PatchBoard: Schema-Grounded State Mutation for Reliable and Auditable LLM Multi-Agent Collaboration
Pith reviewed 2026-06-29 07:51 UTC · model grok-4.3
The pith
PatchBoard replaces dialogue in LLM multi-agent systems with validated JSON Patch mutations over a shared structured state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PatchBoard achieves reliable and auditable collaboration by replacing inter-agent dialogue with validated JSON Patch mutations over a shared structured state; an Architect agent constructs the task-specific schema and workflow rules while a deterministic kernel validates each proposed mutation against schema constraints, role-specific write contracts, and runtime invariants before committing it transactionally.
What carries the argument
The deterministic kernel that validates every JSON Patch mutation against the schema, role contracts, and invariants before transactional commit.
If this is right
- State changes become attributable and auditable through the immutable mutation log.
- Token cost per successful task falls because structured patches replace open-ended conversation.
- Workflow invariants are enforced mechanically rather than through prompting alone.
- Role separation is maintained by contract checks that prevent unauthorized writes.
Where Pith is reading between the lines
- The same mutation-validation pattern could be applied to other long-horizon agent tasks where dialogue cost grows rapidly.
- If schemas can be generated or composed automatically rather than written by a dedicated Architect, coverage might extend beyond the tested household domain.
- Audit logs produced by the kernel could support post-hoc verification or regulatory review of agent decisions.
Load-bearing premise
The Architect agent can reliably construct a complete and correct task-specific schema plus workflow rules such that the deterministic kernel's validation prevents all relevant failure modes without introducing new ones.
What would settle it
A drop in success rate on episodes where the Architect produces incomplete schemas or where the kernel accepts mutations that still cause downstream task failure.
Figures


read the original abstract
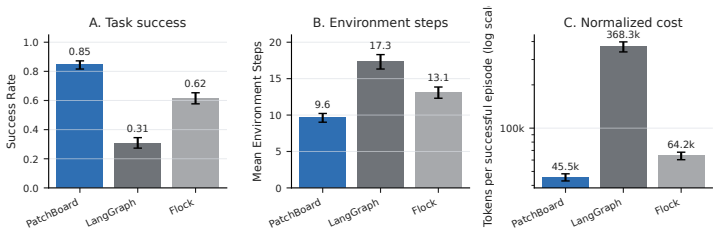
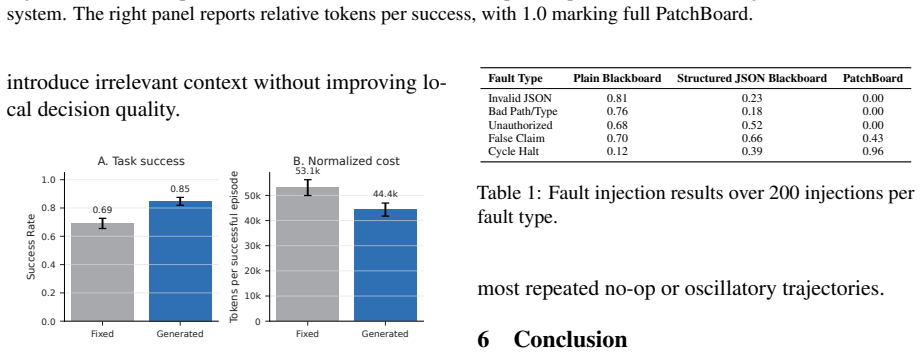
LLM multi-agent systems often coordinate through natural-language dialogue or loosely structured shared memory, making intermediate state difficult to validate, attribute, and audit. We introduce PatchBoard, a schema-grounded collaboration architecture that replaces inter-agent dialogue with validated JSON Patch mutations over a shared structured state. An Architect agent constructs a task-specific schema and workflow rules, while a deterministic kernel validates each proposed state mutation against schema constraints, role-specific write contracts, and runtime invariants before committing it transactionally. On 630 matched ALFWorld episodes, PatchBoard achieves an 84.6% success rate, compared with 30.8% for LangGraph and 61.6% for Flock, while reducing tokens per successful task to 45.5k, compared with 368.3k and 64.2k, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PatchBoard, a multi-agent collaboration architecture that replaces natural-language dialogue with validated JSON Patch mutations over a shared structured state. An Architect agent generates a task-specific schema and workflow rules; a deterministic kernel then enforces schema constraints, role-specific write contracts, and runtime invariants before committing mutations transactionally. On 630 matched ALFWorld episodes the system reports 84.6% success (vs. 30.8% LangGraph, 61.6% Flock) and 45.5k tokens per successful task (vs. 368.3k and 64.2k).
Significance. If the empirical claims are substantiated, the architecture offers a concrete mechanism for making LLM multi-agent state transitions auditable and partially deterministic, which could reduce untraceable failures in long-horizon tasks. The separation of schema construction from validated mutation is a clear design contribution; however, the reported gains rest entirely on unexamined assumptions about Architect reliability and baseline parity.
major comments (2)
- [Abstract] Abstract and experimental evaluation: performance numbers (84.6% success, 45.5k tokens) are stated without any description of experimental controls, baseline re-implementations, random seeds, statistical tests, or failure-mode analysis, making it impossible to assess whether the data support the superiority claim.
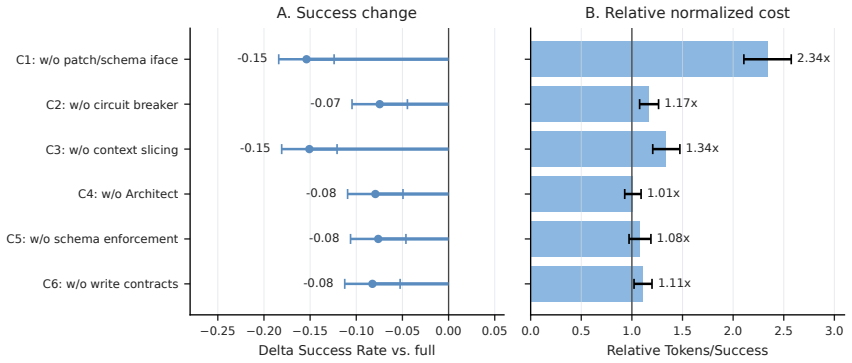
- The headline result depends on the Architect agent producing a complete, correct schema and workflow rules for every episode; the deterministic kernel can only validate against what the Architect supplies. No data are provided on Architect success rate, schema completeness, or cases in which an incomplete schema allowed invalid paths to be accepted.
Simulated Author's Rebuttal
We thank the referee for the insightful comments. We provide point-by-point responses below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental evaluation: performance numbers (84.6% success, 45.5k tokens) are stated without any description of experimental controls, baseline re-implementations, random seeds, statistical tests, or failure-mode analysis, making it impossible to assess whether the data support the superiority claim.
Authors: We acknowledge that the current presentation of results lacks sufficient detail on the experimental methodology. In the revised version, we will include a dedicated subsection describing the experimental controls, the process for re-implementing the LangGraph and Flock baselines, the random seeds used, the application of statistical tests such as paired t-tests or McNemar's test for comparing success rates, and an analysis of failure modes. This will strengthen the empirical claims. revision: yes
-
Referee: The headline result depends on the Architect agent producing a complete, correct schema and workflow rules for every episode; the deterministic kernel can only validate against what the Architect supplies. No data are provided on Architect success rate, schema completeness, or cases in which an incomplete schema allowed invalid paths to be accepted.
Authors: This is a valid observation regarding the dependency on the Architect agent. The manuscript does not report separate metrics for Architect performance or schema quality. We will revise the discussion section to explicitly address this assumption and its implications for the results. We will also clarify that the reported success rates incorporate any failures attributable to the Architect, as the evaluation was end-to-end. However, we do not have additional data to quantify Architect success rates independently. revision: partial
- Quantitative data on the Architect agent's success rate, schema completeness, and invalid path acceptance were not collected during the original experiments.
Circularity Check
No circularity: empirical benchmark results with no self-referential reductions
full rationale
The paper reports success rates and token counts from direct comparisons against LangGraph and Flock on 630 matched ALFWorld episodes. No equations, fitted parameters, or derivation chains are present. The Architect agent's role is an architectural assumption whose reliability is not claimed via self-citation or by-construction equivalence; evaluation remains external to any internal fit. This matches the default expectation of a non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption JSON Patch operations can be validated deterministically against schemas, role contracts, and runtime invariants.
- domain assumption An LLM-based Architect can produce schemas and rules sufficient for the target task domain.
invented entities (3)
-
Architect agent
no independent evidence
-
Deterministic kernel
no independent evidence
-
Role-specific write contracts
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Always-OnAgents:A Survey of Persistent Memory, State, and Governance in LLMAgents
Survey mapping persistent state in LLM agents along six axes and proposing the AOEP-v0 protocol to evaluate governance and recovery obligations.
Reference graph
Works this paper leans on
-
[1]
AgentScope: A flexible yet robust multi-agent platform, 2024
Prompting is programming: A query language for large language models.Proceedings of the ACM on Programming Languages, 7(PLDI):1946–1969. Pierre Bourhis, Juan L Reutter, Fernando Suárez, and Domagoj Vrgoˇc. 2017. Json: data model, query lan- guages and schema specification. InProceedings of the 36th ACM SIGMOD-SIGACT-SIGAI symposium on principles of databa...
-
[2]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as operating sys- tems.Preprint, arXiv:2310.08560. Nii H Penny. 1986. Blackboard systems: The black- board model of problem solving and the evolution of blackboard architectures.The AI Magazine. Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyua...
work page internal anchor Pith review Pith/arXiv arXiv 1986
-
[3]
Reflexion: Language agents with verbal rein- forcement learning. InAdvances in Neural Informa- tion Processing Systems, volume 36. Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2021. ALFWorld: Aligning text and embodied environments for interactive learning. In International Conference on Learning ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.