GiPL: Generative augmented iterative Pseudo-Labeling for Cross-Domain Few-Shot Object Detection
Pith reviewed 2026-06-29 08:39 UTC · model grok-4.3
The pith
GiPL improves cross-domain few-shot object detection by fusing iterative pseudo-labels with generative image synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
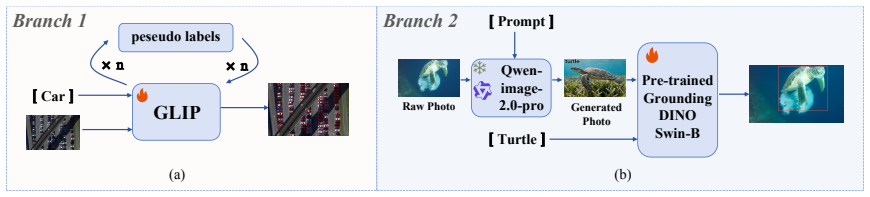
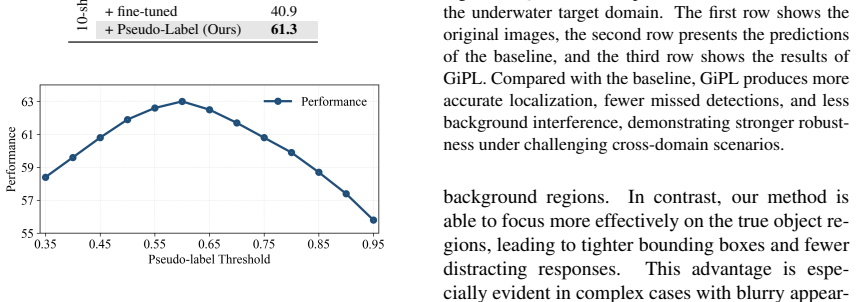
The GiPL framework consists of an iterative pseudo-label self-training branch that performs zero-shot inference on the support set, fuses the resulting pseudo-annotations with ground-truth labels, and repeatedly optimizes the detector, together with a generative data-augmentation branch that synthesizes domain-aligned multi-object images via large vision-language models; together these branches enable fuller use of limited target-domain data while suppressing overfitting, producing higher detection accuracy than existing cross-domain few-shot methods on the RUOD, CARPK, and CarDD benchmarks.
What carries the argument
Two-branch training framework whose first branch runs iterative pseudo-label self-training on the support set and whose second branch synthesizes additional training images with vision-language models.
If this is right
- Support sets with only single-instance annotations can be turned into richer training signals through repeated pseudo-label fusion.
- Synthesized multi-object images reduce the overfitting that occurs when fine-tuning on fewer than ten target-domain examples.
- The same two-branch recipe yields measurable gains on three distinct cross-domain benchmarks at every shot level tested.
- Vision-language models become practical backbones for few-shot detection once their zero-shot outputs are iteratively refined and their generative capacity is used for data expansion.
Where Pith is reading between the lines
- The generative branch could be swapped for other synthesis methods if the vision-language model itself is unavailable or too costly.
- The iterative pseudo-label loop might be applied to tasks beyond detection, such as instance segmentation, provided reliable zero-shot masks can be obtained.
- If the noise-filtering step inside the first branch is made explicit, the method could be tested for robustness on even noisier support sets.
- The overall pattern suggests that combining self-training with generative augmentation may generalize to other low-data transfer settings where domain shift is the dominant obstacle.
Load-bearing premise
Zero-shot inference on the support set yields pseudo-annotations accurate enough to fuse with ground-truth labels without adding damaging noise during iterative training.
What would settle it
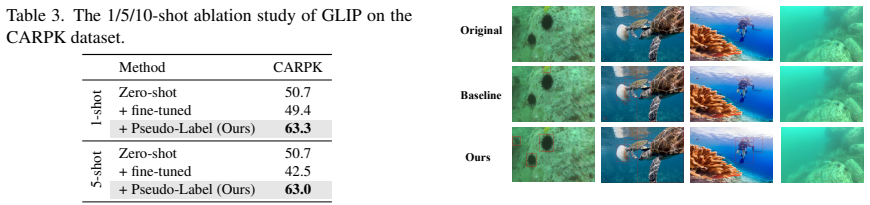
Running the same 1/5/10-shot experiments on RUOD, CARPK, or CarDD while disabling either the pseudo-label iteration or the generative augmentation branch and observing no accuracy gain or a drop relative to the published baselines would falsify the claim.
Figures

read the original abstract
Vision-language foundation models have shown promising zero-shot generalization for Cross-Domain Few-Shot Object Detection (CD-FSOD). However, they face two critical challenges in fine-tuning: insufficient support set utilization due to sparse single-instance annotations, and severe overfitting under extremely limited target-domain samples. To address these issues, this paper proposes GiPL, an efficient two-branch training framework. In the first branch, we design an iterative pseudo-label self-training paradigm, which performs zero-shot inference on the support set to generate reliable pseudo-annotations, fuses them with ground-truth labels, and iteratively optimizes the model to fully exploit support set data. In the second branch, we introduce generative data augmentation pipeline using large vision-language models, which synthesizes domain-aligned, multi-object annotated images to enrich training samples and suppress overfitting. Extensive experiments on three challenging CD-FSOD datasets (RUOD, CARPK, CarDD) under 1/5/10-shot settings demonstrate that GiPL consistently outperforms state-of-the-art methods with significant performance gains. Code is available at \href{https://github.com/z-yaz/CDiscover}{CDiscover}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GiPL, a two-branch framework for Cross-Domain Few-Shot Object Detection (CD-FSOD). Branch 1 performs zero-shot inference on the sparse support set to generate pseudo-annotations, fuses them with ground-truth labels, and iteratively optimizes the detector. Branch 2 uses large vision-language models to synthesize domain-aligned, multi-object images for data augmentation. Experiments on RUOD, CARPK, and CarDD under 1/5/10-shot regimes report consistent outperformance of prior SOTA methods; code is released.
Significance. If validated, the combination of iterative pseudo-label self-training with generative augmentation offers a practical route to mitigate both under-utilization of support data and overfitting in CD-FSOD. The explicit code release is a positive contribution to reproducibility. Significance is tempered by the absence of quantitative validation for the core premise that zero-shot pseudo-labels remain reliable after fusion.
major comments (3)
- [Abstract] Abstract: the assertion that zero-shot inference produces 'reliable pseudo-annotations' that can be fused with ground-truth labels without harmful noise is load-bearing for the central claim, yet the manuscript supplies no confidence thresholds, consistency checks across iterations, or measured pseudo-label precision/recall on the target support set.
- [Abstract] Abstract / Experiments: no ablation isolating the iterative pseudo-label branch from the generative augmentation branch is described, so it is impossible to determine whether reported gains on RUOD/CARPK/CarDD arise from the pseudo-label fusion, the generative data, or their interaction.
- [Method (first branch)] The description of the first branch states that pseudo-annotations are fused and used for iterative optimization, but provides no mechanism (e.g., per-iteration filtering or loss re-weighting) to control error propagation when the foundation model's zero-shot detections are domain-shifted.
minor comments (1)
- [Abstract] The abstract refers to 'three challenging CD-FSOD datasets' but does not list the exact shot settings or baseline methods compared; a concise table in the abstract or introduction would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, providing the strongest honest defense of the manuscript while committing to revisions where the concerns identify genuine gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that zero-shot inference produces 'reliable pseudo-annotations' that can be fused with ground-truth labels without harmful noise is load-bearing for the central claim, yet the manuscript supplies no confidence thresholds, consistency checks across iterations, or measured pseudo-label precision/recall on the target support set.
Authors: The manuscript does not provide direct quantitative validation such as precision/recall or confidence thresholds for the pseudo-annotations. The reported gains on RUOD, CARPK, and CarDD under multiple shot regimes serve as indirect empirical support that the fused labels are beneficial overall. To strengthen the claim, we will add an analysis section reporting pseudo-label precision/recall on the support sets and consistency metrics across iterations in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract / Experiments: no ablation isolating the iterative pseudo-label branch from the generative augmentation branch is described, so it is impossible to determine whether reported gains on RUOD/CARPK/CarDD arise from the pseudo-label fusion, the generative data, or their interaction.
Authors: We agree that the absence of branch-isolated ablations limits interpretability of the gains. The current results demonstrate the full GiPL framework, but we will add dedicated ablation experiments in the revised version, including performance with the pseudo-label branch alone and the generative branch alone on the three datasets. revision: yes
-
Referee: [Method (first branch)] The description of the first branch states that pseudo-annotations are fused and used for iterative optimization, but provides no mechanism (e.g., per-iteration filtering or loss re-weighting) to control error propagation when the foundation model's zero-shot detections are domain-shifted.
Authors: The fusion of pseudo-annotations with ground-truth labels and the iterative refinement process are intended to limit the impact of noisy detections. However, the manuscript does not explicitly describe additional controls such as per-iteration filtering. We will expand the method description to clarify the fusion procedure and will introduce a lightweight confidence-based filtering step in the revised version to better address domain-shift concerns. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical two-branch method (iterative pseudo-label self-training fused with ground-truth plus generative augmentation from external VLMs) evaluated on RUOD/CARPK/CarDD under k-shot settings. No equations, fitted parameters, or self-citations are described that would reduce any reported gain or prediction to an input by construction. The framework treats pre-trained model performance as given from prior literature and validates via external benchmarks, making the central claims independent of self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language foundation models produce usable zero-shot detections on support-set images that can be treated as pseudo-labels.
- domain assumption Generative outputs from large vision-language models can be produced with domain alignment and multi-object annotations that improve generalization.
Reference graph
Works this paper leans on
-
[1]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Syn- naeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on com- puter vision, pages 213–229. Springer, 2020. 2
2020
-
[2]
Few-shot object detection with attention-rpn and multi-relation detector
Qi Fan, Wei Zhuo, Chi-Keung Tang, and Yu-Wing Tai. Few-shot object detection with attention-rpn and multi-relation detector. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 4013–4022, 2020. 2
2020
-
[3]
Rethinking general underwater object detec- tion: Datasets, challenges, and solutions.Neuro- computing, 517:243–256, 2023
Chenping Fu, Risheng Liu, Xin Fan, Puyang Chen, Hao Fu, Wanqi Yuan, Ming Zhu, and Zhongxuan Luo. Rethinking general underwater object detec- tion: Datasets, challenges, and solutions.Neuro- computing, 517:243–256, 2023. 5
2023
-
[4]
Styleadv: Meta style adversarial training for cross- domain few-shot learning
Yuqian Fu, Yu Xie, Yanwei Fu, and Yu-Gang Jiang. Styleadv: Meta style adversarial training for cross- domain few-shot learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24575–24584, 2023. 2
2023
-
[5]
Cross- domain few-shot object detection via enhanced open-set object detector
Yuqian Fu, Yu Wang, Yixuan Pan, Lian Huai, Xingyu Qiu, Zeyu Shangguan, Tong Liu, Yanwei Fu, Luc Van Gool, and Xingqun Jiang. Cross- domain few-shot object detection via enhanced open-set object detector. InEuropean Confer- ence on Computer Vision, pages 247–264. Springer,
-
[6]
Acrofod: An adaptive method for cross-domain few-shot object detection
Yipeng Gao, Lingxiao Yang, Yunmu Huang, Song Xie, Shiyong Li, and Wei-Shi Zheng. Acrofod: An adaptive method for cross-domain few-shot object detection. InEuropean Conference on Computer Vision, pages 673–690. Springer, 2022. 2
2022
-
[7]
Asyfod: An asym- metric adaptation paradigm for few-shot domain adaptive object detection
Yipeng Gao, Kun-Yu Lin, Junkai Yan, Yaowei Wang, and Wei-Shi Zheng. Asyfod: An asym- metric adaptation paradigm for few-shot domain adaptive object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3261–3271, 2023. 2
2023
-
[8]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation.arXiv preprint arXiv:2104.13921, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Meng-Ru Hsieh, Yen-Liang Lin, and Winston H. Hsu. Drone-based object counting by spatially reg- ularized regional proposal network. InIEEE In- ternational Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 4165–4173. IEEE Computer Society, 2017. 5
2017
-
[10]
Few-shot object detection via feature reweighting
Bingyi Kang, Zhuang Liu, Xin Wang, Fisher Yu, Jiashi Feng, and Trevor Darrell. Few-shot object detection via feature reweighting. InProceedings of the IEEE/CVF international conference on com- puter vision, pages 8420–8429, 2019. 2
2019
-
[11]
Rethinking few- shot object detection on a multi-domain bench- mark
Kibok Lee, Hao Yang, Satyaki Chakraborty, Zhaowei Cai, Gurumurthy Swaminathan, Avinash Ravichandran, and Onkar Dabeer. Rethinking few- shot object detection on a multi-domain bench- mark. InEuropean Conference on Computer Vi- sion, pages 366–382. Springer, 2022. 3
2022
-
[12]
Grounded language-image pre- training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre- training. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 10965–10975, 2022. 2, 3, 5
2022
-
[13]
Yu Li, Xingyu Qiu, Yuqian Fu, Jie Chen, Tianwen Qian, Xu Zheng, Danda Pani Paudel, Yanwei Fu, Xuanjing Huang, Luc Van Gool, et al. Domain- rag: Retrieval-guided compositional image gener- ation for cross-domain few-shot object detection. arXiv preprint arXiv:2506.05872, 2025. 2
-
[14]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024. 1, 2, 3, 5
2024
-
[15]
Locate anything on earth: Advancing open-vocabulary object detection for remote sensing community
Jiancheng Pan, Yanxing Liu, Yuqian Fu, Muyuan Ma, Jiahao Li, Danda Pani Paudel, Luc Van Gool, and Xiaomeng Huang. Locate anything on earth: Advancing open-vocabulary object detection for remote sensing community. InThirty-Ninth AAAI Conference on Artificial Intelligence, Thirty- Seventh Conference on Innovative Applications of Artificial Intelligence, Fif...
2025
-
[16]
En- hance then search: An augmentation-search strat- egy with foundation models for cross-domain few- shot object detection
Jiancheng Pan, Yanxing Liu, Xiao He, Long Peng, Jiahao Li, Yuze Sun, and Xiaomeng Huang. En- hance then search: An augmentation-search strat- egy with foundation models for cross-domain few- shot object detection. InCVPRW, 2025. 5, 6
2025
-
[17]
Ntire 2026 challenge on cross-domain few-shot ob- ject detection: methods and results
Xingyu Qiu, Yuqian Fu, Geng Jiawei, Bin Ren, Jiancheng Pan, Yanwei Fu, Radu Timofte, et al. Ntire 2026 challenge on cross-domain few-shot ob- ject detection: methods and results. InCVPRW,
2026
-
[18]
YOLOv3: An Incremental Improvement
Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement.arXiv preprint arXiv:1804.02767, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
You only look once: Unified, real- time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real- time object detection. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 779–788, 2016. 2
2016
-
[20]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015. 2
2015
-
[21]
Fsce: Few-shot object detection via contrastive proposal encoding
Bo Sun, Banghuai Li, Shengcai Cai, Ye Yuan, and Chi Zhang. Fsce: Few-shot object detection via contrastive proposal encoding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7352–7362, 2021. 2
2021
-
[22]
Frustratingly simple few-shot object detection.arXiv preprint arXiv:2003.06957, 2020
Xin Wang, Thomas E Huang, Trevor Darrell, Joseph E Gonzalez, and Fisher Yu. Frustratingly simple few-shot object detection.arXiv preprint arXiv:2003.06957, 2020. 2
-
[23]
Cardd: A new dataset for vision-based car damage detection.IEEE Trans
Xinkuang Wang, Wenjing Li, and Zhongcheng Wu. Cardd: A new dataset for vision-based car damage detection.IEEE Trans. Intell. Transp. Syst., 24(7): 7202–7214, 2023. 5
2023
-
[24]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Shengming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Ming- gang Wu, Peng Wang, Shuting Yu, Tingku...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Cd-fsod: A benchmark for cross- domain few-shot object detection
Wuti Xiong. Cd-fsod: A benchmark for cross- domain few-shot object detection. InICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–
2023
-
[26]
Meta r-cnn: Towards general solver for instance-level low-shot learning
Xiaopeng Yan, Ziliang Chen, Anni Xu, Xiaoxi Wang, Xiaodan Liang, and Liang Lin. Meta r-cnn: Towards general solver for instance-level low-shot learning. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9577– 9586, 2019. 2
2019
-
[27]
Open-vocabulary object de- tection using captions
Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih-Fu Chang. Open-vocabulary object de- tection using captions. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 14393–14402, 2021. 2
2021
-
[28]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising an- chor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Yaze Zhao, Yixiong Zou, Yuhua Li, and Ruixuan Li. Interpretable cross-domain few-shot learning with rectified target-domain local alignment.arXiv preprint arXiv:2603.17655, 2026. 2
-
[30]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiao- gang Wang, and Jifeng Dai. Deformable detr: De- formable transformers for end-to-end object detec- tion.arXiv preprint arXiv:2010.04159, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
Flatten long-range loss landscapes for cross-domain few-shot learning
Yixiong Zou, Yicong Liu, Yiman Hu, Yuhua Li, and Ruixuan Li. Flatten long-range loss landscapes for cross-domain few-shot learning. InCVPR 2024, pages 23575–23584. IEEE, 2024. 2
2024
-
[32]
Attention temperature matters in vit-based cross- domain few-shot learning
Yixiong Zou, Ran Ma, Yuhua Li, and Ruixuan Li. Attention temperature matters in vit-based cross- domain few-shot learning. InNeurIPS 2024, 2024
2024
-
[33]
A closer look at the CLS token for cross-domain few-shot learning
Yixiong Zou, Shuai Yi, Yuhua Li, and Ruixuan Li. A closer look at the CLS token for cross-domain few-shot learning. InNeurIPS 2024, 2024. 2
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.