Explaining Rankings with Hidden Group Bonuses
Pith reviewed 2026-06-29 00:36 UTC · model grok-4.3
The pith
Observed rankings can be explained by jointly recovering a linear utility function and latent constant group bonuses from the data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a formal framework for the ranking explanation problem with unobserved sensitive features that act through group-specific linear boosts, then develop an algorithmic solution that leverages constraint satisfaction and automated reasoning techniques to jointly infer the linear scoring parameters and latent group bonuses consistent with the observed rankings; they prove that determining a satisfying linear function with group-specific bonuses is NP-hard in general but admits a polynomial-time solution when the feature dimension and the number of groups are constant.
What carries the argument
Constraint satisfaction and automated reasoning techniques that jointly infer linear scoring parameters together with latent group bonuses.
If this is right
- The method recovers both the underlying linear weights and the hidden group bonuses from ranking data alone.
- Explanations remain possible even when sensitive group attributes are never observed.
- The approach supplies faithful accounts of ranking outcomes in settings that use constant group adjustments for fairness.
- For fixed feature dimension and number of groups the inference problem can be solved efficiently.
Where Pith is reading between the lines
- The same constraint-satisfaction encoding could be adapted to settings where group bonuses are allowed to be linear rather than constant.
- Testing the recovered bonuses against downstream fairness metrics would check whether the inferred constants align with intended policy goals.
- The hardness result suggests that scaling to high-dimensional feature spaces will require additional structural assumptions beyond those already stated.
Load-bearing premise
The model assumes that observed rankings are produced exactly by a linear utility plus additive group-specific bonuses with no noise, ties, or other unmodeled factors.
What would settle it
Run the algorithm on rankings generated from a linear model plus bonuses and then add even modest random noise or ties; if the recovered parameters no longer reproduce the input order exactly, the exact-match assumption is violated.
Figures





read the original abstract
Determining a linear utility function that correlates with observed candidate rankings is a foundational problem with applications in domains such as admissions, hiring, and recommendation systems, e.g., [Storandt and Funke, AAAI'19, Zhang et al., KDD'23, Wang et al., ICDE'24 (best paper award), Chen and Wong, VLDB'24]. Traditionally, these models assume full visibility into the feature sets used to determine the utility score. However, real-world scenarios often involve sensitive attributes that are hidden or partially observed, yet may influence outcomes through additive bonuses designed to promote fairness, as in [Gale and Marian, ICDE'24]. Motivated by such practical concerns, we study a variant of the ranking explanation problem where sensitive features are unobserved but may influence candidate rankings through group-specific linear boosts. We present a formal framework for modeling this problem and develop an algorithmic solution that leverages constraint satisfaction and automated reasoning techniques to jointly infer the linear scoring parameters and latent group bonuses consistent with the observed rankings. We further show that determining a satisfying linear function with group-specific bonuses is \textsf{NP}-hard in general, but when the feature dimension and the number of groups are constant, the problem admits a polynomial-time solution. Our approach is the first to address this nuanced variant, which captures key real-world challenges in fair ranking and admission systems. We perform extensive experiments on both real-world and synthetic datasets, demonstrating that our method effectively recovers hidden bonus structures and provides faithful explanations of observed ranking outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a formal framework for explaining observed rankings using linear utility functions with additive latent group bonuses for hidden sensitive attributes. It develops an algorithmic solution based on constraint satisfaction and automated reasoning to jointly infer the linear parameters and group bonuses. The authors establish that the problem is NP-hard in general but solvable in polynomial time when the feature dimension and the number of groups are constant. Experiments on synthetic and real-world datasets are presented to show that the method recovers hidden bonus structures and provides faithful explanations.
Significance. If the theoretical claims and experimental results hold, this work would be significant as it is the first to address ranking explanation with hidden group bonuses, bridging algorithmic fairness and ranking problems. The fixed-parameter tractability result when dimension and groups are constant is a notable theoretical contribution, and the use of CSP techniques is innovative for this setting. The experimental validation adds practical value.
major comments (1)
- [Abstract] The framework relies on the assumption that observed rankings are produced exactly by a linear utility plus additive group bonuses with no noise, ties, or other factors (as implied by the consistency condition for the CSP procedure). This assumption is load-bearing for both the algorithmic solution and the complexity results; small perturbations in real rankings could render instances unsatisfiable.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The framework relies on the assumption that observed rankings are produced exactly by a linear utility plus additive group bonuses with no noise, ties, or other factors (as implied by the consistency condition for the CSP procedure). This assumption is load-bearing for both the algorithmic solution and the complexity results; small perturbations in real rankings could render instances unsatisfiable.
Authors: We agree that the model is defined under the exact-consistency assumption (no noise, no ties, and rankings produced precisely by linear utility plus additive group bonuses). This assumption is stated via the consistency condition in the CSP formulation and is indeed central to both the NP-hardness result and the FPT algorithm for constant dimension and number of groups. The paper studies this idealized setting to obtain clean theoretical guarantees; we do not claim robustness to perturbations. To make the scope clearer, we will revise the abstract to explicitly note the exact-consistency assumption and will add a short paragraph in the introduction (or conclusions) acknowledging that noisy or inconsistent rankings would require relaxations such as soft constraints or optimization-based variants, which we leave for future work. revision: yes
Circularity Check
No circularity: framework, hardness proof, and FPT result are independent of inputs
full rationale
The paper defines a new problem variant (linear scoring plus latent group bonuses exactly reproducing observed rankings with no noise), then applies standard CSP/automated-reasoning techniques to solve for parameters and proves NP-hardness plus FPT tractability when d and number of groups are constant. These steps rely on external complexity results and constraint-solving methods rather than any self-definition, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or fitting procedures appear that reduce a claimed output to the modeling assumption by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qingyao Ai, Keping Bi, Cheng Luo, Jiafeng Guo, and W Bruce Croft. 2018. Unbiased learning to rank with unbiased propensity estimation. InSIGIR 2018
2018
-
[2]
Sanjeev Arora, László Babai, Jacques Stern, and Z Sweedyk. 1997. The hardness of approximate optima in lattices, codes, and systems of linear equations.J. Comput. System Sci.54, 2 (1997), 317–331
1997
-
[3]
Abolfazl Asudeh, Hosagrahar Visvesvaraya Jagadish, Julia Stoyanovich, and Gautam Das. 2019. Designing fair ranking schemes. InSIGMOD 2019. 1259–1276
2019
-
[4]
Abolfazl Asudeh, Azade Nazi, Nan Zhang, Gautam Das, and HV Jagadish. 2019. RRR: Rank-regret representative. InSIGMOD 2019. 263–280
2019
-
[5]
Amey Bhangale and Subhash Khot. 2021. Optimal inapproximability of satisfiable k-LIN over non-abelian groups. InProceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing. 1615–1628
2021
-
[6]
Stephan Börzsönyi, Donald Kossmann, and Konrad Stocker. 2001. The skyline operator. InICDE 2001. IEEE
2001
- [7]
-
[8]
Yuan-Chi Chang, Lawrence Bergman, Vittorio Castelli, Chung-Sheng Li, Ming-Ling Lo, and John R Smith. 2000. The onion technique: Indexing for linear optimization queries. InACM SIGMOD 2000. 391–402
2000
-
[9]
Bahzad Charbuty and Adnan Abdulazeez. 2021. Classification based on decision tree algorithm for machine learning.Journal of applied science and technology trends2, 01 (2021), 20–28
2021
-
[10]
Qixu Chen and Raymond Chi-Wing Wong. 2024. Robust Best Point Selection under Unreliable User Feedback.Proceedings of the VLDB Endowment17, 11 (2024)
2024
-
[11]
Zixuan Chen, Panagiotis Manolios, and Mirek Riedewald. 2025. Synthesizing Scoring Functions for Rankings using Symbolic Gradient Descent. InICDE 2025
2025
-
[12]
Tanya Chowdhury, Razieh Rahimi, and James Allan. 2023. Rank-lime: local model-agnostic feature attribution for learning to rank. InProceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval. 33–37
2023
-
[13]
Tanya Chowdhury, Yair Zick, and James Allan. 2025. RankSHAP: Shapley value based feature attributions for learning to rank. InInternational Conference on Learning Representations, Vol. 2025. 36765–36794
2025
-
[14]
Gautam Das, Dimitrios Gunopulos, Nick Koudas, and Dimitris Tsirogiannis. 2006. Answering top-k queries using views. InPVLDB 2006. 451–462
2006
-
[15]
Andrew Davenport and Jayant Kalagnanam. 2004. A computational study of the Kemeny rule for preference aggregation. InAAAI, Vol. 4. 697–702
2004
-
[16]
Finale Doshi-Velez and Been Kim. 2017. Towards a rigorous science of interpretable machine learning.arXiv preprint arXiv:1702.08608(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Cynthia Dwork, Ravi Kumar, Moni Naor, and Dandapani Sivakumar. 2001. Rank aggregation methods for the web. InWWW 2001. 613–622
2001
-
[18]
1987.Algorithms in combinatorial geometry
Herbert Edelsbrunner. 1987.Algorithms in combinatorial geometry. Vol. 10. Springer Science & Business Media
1987
-
[19]
Ronald Fagin. 2002. Combining fuzzy information: an overview.ACM SIGMOD Record31, 2 (2002), 109–118
2002
-
[20]
Ronald Fagin, Amnon Lotem, and Moni Naor. 2001. Optimal aggregation algorithms for middleware. InProceedings of the twentieth ACM SIGMOD-SIGACT- SIGART symposium on Principles of database systems. 102–113
2001
-
[21]
Abraham Gale and Amélie Marian. 2020. Explaining monotonic ranking functions. Proc. VLDB Endow.14, 4 (Dec. 2020), 640–652. doi:10.14778/3436905.3436922
-
[22]
Abraham Gale and Amélie Marian. 2024. Explainable disparity compensation for efficient fair ranking. InICDE 2024. IEEE
2024
-
[23]
Hongjie Guo, Jianzhong Li, and Hong Gao. 2025. Towards strong regret minimization sets: Balancing freshness and diversity in data selection.Theoretical Computer Science1026 (2025), 114986
2025
-
[24]
Qianyu Guo, Gong Haotong, Xujun Wei, Yanwei Fu, Yizhou Yu, Wenqiang Zhang, and Weifeng Ge. 2023. Rankdnn: Learning to rank for few-shot learning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 37. 728–736
2023
-
[25]
Zhian He and Eric Lo. 2014. Answering Why-Not Questions on Top-K Queries. IEEE Transactions on Knowledge and Data Engineering26, 6 (2014), 1300–1315
2014
-
[26]
Maria Heuss, Maarten de Rijke, and Avishek Anand. 2025. RankingSHAP-Faithful Listwise Feature Attribution Explanations for Ranking Models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 381–391
2025
-
[27]
Taylor Kessler Faulkner, Will Brackenbury, and Ashwin Lall. 2015. K-regret queries with nonlinear utilities.Proceedings of the VLDB Endowment8, 13 (2015)
2015
-
[28]
Subhash Khot, Guy Kindler, Elchanan Mossel, and Ryan O’Donnell. 2007. Optimal inapproximability results for MAX-CUT and other 2-variable CSPs?SIAM J. Comput.37, 1 (2007), 319–357
2007
-
[29]
Hsiang-Tsung Kung, Fabrizio Luccio, and Franco P Preparata. 1975. On finding the maxima of a set of vectors.Journal of the ACM (JACM)22, 4 (1975), 469–476
1975
-
[30]
Chiyan Lee, Hideyuki Hasegawa, and Shangce Gao. 2022. Complex-Valued Neural Networks: A Comprehensive Survey.IEEE/CAA Journal of Automatica Sinica 9 (2022), 1406–1426. https://api.semanticscholar.org/CorpusID:251324986
2022
-
[31]
Hao Liu, Raymond Chi-Wing Wong, Zheng Zhang, Min Xie, and Bo Tang. 2024. Fair Top-k Query on Alpha-Fairness. InICDE 2024. IEEE, 2338–2350
2024
-
[32]
Qing Liu, Yunjun Gao, Gang Chen, Baihua Zheng, and Linlin Zhou. 2016. Answering why-not and why questions on reverse top-k queries.The VLDB Journal25, 6 (2016), 867–892
2016
-
[33]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4768–4777
2017
-
[34]
Michael Mathioudakis, Carlos Castillo, Giorgio Barnabo, and Sergio Celis. 2020. Affirmative action policies for top-k candidates selection: with an application to the design of policies for university admissions. InACM SAC 2020
2020
-
[35]
Dastan Maulud and Adnan M Abdulazeez. 2020. A review on linear regression comprehensive in machine learning.Journal of applied science and technology trends1, 2 (2020), 140–147
2020
-
[36]
Nimrod Megiddo. 1984. Linear programming in linear time when the dimension is fixed.Journal of the ACM (JACM)31, 1 (1984), 114–127
1984
-
[37]
Marco Morik, Ashudeep Singh, Jessica Hong, and Thorsten Joachims. 2020. Controlling fairness and bias in dynamic learning-to-rank. InSIGIR 2020. 429–438
2020
-
[38]
Danupon Nanongkai, Ashwin Lall, Atish Das Sarma, and Kazuhisa Makino. 2012. Interactive regret minimization. InSIGMOD 2012. 109–120
2012
-
[39]
Danupon Nanongkai, Atish Das Sarma, Ashwin Lall, Richard J Lipton, and Jun Xu. 2010. Regret-minimizing representative databases.PVLDB 2010(2010)
2010
-
[40]
Ryan O’Donnell, Yi Wu, and Yuan Zhou. 2011. Hardness of Max-2Lin and Max-3Lin over integers, reals, and large cyclic groups. InIEEE CCC 2011. IEEE
2011
-
[41]
Jianzhong Qi, Fei Zuo, Hanan Samet, and Jia Cheng Yao. 2018. K-regret queries using multiplicative utility functions.ACM TODS 2018(2018)
2018
-
[42]
Li Qian, Jinyang Gao, and HV Jagadish. 2015. Learning user preferences by adaptive pairwise comparison.Proceedings of the VLDB Endowment8, 11 (2015), 1322–1333
2015
-
[43]
Miroslav Rada and Michal Cerny. 2018. A new algorithm for enumeration of cells of hyperplane arrangements and a comparison with Avis and Fukuda’s reverse search.SIAM Journal on Discrete Mathematics32, 1 (2018), 455–473
2018
-
[44]
Theresia Veronika Rampisela, Tuukka Ruotsalo, Maria Maistro, and Christina Lioma. 2024. Can we trust recommender system fairness evaluation? the role of fairness and relevance. InSIGIR 2024. 271–281
2024
-
[45]
Why should I trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " Why should I trust you?" Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining
2016
-
[46]
2022.Convex cones: geometry and probability
Rolf Schneider. 2022.Convex cones: geometry and probability. Vol. 2319. Springer
2022
-
[47]
Procheta Sen, Debasis Ganguly, Manisha Verma, and Gareth JF Jones. 2020. The curious case of IR explainability: Explaining document scores within and across ranking models. InSIGIR 2020. 2069–2072
2020
-
[48]
regret-minimizing representative
Suraj Shetiya, Abolfazl Asudeh, Sadia Ahmed, and Gautam Das. 2019. A unified optimization algorithm for solving" regret-minimizing representative" problems. Proceedings of the VLDB Endowment13, 3 (2019)
2019
-
[49]
Suraj Shetiya, Ian P Swift, Abolfazl Asudeh, and Gautam Das. 2022. Fairness-aware range queries for selecting unbiased data. InICDE 2022. IEEE
2022
-
[50]
Ashudeep Singh and Thorsten Joachims. 2019. Policy learning for fairness in ranking.Advances in neural information processing systems32 (2019)
2019
-
[51]
V Srinivasan. 1976. Linear programming computational procedures for ordinal regression.Journal of the ACM (JACM)23, 3 (1976), 475–487
1976
-
[52]
Sabine Storandt and Stefan Funke. 2019. Algorithms for average regret minimiza- tion. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 33
2019
-
[53]
Thibaut Thonet, Yagmur Gizem Cinar, Eric Gaussier, Minghan Li, and Jean-Michel Renders. 2022. Listwise learning to rank based on approximate rank indicators. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 8494–8502
2022
-
[54]
2017.Handbook of discrete and computational geometry
Csaba D Toth, Joseph O’Rourke, and Jacob E Goodman. 2017.Handbook of discrete and computational geometry. CRC press
2017
-
[55]
Manisha Verma and Debasis Ganguly. 2019. LIRME: locally interpretable ranking model explanation. InSIGIR 2019. 1281–1284
2019
-
[56]
Akrivi Vlachou, Christos Doulkeridis, Yannis Kotidis, and Kjetil Nørvåg. 2010. Reverse top-k queries. InICDE 2010. IEEE, 365–376
2010
-
[57]
Weicheng Wang, Raymond Chi-Wing Wong, HV Jagadish, and Min Xie. 2024. Reverse regret query. InICDE 2024. IEEE
2024
-
[58]
Weicheng Wang, Raymond Chi-Wing Wong, Jinyang Li, and HV Jagadish. 2025. Interactive Learning for Diverse Top-k Set. InICDE 2025. IEEE Computer Society
2025
-
[59]
Weicheng Wang, Raymond Chi-Wing Wong, and Min Xie. 2021. Interactive search for one of the top-k. InSIGMOD 2021
2021
-
[60]
Dong Xin, Jiawei Han, Hong Cheng, and Xiaolei Li. 2006. Answering top-k queries with multi-dimensional selections: The ranking cube approach. InVLDB. VLDB Endowment, Seattle, WA, USA, 463–475
2006
-
[61]
Guangyi Zhang, Nikolaj Tatti, and Aristides Gionis. 2023. Finding favourite tuples on data streams with provably few comparisons. InACM SIGKDD 2023. Appendix A Additional experimental details We additionally performed experiments where the tuple feature components and weight vector components are sampled from a Zeta Explaining Rankings with Hidden Group B...
2023
-
[62]
bonus dimension
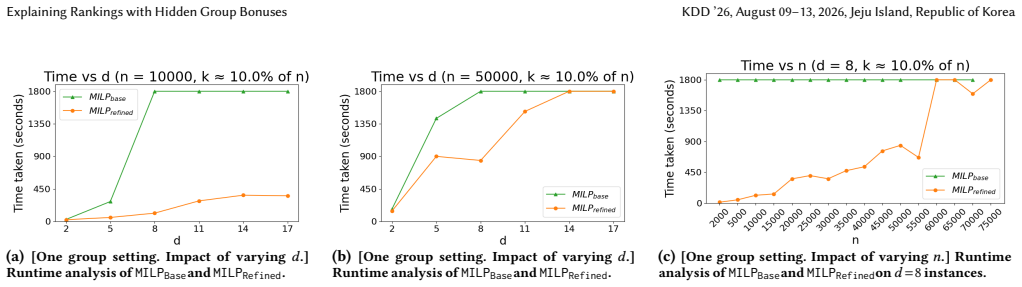
computes a Linear Program with𝑑 variables and 𝑛2 constraints in every cell. Meggido [ 36] proposes a linear-time algorithm for solving an LP in fixed dimension𝑑. Combining the two results, the enumeration process consumes a total ofO (𝑛2𝑑)time. In every region, using the weight vector returned by the LP, the scores for the 𝑛 tuples are computed in O (𝑛𝑑) ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.