DVSM: Decoder-only View Synthesis Model Done Right
Pith reviewed 2026-06-29 08:37 UTC · model grok-4.3
The pith
Decoder-only architecture with KV-cache scene representation outperforms encoder-decoder models for novel view synthesis using fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
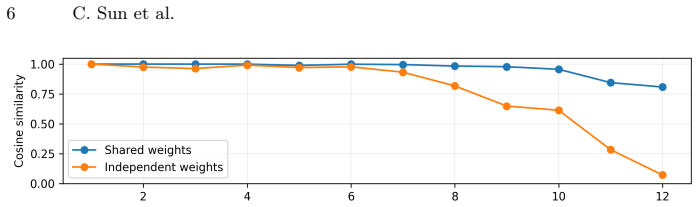
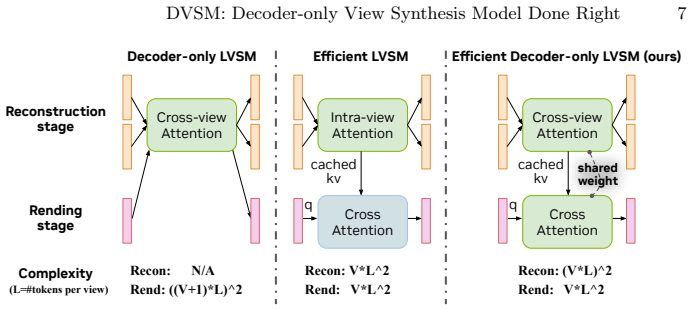
Through controlled experiments, a decoder-only architecture that represents scenes implicitly as a KV-cache outperforms encoder-decoder variants while using fewer parameters at identical rendering complexity. Sharing weights between the color-input reconstruction network and the camera-only rendering network better aligns their features at the same viewpoint, facilitating image synthesis. Building on this, the model incorporates foundation model priors and stage-wise patch sizing for an improved efficiency-quality tradeoff and establishes a new state of the art for novel-view synthesis across multiple benchmarks.
What carries the argument
Decoder-only network that represents scenes implicitly as a KV-cache, with weight sharing between the reconstruction and rendering networks.
If this is right
- Decoder-only designs achieve better performance with reduced parameter counts at fixed rendering complexity.
- Weight sharing between reconstruction and rendering networks improves feature alignment for synthesis.
- Foundation model priors combined with stage-wise patch sizing yield better efficiency-quality tradeoffs.
- New state-of-the-art results on multiple novel-view synthesis benchmarks, sometimes exceeding per-scene optimized methods under dense views.
Where Pith is reading between the lines
- If the KV-cache representation generalizes, it may allow view synthesis models to handle more complex scenes without explicit 3D structures.
- The design could simplify pipelines by eliminating separate encoder modules in related rendering tasks.
- Testing on dynamic scenes would reveal whether the implicit caching approach extends beyond static novel view synthesis.
Load-bearing premise
The controlled experiments fairly isolate the effect of encoder-decoder versus decoder-only design without unstated differences in training procedure, data, or optimization.
What would settle it
Reproducing the experiments with exactly matched training procedures, datasets, and optimizers for both architectures and finding no performance advantage for the decoder-only version.
Figures





read the original abstract
Recent Large View Synthesis Models (LVSMs) advocate an encoder-decoder architecture that separates reconstruction and rendering into distinct networks. We re-examine this design. Through controlled experiments, we show that a decoder-only architecture, which represents scenes implicitly as a KV-cache, outperforms encoder-decoder variants while using fewer parameters at identical rendering complexity. Further analysis shows that sharing weights between the color-input reconstruction network and the camera-only rendering network better aligns their features at the same viewpoint, facilitating image synthesis. Building on this finding, our model, dubbed DVSM, further incorporates foundation model priors and stage-wise patch sizing for an improved efficiency-quality tradeoff. Our results establish a new state of the art for novel-view synthesis across multiple benchmarks, in some cases even outperforming per-scene-optimized 3DGS under dense input views.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that encoder-decoder architectures in large view synthesis models are suboptimal; through controlled experiments it shows a decoder-only model (representing scenes implicitly via KV-cache) outperforms them with fewer parameters at matched rendering complexity, that weight sharing between reconstruction and rendering networks improves feature alignment at the same viewpoint, and that adding foundation-model priors plus stage-wise patch sizing yields a new SOTA on multiple novel-view-synthesis benchmarks, sometimes surpassing per-scene 3DGS under dense inputs.
Significance. If the controlled experiments isolate architecture from training and data differences, the result would challenge the prevailing encoder-decoder paradigm for LVSMs, demonstrate the utility of implicit KV-cache scene representations, and provide a concrete efficiency-quality improvement path via weight sharing and staged training. The work supplies an empirical architecture comparison rather than a parameter-free derivation.
major comments (2)
- [§4.2] §4.2 (Controlled Experiments): the manuscript states that decoder-only and encoder-decoder variants were compared “under identical rendering complexity” but does not list the exact hyper-parameters (learning rate schedule, batch size, data augmentation, optimizer settings) used for each; without an explicit statement or table confirming these were held fixed, the reported gains cannot be unambiguously attributed to the architectural choice versus unstated procedural differences.
- [§3.3] §3.3 (Weight Sharing Analysis): the claim that weight sharing “better aligns their features at the same viewpoint” is supported only by qualitative feature visualizations; a quantitative metric (e.g., cosine similarity or mutual information between reconstruction and rendering features before/after sharing) is needed to substantiate that this alignment is the causal mechanism for the observed PSNR/SSIM gains.
minor comments (2)
- [Table 2] Table 2 caption should explicitly state whether the reported parameter counts include the foundation-model backbone or only the task-specific layers.
- [§3.4] The stage-wise patch sizing schedule (progression from 8×8 to 64×64) is described in §3.4 but the exact epoch boundaries and learning-rate resets at each stage are not tabulated; a supplementary table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Both points identify areas where additional documentation or metrics would strengthen the manuscript, and we will revise accordingly.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Controlled Experiments): the manuscript states that decoder-only and encoder-decoder variants were compared “under identical rendering complexity” but does not list the exact hyper-parameters (learning rate schedule, batch size, data augmentation, optimizer settings) used for each; without an explicit statement or table confirming these were held fixed, the reported gains cannot be unambiguously attributed to the architectural choice versus unstated procedural differences.
Authors: We agree that an explicit listing of hyper-parameters is necessary to unambiguously attribute the gains to the architectural choice. The experiments were performed with identical settings across variants, but this was not tabulated. In the revised manuscript we will add a table in §4.2 that enumerates learning rate schedule, batch size, data augmentation, optimizer, and all other training details, confirming they were held fixed. revision: yes
-
Referee: [§3.3] §3.3 (Weight Sharing Analysis): the claim that weight sharing “better aligns their features at the same viewpoint” is supported only by qualitative feature visualizations; a quantitative metric (e.g., cosine similarity or mutual information between reconstruction and rendering features before/after sharing) is needed to substantiate that this alignment is the causal mechanism for the observed PSNR/SSIM gains.
Authors: We acknowledge that the current evidence is qualitative. A quantitative metric would provide stronger support for the claimed mechanism. In the revision we will report average cosine similarity (and optionally mutual information) between the reconstruction-network and rendering-network features at matched viewpoints, computed both before and after weight sharing, to quantify the alignment improvement. revision: yes
Circularity Check
Empirical architecture comparison exhibits no circularity
full rationale
The paper reports controlled experiments comparing decoder-only vs. encoder-decoder architectures for novel view synthesis, with claims resting on measured performance differences rather than any analytical derivation. No equations, predictions, or first-principles results are presented that reduce by construction to fitted parameters, self-citations, or ansatzes within the paper. The work is self-contained as an empirical study; the central claim (decoder-only superiority at fixed rendering complexity) is supported by experimental isolation rather than definitional equivalence or load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: EMNLP (2023)
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebr’on, F., Sanghai, S.K.: Gqa: Training generalized multi-query transformer models from multi-head checkpoints. In: EMNLP (2023)
2023
-
[2]
In: ICCV (2025)
Bai, J., Xia, M., Fu, X., Wang, X., Mu, L., Cao, J., Liu, Z., Hu, H., Bai, X., Wan, P., Zhang, D.: Recammaster: Camera-controlled generative rendering from a single video. In: ICCV (2025)
2025
-
[3]
In: CVPR (2022)
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In: CVPR (2022)
2022
-
[4]
In: ICLR (2023)
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. In: ICLR (2023)
2023
-
[5]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
Cao, C., Zhou, J., Li, S., Liang, J., Yu, C., Wang, F., Xue, X., Fu, Y.: Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video gen- eration. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
2025
-
[6]
In: ICCV (2021)
Caron, M., Touvron, H., Misra, I., J’egou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: ICCV (2021)
2021
-
[7]
In: CVPR (2021)
Chan, E., Lin, C.Z., Chan, M.A., Nagano, K., Pan, B., Mello, S.D., Gallo, O., Guibas, L.J., Tremblay, J., Khamis, S., Karras, T., Wetzstein, G.: Efficient geometry-aware 3d generative adversarial networks. In: CVPR (2021)
2021
-
[8]
In: CVPR (2024)
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V.: Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: CVPR (2024)
2024
-
[9]
In: ECCV (2022)
Chen, A., Xu, Z., Geiger, A., Yu, J., Su, H.: Tensorf: Tensorial radiance fields. In: ECCV (2022)
2022
-
[10]
In: ICCV (2021)
Chen, A., Xu, Z., Zhao, F., Zhang, X., Xiang, F., Yu, J., Su, H.: Mvsnerf: Fast gen- eralizable radiance field reconstruction from multi-view stereo. In: ICCV (2021)
2021
-
[11]
In: ECCV (2024)
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: ECCV (2024)
2024
-
[12]
Long-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction
Chen, Z., Tan, H., Wang, P., Xu, Z., Li, F.: Long-lrm++: Preserving fine details in feed-forward wide-coverage reconstruction. arXiv preprint arXiv:2512.10267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: ICCV (2025)
Chen, Z., Tan, H., Zhang, K., Bi, S., Luan, F., Hong, Y., Li, F., Xu, Z.: Long-lrm: Long-sequence large reconstruction model for wide-coverage gaussian splats. In: ICCV (2025)
2025
-
[14]
Choudhury, R., Kim, J., Park, J., Yang, E., Jeni, L.A., Kitani, K.M.: Accelerating vision transformers with adaptive patch sizes (2025)
2025
-
[15]
In: ICML (2024)
Dao, T., Gu, A.: Transformers are ssms: Generalized models and efficient algo- rithms through structured state space duality. In: ICML (2024)
2024
-
[16]
In: ICLR (2024)
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. In: ICLR (2024)
2024
-
[17]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: Animageisworth16x16words:Transformersforimagerecognitionatscale(2021)
2021
-
[18]
In: CVPR (2023)
Du, Y., Smith, C., Tewari, A., Sitzmann, V.: Learning to render novel views from wide-baseline stereo pairs. In: CVPR (2023)
2023
-
[19]
In: CVPR (2022) 16 C
Fridovich-Keil, S., Yu, A., Tancik, M., Chen, Q., Recht, B., Kanazawa, A.: Plenox- els: Radiance fields without neural networks. In: CVPR (2022) 16 C. Sun et al
2022
-
[20]
In: ICCV (2025)
Govindarajan,S.,Rebain,D.,Yi,K.M.,Tagliasacchi,A.:Radiantfoam:Real-time differentiable ray tracing. In: ICCV (2025)
2025
-
[21]
In: CVPR (2019)
Gu, X., Fan, Z., Zhu, S., Dai, Z., Tan, F., Tan, P.: Cascade cost volume for high-resolution multi-view stereo and stereo matching. In: CVPR (2019)
2019
-
[22]
In: CVPR (2019)
Guo, X., Yang, K., Yang, W., Wang, X., Li, H.: Group-wise correlation stereo network. In: CVPR (2019)
2019
-
[23]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
2016
-
[24]
In: CVPR (2024)
Heinrich, G., Ranzinger, M., Yin, H., Lu, Y., Kautz, J., Tao, A., Catanzaro, B., Molchanov, P.: Radiov2.5: Improved baselines for agglomerative vision foundation models. In: CVPR (2024)
2024
-
[25]
In: EMNLP (2020)
Henry, A., Dachapally, P.R., Pawar, S.S., Chen, Y.: Query-key normalization for transformers. In: EMNLP (2020)
2020
-
[26]
In: CVPR (2024)
Hong, S., Jung, J., Shin, H., Yang, J., Kim, S., Luo, C.: Unifying correspondence, pose and nerf for generalized pose-free novel view synthesis. In: CVPR (2024)
2024
-
[27]
In: ICLR (2024)
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: LRM: large reconstruction model for single image to 3d. In: ICLR (2024)
2024
-
[28]
arXiv preprint arXiv:2602.06478 (2026)
Jia, X., Sun, Y., You, J., Wong, S., Zou, Z., Yan, J., Wu, Z., Jiang, Y.G.: Efficient- lvsm: Faster, cheaper and and better large view synthesis model via decoupled co-refinement attention. arXiv preprint arXiv:2602.06478 (2026)
-
[29]
In: ICCV (2025)
Jiang, H., Tan, H., Wang, P., Jin, H., Zhao, Y., Bi, S., Zhang, K., Luan, F., Sunkavalli, K., Huang, Q., Pavlakos, G.: Rayzer: A self-supervised large view synthesis model. In: ICCV (2025)
2025
-
[30]
In: ICLR (2025)
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: LVSM: A large view synthesis model with minimal 3d inductive bias. In: ICLR (2025)
2025
-
[31]
In: ECCV (2016)
Johnson, J., Alahi, A., Li, F.F.: Perceptual losses for real-time style transfer and super-resolution. In: ECCV (2016)
2016
-
[32]
ACM TOG (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM TOG (2023)
2023
-
[33]
In: CVPR (2022)
Khakhulin, T., Korzhenkov, D., Solovev, P., Sterkin, G., Ardelean, A., Lempitsky, V.: Stereo magnification with multi-layer images. In: CVPR (2022)
2022
-
[34]
arXiv preprint arXiv:2602.21341 (2026)
Kim, E., Ryu, H., Mitchel, T.W., Sitzmann, V.: Scaling view synthesis transform- ers. arXiv preprint arXiv:2602.21341 (2026)
-
[35]
In: CVPR (2024)
Kong, X., Liu, S., Lyu, X., Taher, M., Qi, X., Davison, A.J.: Eschernet: A gener- ative model for scalable view synthesis. In: CVPR (2024)
2024
-
[36]
Li, R., Yi, B., Liu, J., Gao, H., Ma, Y., Kanazawa, A.: Cameras as relative posi- tional encoding. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[37]
Liang, H., Ren, J., Mirzaei, A., Torralba, A., Liu, Z., Gilitschenski, I., Fidler, S., Oztireli, C., Ling, H., Gojcic, Z., Huang, J.: Feed-forward bullet-time reconstruc- tion of dynamic scenes from monocular videos. Adv. Neural Inform. Process. Syst. (2025)
2025
-
[38]
In: ICCV (2025)
Lin, C., Sun, C., Yang, F., Chen, M., Lin, Y., Liu, Y.: Longsplat: Robust unposed 3d gaussian splatting for casual long videos. In: ICCV (2025)
2025
-
[39]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arxiv preprint arxiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: CVPR (2024)
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., Li, X., Sun, X., Ashok, R., Mukherjee, A., Kang, H., Kong, X., Hua, G., DVSM: Decoder-only View Synthesis Model Done Right 17 Zhang, T., Benes, B., Bera, A.: DL3DV-10K: A large-scale scene dataset for deep learning-based 3d vision. In: CVPR (2024)
2024
-
[41]
In: ICLR (2024)
Liu, Y., Lin, C.H., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Sync- dreamer: Generating multiview-consistent images from a single-view image. In: ICLR (2024)
2024
-
[42]
In: CVPR (2022)
Liu, Y., Peng, S., Liu, L., Wang, Q., Wang, P., Theobalt, C., Zhou, X., Wang, W.: Neural rays for occlusion-aware image-based rendering. In: CVPR (2022)
2022
-
[43]
In: CVPR (2024)
Long, X., Guo, Y., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Haber- mann, M., Theobalt, C., Wang, W.: Wonder3d: Single image to 3d using cross- domain diffusion. In: CVPR (2024)
2024
-
[44]
In: ICLR (2017)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2017)
2017
-
[45]
von Lützow, N., Nießner, M.: Linprim: Linear primitives for differentiable volu- metric rendering. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[46]
IEEE TVCG (1995)
Max, N.L.: Optical models for direct volume rendering. IEEE TVCG (1995)
1995
-
[47]
In: CVPR (2023)
Meuleman, A., Liu, Y., Gao, C., Huang, J.B., Kim, C., Kim, M.H., Kopf, J.: Progressively optimized local radiance fields for robust view synthesis. In: CVPR (2023)
2023
-
[48]
SIGGRAPH (2019)
Mildenhall, B., Srinivasan, P.P., Cayon, R.O., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: practical view synthesis with prescriptive sampling guidelines. SIGGRAPH (2019)
2019
-
[49]
In: ECCV (2020)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
2020
-
[50]
arXiv preprint arXiv:2510.13063 (2025)
Mitchel, T.W., Ryu, H., Sitzmann, V.: True self-supervised novel view synthesis is transferable. arXiv preprint arXiv:2510.13063 (2025)
-
[51]
ACM TOG (2024)
Moenne-Loccoz, N., Mirzaei, A., Perel, O., de Lutio, R., Esturo, J.M., State, G., Fidler, S., Sharp, N., Gojcic, Z.: 3d gaussian ray tracing: Fast tracing of particle scenes. ACM TOG (2024)
2024
-
[52]
ACM TOG (2022)
Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM TOG (2022)
2022
-
[53]
TMLR (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y.B., Li, S.W., Misra, I., Rabbat, M.G., Sharma, V., Synnaeve, G., Xu, H., Jégou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual ...
2024
-
[54]
Philosophical Transactions of the Royal Society of London (1865)
Plucker, J.: On a new geometry of space. Philosophical Transactions of the Royal Society of London (1865)
-
[55]
In: Machine Learning and Systems (2023)
Pope, R., Douglas, S., Chowdhery, A., Devlin, J., Bradbury, J., Levskaya, A., Heek, J., Xiao, K., Agrawal, S., Dean, J.: Efficiently scaling transformer inference. In: Machine Learning and Systems (2023)
2023
-
[56]
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., et al.: Gated attention for large language models: Non- linearity, sparsity, and attention-sink-free. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[57]
In: CVPR (2023)
Ranzinger, M., Heinrich, G., Kautz, J., Molchanov, P.: Am-radio: Agglomerative vision foundation model reduce all domains into one. In: CVPR (2023)
2023
-
[58]
In: ICCV (2021) 18 C
Reiser, C., Peng, S., Liao, Y., Geiger, A.: Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In: ICCV (2021) 18 C. Sun et al
2021
-
[59]
In: CVPR (2025)
Ren, X., Shen, T., Huang, J., Ling, H., Lu, Y., Nimier-David, M., Muller, T., Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video gener- ation with precise camera control. In: CVPR (2025)
2025
-
[60]
In: ICCV (2021)
Rombach, R., Esser, P., Ommer, B.: Geometry-free view synthesis: Transformers and no 3d priors. In: ICCV (2021)
2021
-
[61]
In: CVPR (2022)
Sajjadi, M.S.M., Meyer, H., Pot, E., Bergmann, U., Greff, K., Radwan, N., Vora, S., Lucic, M., Duckworth, D., Dosovitskiy, A., Uszkoreit, J., Funkhouser, T.A., Tagliasacchi, A.: Scene representation transformer: Geometry-free novel view syn- thesis through set-latent scene representations. In: CVPR (2022)
2022
-
[62]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N.: Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[63]
In: CVPR (2016)
Shi, W., Caballero, J., Huszár, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert, D., Wang, Z.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR (2016)
2016
-
[64]
Sim’eoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrst- edt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., J’egou, H., Labatut, P., Bo- janowski, P.: Dinov3. arXiv pr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Sitzmann, V., Rezchikov, S., Freeman, W.T., Tenenbaum, J.B., Durand, F.: Light field networks: Neural scene representations with single-evaluation rendering. In: Adv. Neural Inform. Process. Syst. (2021)
2021
-
[66]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Smart, B., Zheng, C., Laina, I., Prisacariu, V.A.: Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs. arXiv preprint arXiv:2408.13912 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
IEEE TPAMI (2021)
Suhail, M., Esteves, C., Sigal, L., Makadia, A.: Light field neural rendering. IEEE TPAMI (2021)
2021
-
[68]
In: ECCV (2022)
Suhail, M., Esteves, C., Sigal, L., Makadia, A.: Generalizable patch-based neural rendering. In: ECCV (2022)
2022
-
[69]
In: CVPR (2025)
Sun, C., Choe, J., Loop, C., Ma, W., Wang, Y.F.: Sparse voxels rasterization: Real-time high-fidelity radiance field rendering. In: CVPR (2025)
2025
-
[70]
In: CVPR (2022)
Sun, C., Sun, M., Chen, H.T.: Direct voxel grid optimization: Super-fast conver- gence for radiance fields reconstruction. In: CVPR (2022)
2022
-
[71]
In: ICML (2025)
Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, O., Hashimoto, T., Guestrin, C.: Learning to (learn at test time): Rnns with expressive hidden states. In: ICML (2025)
2025
-
[72]
3DV (2024)
Szymanowicz, S., Insafutdinov, E., Zheng, C., Campbell, D., Henriques, J.F., Rupprecht, C., Vedaldi, A.: Flash3d: Feed-forward generalisable 3d scene recon- struction from a single image. 3DV (2024)
2024
-
[73]
In: SIGGRAPH (2023)
Tancik, M., Weber, E., Ng, E., Li, R., Yi, B., Wang, T., Kristoffersen, A., Austin, J., Salahi, K., Ahuja, A., et al.: Nerfstudio: A modular framework for neural radiance field development. In: SIGGRAPH (2023)
2023
-
[74]
In: ECCV (2024)
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi-view gaussian model for high-resolution 3d content creation. In: ECCV (2024)
2024
-
[75]
In: ECCV (2024)
Tang, S., Chen, J., Wang, D., Tang, C., Zhang, F., Fan, Y., Chandra, V., Fu- rukawa, Y., Ranjan, R.: Mvdiffusion++: A dense high-resolution multi-view dif- fusion model for single or sparse-view 3d object reconstruction. In: ECCV (2024)
2024
-
[76]
In: NeurIPS (2023)
Tang, S., Zhang, F., Chen, J., Wang, P., Furukawa, Y.: Mvdiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion. In: NeurIPS (2023)
2023
-
[77]
In: AAAI (2025) DVSM: Decoder-only View Synthesis Model Done Right 19
Tobiasz, R., Wilczy’nski, G., Mazur, M., Tadeja, S.K., Spurek, P.: Meshsplats: Mesh-based rendering with gaussian splatting initialization. In: AAAI (2025) DVSM: Decoder-only View Synthesis Model Done Right 19
2025
-
[78]
In: NeurIPS (2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: NeurIPS (2017)
2017
-
[79]
arXiv preprint arXiv:2602.20160 (2026)
Wang, C., Tan, H., Yifan, W., Chen, Z., Liu, Y., Sunkavalli, K., Bi, S., Liu, L., Hu, Y.: tttlrm: Test-time training for long context and autoregressive 3d recon- struction. arXiv preprint arXiv:2602.20160 (2026)
-
[80]
Wang, H., Ye, K., Li, Y., Chen, W., Chen, B.: The less you depend, the more you learn: Synthesizing novel views from sparse, unposed images without any 3d knowledge. arXiv preprint arXiv:2506.09885 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.