage-wise training versus standard classification fine-tuning and versus training without the auxiliary alignment losses). These results will allow direct attribution of the reported gains to the latent-reasoning component. revision: yes
-
Referee: [§4 and Table 2] §4 and Table 2: the claim of matching explicit reasoning performance while achieving 12.9X speedup rests on end-to-end F1 equivalence, but no mechanistic validation (e.g., probing whether hidden states encode the same reasoning steps) is supplied, leaving open the possibility that performance gains come from data or architecture rather than latent reasoning transfer.
Authors: The referee correctly observes that end-to-end equivalence alone leaves the mechanistic claim under-supported. While the parity with GuardReasoner and the large efficiency gains are consistent with successful latent transfer, we did not include probing experiments in the submitted version. We will add a probing subsection (linear probes on hidden states for reasoning-step detection) and report the results in the revision or appendix to provide direct evidence that the hidden states encode comparable safety reasoning steps. revision: yes
Circularity Check
No circularity in derivation or performance claims
full rationale
The paper describes an empirical training curriculum for embedding reasoning in latent states and reports direct benchmark evaluations (macro-F1, speedup) against external baselines (Llama Guard 3) and a separately described explicit-reasoning baseline. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that reduce the central claims to their own inputs appear in the abstract or described method. All reported quantities are externally measured outcomes, not internal redefinitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- stage-wise curriculum hyperparameters
axioms (1)
- domain assumption Multi-step safety reasoning can be equivalently represented in continuous hidden states without explicit text generation
Reference graph
Works this paper leans on
-
[1]
Implicit chain of thought reasoning via knowledge distillation
Implicit chain of thought reasoning via knowl- edge distillation.Preprint, arXiv:2311.01460. Shaona Ghosh, Prasoon Varshney, Erick Galinkin, and Christopher Parisien. 2024. Aegis: Online adaptive ai content safety moderation with ensemble of llm experts.Preprint, arXiv:2404.05993. Shaona Ghosh, Prasoon Varshney, Makesh Narsimhan Sreedhar, Aishwarya Padmak...
-
[2]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Training large language model to reason in a continuous latent space. Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. 2023. Dis- tilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Salad-bench: A hierarchical and comprehen- sive safety benchmark for large language models. Preprint, arXiv:2402.05044. Zi Lin, Zihan Wang, Yongqi Tong, Yangkun Wang, Yuxin Guo, Yujia Wang, and Jingbo Shang. 2023. Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation.Preprint, arXiv:2310.17389. Weihao Liu, Dehai M...
-
[4]
Guardreasoner: Towards reasoning-based llm safeguards.Preprint, arXiv:2501.18492. Llama Team. 2024. Meta Llama guard 2. https: //github.com/meta-llama/PurpleLlama/blob/ main/Llama-Guard2/MODEL_CARD.md. Ilya Loshchilov and Frank Hutter. 2019. De- coupled weight decay regularization.Preprint, arXiv:1711.05101. Todor Markov, Chong Zhang, Sandhini Agarwal, Ty...
-
[5]
Umap: Uniform manifold approximation and projection for dimension reduction.Preprint, arXiv:1802.03426. NVIDIA. 2025. Nemotron Content Safety Rea- soning 4B. https://huggingface.co/nvidia/ Nemotron-Content-Safety-Reasoning-4B. OpenAI. 2024. OpenAI o1 system card. https:// openai.com/index/openai-o1-system-card/. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almei...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
InThirty-seventh Conference on Neural Information Processing Sys- tems
Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Sys- tems. Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. 2023. Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails.Preprint, arXiv:2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.