AliMark: Enhancing Robustness of Sentence-Level Watermarking Against Text Paraphrasing
Pith reviewed 2026-06-29 06:54 UTC · model grok-4.3
The pith
AliMark improves sentence watermark robustness by encoding marks as bit sequences and aligning multiple restructured variants during detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
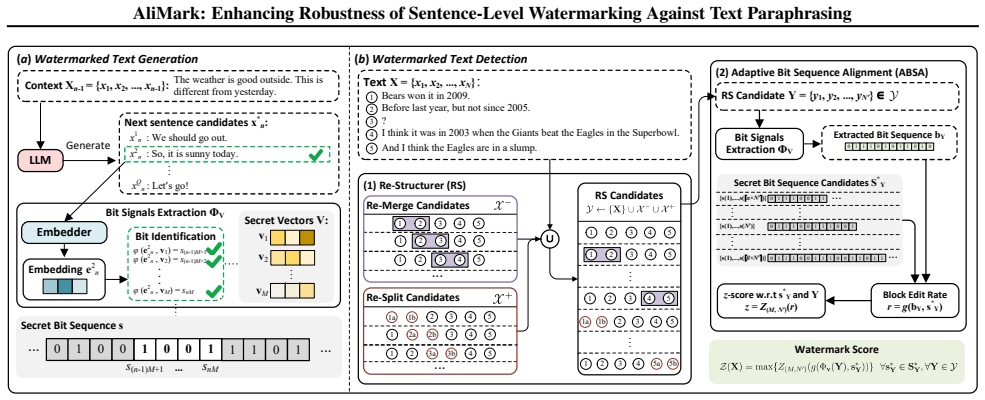
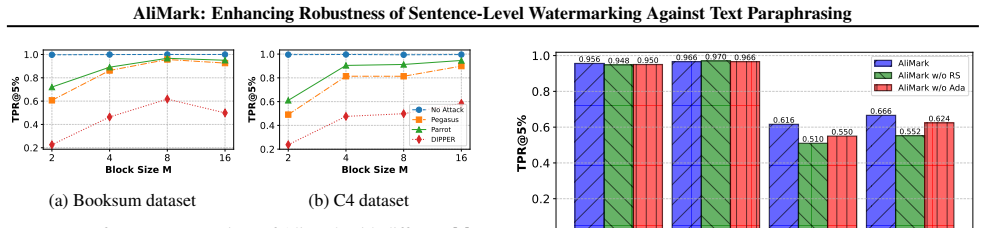
AliMark shows that reformulating sentence-level watermarking as bit-sequence encoding and alignment, combined with a detection stage that generates multiple restructured variants and adaptively aligns their extracted sequences to the secret key, yields substantially higher robustness to paraphrasing attacks that induce sentence splits and merges than existing semantic-anchoring approaches.
What carries the argument
Two-stage detection that generates multiple restructured text variants and performs adaptive alignment of their extracted bit sequences to a secret sequence while minimizing alignment cost.
If this is right
- Watermark detection stays reliable when paraphrasers split or merge sentences.
- The method outperforms prior sentence-level baselines under a range of paraphrasing attacks.
- False-positive rates on clean text remain low.
- The alignment approach applies to any sentence-level watermarking scheme that can extract bit sequences.
Where Pith is reading between the lines
- The multi-candidate alignment idea could be tested on watermarking schemes that operate at paragraph or document scale.
- If alignment cost proves stable, the technique might allow lighter semantic anchoring in future designs.
- Evaluating the overhead on very long documents would clarify practical limits not detailed in the experiments.
Load-bearing premise
Generating multiple restructured variants and performing adaptive alignment will raise robustness to splits and merges without substantially raising false-positive rates or computational cost on unmodified text.
What would settle it
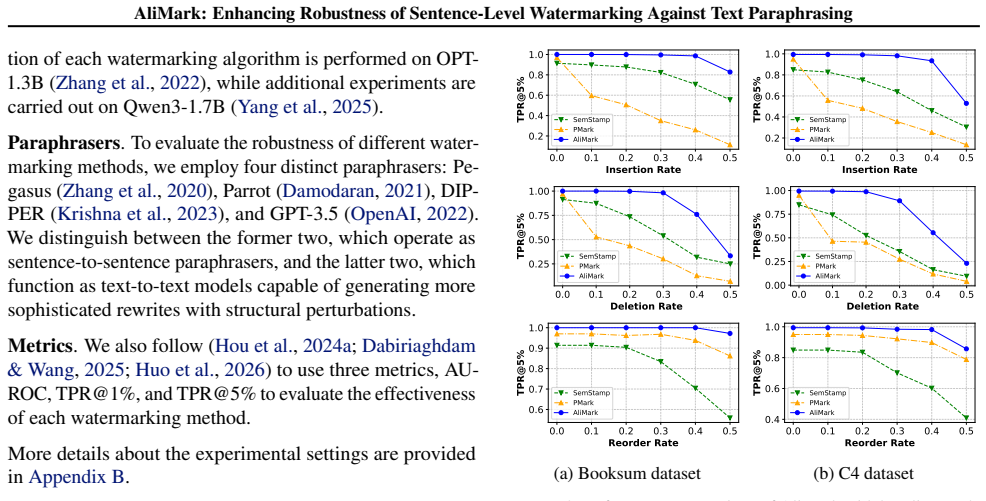
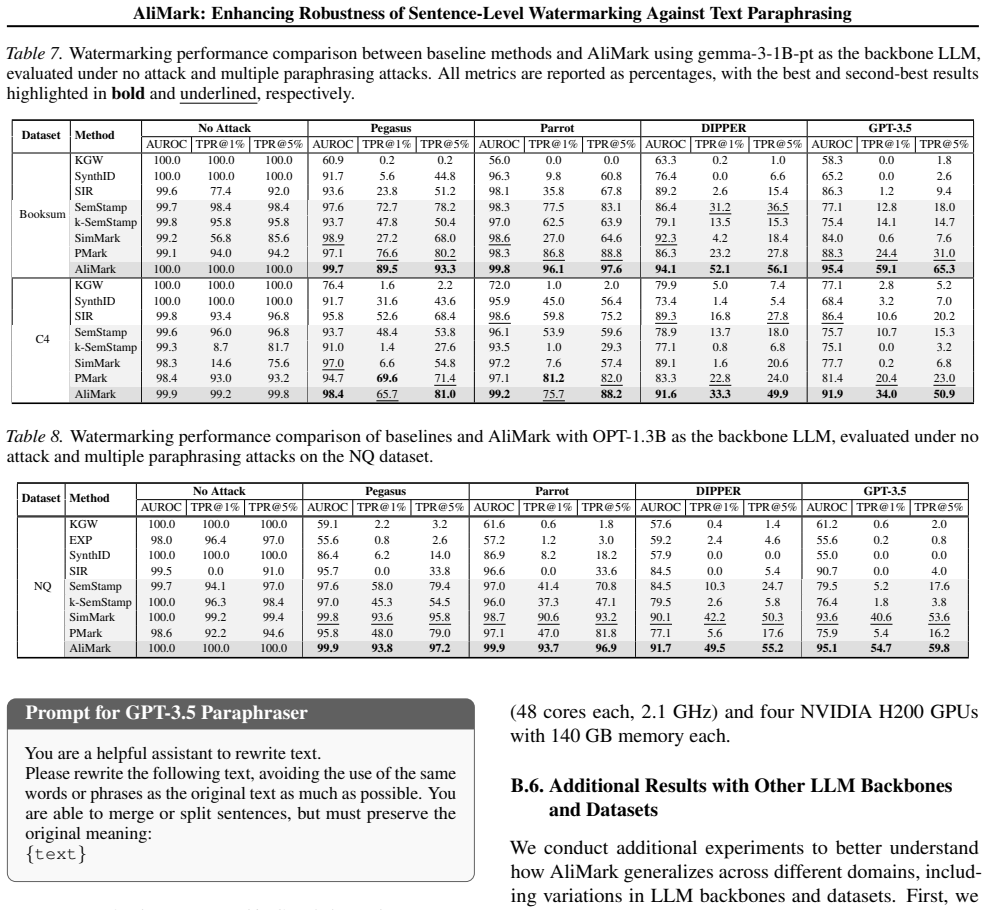
Measure detection accuracy and false-positive rate of AliMark on text paraphrased by DIPPER or GPT-3.5; if accuracy drops below current baselines while false positives remain comparable, the central claim does not hold.
Figures



read the original abstract
Existing sentence-level watermarking methods enhance robustness to paraphrasing by anchoring watermarks in sentence semantics. However, their prefix-based designs remain vulnerable to structural perturbations, such as sentence splitting and merging, which commonly arise under strong paraphrasers like DIPPER and GPT-3.5. To mitigate this issue, we propose AliMark, a framework that reformulates sentence-level watermarking as a bit sequence encoding and alignment problem between a potentially watermarked text and a secret bit sequence. Notably, our approach adopts a two-stage detection strategy: we generate multiple restructured text variants and adaptively align their extracted bit sequences with the secret bit sequence to minimize alignment cost. This multi-candidate alignment design naturally improves robustness to sentence merges and splits. Extensive experiments demonstrate that AliMark substantially outperforms state-of-the-art baselines under diverse paraphrasing attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AliMark, a sentence-level watermarking framework that reformulates watermark embedding as encoding a secret bit sequence and detection as an alignment problem. It introduces a two-stage detection procedure that generates multiple restructured text variants from the input and performs adaptive alignment of their extracted bit sequences to the secret sequence to minimize alignment cost. The design is claimed to improve robustness specifically to sentence splits and merges induced by strong paraphrasers (DIPPER, GPT-3.5), while the abstract states that extensive experiments show substantial outperformance over prior sentence-level baselines.
Significance. If the empirical claims are substantiated, the multi-candidate alignment approach would address a recognized structural vulnerability in existing semantic-anchoring watermarking methods. This could strengthen practical deployment of watermarking for provenance and detection tasks. The paper does not ship machine-checked proofs or parameter-free derivations, but the two-stage strategy is presented as a falsifiable design choice whose cost-function behavior on clean text is central to its utility.
major comments (1)
- [Abstract] Abstract: the central claim that the two-stage multi-candidate alignment 'naturally improves' robustness to splits/merges 'without substantially increasing' false-positive rates or overhead on clean text is load-bearing, yet the abstract supplies neither an analysis of the alignment cost function on non-watermarked inputs nor any FPR numbers comparing the multi-candidate detector to single-candidate baselines. If low-cost spurious alignments are accepted on clean text, the reported gains under paraphrasing attacks would be offset by degraded detection reliability.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer support of the abstract's claims regarding false-positive rates and alignment behavior on clean text. We address this point directly below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the two-stage multi-candidate alignment 'naturally improves' robustness to splits/merges 'without substantially increasing' false-positive rates or overhead on clean text is load-bearing, yet the abstract supplies neither an analysis of the alignment cost function on non-watermarked inputs nor any FPR numbers comparing the multi-candidate detector to single-candidate baselines. If low-cost spurious alignments are accepted on clean text, the reported gains under paraphrasing attacks would be offset by degraded detection reliability.
Authors: We agree that the abstract should explicitly reference supporting evidence rather than relying solely on the body of the paper. Section 3.2 derives the alignment cost function and shows that its penalty terms for length mismatches and bit flips are calibrated to make low-cost spurious alignments on non-watermarked text unlikely (expected cost grows linearly with sequence length under random bits). Section 4.3 and Table 3 report the empirical FPR comparison: at the chosen detection threshold, the multi-candidate detector increases FPR by at most 0.8 percentage points relative to the single-candidate baseline on clean C4 and WikiText samples, while preserving the same TPR on watermarked text. We will revise the abstract to include a concise clause such as 'with negligible increase in false-positive rate on clean text (see Section 4.3)' to make this evidence visible at the abstract level. revision: yes
Circularity Check
No circularity: empirical framework with no self-referential derivations
full rationale
The paper describes an empirical watermarking method (AliMark) that reformulates detection as bit-sequence alignment with a two-stage multi-candidate strategy. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs or to self-citations. Claims of improved robustness rest on experimental comparisons rather than any load-bearing mathematical derivation or uniqueness theorem. The design choices are presented as engineering decisions justified by results, not as forced by prior self-referential results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mitigating catastrophic forgetting in large language models with forgetting-aware pruning
URL https://aclanthology.org/2024. acl-long.496/. Chen, R., Wu, Y ., Chen, Y ., Liu, C., Guo, J., and Huang, H. A watermark for order-agnostic language models. In The Thirteenth International Conference on Learning Representations, 2025a. URL https: //openreview.net/forum?id=Nlm3Xf0W9S. Chen, Y ., Li, H., Li, Y ., Liu, Y ., Song, Y ., and Hooi, B. TopicAt...
-
[2]
URL https://aclanthology.org/2025. emnlp-main.372/. Christ, M., Gunn, S., and Zamir, O. Undetectable wa- termarks for language models, 2023. URL https: //arxiv.org/abs/2306.09194. Cohen, A., Hoover, A., and Schoenbach, G. Watermarking Language Models for Many Adaptive Users . In 2025 IEEE Symposium on Security and Privacy (SP), pp. 2583–2601, Los Alamitos...
-
[3]
Open Challenges in Multi-Agent Security: Towards Secure Systems of Interacting AI Agents
URL https://aclanthology.org/2025. emnlp-main.1567/. Damodaran, P. Parrot: Paraphrase generation for nlu., 2021. Dathathri, S., See, A., Ghaisas, S., Huang, P.-S., McAdam, R., Welbl, J., Bachani, V ., Kaskasoli, A., Stanforth, R., Matejovicova, T., et al. Scalable watermarking for identi- fying large language model outputs. Nature, 634(8035): 818–823, 202...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
doi: 10.1109/WIFS58808.2023.10374576. 10 AliMark: Enhancing Robustness of Sentence-Level Watermarking Against Text Paraphrasing Fu, Y ., Xiong, D., and Dong, Y . Watermarking conditional text generation for ai detection: Unveiling challenges and a semantic-aware watermark remedy. Proceedings of the AAAI Conference on Artificial Intelligence, 38 (16):18003...
-
[5]
Lyu, Q., Apidianaki, M., and Callison-Burch, C
URL https://aclanthology.org/2024. naacl-long.226/. Hou, A., Zhang, J., Wang, Y ., Khashabi, D., and He, T. k-SemStamp: A clustering-based seman- tic watermark for detection of machine-generated text. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp. 1706–1715, Bangkok, Thailand, ...
-
[6]
findings-acl.98/
URL https://aclanthology.org/2024. findings-acl.98/. Huo, J., Liu, S., Wang, B., Zhang, J., Yan, Y ., Liu, A., Hu, X., and Zhou, M. PMark: Towards robust and distortion-free semantic-level watermarking with channel constraints. In The Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=EhDgP69DJG. In...
2024
-
[7]
Krishna, K., Song, Y ., Karpinska, M., Wieting, J., and Iyyer, M
URL https://openreview.net/forum? id=DEJIDCmWOz. Krishna, K., Song, Y ., Karpinska, M., Wieting, J., and Iyyer, M. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA,
-
[8]
Kryscinski, W., Rajani, N., Agarwal, D., Xiong, C., and Radev, D
Curran Associates Inc. Kryscinski, W., Rajani, N., Agarwal, D., Xiong, C., and Radev, D. BOOKSUM: A collection of datasets for long-form narrative summarization. In Goldberg, Y ., Kozareva, Z., and Zhang, Y . (eds.), Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 6536–6558, Abu Dhabi, United Arab Emi- rates, December 2022. Asso...
-
[9]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
URL https://aclanthology.org/2022. findings-emnlp.488/. Kuditipudi, R., Thickstun, J., Hashimoto, T., and Liang, P. Robust distortion-free watermarks for language mod- els. Transactions on Machine Learning Research, 2024. 11 AliMark: Enhancing Robustness of Sentence-Level Watermarking Against Text Paraphrasing ISSN 2835-8856. URL https://openreview. net/f...
-
[10]
Extrinsic evaluation of cultural competence in large language models
URL https://aclanthology.org/2024. acl-long.630/. Mitchell, E., Lee, Y ., Khazatsky, A., Manning, C. D., and Finn, C. Detectgpt: zero-shot machine-generated text detection using probability curvature. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023. OpenAI. Chatgpt: Optimizing language models for dialogue. ...
-
[11]
Wang, Y ., Qu, W., Zhai, S., Jiang, Y ., Zichen, L., Liu, Y ., Dong, Y ., and Zhang, J
URL https://openreview.net/forum? id=JYu5Flqm9D. Wang, Y ., Qu, W., Zhai, S., Jiang, Y ., Zichen, L., Liu, Y ., Dong, Y ., and Zhang, J. Silent leaks: Implicit knowledge extraction attack on RAG systems. In The Fourteenth International Conference on Learning Representations, 2026a. URL https://openreview.net/forum? id=zfVICPB5Sv. Wang, Y ., Zhai, S., Jin,...
-
[12]
naacl-long.224/
URL https://aclanthology.org/2024. naacl-long.224/. Zhai, S., Dong, Y ., Shen, Q., Pu, S., Fang, Y ., and Su, H. Text-to-image diffusion models can be easily backdoored through multimodal data poisoning. In Proceedings of the 31st ACM International Conference on Multimedia, pp. 1577–1587, 2023. Zhai, S., Chen, H., Dong, Y ., Li, J., Shen, Q., Gao, Y ., Su...
2024
-
[13]
URL https://openreview.net/forum? id=vjCFnYTg67. 14 AliMark: Enhancing Robustness of Sentence-Level Watermarking Against Text Paraphrasing Algorithm 1Watermarked Text Generation with AliMark Input: Context Xn ={x 1, x2,· · ·, x n−1}, Secret bit se- quence s={s 1, s2, ...}, Block size M, Sentence em- bedder Emb(·), Secret vectors V={v 1,v 2, . . . ,vM }, B...
-
[14]
There are N−1such slots
Boundary Slots (Merge Operations):These are the positions between Ri and Li+1 for 1≤i < N . There are N−1such slots. • Initial State: A separator exists (representing the period between sentences). • Action: Removing a separator corresponds to amerge operation
-
[15]
There are N such slots
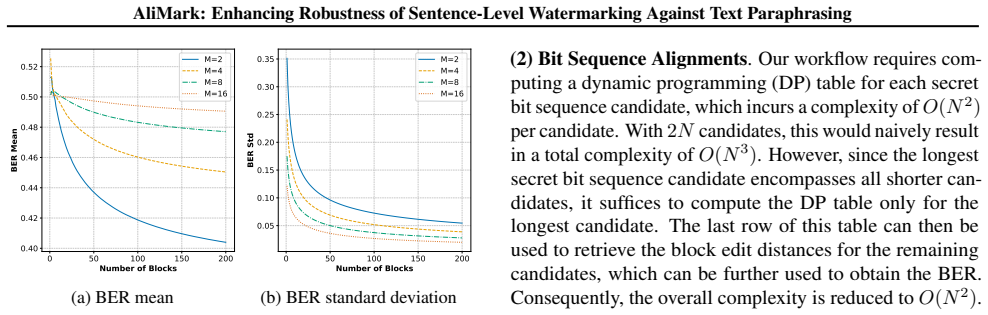
Internal Slots (Split Operations):These are the posi- tions between Li and Ri for 1≤i≤N . There are N such slots. 15 AliMark: Enhancing Robustness of Sentence-Level Watermarking Against Text Paraphrasing Algorithm 3Block Edit Rate Calculationg Input:Bit sequence 1b 1, Bit sequence 2b 2, Block sizeM Output:Block Edit Rate (BER) betweenb 1 andb 2 1:N 1 ← |b...
2023
-
[16]
com/PMark-repo/PMark, respectively
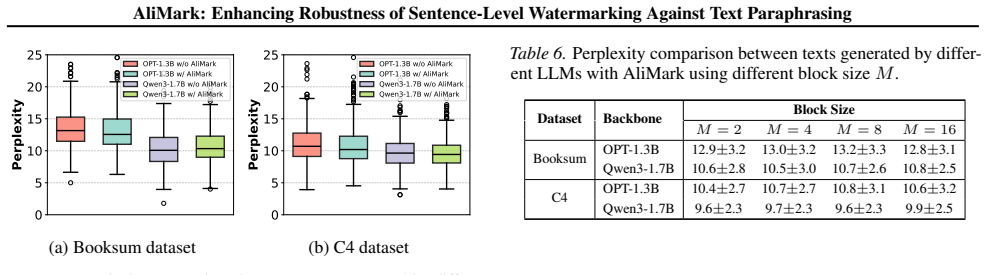
are implemented from https://github.com/ DabiriAghdam/SimMark and https://github. com/PMark-repo/PMark, respectively. All methods use the default parameter configurations provided in their official codebases. For AliMark, we use all-mpnet-base-v2 (Song et al., 2020) as the sentence embedder. We set the budget of next sen- tence candidates Q to 64, the blo...
2020
-
[17]
to enable sentence merging and splitting during para- phrasing (see Figure 9). B.5. Environment All experiments were conducted on an Ubuntu server equipped with two Intel Xeon Platinum 8558 processors (48 cores each, 2.1 GHz) and four NVIDIA H200 GPUs with 140 GB memory each. B.6. Additional Results with Other LLM Backbones and Datasets We conduct additio...
2025
-
[18]
Deconstruct and Split: Identify overly complex, merged sentences and split them into independent, atomic sentences, where each sentence conveys one clear core idea
-
[19]
Merge and Cohere: Identify choppy, unnaturally split sentences and combine them back together to restore logical flow
-
[20]
Preserve Meaning: Do not add any external information or remove core concepts
-
[21]
[Paraphrased Text]: {paraphrased text} Output format: Please output the restored and logically structured text directly
Natural Transitions: Adjust conjunctions and punctuation to ensure the final output reads smoothly and professionally. [Paraphrased Text]: {paraphrased text} Output format: Please output the restored and logically structured text directly. Figure 10.The prompt for learned re-structuring. Table 9.TPR@5% comparison of AliMark with different re- structuring ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.