How Much Is a Dataset Worth? Scaling Laws, the Vendi Score, and Matrix Spectral Functions
Pith reviewed 2026-06-29 08:30 UTC · model grok-4.3
The pith
Neural scaling law objectives and the Vendi Score are both submodular, with the Vendi Score as a special case of matrix spectral functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show both that common neural-scaling-law objectives and the Vendi Score are submodular. We further show that the Vendi Score is a special case of a broader class of submodular objectives that we call matrix spectral functions. This also includes determinantal (DPP) objectives, as well as many others. We also introduce weakly matrix monotone functions and show how they lead to weakly submodular matrix spectral functions, yielding a broad family of practical objectives for data appraisal. We develop secular-equation-based updates that avoid repeated eigendecompositions during greedy optimization, reducing marginal-gain evaluation for m-dimensional embeddings by an O(m) factor relative to or
What carries the argument
Matrix spectral functions, the class of submodular objectives obtained by applying a function to the eigenvalues of a matrix representation of the dataset and used for data appraisal.
If this is right
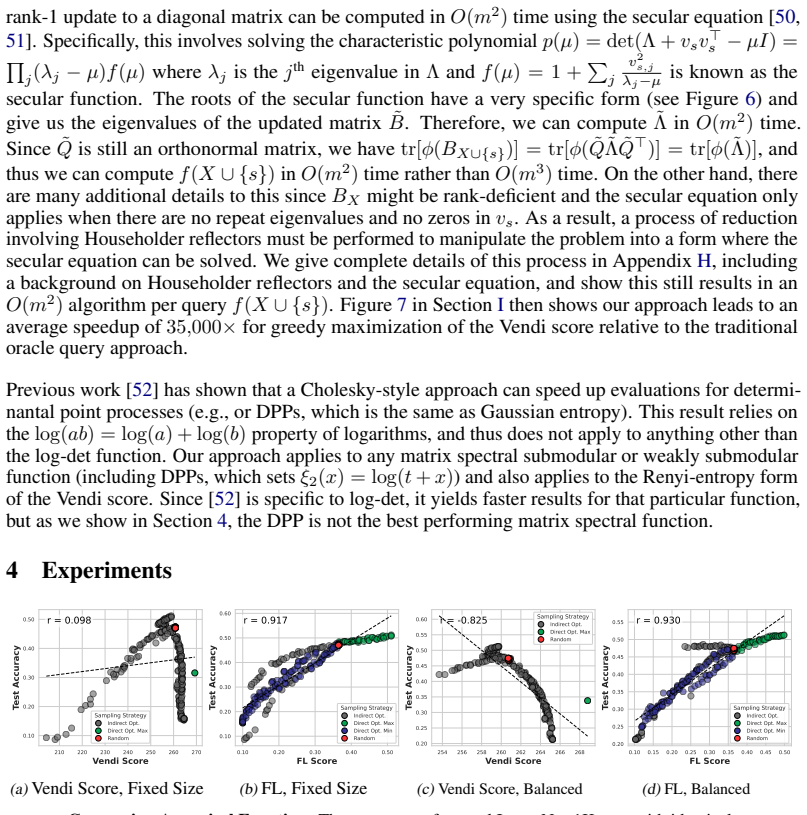
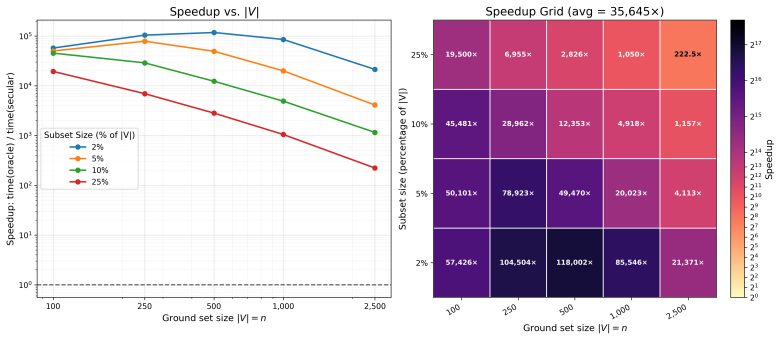
- Secular-equation updates make direct greedy optimization of the Vendi Score feasible on ImageNet-1K with an average 35,000x speedup.
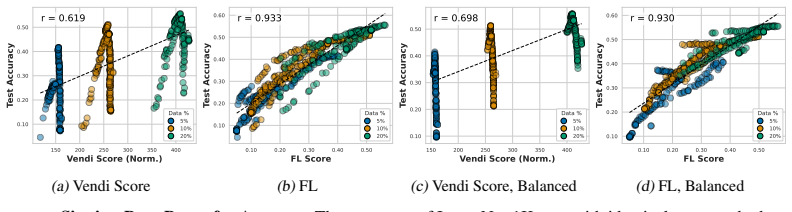
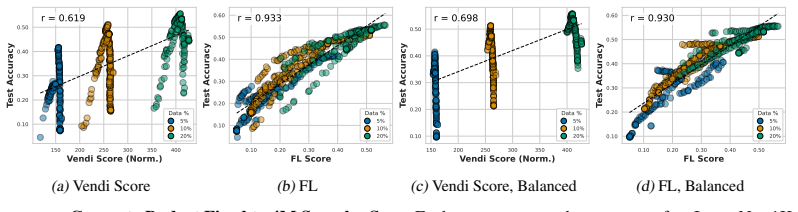
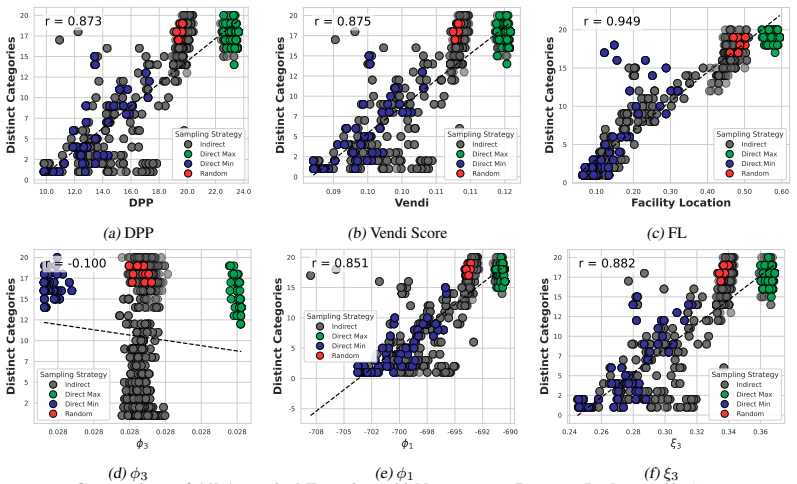
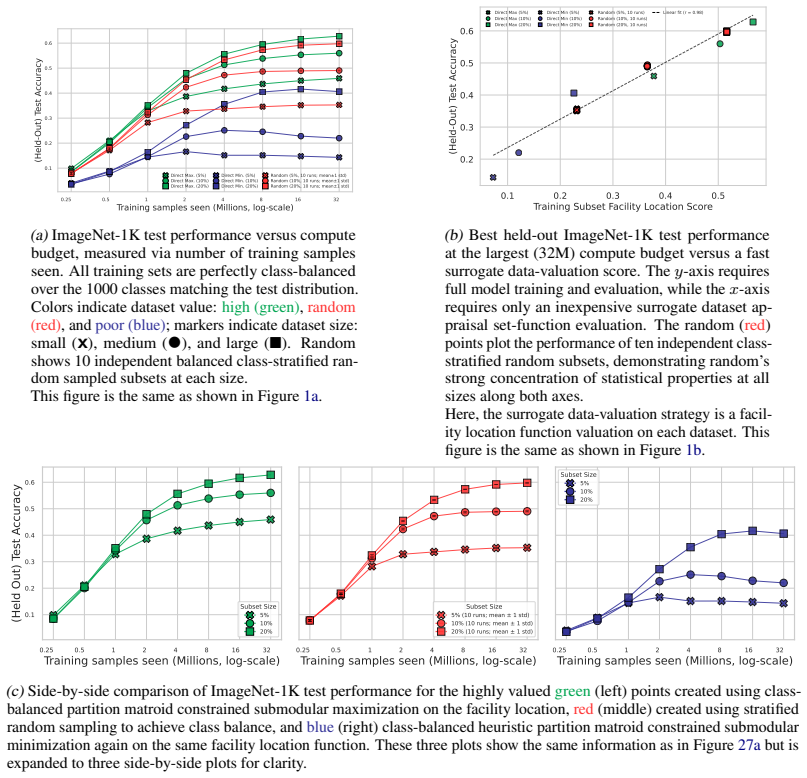
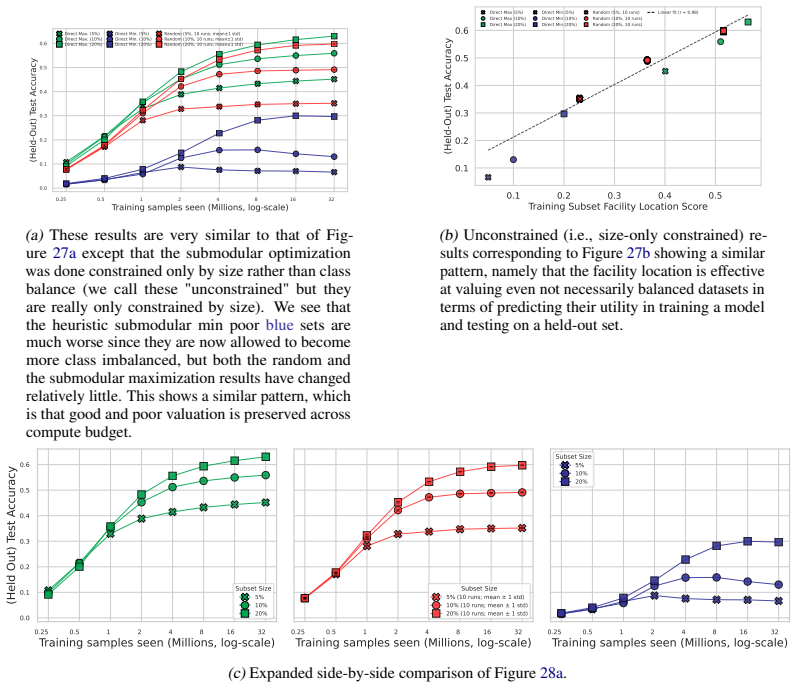
- Among the tested objectives, facility location best predicts held-out test performance under fixed-size, class-balanced, and fixed-budget regimes.
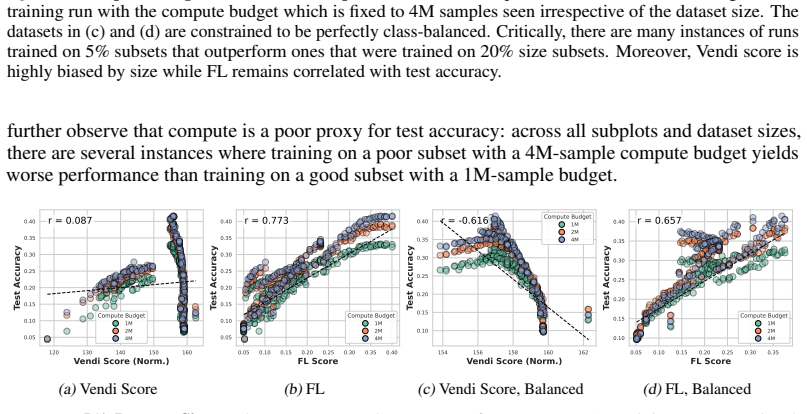
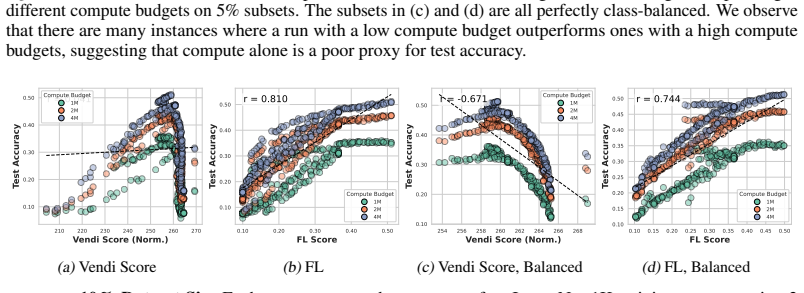
- The Vendi Score correlates with downstream performance over moderate ranges but becomes a poor proxy once pushed to higher values.
- Uniformly random fixed-size subsets, both unconstrained and class-balanced, exhibit tight concentration in both appraisal scores and held-out accuracy.
- Even after controlling for dataset size, class balance, and training budget, held-out performance still varies smoothly from good to bad.
Where Pith is reading between the lines
- Submodularity supplies approximation guarantees for greedy selection that could be applied directly to dataset curation pipelines.
- The same matrix spectral construction may extend to data valuation in active learning or self-supervised regimes where kernel matrices are already computed.
- The observed concentration of random subsets suggests that simple sampling may already achieve near-optimal appraisal scores in many practical settings.
- Weakly matrix monotone functions offer a route to design new objectives that align more closely with a target loss or architecture.
Load-bearing premise
That maximizing these submodular matrix spectral objectives by greedy selection will reliably identify subsets with better held-out test performance.
What would settle it
An experiment showing that, on multiple standard image datasets, greedy subsets chosen to maximize the Vendi Score or other matrix spectral functions achieve no higher held-out accuracy than class-balanced random sampling of the same size.
Figures


















read the original abstract
Neural scaling laws appraise data through dataset size, while the Vendi Score uses quantum entropy to measure dataset value. We show both that common neural-scaling-law objectives and the Vendi Score are submodular. We further show that the Vendi Score is a special case of a broader class of submodular objectives that we call matrix spectral functions. This also includes determinantal (DPP) objectives, as well as many others. We also introduce weakly matrix monotone functions and show how they lead to weakly submodular matrix spectral functions, yielding a broad family of practical objectives for data appraisal. We develop secular-equation-based updates that avoid repeated eigendecompositions during greedy optimization, reducing marginal-gain evaluation for $m$-dimensional embeddings by an $O(m)$ factor relative to oracle queries. This yields an average empirical speedup of about 35,000x, making direct optimization of the Vendi Score feasible on ImageNet-1K-scale datasets. Thus enabled, we compare how well several objectives predict the value of training subsets for held-out test performance under fixed-size, class-balanced, and fixed training-budget regimes, including the Vendi Score, DPPs, facility location, and three new matrix spectral variants. Across multiple datasets, facility location performs the best. Direct optimization also reveals that, while the Vendi Score is predictive over moderate score ranges, pushing the objective to higher values can make it a poor downstream performance proxy. We also find that uniformly at random fixed-size subsets, both unconstrained and class-balanced, are remarkably concentrated in both appraisal scores and held-out performance. Finally, we show that size, class balance, and training budget do not alone determine data value: even when controlling for these factors, performance ranges smoothly from good to bad.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that common neural scaling-law objectives and the Vendi Score are submodular, that the Vendi Score belongs to the broader class of matrix spectral functions (extended via newly introduced weakly matrix monotone functions), develops secular-equation updates that reduce the cost of marginal-gain computations by an O(m) factor, and empirically compares several such objectives (including facility location, DPPs, and new matrix-spectral variants) for their ability to select training subsets that predict held-out performance under fixed-size, class-balanced, and fixed-budget regimes on multiple datasets, finding facility location strongest while noting that Vendi Score degrades at high values and that random subsets are concentrated.
Significance. If the derivations and empirical rankings hold, the work supplies a unifying submodular framework that connects scaling laws with diversity measures and supplies practical, scalable algorithms for data appraisal. The reported 35,000x average speedup and the finding that size/balance/budget do not solely determine value are concrete contributions that could affect data-selection practice.
major comments (2)
- [empirical comparisons section] Empirical comparisons section (fixed-size, class-balanced, and fixed training-budget regimes): the ranking that facility location performs best rests on point estimates of held-out performance; without reported standard deviations across random seeds, confidence intervals, or statistical tests, it is unclear whether the observed differences are reliable or could be explained by sampling variability.
- [weakly matrix monotone functions section] § on weakly matrix monotone functions and weak submodularity: the central extension from matrix monotonicity to weak submodularity for the family of matrix spectral functions is load-bearing for the claim of a 'broad family of practical objectives'; the manuscript should explicitly state the precise inequality that defines 'weakly' and verify it holds for the concrete functions (Vendi, DPP) used later.
minor comments (3)
- [abstract] Abstract: the phrase 'reducing marginal-gain evaluation for m-dimensional embeddings by an O(m) factor relative to oracle queries' should clarify whether the factor is worst-case, average-case, or observed; the reported 35,000x empirical speedup is useful but should be tied to a specific m and dataset size.
- [theoretical development] Notation for matrix spectral functions: ensure the definition of f(·) is stated once with all required domain assumptions (e.g., positive-semidefinite matrices, monotonicity conditions) before it is specialized to Vendi and DPP cases.
- [figures and tables] Figure captions and tables: all axes and columns should be labeled with explicit units or descriptions (e.g., 'held-out accuracy (%)' rather than 'accuracy'); legends should distinguish the three new matrix-spectral variants.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [empirical comparisons section] Empirical comparisons section (fixed-size, class-balanced, and fixed training-budget regimes): the ranking that facility location performs best rests on point estimates of held-out performance; without reported standard deviations across random seeds, confidence intervals, or statistical tests, it is unclear whether the observed differences are reliable or could be explained by sampling variability.
Authors: We agree that reporting variability across random seeds would strengthen the reliability of the empirical rankings. In the revised manuscript we will add standard deviations computed over multiple random seeds for the held-out performance metrics in all three regimes and will include paired statistical tests to assess whether the observed differences between objectives are significant. revision: yes
-
Referee: [weakly matrix monotone functions section] § on weakly matrix monotone functions and weak submodularity: the central extension from matrix monotonicity to weak submodularity for the family of matrix spectral functions is load-bearing for the claim of a 'broad family of practical objectives'; the manuscript should explicitly state the precise inequality that defines 'weakly' and verify it holds for the concrete functions (Vendi, DPP) used later.
Authors: We will revise the section to state the precise inequality that defines weak submodularity. We will also add a short verification (via direct substitution into the inequality) confirming that both the Vendi Score and the DPP objective satisfy the weak-submodularity condition. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's derivation chain consists of algebraic proofs establishing submodularity for neural scaling-law objectives and the Vendi Score, along with showing the latter as a special case of matrix spectral functions via the introduced concept of weakly matrix monotone functions. These steps rely on standard definitions and properties of submodular set functions and matrix spectral functions rather than any self-referential definitions, fitted parameters from the appraised data, or load-bearing self-citations. The secular-equation updates are presented as an independent algorithmic contribution for efficient greedy optimization. Empirical sections test downstream predictive utility but do not participate in or circularly justify the theoretical claims. The central results are therefore self-contained mathematical statements.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard algebraic properties of submodular functions and matrix spectral functions
invented entities (1)
-
weakly matrix monotone functions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fujishige, S.Submodular functions and optimization. V ol. 58. Elsevier, 2005 (cit. on pp. 2, 11, 18, 19, 21, 22)
2005
-
[2]
Submodularity in machine learning and artificial intelligence
Bilmes, J. “Submodularity in machine learning and artificial intelligence”. In:arXiv preprint arXiv:2202.00132(2022) (cit. on pp. 2, 7, 18, 19, 22, 67)
-
[3]
Submodularity in action: From machine learning to signal processing applications
Tohidi, E., Amiri, R., Coutino, M., Gesbert, D., Leus, G., and Karbasi, A. “Submodularity in action: From machine learning to signal processing applications”. In:IEEE Signal Processing Magazine37.5 (2020), pp. 120–133 (cit. on pp. 2, 18, 19)
2020
-
[4]
The Vendi Score: A Diversity Evaluation Metric for Machine Learning
Friedman, D. and Dieng, A. B. “The Vendi Score: A Diversity Evaluation Metric for Machine Learning”. In:Transactions on Machine Learning Research(2023) (cit. on pp. 2, 6, 26)
2023
-
[5]
Cousins Of The Vendi Score: A Family Of Similarity-Based Diversity Metrics For Science And Machine Learning
Pasarkar, A. P. and Dieng, A. B. “Cousins Of The Vendi Score: A Family Of Similarity-Based Diversity Metrics For Science And Machine Learning”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2024, pp. 3808–3816 (cit. on pp. 2, 6, 26)
2024
-
[6]
Vendi Novelty Scores for Out-of-Distribution Detection
Pasarkar, A. P. and Dieng, A. B. “Vendi Novelty Scores for Out-of-Distribution Detection”. In:arXiv preprint arXiv:2602.10062(2026) (cit. on pp. 2, 6, 26)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Prismatic synthesis: Gradient-based data diversification boosts generalization in llm reasoning
Jung, J. et al. “Prismatic synthesis: Gradient-based data diversification boosts generalization in llm reasoning”. In:arXiv preprint arXiv:2505.20161(2025) (cit. on pp. 2, 6, 9, 10, 26, 60, 63, 64)
-
[8]
Vendi information gain: An alternative to mutual information for science and machine learning
Nguyen, Q. and Dieng, A. B. “Vendi information gain: An alternative to mutual information for science and machine learning”. In:arXiv preprint arXiv:2505.09007(2025) (cit. on pp. 2, 6, 26)
-
[9]
Diversity You Can Actually Measure: A Fast, Model-Free Diversity Metric for Robotics Datasets
Sirigiri, S., Lara, N. S. de, Agia, C., Shkurti, F., and Ramos, F. “Diversity You Can Actually Measure: A Fast, Model-Free Diversity Metric for Robotics Datasets”. In:arXiv preprint arXiv:2603.11634(2026) (cit. on pp. 2, 6, 26)
-
[10]
Conditional Vendi Score: Prompt-Aware Diversity Evaluation for Generative AI Models and LLMs
Jalali, M., Ospanov, A., Gohari, A., and Farnia, F. “Conditional Vendi Score: Prompt-Aware Diversity Evaluation for Generative AI Models and LLMs”. In:The 29th International Conference on Artificial Intelligence and Statistics. 2026.URL: https://openreview. net/forum?id=iDrZToIsyd(cit. on pp. 2, 6, 26)
2026
-
[11]
Quantum information theory
Bennett, C. H. and Shor, P. W. “Quantum information theory”. In:IEEE transactions on information theory44.6 (2002), pp. 2724–2742 (cit. on pp. 2, 55)
2002
-
[12]
Springer Science & Business Media, 2007 (cit
Petz, D.Quantum information theory and quantum statistics. Springer Science & Business Media, 2007 (cit. on pp. 2, 55)
2007
-
[13]
Nielsen, M. A. and Chuang, I. L.Quantum computation and Quantum information. Cam- bridge university press, 2010 (cit. on pp. 2, 55). 12
2010
-
[14]
Generalized submodular information measures: Theoretical properties, examples, optimization algorithms, and applications
Iyer, R., Khargonkar, N., Bilmes, J., and Asnani, H. “Generalized submodular information measures: Theoretical properties, examples, optimization algorithms, and applications”. In: IEEE Transactions on Information Theory68.2 (2021), pp. 752–781 (cit. on p. 2)
2021
-
[15]
Deep Learning Scaling is Predictable, Empirically
Hestness, J. et al.Deep Learning Scaling Is Predictable, Empirically. arXiv preprint arXiv:1712.00409. 2017.URL:https://arxiv.org/abs/1712.00409(cit. on p. 3)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Scaling Laws for Neural Language Models
Kaplan, J. et al.Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361. 2020.URL:https://arxiv.org/abs/2001.08361(cit. on p. 3)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[17]
Training Compute-Optimal Large Language Models
Hoffmann, J. et al. “Training Compute-Optimal Large Language Models”. In:arXiv preprint arXiv:2203.15556(2022).URL:https://arxiv.org/abs/2203.15556(cit. on p. 3)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
and Song, J.Reconciling Kaplan and Chinchilla Scaling Laws
Pearce, T. and Song, J.Reconciling Kaplan and Chinchilla Scaling Laws. 2024.URL: https: //arxiv.org/abs/2406.12907(cit. on p. 3)
-
[19]
2025.URL: https://arxiv.org/abs/ 2406.19146(cit
Porian, T., Wortsman, M., Jitsev, J., Schmidt, L., and Carmon, Y .Resolving Discrepancies in Compute-Optimal Scaling of Language Models. 2025.URL: https://arxiv.org/abs/ 2406.19146(cit. on p. 3)
-
[20]
et al.Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
Dey, N. et al.Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster. 2023.URL: https://arxiv.org/abs/2304.03208 (cit. on p. 3)
-
[21]
Will we run out of data? Limits of LLM scaling based on human-generated data
Villalobos, P., Ho, A., Sevilla, J., Besiroglu, T., Heim, L., and Hobbhahn, M. “Will we run out of data? Limits of LLM scaling based on human-generated data”. In:Forty-first International Conference on Machine Learning. 2024 (cit. on p. 3)
2024
-
[22]
Office, E. C. D. S.General Purpose AI Models and Systemic Risk — FAQ (AI Act). Online FAQ / policy website. 2025.URL: https://digital- strategy.ec.europa.eu/en/ faqs/general-purpose-ai-models-ai-act-questions-answers(cit. on p. 3)
2025
-
[23]
Business Insider, Oct
Tan, H.The AI boom has already run out of human-made training data, Goldman’s data chief says. Business Insider, Oct. 2025.URL: https://www.businessinsider.com/ai-boom- has-run-out-of-human-made-training-data-goldman-2025-10(cit. on p. 3)
2025
-
[24]
C.Copyright and Artificial Intelligence, Part 3: Generative AI Training (Pre- Publication Version)
Office, U. C.Copyright and Artificial Intelligence, Part 3: Generative AI Training (Pre- Publication Version). U.S. Copyright Office Report. 2025.URL: https://www.copyright. gov / ai /Copyright - and - Artificial- Intelligence - Part - 3 - Generative - AI - Training-Report-Pre-Publication-Version.pdf(cit. on p. 3)
2025
-
[25]
et al.AutoScale: Scale-Aware Data Mixing for Pre-Training LLMs
Kang, F. et al.AutoScale: Scale-Aware Data Mixing for Pre-Training LLMs. 2025.URL: https://arxiv.org/abs/2407.20177(cit. on p. 4)
-
[26]
Scaling Laws for Data Filtering–Data Curation cannot be Compute Agnostic
Goyal, S., Maini, P., Lipton, Z. C., Raghunathan, A., and Kolter, J. Z. “Scaling Laws for Data Filtering–Data Curation cannot be Compute Agnostic”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 22702–22711 (cit. on pp. 4, 5, 11, 23)
2024
-
[27]
A Bitter Lesson for Data Filtering
Mohri, C., Duchi, J., and Hashimoto, T. “A Bitter Lesson for Data Filtering”. In:arXiv preprint arXiv:2605.19407(2026) (cit. on pp. 4, 11)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Über monotone matrixfunktionen
Löwner, K. “Über monotone matrixfunktionen”. In:Mathematische Zeitschrift38.1 (1934), pp. 177–216 (cit. on pp. 5, 27)
1934
-
[29]
and Tismenetsky, M.The theory of matrices: with applications
Lancaster, P. and Tismenetsky, M.The theory of matrices: with applications. Elsevier, 1985 (cit. on p. 5)
1985
-
[30]
Springer Science & Business Media, 1997 (cit
Bhatia, R.Matrix analysis. Springer Science & Business Media, 1997 (cit. on pp. 5, 6)
1997
-
[31]
J.Functions of matrices: theory and computation
Higham, N. J.Functions of matrices: theory and computation. SIAM, 2008 (cit. on p. 5)
2008
-
[32]
Positive definite matrices
Bhatia, R. “Positive definite matrices”. In:Positive Definite Matrices. Princeton university press, 2009 (cit. on pp. 5, 27)
2009
-
[33]
Submodular spectral functions of principal submatrices of a hermitian matrix, extensions and applications
Friedland, S and Gaubert, S. “Submodular spectral functions of principal submatrices of a hermitian matrix, extensions and applications”. In:Linear Algebra and its Applications (2011) (cit. on pp. 5, 6, 31)
2011
-
[34]
Strongly subadditive functions
Audenaert, K., Hiai, F., and Petz, D. “Strongly subadditive functions”. In:Acta Mathematica Hungarica128.4 (2010), pp. 386–394 (cit. on pp. 5, 6, 31)
2010
-
[35]
A family of monotone quantum relative entropies
Lewin, M. and Sabin, J. “A family of monotone quantum relative entropies”. In:Letters in Mathematical Physics104.6 (2014), pp. 691–705 (cit. on pp. 5, 6, 31)
2014
-
[36]
Monotone and convex operator functions
Bendat, J. and Sherman, S. “Monotone and convex operator functions”. In:Transactions of the American Mathematical Society79.1 (1955), pp. 58–71 (cit. on pp. 5, 27). 13
1955
-
[37]
Loewner matrices and operator convexity
Bhatia, R. and Sano, T. “Loewner matrices and operator convexity”. In:Mathematische Annalen344.3 (2009), pp. 703–716 (cit. on pp. 6, 27)
2009
-
[38]
Simon, B.Loewner’s theorem on monotone matrix functions. V ol. 10. Springer, 2019 (cit. on pp. 6, 27)
2019
-
[39]
Determinantal point processes for machine learning
Kulesza, A. and Taskar, B. “Determinantal point processes for machine learning”. In:Foun- dations and Trends® in Machine Learning5.2-3 (2012), pp. 123–286 (cit. on p. 6)
2012
-
[40]
The vendi score: A diversity evaluation metric for machine learning
Friedman, D. and Dieng, A. B. “The vendi score: A diversity evaluation metric for machine learning”. In:arXiv preprint arXiv:2210.02410(2022) (cit. on p. 6)
-
[41]
Proof of the strong subadditivity of quantum-mechanical entropy
Lieb, E. H. and Ruskai, M. B. “Proof of the strong subadditivity of quantum-mechanical entropy”. In:Les rencontres physiciens-mathématiciens de Strasbourg-RCP2519 (1973), pp. 36–55 (cit. on pp. 7, 55)
1973
-
[42]
Optimal approximation for unconstrained non-submodular minimization
El Halabi, M. and Jegelka, S. “Optimal approximation for unconstrained non-submodular minimization”. In:International Conference on Machine Learning. PMLR. 2020, pp. 3961– 3972 (cit. on pp. 7, 20)
2020
-
[43]
Combinatorial auctions with decreasing marginal utilities
Lehmann, B., Lehmann, D., and Nisan, N. “Combinatorial auctions with decreasing marginal utilities”. In:Proceedings of the 3rd ACM conference on Electronic Commerce. 2001, pp. 18– 28 (cit. on pp. 7, 20)
2001
-
[44]
MIT press, 2007 (cit
Bottou, L.Large-scale kernel machines. MIT press, 2007 (cit. on pp. 8, 30)
2007
-
[45]
Kernels and reproducing kernel hilbert spaces
Steinwart, I. and Christmann, A. “Kernels and reproducing kernel hilbert spaces”. In:Support Vector Machines. Springer, 2008, pp. 110–163 (cit. on pp. 8, 30)
2008
-
[46]
and Smola, A
Schölkopf, B. and Smola, A. J.Learning with kernels: support vector machines, regulariza- tion, optimization, and beyond. MIT press, 2002 (cit. on pp. 8, 30, 68)
2002
-
[47]
Williams, C. K. and Rasmussen, C. E.Gaussian processes for machine learning. V ol. 2. 3. MIT press Cambridge, MA, 2006 (cit. on pp. 8, 30)
2006
-
[48]
Accelerated greedy algorithms for maximizing submodular set functions
Minoux, M. “Accelerated greedy algorithms for maximizing submodular set functions”. In: Optimization Techniques. Ed. by Stoer, J. V ol. 7. Lecture Notes in Control and Information Sciences. Springer Berlin / Heidelberg, 1978, pp. 234–243.URL: http://dx.doi.org/10. 1007/BFb0006528(cit. on pp. 8, 53)
1978
-
[49]
A Memoization Framework for Scaling Submodular Optimization to Large Scale Problems
Iyer, R. and Bilmes, J. “A Memoization Framework for Scaling Submodular Optimization to Large Scale Problems”. In:Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics. Ed. by Chaudhuri, K. and Sugiyama, M. V ol. 89. Proceedings of Machine Learning Research. PMLR, 2019, pp. 2340–2349.URL: https: //proceedings....
2019
-
[50]
Rank-one modification of the symmetric eigenproblem
Bunch, J. R., Nielsen, C. P., and Sorensen, D. C. “Rank-one modification of the symmetric eigenproblem”. In:Numerische Mathematik31.1 (1978), pp. 31–48 (cit. on pp. 9, 43, 49)
1978
-
[51]
W.Applied numerical linear algebra
Demmel, J. W.Applied numerical linear algebra. SIAM, 1997 (cit. on pp. 9, 42, 43, 47–49)
1997
-
[52]
Fast greedy map inference for determinantal point process to improve recommendation diversity
Chen, L., Zhang, G., and Zhou, E. “Fast greedy map inference for determinantal point process to improve recommendation diversity”. In:Advances in neural information processing systems 31 (2018) (cit. on pp. 9, 72)
2018
-
[53]
Lazier than lazy greedy
Mirzasoleiman, B., Badanidiyuru, A., Karbasi, A., V ondrák, J., and Krause, A. “Lazier than lazy greedy”. In:Proceedings of the AAAI Conference on Artificial Intelligence. V ol. 29. 1. 2015 (cit. on pp. 9, 59)
2015
-
[54]
Size-constrained submodular minimization through minimum norm base
Nagano, K., Kawahara, Y ., and Aihara, K. “Size-constrained submodular minimization through minimum norm base”. In:Proceedings of the 28th International Conference on Machine Learning (ICML-11). 2011, pp. 977–984 (cit. on pp. 11, 21)
2011
-
[55]
An end-to-end submodular frame- work for data-efficient in-context learning
Kumari, L., Wang, S., Das, A., Zhou, T., and Bilmes, J. “An end-to-end submodular frame- work for data-efficient in-context learning”. In:Findings of the Association for Computational Linguistics: NAACL 2024. 2024, pp. 3293–3308 (cit. on p. 18)
2024
-
[56]
Bumblebee: Dynamic kv-cache streaming submodular summarization for infinite-context transformers
Kumari, L., Wang, S., Zhou, T., Sarda, N., Rowe, A., and Bilmes, J. “Bumblebee: Dynamic kv-cache streaming submodular summarization for infinite-context transformers”. In:First Conference on Language Modeling. 2024 (cit. on p. 18)
2024
-
[57]
M.Supermodularity and complementarity
Topkis, D. M.Supermodularity and complementarity. Princeton university press, 1998 (cit. on p. 19)
1998
-
[58]
An analysis of approximations for maximizing submodular set functions—I
Nemhauser, G. L., Wolsey, L. A., and Fisher, M. L. “An analysis of approximations for maximizing submodular set functions—I”. In:Mathematical programming14.1 (1978), pp. 265–294 (cit. on pp. 19, 26). 14
1978
-
[59]
How to Select a Good Training-data Subset for Transcription: Sub- modular Active Selection for Sequences
Lin, H. and Bilmes, J. A. “How to Select a Good Training-data Subset for Transcription: Sub- modular Active Selection for Sequences”. In:Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH). Brighton, UK, 2009 (cit. on p. 19)
2009
-
[60]
Graph-based Submodular Selection for Extractive Summa- rization
Lin, H., Bilmes, J., and Xie, S. “Graph-based Submodular Selection for Extractive Summa- rization”. In:Proc. IEEE Automatic Speech Recognition and Understanding (ASRU). Merano, Italy, 2009 (cit. on p. 19)
2009
-
[61]
A Class of Submodular Functions for Document Summarization
Lin, H. and Bilmes, J. “A Class of Submodular Functions for Document Summarization”. In: The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL/HLT-2011). Portland, OR, 2011 (cit. on p. 19)
2011
-
[62]
Geometric approximation via coresets
Agarwal, P. K., Har-Peled, S., Varadarajan, K. R., et al. “Geometric approximation via coresets”. In:Combinatorial and computational geometry52.1 (2005), pp. 1–30 (cit. on p. 19)
2005
-
[63]
Coresets for Data-efficient Training of Machine Learning Models
Mirzasoleiman, B., Bilmes, J., and Leskovec, J. “Coresets for Data-efficient Training of Machine Learning Models”. In:Proceedings of the 37th International Conference on Machine Learning. 2020 (cit. on pp. 19, 22)
2020
-
[64]
Submodular meets spectral: greedy algorithms for subset selection, sparse approximation and dictionary selection
Das, A. and Kempe, D. “Submodular meets spectral: greedy algorithms for subset selection, sparse approximation and dictionary selection”. In:Proceedings of the 28th International Conference on International Conference on Machine Learning. 2011, pp. 1057–1064 (cit. on p. 20)
2011
-
[65]
Approximate submodularity and its applications: Subset selection, sparse approximation and dictionary selection
Das, A. and Kempe, D. “Approximate submodularity and its applications: Subset selection, sparse approximation and dictionary selection”. In:Journal of Machine Learning Research 19.3 (2018), pp. 1–34 (cit. on p. 20)
2018
-
[66]
Gradient methods for submodular maxi- mization
Hassani, H., Soltanolkotabi, M., and Karbasi, A. “Gradient methods for submodular maxi- mization”. In:Advances in Neural Information Processing Systems30 (2017) (cit. on p. 20)
2017
-
[67]
Combinatorial Penalties: Which structures are preserved by convex relaxations?
El Halabi, M., Bach, F., and Cevher, V . “Combinatorial Penalties: Which structures are preserved by convex relaxations?” In:Proceedings of the Twenty-First International Confer- ence on Artificial Intelligence and Statistics. Ed. by Storkey, A. and Perez-Cruz, F. V ol. 84. Proceedings of Machine Learning Research. PMLR, 2018, pp. 1551–1560.URL: https: //...
2018
-
[68]
Non-submodular function maximization subject to a matroid constraint, with applications
Gatmiry, K. and Gomez-Rodriguez, M. “Non-submodular function maximization subject to a matroid constraint, with applications”. In:arXiv preprint arXiv:1811.07863(2018) (cit. on p. 20)
-
[69]
Guarantees for greedy maximization of non-submodular functions with applications
Bian, A. A., Buhmann, J. M., Krause, A., and Tschiatschek, S. “Guarantees for greedy maximization of non-submodular functions with applications”. In:International conference on machine learning. PMLR. 2017, pp. 498–507 (cit. on p. 20)
2017
-
[70]
Combinatorial Penalties: Which structures are preserved by convex relaxations?
El Halabi, M., Bach, F., and Cevher, V . “Combinatorial Penalties: Which structures are preserved by convex relaxations?” In:International Conference on Artificial Intelligence and Statistics. PMLR. 2018, pp. 1551–1560 (cit. on p. 21)
2018
-
[71]
Robust maximization of non-submodular objectives
Bogunovic, I., Zhao, J., and Cevher, V . “Robust maximization of non-submodular objectives”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2018, pp. 890– 899 (cit. on p. 21)
2018
-
[72]
Online Software System
Bilmes, J.Submarine: SUBModularity for ARtificial INtelligencE and machine learning. Online Software System. 2026 (cit. on p. 21)
2026
-
[73]
Deep learning on a data diet: Finding important examples early in training
Paul, M., Ganguli, S., and Dziugaite, G. K. “Deep learning on a data diet: Finding important examples early in training”. In:Advances in neural information processing systems34 (2021), pp. 20596–20607 (cit. on p. 22)
2021
-
[74]
An Empirical Study of Example Forgetting during Deep Neural Network Learning
Toneva, M., Sordoni, A., Combes, R. Tachet des, Trischler, A., Bengio, Y ., and Gordon, G. J. “An Empirical Study of Example Forgetting during Deep Neural Network Learning”. In: International Conference on Learning Representations. 2019 (cit. on p. 22)
2019
-
[75]
The Impact of Coreset Selection on Spurious Correlations and Group Robustness
Dharmasiri, A., Yang, W., Kirichenko, P., Liu, L. T., and Russakovsky, O. “The Impact of Coreset Selection on Spurious Correlations and Group Robustness”. In:Advances in Neural Information Processing Systems, Datasets and Benchmarks Track. 2025 (cit. on p. 22)
2025
-
[76]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Sener, O. and Savarese, S. “Active Learning for Convolutional Neural Networks: A Core-Set Approach”. In:International Conference on Learning Representations. 2018 (cit. on p. 22). 15
2018
-
[77]
GRAD- MATCH: Gradient Matching Based Data Subset Selection for Efficient Deep Model Training
Killamsetty, K., Sivasubramanian, D., Ramakrishnan, G., De, A., and Iyer, R. “GRAD- MATCH: Gradient Matching Based Data Subset Selection for Efficient Deep Model Training”. In:Proceedings of the 38th International Conference on Machine Learning. 2021 (cit. on p. 22)
2021
-
[78]
GLISTER: General- ization Based Data Subset Selection for Efficient and Robust Learning
Killamsetty, K., Sivasubramanian, D., Ramakrishnan, G., and Iyer, R. “GLISTER: General- ization Based Data Subset Selection for Efficient and Robust Learning”. In:Proceedings of the AAAI Conference on Artificial Intelligence. 2021 (cit. on p. 22)
2021
-
[79]
Data Shapley: Equitable Valuation of Data for Machine Learning
Ghorbani, A. and Zou, J. “Data Shapley: Equitable Valuation of Data for Machine Learning”. In:Proceedings of the 36th International Conference on Machine Learning. 2019 (cit. on p. 22)
2019
-
[80]
Practical Coreset Constructions for Machine Learning
Bachem, O., Lucic, M., and Krause, A. “Practical Coreset Constructions for Machine Learn- ing”. In:arXiv preprint arXiv:1703.06476(2017) (cit. on p. 22)
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.