Brain-IT-VQA: From Brain Signals to Answers
Pith reviewed 2026-06-29 08:18 UTC · model grok-4.3
The pith
Brain-IT-VQA converts fMRI signals into language tokens that a language model uses to answer questions about viewed images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
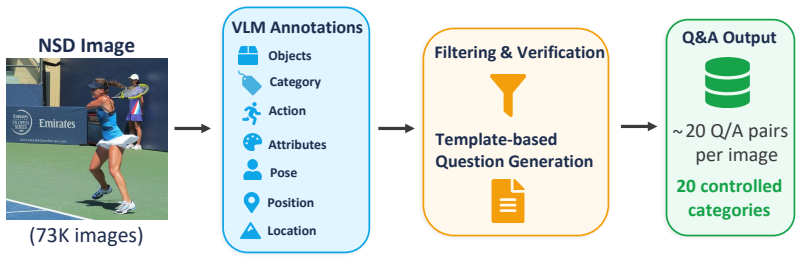
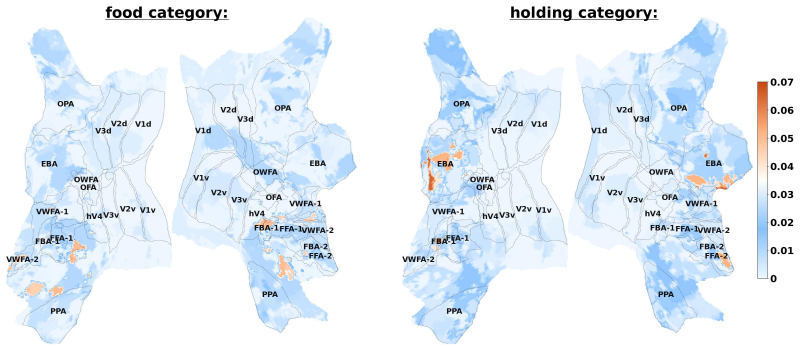
Brain-IT-VQA decodes language tokens from fMRI responses to natural images and integrates them with a language model to answer visual questions, substantially outperforming prior fMRI-based captioning and VQA methods. The NSD-VQA benchmark supplies on average twenty question-answer pairs per image across twenty controlled categories that separate levels of visual understanding, allowing quantification of which visual and semantic information is reliably decodable and analysis of brain-region contributions across question types.
What carries the argument
Brain Interaction Transformer that decodes language tokens directly from brain activity for use by a downstream language model.
If this is right
- The method produces higher accuracy than earlier fMRI captioning and VQA systems on the new benchmark.
- Quantification shows which visual and semantic features are reliably present in fMRI responses to natural images.
- Brain-region contributions can be mapped separately for each of the twenty question categories.
- The controlled question set enables more interpretable evaluation despite small fMRI test sets.
Where Pith is reading between the lines
- The token-decoding step could be reused with other brain-recording methods such as EEG to test cross-modal consistency.
- If token sequences prove stable across subjects, they might serve as a compact intermediate representation for brain-to-text systems.
- The benchmark categories could be extended to test whether high-level semantic relations remain decodable when low-level visual features are controlled.
- Performance differences across categories may indicate which visual computations occur early enough in the visual hierarchy to be captured by current fMRI resolution.
Load-bearing premise
The twenty controlled question categories in NSD-VQA truly separate distinct levels of visual understanding and the limited fMRI test data still supports stable performance comparisons.
What would settle it
A replication in which the new model shows no accuracy gain over prior fMRI VQA baselines on the NSD-VQA test set, or in which accuracy does not differ systematically across the twenty question categories in the expected pattern.
Figures


read the original abstract
Decoding visual content from fMRI signals recorded while a person views images, and specifically answering questions about the seen images, is a long-standing challenge. While significant progress has been made in recent years in visual question answering (VQA) from fMRI, performance remains limited. Moreover, although recent models can make increasingly accurate predictions, they have rarely been used as tools for understanding the structure of visual representations in the brain. We present Brain-IT-VQA, a framework for visual question answering from fMRI. Building on the Brain Interaction Transformer (Brain-IT), our method decodes language tokens from brain activity and integrates them with a language model to answer visual questions. Our model substantially outperforms previous fMRI-based captioning and VQA approaches. We further introduce NSD-VQA, a new dataset and benchmark for visual question answering from fMRI. Unlike existing image-fMRI VQA datasets, which typically provide only a few broad and weakly controlled questions per image, NSD-VQA provides on average 20 question-answer pairs per image across 20 controlled question categories that disentangle multiple levels of visual understanding. This enables more reliable and interpretable evaluation despite limited fMRI test data. Together, Brain-IT-VQA and NSD-VQA provide both a strong predictive framework and a tool for studying brain representations. Using this benchmark, we quantify which forms of visual and semantic information can be reliably decoded from fMRI responses to natural images. We further analyze the contributions of different brain regions across question types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Brain-IT-VQA, a framework extending the Brain Interaction Transformer to decode language tokens from fMRI signals and integrate them with a language model for visual question answering. It claims substantial outperformance over prior fMRI-based captioning and VQA methods. The work also presents the NSD-VQA benchmark, which supplies ~20 question-answer pairs per image across 20 controlled categories designed to disentangle visual and semantic levels, enabling more reliable evaluation and quantification of decodable information from natural-image fMRI responses, plus region-wise analyses.
Significance. If the performance gains and benchmark validity hold, the contribution would be a stronger predictive model for brain-signal decoding together with a controlled tool for probing the structure of visual representations in cortex.
major comments (2)
- [Abstract] Abstract: the central claim that Brain-IT-VQA 'substantially outperforms previous fMRI-based captioning and VQA approaches' is stated without any quantitative results, baselines, error bars, or statistical tests, rendering the outperformance assertion impossible to evaluate.
- [Abstract] Abstract (NSD-VQA description): the assertion that the 20 controlled categories 'disentangle multiple levels of visual understanding' and permit 'more reliable and interpretable evaluation despite limited fMRI test data' is load-bearing for the benchmark's utility, yet no supporting analysis (inter-question correlations, per-category variance, or power calculations) is referenced; this directly engages the concern that small test sets may render performance deltas and region analyses uninterpretable.
minor comments (1)
- [Abstract] The abstract states that the framework 'quantify which forms of visual and semantic information can be reliably decoded' and analyzes 'contributions of different brain regions across question types,' but supplies no methodological details on the decoding metrics, statistical tests, or region definitions used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and indicate planned revisions to strengthen the presentation of results and benchmark justification.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Brain-IT-VQA 'substantially outperforms previous fMRI-based captioning and VQA approaches' is stated without any quantitative results, baselines, error bars, or statistical tests, rendering the outperformance assertion impossible to evaluate.
Authors: We agree that the abstract would be improved by including key quantitative support. The main text reports specific metrics (accuracy, BLEU, and CIDEr scores with error bars and statistical tests against prior methods in Tables 1-2 and Section 4.1). In revision we will add concise numerical results and baseline references to the abstract while keeping it within length limits. revision: yes
-
Referee: [Abstract] Abstract (NSD-VQA description): the assertion that the 20 controlled categories 'disentangle multiple levels of visual understanding' and permit 'more reliable and interpretable evaluation despite limited fMRI test data' is load-bearing for the benchmark's utility, yet no supporting analysis (inter-question correlations, per-category variance, or power calculations) is referenced; this directly engages the concern that small test sets may render performance deltas and region analyses uninterpretable.
Authors: The main text already provides per-category performance variance, region-wise contribution maps, and interpretability results (Sections 4.2-4.3) that support the benchmark's utility. We will revise the abstract to explicitly reference these analyses. We can also add a short note on inter-question correlations if the referee deems it necessary; power calculations for the test set size can be included in the supplement. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces Brain-IT-VQA by extending the prior Brain-IT model and presents NSD-VQA as a new benchmark whose 20 controlled categories are asserted to disentangle visual understanding levels. Performance gains and region analyses are framed as empirical outcomes from applying the decoder to fMRI data, with no equations, fitted-parameter renamings, or self-citation chains shown that would reduce the central claims to inputs by construction. The derivation remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brain-it: Image reconstruction from fmri via brain-interaction transformer
Roman Beliy, Amit Zalcher, Jonathan Kogman, Navve Wasserman, and Michal Irani. Brain-it: Image reconstruction from fmri via brain-interaction transformer. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[2]
Variational autoencoder: An unsupervised model for encoding and decoding fmri activity in visual cortex.NeuroImage, 198:125–136, 2019
Kuan Han, Haiguang Wen, Junxing Shi, Kun-Han Lu, Yizhen Zhang, Di Fu, and Zhongming Liu. Variational autoencoder: An unsupervised model for encoding and decoding fmri activity in visual cortex.NeuroImage, 198:125–136, 2019
2019
-
[3]
Dcnn-gan: Reconstructing realistic image from fmri
Yunfeng Lin, Jiangbei Li, and Hanjing Wang. Dcnn-gan: Reconstructing realistic image from fmri. In2019 16th International Conference on Machine Vision Applications (MVA), pages 1–6. IEEE, 2019
2019
-
[4]
Reconstructing natural scenes from fmri patterns using bigbigan
Milad Mozafari, Leila Reddy, and Rufin VanRullen. Reconstructing natural scenes from fmri patterns using bigbigan. In2020 International joint conference on neural networks (IJCNN), pages 1–8. IEEE, 2020
2020
-
[5]
Biggan-based bayesian reconstruction of natural images from human brain activity.Neuroscience, 444:92–105, 2020
Kai Qiao, Jian Chen, Linyuan Wang, Chi Zhang, Li Tong, and Bin Yan. Biggan-based bayesian reconstruction of natural images from human brain activity.Neuroscience, 444:92–105, 2020
2020
-
[6]
Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning.NeuroImage, 228:117602, 2021
Ziqi Ren, Jie Li, Xuetong Xue, Xin Li, Fan Yang, Zhicheng Jiao, and Xinbo Gao. Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning.NeuroImage, 228:117602, 2021
2021
-
[7]
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22710–22720, 2023
2023
-
[8]
High-resolution image reconstruction with latent diffusion models from human brain activity
Yu Takagi and Shinji Nishimoto. High-resolution image reconstruction with latent diffusion models from human brain activity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14453–14463, 2023
2023
-
[9]
Natural scene reconstruction from fmri signals using generative latent diffusion.Scientific Reports, 13(1):15666, 2023
Furkan Ozcelik and Rufin VanRullen. Natural scene reconstruction from fmri signals using generative latent diffusion.Scientific Reports, 13(1):15666, 2023
2023
-
[10]
Deep image recon- struction from human brain activity.PLoS computational biology, 15(1):e1006633, 2019
Guohua Shen, Tomoyasu Horikawa, Kei Majima, and Yukiyasu Kamitani. Deep image recon- struction from human brain activity.PLoS computational biology, 15(1):e1006633, 2019
2019
-
[11]
Constraint-free natural image reconstruction from fmri signals based on convolutional neural network.Frontiers in human neuroscience, 12:242, 2018
Chi Zhang, Kai Qiao, Linyuan Wang, Li Tong, Ying Zeng, and Bin Yan. Constraint-free natural image reconstruction from fmri signals based on convolutional neural network.Frontiers in human neuroscience, 12:242, 2018
2018
-
[12]
Mindbridge: A cross-subject brain decoding framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Mindbridge: A cross-subject brain decoding framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11333–11342, 2024
2024
-
[13]
Umbrae: Unified multi- modal brain decoding
Weihao Xia, Raoul de Charette, Cengiz Oztireli, and Jing-Hao Xue. Umbrae: Unified multi- modal brain decoding. InEuropean Conference on Computer Vision, pages 242–259. Springer, 2024
2024
-
[14]
SSM2Mel: State Space Model to Reconstruct Mel Spectrogram from the EEG,
Wanqiu Huang, Ke Ma, Tingyu Xie, and Hongwei Wang. Brainchat: Interactive semantic information decoding from fmri using large-scale vision-language pretrained models. InICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2025. doi: 10.1109/ICASSP49660.2025.10889434. 10
-
[15]
MindLLM: A subject-agnostic and versatile model for fMRI-to-text decoding
Weikang Qiu, Zheng Huang, Haoyu Hu, Aosong Feng, Yujun Yan, and Rex Ying. MindLLM: A subject-agnostic and versatile model for fMRI-to-text decoding. InForty-second Interna- tional Conference on Machine Learning, 2025. URL https://openreview.net/forum? id=EiAQrilPYP
2025
- [16]
-
[17]
Unibrain: A unified model for cross-subject brain decoding.arXiv preprint arXiv:2412.19487, 2024
Zicheng Wang, Zhen Zhao, Luping Zhou, and Parashkev Nachev. Unibrain: A unified model for cross-subject brain decoding.arXiv preprint arXiv:2412.19487, 2024
-
[18]
Mindgpt: Interpreting what you see with non-invasive brain recordings, 2023
Jiaxuan Chen, Yu Qi, Yueming Wang, and Gang Pan. Mindgpt: Interpreting what you see with non-invasive brain recordings, 2023. URLhttps://arxiv.org/abs/2309.15729
-
[19]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
2022
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[21]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[22]
OpenAI. GPT-4 technical report. Technical report, OpenAI, 2023. arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[25]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Wayne Xin Zhao, Ji-Rong Wang, Wenhao Wang, Chunyu Kit Chan, and Steven C.H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.arXiv preprint arXiv:2305.06500, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Identifying natural images from human brain activity.Nature, 452(7185):352–355, 2008
Kendrick N Kay, Thomas Naselaris, Ryan J Prenger, and Jack L Gallant. Identifying natural images from human brain activity.Nature, 452(7185):352–355, 2008
2008
-
[27]
Bayesian reconstruction of natural images from human brain activity.Neuron, 63(6):902–915, 2009
Thomas Naselaris, Ryan J Prenger, Kendrick N Kay, Michael Oliver, and Jack L Gallant. Bayesian reconstruction of natural images from human brain activity.Neuron, 63(6):902–915, 2009
2009
-
[28]
Reconstructing visual experiences from brain activity evoked by natural movies.Current biology, 21(19):1641–1646, 2011
Shinji Nishimoto, An T Vu, Thomas Naselaris, Yuval Benjamini, Bin Yu, and Jack L Gallant. Reconstructing visual experiences from brain activity evoked by natural movies.Current biology, 21(19):1641–1646, 2011
2011
-
[29]
Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream.Journal of Neuroscience, 35 (27):10005–10014, 2015
Umut Güçlü and Marcel AJ Van Gerven. Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream.Journal of Neuroscience, 35 (27):10005–10014, 2015
2015
-
[30]
Generative adversarial networks for reconstructing natural images from brain activity
Katja Seeliger, Umut Güçlü, Luca Ambrogioni, Yagmur Güçlütürk, and Marcel AJ Van Ger- ven. Generative adversarial networks for reconstructing natural images from brain activity. NeuroImage, 181:775–785, 2018
2018
-
[31]
Generative adversarial networks conditioned on brain activity reconstruct seen images
Ghislain St-Yves and Thomas Naselaris. Generative adversarial networks conditioned on brain activity reconstruct seen images. In2018 IEEE international conference on systems, man, and cybernetics (SMC), pages 1054–1061. IEEE, 2018
2018
-
[32]
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fmri.Advances in Neural Information Processing Systems, 32:6514–6524, 2019
Roman Beliy, Guy Gaziv, Assaf Hoogi, Francesca Strappini, Tal Golan, and Michal Irani. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fmri.Advances in Neural Information Processing Systems, 32:6514–6524, 2019. 11
2019
-
[33]
S., Tripathy, M., Villanueva, C
Paul S Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, et al. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data.arXiv preprint arXiv:2403.11207, 2024
-
[34]
Mindtuner: Cross-subject visual decoding with visual fingerprint and semantic correction
Zixuan Gong, Qi Zhang, Guangyin Bao, Lei Zhu, Rongtao Xu, Ke Liu, Liang Hu, and Duoqian Miao. Mindtuner: Cross-subject visual decoding with visual fingerprint and semantic correction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14247– 14255, 2025
2025
-
[35]
Through their eyes: multi-subject brain decoding with simple alignment techniques.Imaging Neuroscience, 2:1–21, 2024
Matteo Ferrante, Tommaso Boccato, Furkan Ozcelik, Rufin VanRullen, and Nicola Toschi. Through their eyes: multi-subject brain decoding with simple alignment techniques.Imaging Neuroscience, 2:1–21, 2024
2024
-
[36]
See through their minds: Learning transferable brain decoding models from cross-subject fmri
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, and Nanning Zheng. See through their minds: Learning transferable brain decoding models from cross-subject fmri. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5730–5738, 2025
2025
-
[37]
The Wisdom of a Crowd of Brains: A Universal Brain Encoder
Roman Beliy, Navve Wasserman, Amit Zalcher, and Michal Irani. The wisdom of a crowd of brains: A universal brain encoder.arXiv preprint arXiv:2406.12179, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Interpretable fmri captioning via contrastive learning
Vyacheslav Shen, Kassymzhomart Kunanbayev, Donggon Jang, and Daeshik Kim. Interpretable fmri captioning via contrastive learning. In James C. Gee, Daniel C. Alexander, Jaesung Hong, Juan Eugenio Iglesias, Carole H. Sudre, Archana Venkataraman, Polina Golland, Jong Hyo Kim, and Jinah Park, editors,Medical Image Computing and Computer Assisted Intervention ...
2025
-
[39]
A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022
2022
-
[40]
BOLD5000: A public fMRI dataset while viewing 5000 visual images
Nadine Chang, John A Pyles, Austin Marcus, Abhinav Gupta, Michael J Tarr, and Elissa M Aminoff. BOLD5000: A public fMRI dataset while viewing 5000 visual images. InScientific Data, volume 6, page 49, 2019
2019
-
[41]
Neuropictor: Refining fmri-to-image reconstruction via multi-individual pretraining and multi-level modulation
Jingyang Huo, Yikai Wang, Yun Wang, Xuelin Qian, Chong Li, Yanwei Fu, and Jianfeng Feng. Neuropictor: Refining fmri-to-image reconstruction via multi-individual pretraining and multi-level modulation. InEuropean Conference on Computer Vision, pages 56–73. Springer, 2024
2024
-
[42]
BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
Navve Wasserman, Matias Cosarinsky, Yuval Golbari, Aude Oliva, Antonio Torralba, Tamar Rott Shaham, and Michal Irani. Brainexplore: Large-scale discovery of interpretable visual represen- tations in the human brain, 2025. URLhttps://arxiv.org/abs/2512.08560
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team. Gemma: Open models based on gemini research and technology, 2024. URL https://arxiv.org/abs/2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
C-pack: Packaged resources to advance general chinese embedding, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023
2023
-
[46]
Aaron Grattafiori et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/ 2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 12
2014
- [48]
-
[49]
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering . In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6325–6334, Los Alamitos, CA, USA, July 2017. IEEE Computer Society. doi: 10.1109/CVPR.2017.670. URL...
-
[50]
The Color of the Cat is Gray: 1 Million Full-Sentences Visual Question Answering (FSVQA)
Andrew Shin, Yoshitaka Ushiku, and Tatsuya Harada. The color of the cat is gray: 1 million full-sentences visual question answering (fsvqa), 2016. URL https://arxiv.org/abs/ 1609.06657
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[51]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering . In2015 IEEE Inter- national Conference on Computer Vision (ICCV), pages 2425–2433, Los Alamitos, CA, USA, December 2015. IEEE Computer Society. doi: 10.1109/ICCV .2015.279. URL https://doi.ieeecomputersociet...
-
[52]
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , pages =
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Comput...
-
[53]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Jade Goldstein, Alon Lavie, Chin-Yew Lin, and Clare V oss, editors,Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan,...
2005
-
[54]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URLhttps://aclanthology.org/W04-1013/
2004
-
[55]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. CIDEr: Consensus-based image description evaluation . In2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4566–4575, Los Alamitos, CA, USA, June 2015. IEEE Computer Society. doi: 10.1109/CVPR.2015.7299087. URL https://doi.ieeecomputersociety. org/10.1109/CVPR.2015.7299087
-
[56]
Spice: Semantic propositional image caption evaluation
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. Spice: Semantic propositional image caption evaluation. InECCV, 2016
2016
-
[57]
High-resolution image reconstruction with latent diffusion models from human brain activity
Yu Takagi and Shinji Nishimoto. High-resolution image reconstruction with latent diffusion models from human brain activity. InCVPR, 2023
2023
-
[58]
J. et al. Han. Onellm: One framework to align all modalities with language. InCVPR, 2024
2024
-
[59]
W. Mai and Z. Zhang. Unibrain: Unify image reconstruction and captioning all in one diffusion model from human brain activity.arXiv preprint arXiv:2308.07428, 2023
-
[60]
Brain-language fusion enables interactive neural readout and in-silico experimenta- tion, 2025
Victoria Bosch, Daniel Anthes, Adrien Doerig, Sushrut Thorat, Peter König, and Tim Christian Kietzmann. Brain-language fusion enables interactive neural readout and in-silico experimenta- tion, 2025. URLhttps://arxiv.org/abs/2509.23941
-
[61]
Ida Gobbini, Maura L Furey, Alumit Ishai, Jennifer L Schouten, and Pietro Pietrini
James V Haxby, M. Ida Gobbini, Maura L Furey, Alumit Ishai, Jennifer L Schouten, and Pietro Pietrini. Distributed and overlapping representations of faces and objects in ventral temporal cortex.Science, 293(5539):2425–2430, 2001
2001
-
[62]
Beyond mind-reading: multi-voxel pattern analysis of fmri data.Trends in Cognitive Sciences, 10(9):424–430, 2006
Kenneth A Norman, Sean M Polyn, Greg J Detre, and James V Haxby. Beyond mind-reading: multi-voxel pattern analysis of fmri data.Trends in Cognitive Sciences, 10(9):424–430, 2006. 13
2006
-
[63]
Zeiler and Rob Fergus
Matthew D. Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In Computer Vision – ECCV 2014, volume 8689 ofLecture Notes in Computer Science, pages 818–833. Springer, 2014
2014
-
[64]
why should I trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "why should I trust you?": Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144, 2016
2016
-
[65]
Apurva Ratan Murty, and Nancy Kanwisher
Meenakshi Khosla, N. Apurva Ratan Murty, and Nancy Kanwisher. A highly selective response to food in human visual cortex revealed by hypothesis-free voxel decomposi- tion.Current Biology, 32(19):4159–4171.e9, 2022. ISSN 0960-9822. doi: https://doi.org/ 10.1016/j.cub.2022.08.009. URL https://www.sciencedirect.com/science/article/ pii/S0960982222012866
-
[66]
Scaling instruction-finetuned language models, 2022
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, et al. Scaling instruction-finetuned language models, 2022
2022
-
[67]
objects". OUTPUT FORMAT (STRICT JSON ONLY): {
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7. 14 Appendix A Limitation fMRI Assumptions.Following standard practice in the field, our model assumes that fMRI responses are memoryless and replicable. The memoryless assum...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.