TRACE: Toulmin-based Reasoning Assessment through Constructive Elements for LLM CoT Evaluation
Pith reviewed 2026-06-29 07:16 UTC · model grok-4.3
The pith
TRACE evaluates LLM Chain-of-Thought reasoning structure via Toulmin elements and metacognition, correlating r=0.74 with answer accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
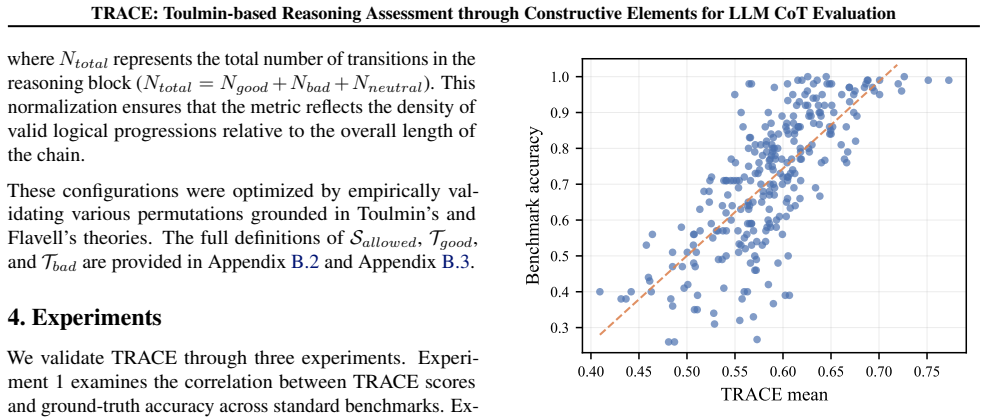
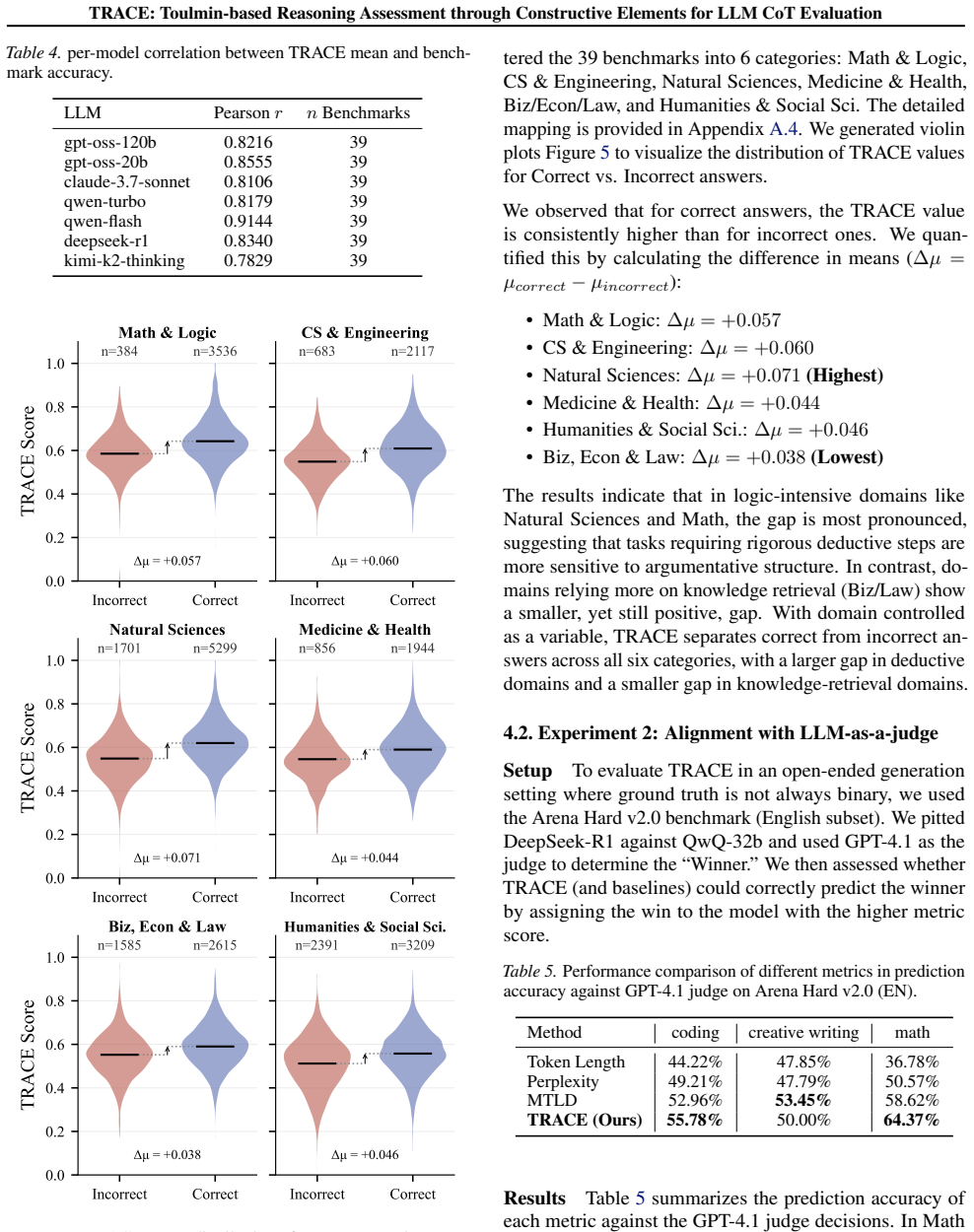
TRACE integrates Toulmin's argumentation theory with Flavell's metacognitive framework to assess reasoning structure in CoT. Experiments on 26.3K QA samples across 7 reasoning models show strong correlation with benchmark accuracy (r=0.74). Furthermore, TRACE is effective as a reinforcement learning reward signal, outperforming accuracy-only baselines. Together, these results indicate that logically sound reasoning leads to higher-quality answers.
What carries the argument
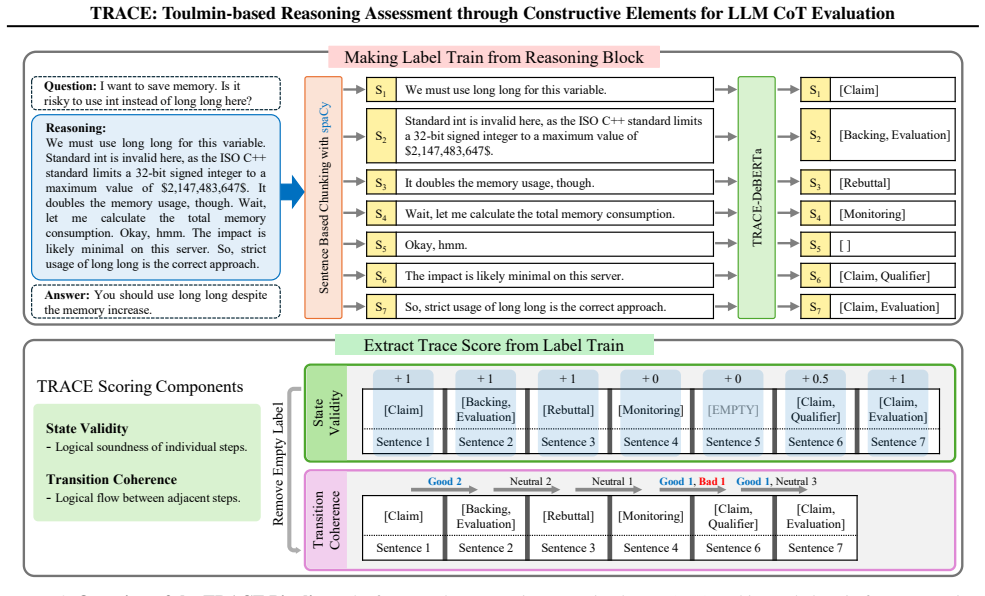
TRACE metric that scores constructive elements of arguments by combining Toulmin's six components (claim, data, warrant, backing, qualifier, rebuttal) with metacognitive monitoring and evaluation steps.
If this is right
- Logically sound reasoning processes lead to higher-quality answers.
- TRACE can function as an effective reinforcement learning reward signal that improves model performance beyond accuracy-only training.
- Reasoning evaluation for open-ended LLM outputs can shift focus from outcomes to argument structure.
- A complementary metric exists alongside accuracy for judging LLM capabilities on reasoning tasks.
Where Pith is reading between the lines
- The method could be adapted to assess reasoning in domains beyond QA, such as code generation or multi-step planning.
- Training objectives might be redesigned to explicitly encourage construction of Toulmin-style argument components.
- If structural scores drive accuracy, similar frameworks could help diagnose and reduce specific failure modes like unsupported claims.
- Educational applications might use the same scoring to give feedback on student reasoning chains.
Load-bearing premise
The specific integration of Toulmin's argumentation elements and Flavell's metacognition provides a valid, generalizable measure of reasoning quality that is independent of and predictive of final-answer correctness rather than merely correlated with it.
What would settle it
A new set of models or tasks where high TRACE scores consistently appear with low final-answer accuracy, or where reinforcement learning using TRACE rewards fails to outperform accuracy-based rewards.
Figures


read the original abstract
Evaluating open-ended outputs from large language models (LLMs) remains challenging due to the absence of ground truth. Existing metrics rely on final-answer accuracy or surface-level statistics, leaving the reasoning process itself unexamined. We introduce TRACE (Toulmin-based Reasoning Assessment through Constructive Elements), a metric that analyzes Chain-of-Thought (CoT) reasoning processes. Rather than judging outcomes, TRACE inspects how arguments are constructed by integrating Toulmin's argumentation theory with Flavell's metacognitive framework to assess reasoning structure. Experiments on 26.3K QA samples across 7 reasoning models show strong correlation with benchmark accuracy (r=0.74). Furthermore, TRACE is effective as a reinforcement learning reward signal, outperforming accuracy-only baselines. Together, these results indicate that logically sound reasoning leads to higher-quality answers. TRACE thus serves as a complementary metric for evaluating open-ended outputs. Code is available at https://github.com/hyyangkisti/trace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACE, a metric that integrates Toulmin's argumentation theory with Flavell's metacognitive framework to evaluate the structure of Chain-of-Thought (CoT) reasoning in LLMs rather than final-answer accuracy. On 26.3K QA samples across 7 reasoning models, it reports a correlation of r=0.74 with benchmark accuracy and demonstrates that TRACE serves as an effective RL reward signal, outperforming accuracy-only baselines. The authors conclude that logically sound reasoning leads to higher-quality answers and position TRACE as a complementary metric for open-ended LLM outputs.
Significance. If the metric can be shown to capture an independent dimension of reasoning quality, it would address a genuine gap in LLM evaluation by moving beyond outcome-based metrics; the RL result, if robust, would further suggest practical utility for training.
major comments (3)
- [Abstract] Abstract: the inference that 'logically sound reasoning leads to higher-quality answers' rests on the r=0.74 correlation and the RL result, yet the abstract supplies no controls (e.g., regressing out model size, prompt difficulty, or final-answer correctness) to establish that TRACE measures an independent causal factor rather than a downstream correlate.
- [Abstract] Abstract and §3 (metric definition): without explicit scoring rules for the Toulmin elements and Flavell metacognitive components, or any demonstration that the metric construction excludes accuracy signals, it is impossible to rule out circularity between TRACE and the benchmark accuracy it is correlated with.
- [RL experiments] RL experiments section: the claim that TRACE outperforms accuracy-only baselines requires the precise reward formulation, training details, and ablation controls; absent these, the result does not yet secure that the structured-reasoning signal is the operative factor.
minor comments (2)
- [Abstract] The abstract states '26.3K QA samples' but does not name the underlying datasets or the seven models; this information should appear in the experimental setup.
- Notation for the TRACE score components is not introduced in the abstract; a compact definition or table of the six Toulmin/Flavell elements would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract and experimental details can be clarified. We address each major comment below, indicating revisions where appropriate to strengthen the presentation without overstating the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the inference that 'logically sound reasoning leads to higher-quality answers' rests on the r=0.74 correlation and the RL result, yet the abstract supplies no controls (e.g., regressing out model size, prompt difficulty, or final-answer correctness) to establish that TRACE measures an independent causal factor rather than a downstream correlate.
Authors: We agree the abstract phrasing could be read as implying a causal claim stronger than the reported evidence. The r=0.74 reflects a correlation across 7 models and 26.3K samples, and the RL result demonstrates practical utility rather than controlled isolation of an independent factor. In revision we will change the abstract wording from 'indicate that' to 'suggest that' and add a brief clause noting that controlled analyses for confounders such as model scale remain future work. No new experiments are added, but the language will be tempered accordingly. revision: partial
-
Referee: [Abstract] Abstract and §3 (metric definition): without explicit scoring rules for the Toulmin elements and Flavell metacognitive components, or any demonstration that the metric construction excludes accuracy signals, it is impossible to rule out circularity between TRACE and the benchmark accuracy it is correlated with.
Authors: Section 3 defines TRACE via explicit rubrics on Toulmin components (claim, data, warrant, backing, qualifier, rebuttal) and Flavell metacognitive elements (planning, monitoring, evaluation), scored on structural presence, completeness, and coherence within the CoT text. Scoring is performed without reference to final-answer correctness. We will expand §3 in the revision to include the full rubric table, annotation guidelines, and two worked examples showing cases where high TRACE coincides with incorrect answers (and vice versa). This makes the independence from accuracy explicit and addresses potential circularity concerns. revision: yes
-
Referee: [RL experiments] RL experiments section: the claim that TRACE outperforms accuracy-only baselines requires the precise reward formulation, training details, and ablation controls; absent these, the result does not yet secure that the structured-reasoning signal is the operative factor.
Authors: We will revise the RL section to report the exact reward formulation (normalized TRACE score used directly as the reward), the RL algorithm and hyperparameters, training steps, environment details, and ablation results comparing TRACE reward against accuracy-only and random baselines. These additions will clarify the contribution of the structured-reasoning component. revision: yes
Circularity Check
No significant circularity; metric defined from external theories with correlation as outcome
full rationale
The provided abstract defines TRACE explicitly from Toulmin's argumentation theory integrated with Flavell's metacognitive framework, independent of accuracy. Correlation (r=0.74) and RL reward results are presented as experimental findings on 26.3K samples, not as definitional inputs or fitted parameters. No equations, self-citations, or reductions to self-inputs appear. The inference from correlation to 'logically sound reasoning leads to higher-quality answers' is an interpretive claim, not a circular derivation step. Per rules, absent specific quotes exhibiting construction-by-inputs or load-bearing self-citation chains, score remains 0.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Odyssey: Constructing Verifiable Local Truth-Preserving Foundation Models
ODYSSEY is a sheaf-theoretic framework for building verifiable foundation models as compositions of foundries via left and right Kan extensions.
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:268232499. Antoun, W., Sagot, B., and Seddah, D. Modernbert or debertav3? examining architecture and data influence on transformer encoder models performance.arXiv preprint arXiv:2504.08716, 2025. Bai, G., Liu, J., Bu, X., He, Y ., Liu, J., Zhou, Z., Lin, Z., Su, W., Ge, T., Zheng, B., and Ouyang, W. MT-bench-...
-
[2]
Lessons from the Trenches on Reproducible Evaluation of Language Models
URL https://aclanthology.org/2024. acl-long.401/. Biderman, S., Schoelkopf, H., Sutawika, L., Gao, L., Tow, J., Abbasi, B., Aji, A. F., Ammanamanchi, P. S., Black, S., Clive, J., et al. Lessons from the trenches on repro- ducible evaluation of language models.arXiv preprint arXiv:2405.14782, 2024. Chen, G. H., Chen, S., Liu, Z., Jiang, F., and Wang, B. Hu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024 2024
-
[3]
acl-main.372/
URL https://aclanthology.org/2020. acl-main.372/. Du, X., Yao, Y ., Ma, K., et al. SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines. In The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems Datasets and Benchmarks Track,
2020
-
[4]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
URL https://openreview.net/forum? id=6WgflzYQpf. Dubois, Y ., Galambosi, B., Liang, P., and Hashimoto, T. B. Length-controlled alpacaeval: A simple way to debias automatic evaluators, 2025. URL https://arxiv. org/abs/2404.04475. Flavell, J. H. Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry.American psychologist, 34(1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.xinn.2025.101253 2025
-
[5]
Process reward models that think.arXiv preprint arXiv:2504.16828,
URL https://openreview.net/forum? id=sE7-XhLxHA. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. URL https:// openreview.net/forum?id=d7KBjmI3GmQ. Khalifa, M., Agarwal, R., Logeswaran, L., Kim, J., Peng...
-
[6]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
URL https://openreview.net/forum? id=4T33izzFpK. Li, T., Chiang, W.-L., Frick, E., Dunlap, L., Wu, T., Zhu, B., Gonzalez, J. E., and Stoica, I. From crowdsourced data to high-quality benchmarks: Arena-hard and bench- builder pipeline. InForty-second International Con- ference on Machine Learning, 2025. URL https: //openreview.net/forum?id=KfTf9vFvSn. Lin,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3115/v1/d14-1006 2025
-
[7]
URL https: //aclanthology.org/2025.acl-long.127/
doi: 10.18653/v1/2025.acl-long.127. URL https: //aclanthology.org/2025.acl-long.127/. Wei, J., Wang, X., Schuurmans, D., Bosma, M., ichter, b., Xia, F., Chi, E., Le, Q. V ., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neura...
-
[8]
Zeng, Z., Chen, P., Liu, S., Jiang, H., and Jia, J
URL https://openreview.net/forum? id=2a36EMSSTp. Zeng, Z., Chen, P., Liu, S., Jiang, H., and Jia, J. MR-GSM8k: A meta-reasoning benchmark for large language model evaluation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https:// openreview.net/forum?id=br4H61LOoI. Zheng, C., Zhang, Z., Zhang, B., Lin, R., Lu, K., Yu, B....
2025
-
[9]
By the tower law of field extensions, we have:[K:F] = [K:E]·[E:F]
doi: 10.18653/v1/2025.acl-long.50. URL https: //aclanthology.org/2025.acl-long.50/. Zheng, L., Chiang, W.-L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging llm-as-a-judge with mt-bench and chatbot arena. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Le...
-
[10]
The answer is (B), which is correct
:Q] = 2because √ 2is irrational. ”→[Evidence, Warrant] “The answer is (B), which is correct. ”→[Claim, Evaluation] “I think most people would say that lying is wrong. ”→[Claim, Qualifier, Backing] No Label Cases: “Hmm. ”→[ ] “Okay, let’s tackle this question. ”→[ ] “Thank you for listening. ”→[ ] B.2. Allowed States State Validity is computed based on the...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.