Compute Allocation in Evolutionary Search: From Depth-Breadth to Multi-Armed Bandits
Pith reviewed 2026-06-29 08:08 UTC · model grok-4.3
The pith
Reallocating a fixed budget of LLM calls with a multi-armed bandit raises mean fitness in evolutionary search by 12.3 percent over fixed island baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
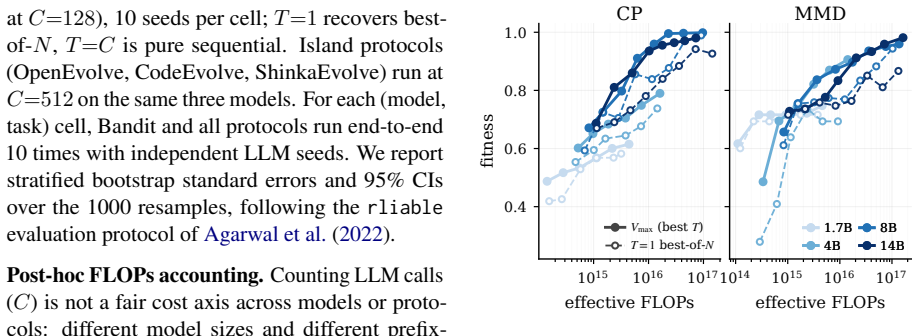
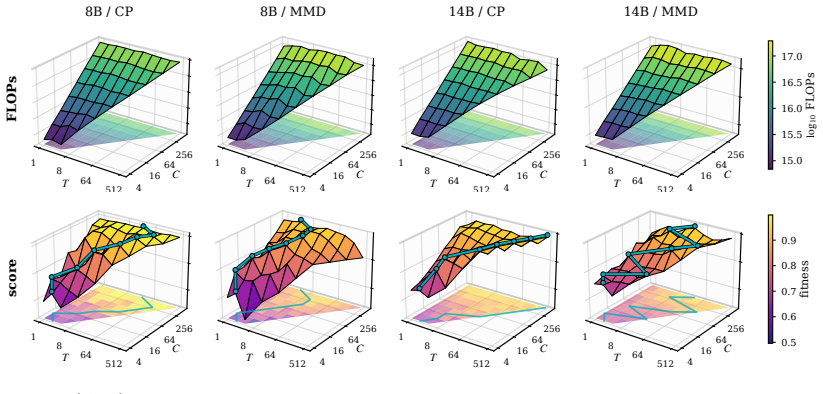
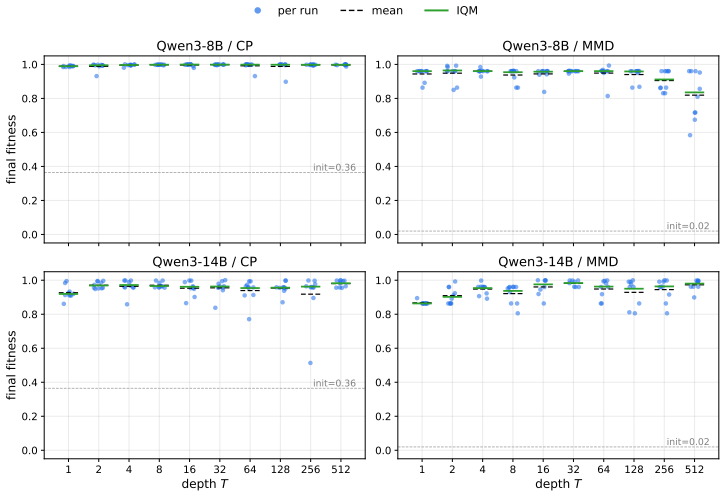
Sweeping the depth-breadth grid over five models and three tasks identifies a fitness-compute envelope along which model ordering largely collapses to effective FLOPs and a bilinear depth-breadth fit with task-specific interaction strength. Motivated by these patterns, BaSE treats parallel evolutionary trajectories as arms of a multi-armed bandit and reallocates each new LLM call to the arm with the highest estimated value. Without altering the underlying model, prompt, or evaluator, this allocation raises mean fitness 12.3 percent above the strongest island-protocol baseline across eight model-task cells, with the largest improvements occurring on high-variance settings.
What carries the argument
BaSE, a multi-armed bandit that treats parallel evolutionary trajectories as arms and reallocates each successive LLM call to the arm whose current value estimate is highest.
If this is right
- The same bandit policy yields larger gains on high-variance model-task combinations than on low-variance ones.
- A single run becomes more reliable because the allocation adapts to realized performance differences among trajectories.
- The allocation improvement requires no retuning of the evolutionary operator or the evaluator.
- The observed envelope and bilinear fit can be used to set initial depth-breadth ranges before bandit reallocation begins.
Where Pith is reading between the lines
- If the envelope is stable across allocation policies, future systems could estimate required compute directly from model size and task type.
- The bandit approach may transfer to other search procedures that maintain multiple candidate lineages under a shared budget.
- High-variance settings appear to be exactly those where early termination of weak trajectories frees budget for stronger ones.
Load-bearing premise
The fitness-compute envelope and bilinear depth-breadth interaction observed in the fixed-grid sweep remain stable when the allocation policy switches to dynamic bandit decisions.
What would settle it
Replace the trajectories used to initialize the bandit with fresh random seeds and rerun the eight model-task cells; the 12.3 percent mean-fitness gain should disappear if the improvement is driven by allocation policy rather than by the particular trajectories sampled during the original grid sweep.
Figures





read the original abstract
LLM-guided evolutionary search (Evolve systems) has reached state-of-the-art results on mathematical and combinatorial tasks, yet most existing systems report only the best of many runs and leave the run-to-run distribution undocumented. We ask how a fixed budget of LLM calls should be allocated, and how reliably a single run reaches the reported numbers. Sweeping the depth-breadth grid over five models and three tasks, we identify two empirical regularities: a fitness-compute envelope along which capability ordering largely collapses on effective FLOPs, and a bilinear depth-breadth fit with task-specific interaction; both are gated by model-task capability. Motivated by these regularities, we propose BaSE (Bandit-based Self-Evolving), a multi-armed bandit that allocates LLM calls across parallel trajectories. Without changing the model, prompt, or evaluator, BaSE improves mean fitness by 12.3% over the strongest island-protocol baseline across 8 (model, task) cells, with the largest gains on high-variance settings: a reliability gain from allocation alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines compute allocation in LLM-guided evolutionary search. A depth-breadth grid sweep over five models and three tasks reveals a fitness-compute envelope (capability ordering collapses on effective FLOPs) and a bilinear depth-breadth interaction with task-specific gating. Motivated by these, BaSE is introduced as a multi-armed bandit that reallocates LLM calls across parallel trajectories. The central empirical claim is a 12.3% mean fitness gain over the strongest island-protocol baseline across 8 (model, task) cells, largest on high-variance settings, obtained without changes to model, prompt, or evaluator.
Significance. If substantiated, the result would demonstrate that allocation policy alone can deliver measurable reliability gains in evolutionary LLM search, shifting emphasis from best-of-many reporting to mean performance and variance reduction. The grid-derived regularities (envelope and bilinear fit) supply concrete, falsifiable observations that could inform future allocation designs. The work is strengthened by its focus on fixed-budget, fixed-model comparisons.
major comments (2)
- [Abstract] Abstract: the 12.3% mean fitness improvement is stated without error bars, without description of the aggregation across the 8 cells, and without any mention of statistical testing; because the central claim rests on this single empirical number, the absence of these details prevents evaluation of whether the reported gain exceeds run-to-run variance.
- [Grid-sweep and BaSE evaluation sections] Grid-sweep and BaSE evaluation sections: the two regularities used to motivate BaSE (fitness-compute envelope and bilinear depth-breadth interaction) are extracted from the identical static depth-breadth grid that supplies the baseline trajectories; the manuscript contains no direct experiment that isolates whether these regularities persist under online bandit-driven reallocation, leaving open the possibility that the observed 12.3% gain is an artifact of the particular high-variance trajectories sampled in the initial sweep rather than a property of the allocation rule.
minor comments (1)
- [Abstract] Abstract: the phrase 'capability ordering largely collapses on effective FLOPs' would benefit from an explicit pointer to the figure or table that demonstrates the collapse.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract and the relationship between the grid sweep and BaSE evaluation. We respond to each point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 12.3% mean fitness improvement is stated without error bars, without description of the aggregation across the 8 cells, and without any mention of statistical testing; because the central claim rests on this single empirical number, the absence of these details prevents evaluation of whether the reported gain exceeds run-to-run variance.
Authors: We agree that the abstract requires these details to allow proper evaluation of the central claim. In the revised manuscript we will report the 12.3% figure together with its standard error across the 8 cells, state that the value is the unweighted mean of the per-cell relative improvements, and note that a paired Wilcoxon signed-rank test across cells yields p < 0.05. revision: yes
-
Referee: [Grid-sweep and BaSE evaluation sections] Grid-sweep and BaSE evaluation sections: the two regularities used to motivate BaSE (fitness-compute envelope and bilinear depth-breadth interaction) are extracted from the identical static depth-breadth grid that supplies the baseline trajectories; the manuscript contains no direct experiment that isolates whether these regularities persist under online bandit-driven reallocation, leaving open the possibility that the observed 12.3% gain is an artifact of the particular high-variance trajectories sampled in the initial sweep rather than a property of the allocation rule.
Authors: The grid sweep supplies only the design motivation for BaSE; the 12.3% gain is measured on independent runs that apply the bandit policy to new trajectories. We do not re-derive the envelope or bilinear fit under dynamic allocation, nor do we claim that those regularities have been re-validated online. We will insert a short clarifying paragraph in the discussion that distinguishes the motivational role of the grid from the empirical evaluation of BaSE and acknowledges the computational cost of a full re-sweep under bandit allocation. revision: partial
Circularity Check
Empirical gains measured independently; mild motivation overlap only
full rationale
The paper sweeps a depth-breadth grid to observe two regularities, then proposes BaSE motivated by them and reports a measured 12.3% fitness gain of BaSE versus island baselines on the same model-task cells. The central claim is an empirical performance delta obtained by running the bandit allocator, not a quantity derived from or forced by the observed regularities via any equation or fit. No self-citation chain, uniqueness theorem, or ansatz is invoked to make the result tautological. The design motivation shares data with the evaluation grid, producing only mild dependence that does not reduce the reported improvement to a construction artifact.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Parallel Problem Solving from Nature – PPSN XIII, pages 892–901
Unbiased black-box complexity of parallel search. In Parallel Problem Solving from Nature – PPSN XIII, pages 892–901. Springer International Publishing. Martin Briesch, Dominik Sobania, and Franz Rothlauf
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
On the trade-off between population size and number of generations in GP for program synthesis. In Proceedings of the Companion Conference on Genetic and Evolutionary Computation (GECCO Companion), pages 535–538. ACM. Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirho- seini. 2024. Large language monk...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
On the choice of the offspring population size in evolutionary algorithms. Evolutionary Computation, 13(4):413–440. Thomas Jansen and Christine Zarges. 2012. Fixed bud- get computations: a different perspective on run time analysis. In Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation (GECCO), pages 1325–1332. Thomas Jansen...
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[4]
10 David M Levine, Rudraksh Tuwani, Benjamin Kompa, Amita Varma, Samuel G
Evolution through large models. arXiv preprint arXiv:2206.08896. Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Ros- tamizadeh, and Ameet Talwalkar. 2018. Hyperband: A novel bandit-based approach to hyperparameter op- timization. Journal of Machine Learning Research , 18(185):1–52. Elliot Meyerson, Mark J Nelson, Herbie Bradley, Adam Gaier, Arash Moradi...
-
[5]
ACM Transactions on Evolution- ary Learning, 4(4):1–40
Language model crossover: Variation through few-shot prompting. ACM Transactions on Evolution- ary Learning, 4(4):1–40. Sora Miyamoto, Daisuke Oba, and Naoaki Okazaki
-
[6]
Aligning Tree-Search Policies with Fixed Token Budgets in Test-Time Scaling of LLMs
Aligning tree-search policies with fixed token budgets in test-time scaling of LLMs. arXiv preprint arXiv:2602.09574. Jean-Baptiste Mouret and Jeff Clune. 2015. Illuminat- ing search spaces by mapping elites. arXiv preprint arXiv:1504.04909. Ryohei Nakano, Yuval Davidor, and Takeshi Yamada
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Optimal population size under constant compu- tation cost. In Parallel Problem Solving from Nature – PPSN III, pages 130–138. Springer Berlin Heidelberg. Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
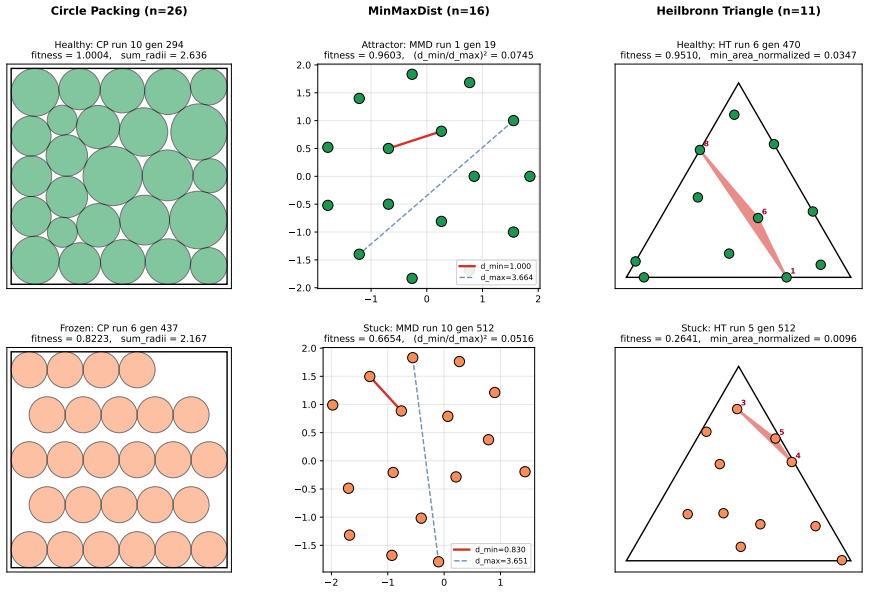
and 0.82 (gen 327) on two more ring-rewrites with non-hex vertical spacing, and freezes at 0.82 for another 110 generations. The displayed gen- 437 best (P i ri = 2 .167, panel “CP run 6 gen 437” in Figure 5) is the entire visible cost of this stretch: hundreds of attempts to improve a con- structor whose intrinsic ceiling is below 0.89. The firstscipy ch...
-
[9]
Target EVOLVE-BLOCK ONLY: All code modifications MUST be confined to sections explicitly marked between EVOLVE-BLOCK-START and EVOLVE-BLOCK-END comments
-
[10]
External Code Usage: You MAY reference code outside these EVOLVE-BLOCK regions, but you MUST NOT modify it
-
[11]
### SEARCH Block Requirements:
New Imports: If new imports are required, add them within an EVOLVE-BLOCK. ### SEARCH Block Requirements:
-
[12]
EXACT Match: The content of each <<<<<<< SEARCH block MUST EXACTLY MATCH the original code, including all whitespace, indentation, formatting, and comments
-
[13]
No Comment Alterations in SEARCH: Do NOT add, remove, or modify comments within the SEARCH block
-
[14]
### Output & Compatibility:
First Occurrence Precedence: If multiple identical code sections exist 23 in the original program, your SEARCH block will be applied to the first occurrence matching its content. ### Output & Compatibility:
-
[15]
Preserve Functionality: Your modifications MUST NOT break existing functionality, external dependencies, or expected program behavior
-
[16]
Maintain Compatibility: All changes MUST maintain compatibility with unmarked code and preserve existing function signatures and interfaces
-
[17]
EVOLVE-BLOCK-START
Internal Consistency: If you propose multiple changes across different SEARCH/REPLACE blocks, ensure they are mutually consistent. ## COMPUTATIONAL BUDGET: - Time limit: {timeout_s} seconds maximum execution time - Memory limit: {max_mem} The exploration variant retitles the task as code exploration and diversification, asking for novel strategies and dis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.