DGSG-Mind: Dynamic 3D Gaussian Scene Graphs for Long-Term Scene Understanding and Grounding
Pith reviewed 2026-06-29 08:46 UTC · model grok-4.3
The pith
DGSG-Mind couples a probabilistic voxel grid with explicit 3D Gaussians to build dynamic scene graphs that support incremental semantic mapping and embodied reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
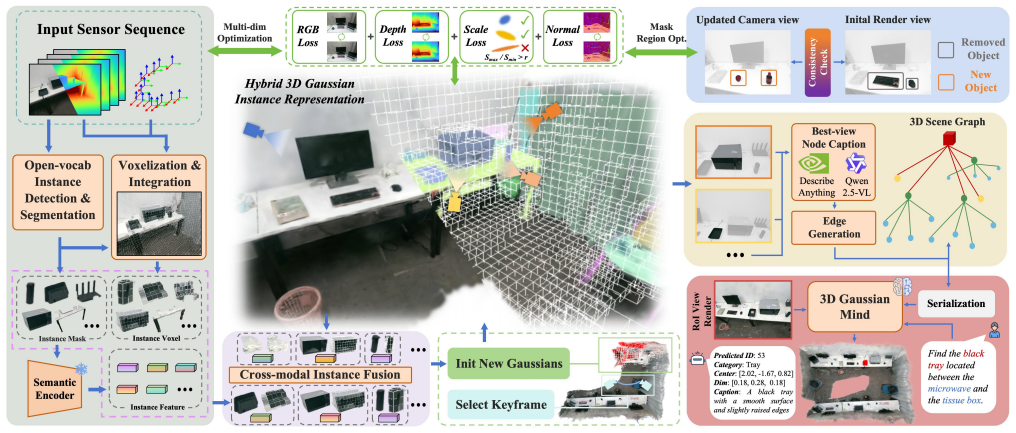
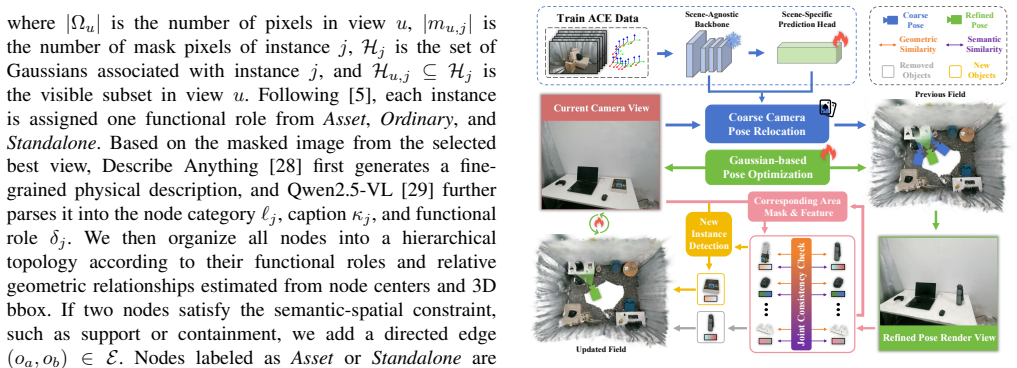
DGSG-Mind is a hybrid instance-aware 3D Gaussian dynamic scene graph system that couples a probabilistic voxel grid with explicit 3D Gaussians to achieve robust cross-modal instance fusion and incremental semantic mapping, handles dynamic changes via Gaussian visual relocalization and localized masked refinement, constructs a hierarchical scene graph on the instance Gaussian map, and deploys the 3D Gaussian Mind to integrate structural relations, spatial-semantic information, and visually annotated RoI Gaussian renderings for multimodal reasoning.
What carries the argument
The instance Gaussian map that anchors cross-modal fusion, supports Gaussian-based relocalization and masked refinement for dynamic updates, and supplies the base for the hierarchical scene graph plus the 3D Gaussian Mind reasoning agent.
If this is right
- The system can maintain consistent open-vocabulary labels across long robot trajectories without pre-built maps.
- It supports real-time target-oriented reasoning and map updates on physical robots.
- Performance gains appear in both 3D open-vocabulary semantic segmentation and full scene reconstruction.
- The same representation works for zero-shot 3D visual grounding when geometry is only self-reconstructed.
Where Pith is reading between the lines
- The same hybrid map could be tested in continuous navigation loops where new objects enter the scene mid-task.
- Integration with additional sensor modalities might further reduce reliance on visual cues alone for instance fusion.
- The reasoning agent structure could be applied to query-based map editing rather than only grounding.
- Results on self-reconstructed maps suggest the approach may reduce the need for separate mapping and understanding pipelines in embodied systems.
Load-bearing premise
Coupling a probabilistic voxel grid with explicit 3D Gaussians supplies enough cross-view cues for reliable instance association even when scenes undergo topological change.
What would settle it
A controlled sequence of views in which objects change topology or move such that the Gaussian relocalization and masked refinement produce inconsistent instance labels across time.
Figures




read the original abstract
Integrating open-vocabulary semantic information into dynamic 3D scene representations is essential for long-term embodied scene understanding. However, existing methods often suffer from fragile instance association due to incomplete cross-view cues, while their limited ability to handle object-level topological changes restricts long-term robotic task execution. Moreover, current 3D scene understanding methods either rely on simple feature matching without explicit spatial reasoning or assume offline ground-truth 3D geometry. To address these challenges, we present DGSG-Mind, a hybrid instance-aware 3D Gaussian dynamic scene graph system with an embodied reasoning agent. Our system couples a probabilistic voxel grid with explicit 3D Gaussians to enable robust cross-modal instance fusion and incremental semantic mapping. It handles dynamic changes through Gaussian-based visual relocalization and localized masked refinement guided by geometric-semantic consistency. Built on the instance Gaussian map, DGSG-Mind further constructs a hierarchical scene graph and develops the 3D Gaussian Mind, which integrates structural relations, spatial-semantic information, and visually annotated RoI Gaussian renderings for multimodal reasoning. Extensive experiments show that DGSG-Mind achieves the best zero-shot 3DVG performance among methods operating on self-reconstructed maps, while also delivering strong performance in 3D open-vocabulary semantic segmentation and scene reconstruction. We further deploy DGSG-Mind on real-world robots to demonstrate its target-oriented reasoning and dynamic update capabilities. The project page of DGSG-Mind is available at https://icr-lab.github.io/DGSG-Mind
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DGSG-Mind, a hybrid dynamic 3D Gaussian scene graph system that couples a probabilistic voxel grid with explicit 3D Gaussians to enable robust cross-modal instance fusion, incremental semantic mapping, and handling of dynamic object-level changes via Gaussian-based relocalization and masked refinement. It builds a hierarchical scene graph and introduces the 3D Gaussian Mind for multimodal reasoning integrating structural, spatial-semantic, and visual RoI information. The central claims are superior zero-shot 3D visual grounding (3DVG) performance among methods on self-reconstructed maps, strong results in open-vocabulary 3D semantic segmentation and scene reconstruction, and successful real-robot deployment for target-oriented reasoning.
Significance. If the hybrid fusion mechanism is shown to be necessary for the reported gains, the work could advance long-term embodied scene understanding by addressing fragile instance association and topological changes in dynamic environments without relying on offline ground-truth geometry. The real-world robot deployment provides concrete evidence of practical applicability beyond simulation benchmarks.
major comments (1)
- [Abstract / Experiments] Abstract and Experiments section: The headline claim of best zero-shot 3DVG performance among self-reconstructed-map methods is attributed to coupling the probabilistic voxel grid with explicit 3D Gaussians for 'robust cross-modal instance fusion,' yet no ablation studies (e.g., hybrid vs. Gaussians-only on identical reconstruction pipeline and 3DVG benchmarks) are reported to isolate this component's contribution versus downstream scene-graph or relocalization elements.
minor comments (2)
- [Abstract] Abstract: Quantitative results, dataset names, metric values, error bars, and experimental protocols are omitted, preventing direct assessment of the strength of the performance claims.
- [Experiments] The manuscript would benefit from explicit comparison tables or figures contrasting the hybrid design against recent 3D Gaussian and scene-graph baselines on the same self-reconstruction setting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The headline claim of best zero-shot 3DVG performance among self-reconstructed-map methods is attributed to coupling the probabilistic voxel grid with explicit 3D Gaussians for 'robust cross-modal instance fusion,' yet no ablation studies (e.g., hybrid vs. Gaussians-only on identical reconstruction pipeline and 3DVG benchmarks) are reported to isolate this component's contribution versus downstream scene-graph or relocalization elements.
Authors: We agree that the manuscript does not report the requested ablation isolating the hybrid probabilistic voxel grid + 3D Gaussians fusion from a Gaussians-only variant on an otherwise identical reconstruction and 3DVG pipeline. While the system is designed around this coupling and the full pipeline is compared against external baselines, the absence of this internal ablation leaves the specific contribution of the hybrid fusion less clearly quantified relative to the scene-graph and relocalization modules. In the revised manuscript we will add these experiments on the same 3DVG benchmarks. revision: yes
Circularity Check
No circularity: system description contains no derivations, equations, or self-referential predictions
full rationale
The manuscript describes an engineering system (hybrid voxel-Gaussian scene graph with embodied agent) whose central claims rest on experimental benchmarks and real-robot deployment rather than any mathematical derivation chain. No equations appear that could reduce a 'prediction' to a fitted input by construction, no self-citation is invoked as a uniqueness theorem, and the hybrid coupling is presented as a design contribution rather than derived from prior self-work. The paper is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
3D Gaussian Mind
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Seeground: See and ground for zero-shot open-vocabulary 3d visual grounding,
R. Li, S. Li, L. Kong, X. Yang, and J. Liang, “Seeground: See and ground for zero-shot open-vocabulary 3d visual grounding,” inCVPR, 2025, pp. 3707–3717
2025
-
[2]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” inICRA. IEEE, 2024, pp. 5021–5028
2024
-
[3]
Omnimap: A general mapping framework integrating optics, geometry, and semantics,
Y . Deng, Y . Yue, J. Dou, J. Zhao, J. Wang, Y . Tang, Y . Yang, and M. Fu, “Omnimap: A general mapping framework integrating optics, geometry, and semantics,”IEEE Transactions on Robotics, 2025
2025
-
[4]
Dynamic open-vocabulary 3d scene graphs for long-term language- guided mobile manipulation,
Z. Yan, S. Li, Z. Wang, L. Wu, H. Wang, J. Zhu, L. Chen, and J. Liu, “Dynamic open-vocabulary 3d scene graphs for long-term language- guided mobile manipulation,”RAL, 2025
2025
-
[5]
Dynamicgsg: Dynamic 3d gaussian scene graphs for environment adaptation,
L. Ge, X. Zhu, Z. Yang, and X. Li, “Dynamicgsg: Dynamic 3d gaussian scene graphs for environment adaptation,” inIROS. IEEE, 2025, pp. 2232–2239
2025
-
[6]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[7]
Hierarchical Open-V ocabulary 3D Scene Graphs for Language- Grounded Robot Navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hierarchical Open-V ocabulary 3D Scene Graphs for Language- Grounded Robot Navigation,” inRSS, Delft, Netherlands, July 2024
2024
-
[8]
Opengs- slam: Open-set dense semantic slam with 3d gaussian splatting for object-level scene understanding,
D. Yang, Y . Gao, X. Wang, Y . Yue, Y . Yang, and M. Fu, “Opengs- slam: Open-set dense semantic slam with 3d gaussian splatting for object-level scene understanding,” inICRA, 2025, pp. 8486–8492
2025
-
[9]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” inCVPR, 2024, pp. 20 051–20 060
2024
-
[10]
Opengs-fusion: Open-vocabulary dense mapping with hybrid 3d gaussian splatting for refined object-level understanding,
D. Yang, X. Wang, Y . Gao, S. Liu, B. Ren, Y . Yue, and Y . Yang, “Opengs-fusion: Open-vocabulary dense mapping with hybrid 3d gaussian splatting for refined object-level understanding,” inIROS, 2025, pp. 21 135–21 142
2025
-
[11]
Gaussian grouping: Segment and edit anything in 3d scenes,
M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian grouping: Segment and edit anything in 3d scenes,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 162–179
2024
-
[12]
Objectgs: Object-aware scene reconstruction and scene understanding via gaussian splatting,
R. Zhu, M. Yu, L. Xu, L. Jiang, Y . Li, T. Zhang, J. Pang, and B. Dai, “Objectgs: Object-aware scene reconstruction and scene understanding via gaussian splatting,” inICCV, 2025, pp. 8350–8360
2025
-
[13]
Visual programming for zero-shot open-vocabulary 3d visual grounding,
Z. Yuan, J. Ren, C.-M. Feng, H. Zhao, S. Cui, and Z. Li, “Visual programming for zero-shot open-vocabulary 3d visual grounding,” in CVPR, 2024, pp. 20 623–20 633
2024
-
[14]
Spazer: Spatial-semantic progressive reasoning agent for zero-shot 3d visual grounding,
Z. Jin, R.-C. Tu, J. Liao, W. Sun, X. Luo, S. Liu, and D. Tao, “Spazer: Spatial-semantic progressive reasoning agent for zero-shot 3d visual grounding,”NIPS, vol. 38, pp. 165 549–165 576, 2026
2026
-
[15]
Splatam: Splat track & map 3d gaussians for dense rgb-d slam,
N. Keetha, J. Karhade, K. M. Jatavallabhula, G. Yang, S. Scherer, D. Ramanan, and J. Luiten, “Splatam: Splat track & map 3d gaussians for dense rgb-d slam,” inCVPR, 2024, pp. 21 357–21 366
2024
-
[16]
Rgbd gs-icp slam,
S. Ha, J. Yeon, and H. Yu, “Rgbd gs-icp slam,” inECCV. Springer, 2024, pp. 180–197
2024
-
[17]
Gsfusion: Online rgb-d mapping where gaussian splatting meets tsdf fusion,
J. Wei and S. Leutenegger, “Gsfusion: Online rgb-d mapping where gaussian splatting meets tsdf fusion,”IEEE Robotics and Automation Letters, vol. 9, no. 12, pp. 11 865–11 872, 2024
2024
-
[18]
Segs-slam: Structure-enhanced 3d gaussian splatting slam with appearance embedding,
T. Wen, Z. Liu, and Y . Fang, “Segs-slam: Structure-enhanced 3d gaussian splatting slam with appearance embedding,” inICCV, 2025, pp. 28 103–28 113
2025
-
[19]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inEMNLP-IJCNLP, 2019, pp. 3982– 3992
2019
-
[20]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inICCV, 2023, pp. 11 975–11 986
2023
-
[21]
Foundations of spatial perception for robotics: Hierarchical representations and real-time systems,
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone, “Foundations of spatial perception for robotics: Hierarchical representations and real-time systems,”IJRR, 2024
2024
-
[22]
Beyond bare queries: Open- vocabulary object grounding with 3d scene graph,
S. Linok, T. Zemskova, S. Ladanova, R. Titkov, D. Yudin, M. Monastyrny, and A. Valenkov, “Beyond bare queries: Open- vocabulary object grounding with 3d scene graph,” inICRA. IEEE, 2025, pp. 13 582–13 589
2025
-
[23]
Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation,
H. Jiang, B. Huang, R. Wu, Z. Li, S. Garg, H. Nayyeri, S. Wang, and Y . Li, “Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation,”arXiv preprint arXiv:2402.15487, 2024
-
[24]
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses,
E. Brachmann, T. Cavallari, and V . A. Prisacariu, “Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses,” inCVPR, 2023, pp. 5044–5053
2023
-
[25]
Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,
J. Yang, X. Chen, S. Qian, N. Madaan, M. Iyengar, D. F. Fouhey, and J. Chai, “Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,” inICRA. IEEE, 2024, pp. 7694– 7701
2024
-
[26]
Yolo- world: Real-time open-vocabulary object detection,
T. Cheng, L. Song, Y . Ge, W. Liu, X. Wang, and Y . Shan, “Yolo- world: Real-time open-vocabulary object detection,” inCVPR, 2024, pp. 16 901–16 911
2024
-
[27]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inICCV, 2023, pp. 4015–4026
2023
-
[28]
Describe anything: Detailed localized image and video captioning,
L. Lian, Y . Ding, Y . Ge, S. Liu, H. Mao, B. Li, M. Pavone, M.-Y . Liu, T. Darrell, A. Yalaet al., “Describe anything: Detailed localized image and video captioning,” inICCV, 2025, pp. 21 766–21 777
2025
-
[29]
S. Bai, K. Chen, X. Liu, and J. W. et al., “Qwen2.5-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Vermaet al., “The replica dataset: A digital replica of indoor spaces,”arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[31]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inCVPR, 2017, pp. 5828–5839
2017
-
[32]
Scanrefer: 3d object localization in rgb-d scans using natural language,
D. Z. Chen, A. X. Chang, and M. Nießner, “Scanrefer: 3d object localization in rgb-d scans using natural language,” inECCV. Springer, 2020, pp. 202–221
2020
-
[33]
Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes,
P. Achlioptas, A. Abdelreheem, F. Xia, M. Elhoseiny, and L. Guibas, “Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes,” inECCV. Springer, 2020, pp. 422–440
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.