Rubric-Guided Process Reward for Stepwise Model Routing
Pith reviewed 2026-06-29 07:56 UTC · model grok-4.3
The pith
RoRo trains a Rubricor and Judge via alternating optimization to score routing trajectories with query-specific rubrics, supplying process rewards that outperform outcome-only supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
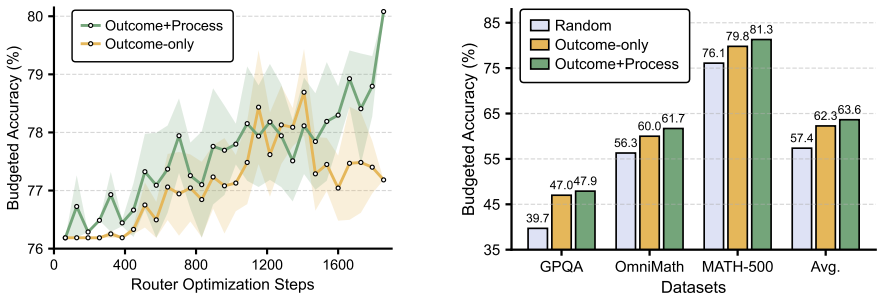
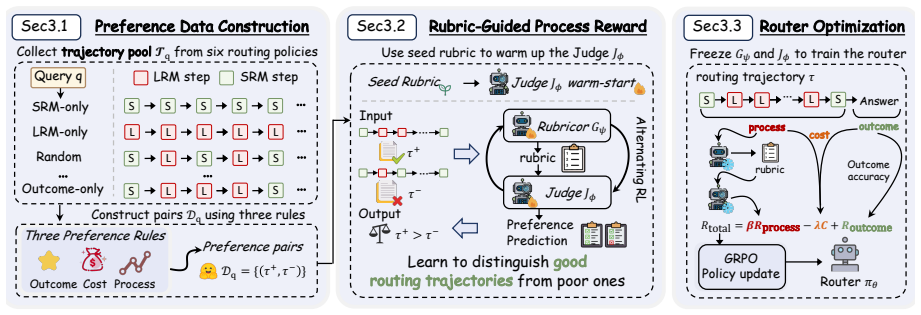
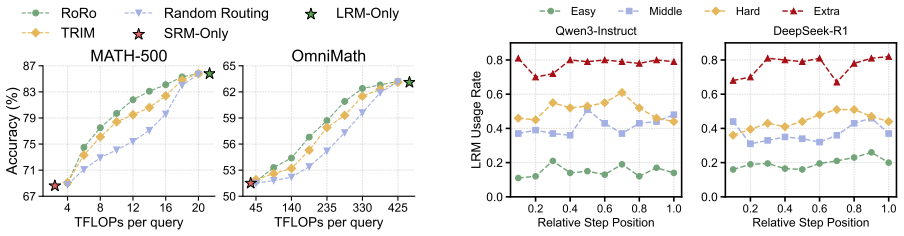
RoRo collects routing trajectories, builds preference pairs from outcome, cost, and process quality, and uses alternating optimization to train Rubricor to generate query-specific evaluation rubrics and a Judge to score the trajectories under those rubrics; the resulting process rewards, when combined with outcome rewards, train a routing policy via GRPO that outperforms baselines on five reasoning benchmarks under same-family and cross-family settings.
What carries the argument
Rubricor-Judge alternating optimization that produces query-specific rubrics and scores routing trajectories to generate process rewards.
If this is right
- Intermediate routing decisions receive direct supervision instead of only final-answer correctness.
- The router achieves higher accuracy and better cost trade-offs on five reasoning benchmarks in both same-family and cross-family model settings.
- Process rewards derived from rubric scoring generalize the supervision signal beyond outcome-only methods.
- Alternating optimization between rubric generation and trajectory scoring produces usable rewards for GRPO policy optimization.
Where Pith is reading between the lines
- The same rubric-generation loop could be tested on sequential decisions outside model routing, such as tool-use chains or multi-step planning.
- If rubric quality can be maintained without human validation, the method reduces dependence on manually designed evaluation criteria in other RL settings.
- Cross-family gains suggest the rubric approach may help when routing between models whose internal representations differ substantially.
Load-bearing premise
Preference pairs built from outcome, cost, and process quality can be scored reliably by the learned Judge under a rubric generated by Rubricor without introducing new biases or needing human checks on rubric quality.
What would settle it
Run a held-out human rating study on scored trajectories and check whether Judge scores under the generated rubrics show low correlation with human judgments on process quality; if correlation is near zero while performance gains vanish on new benchmarks, the rubric-guided process reward claim is falsified.
Figures


read the original abstract
Stepwise model routing improves the efficiency of Large Reasoning Models (LRMs) by assigning each reasoning step to a suitable model. Recent methods formulate routing as a sequential decision process and train the router with reinforcement learning. However, although they model routing as a process, they still supervise the router with outcome rewards. Such rewards only reflect final answer correctness and fail to evaluate intermediate routing decisions, which can weaken performance and generalization. To address this gap, we propose RoRo, a rubric-guided process reward framework for stepwise model routing. RoRo first collects diverse routing trajectories and constructs preference pairs based on outcome, cost, and process quality. It then trains a Rubricor to generate a query-specific evaluation rubric and a Judge to score routing trajectories under this rubric through alternating optimization. The resulting process rewards are combined with outcome rewards to optimize the routing policy via GRPO. Experiments on five reasoning benchmarks under both same-family and cross-family settings show that RoRo consistently outperforms strong baselines and achieves better accuracy and cost trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RoRo, a rubric-guided process reward framework for stepwise model routing in Large Reasoning Models. It collects diverse routing trajectories, constructs preference pairs based on outcome, cost, and process quality, then trains a Rubricor to generate query-specific rubrics and a Judge to score trajectories via alternating optimization. The resulting process rewards are combined with outcome rewards to optimize the routing policy using GRPO. Experiments on five reasoning benchmarks under same-family and cross-family settings report that RoRo consistently outperforms strong baselines with improved accuracy-cost trade-offs.
Significance. If the process rewards derived from the learned Judge under Rubricor rubrics genuinely reflect intermediate routing quality independent of outcome and cost signals, the framework would address a clear gap in outcome-only supervision for sequential routing decisions, potentially enabling more efficient and generalizable inference in LRMs.
major comments (3)
- [Experiments] The central claim that process rewards improve routing over outcome-only baselines rests on the Judge producing scores that capture genuine process quality. However, the manuscript provides no human validation, inter-annotator agreement, or correlation analysis between Judge scores and human process judgments (Experiments section), leaving open the possibility that gains arise from rubric artifacts or reproduction of outcome/cost patterns rather than new information.
- [Method] The alternating optimization between Rubricor and Judge is presented as producing stable, query-specific rubrics, but no convergence diagnostics, stability metrics, or ablation on whether rubrics remain non-circular with the preference-construction signals (outcome, cost, process quality) are reported (Method section). This is load-bearing for attributing performance gains to the process term in GRPO.
- [Experiments] Table or figure reporting the five-benchmark results does not include statistical significance tests, variance across runs, or controls for GRPO hyperparameter sensitivity and baseline implementation details, which are required to substantiate the 'consistent outperformance' claim given the low-visibility dataset construction process.
minor comments (2)
- [Introduction] The abstract and method description introduce 'Rubricor' and 'Judge' without a dedicated related-work subsection contrasting them against prior rubric or LLM-as-judge approaches.
- [Method] Notation for the combined reward (process + outcome) inside GRPO is introduced without an explicit equation reference, making it harder to trace how the process term is scaled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested validation, diagnostics, and statistical details.
read point-by-point responses
-
Referee: [Experiments] The central claim that process rewards improve routing over outcome-only baselines rests on the Judge producing scores that capture genuine process quality. However, the manuscript provides no human validation, inter-annotator agreement, or correlation analysis between Judge scores and human process judgments (Experiments section), leaving open the possibility that gains arise from rubric artifacts or reproduction of outcome/cost patterns rather than new information.
Authors: We agree that explicit human validation would provide stronger evidence that the Judge scores reflect genuine process quality. The preference pairs explicitly incorporate process-quality signals during construction, but to address the concern we will add a small-scale human correlation study (with inter-annotator agreement) on a held-out subset of trajectories in the revised manuscript. revision: yes
-
Referee: [Method] The alternating optimization between Rubricor and Judge is presented as producing stable, query-specific rubrics, but no convergence diagnostics, stability metrics, or ablation on whether rubrics remain non-circular with the preference-construction signals (outcome, cost, process quality) are reported (Method section). This is load-bearing for attributing performance gains to the process term in GRPO.
Authors: We will add convergence curves for the alternating optimization, stability metrics across iterations, and an ablation demonstrating that the learned rubrics do not collapse to outcome/cost signals alone. These additions will be placed in the Method section and appendix of the revision. revision: yes
-
Referee: [Experiments] Table or figure reporting the five-benchmark results does not include statistical significance tests, variance across runs, or controls for GRPO hyperparameter sensitivity and baseline implementation details, which are required to substantiate the 'consistent outperformance' claim given the low-visibility dataset construction process.
Authors: We acknowledge the need for statistical rigor. The revised manuscript will report means and standard deviations over multiple random seeds, include paired t-test p-values against baselines, and provide additional details on GRPO hyperparameter ranges and baseline re-implementation choices. revision: yes
Circularity Check
No significant circularity detected; derivation relies on external preference construction and benchmark evaluation.
full rationale
The abstract describes an external data collection step to build preference pairs from outcome, cost, and process quality signals, followed by alternating optimization to train Rubricor and Judge, with the resulting scores added to outcome rewards inside GRPO. This structure does not reduce the process reward term to a quantity defined by the router policy itself or to fitted parameters by construction. No self-definitional equations, fitted-input predictions, or load-bearing self-citations are identifiable from the provided text. The performance claims rest on experiments across five benchmarks rather than internal redefinitions, making the chain self-contained against external evaluation.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Rubricor
no independent evidence
-
Judge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Rubrics as rewards: Reinforcement learning beyond verifiable domains. InInternational Confer- ence on Learning Representations. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. 2025. Openrubrics: Towards scalable synthetic rubric generation for re- ward modeling and LLM alignment.arXiv preprint arXiv:2510.07743. Qianli Ma, Haotian Zhou, Tingkai Liu, Jianbo Yuan, Pengfei Liu, Yang You, and Hongx...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Solving math word problems with process- based and outcome-based feedback. Binghai Wang, Yantao Liu, Yuxuan Liu, Tianyi Tang, Shenzhi Wang, Chang Gao, Chujie Zheng, Yichang Zhang, Le Yu, Shixuan Liu, Tao Gui, Qi Zhang, Xu- anjing Huang, Bowen Yu, Fei Huang, and Junyang Lin. 2026. Outcome accuracy is not enough: Align- ing the reasoning process of reward m...
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Wenhao Zeng, Xuteng Zhang, Yuling Shi, Chao Hu, Yuting Chen, Beijun Shen, and Xiaodong Gu. 2026. Glimprouter: Efficient collaborative inference by glimpsing one token of thoughts.arXiv preprint arXiv:2601.05110. Haozhen Zhang, Tao Feng, and Jiaxuan You. 2026. Router-r1: Teaching llms multi-round rout...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
The routing policy is a 2-layer MLP with 128 hidden units, following TRIM (Kapoor et al., 2026)
for cross-family collaboration. The routing policy is a 2-layer MLP with 128 hidden units, following TRIM (Kapoor et al., 2026). It takes a 5-dimensional state vector as input, including three uncertainty-derived features (the current-step uncertainty, the minimum and average uncertainty over the prefix), the step token count normalized by a fixed constan...
2026
-
[6]
We use the subset with difficulty levels 1–10 for our evaluation
The benchmark spans a wide range of math- ematical topics and requires advanced problem- solving strategies. We use the subset with difficulty levels 1–10 for our evaluation. GSM8K (Cobbe et al., 2021).GSM8K is a benchmark of 8,792 grade-school math word prob- lems that require multi-step arithmetic reasoning. Although the individual reasoning steps are s...
2021
-
[7]
It evaluates the routing process rather than final answer correctness
-
[8]
It is label-agnostic: it must not refer to trajectory IDs, final correctness, reference answers, or which trajectory is preferred
-
[9]
It should be applicable beyond this specific problem, while still being relevant to the routing challenges shown in the trajectory pool
-
[10]
It should capture whether the route prevents, repairs, or verifies high-impact reasoning errors
-
[11]
always use LRM in later steps
It must not collapse into trivial heuristics such as "always use LRM in later steps", "always minimize LRM calls", "always avoid switching", or "use LRM whenever the solution is long". ### Possible Aspects: Possible aspects include, but are not limited to: intervention before error propagation; timeliness of escalation under uncertainty; avoiding LRM call...
-
[12]
Decide whether the trajectory satisfies the criterion
-
[13]
satisfied
Set "satisfied" to true if the routing behavior clearly satisfies the criterion
-
[14]
satisfied
Set "satisfied" to false if the routing behavior clearly violates the criterion or lacks evidence for satisfying it
-
[15]
criterion_judgments
Use the criterion and score_guidance to make the decision. Compute the final process score as: final_score = sum of weight * score * indicator where indicator = 1 if satisfied is true and 0 otherwise. ### Output Format: Return only a valid JSON object: {"criterion_judgments": [{"criterion": "the original criterion text", "score": 0.5, "satisfied": true} ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.