HoliTok:A Coutinuous Holistic Tokenization with Robust Dual Capabilities of Speech Generation and Understanding
Pith reviewed 2026-06-29 05:52 UTC · model grok-4.3
The pith
HoliTok turns 48 kHz speech into 25 Hz continuous latents that support both generation and understanding in one model without extra tricks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
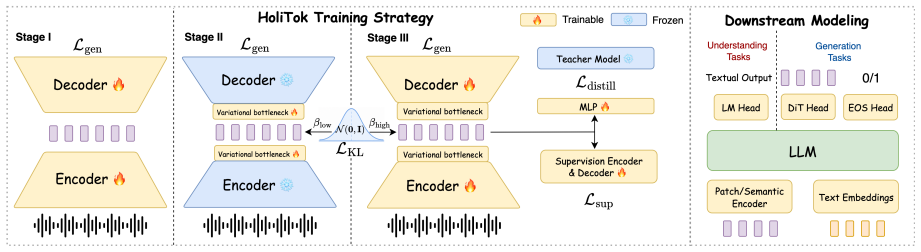
HoliTok encodes 48 kHz speech into a 25 Hz sequence of 128-dimensional continuous latents through progressive training that simultaneously preserves signal fidelity, adds semantic information, and keeps the latents learnable by language models. When these latents drive a unified AR+DiT model, the same sequence supports both generation-specific tasks and joint generation-understanding tasks, and it is the only evaluated representation that does so robustly without additional optimization tricks.
What carries the argument
The progressive training strategy that jointly preserves signal-level fidelity, incorporates semantic information, and maintains strong latent learnability for language models.
If this is right
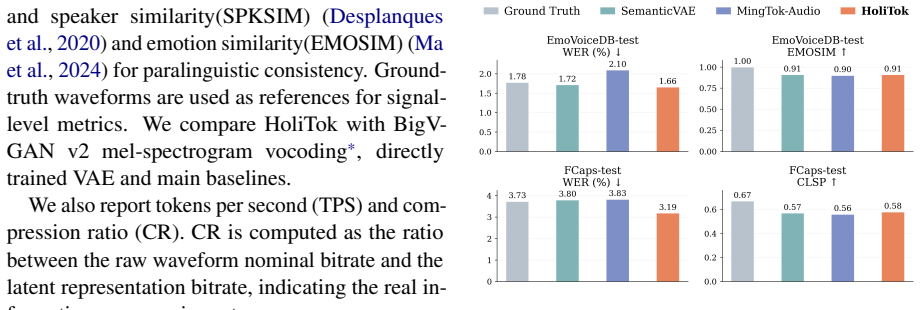
- The tokenizer delivers competitive reconstruction quality from the 25 Hz latents back to 48 kHz waveforms.
- The same latents improve generative learnability, enabling high-quality and controllable speech synthesis.
- The representation works in a unified generation-understanding setup without requiring task-specific adjustments.
- HoliTok functions as both an effective speech tokenizer and a foundational interface for unified spoken language modeling.
Where Pith is reading between the lines
- The 25 Hz rate may trade temporal resolution for semantic stability, suggesting tests on tasks that need fine timing such as prosody control.
- Extending the same progressive training to non-speech audio could test whether the dual generation-understanding property generalizes beyond speech.
- Because the latents are continuous rather than discrete, downstream models might benefit from direct gradient flow during joint training of tokenizer and language model.
Load-bearing premise
The progressive training can achieve high signal fidelity, semantic content, and language-model learnability at the same time without hidden trade-offs or the need for later fixes.
What would settle it
A direct comparison in the same unified AR+DiT architecture where another tokenizer matches or exceeds HoliTok performance on both synthesis and recognition tasks with no added optimization steps.
Figures
read the original abstract
Unified speech foundation models require a holistic tokenization space that is both learnable by language models and decodable into high-quality waveforms. Existing speech tokenizers, however, often fail to satisfy these requirements simultaneously, leading to increased architectural complexity and more involved training designs. We propose HoliTok, a continuous Holistic speech Tokenization model designed for unified generation-understanding modeling. HoliTok encodes 48~kHz speech into a compact 25~Hz sequence of 128-dimensional latents. It is trained with a progressive strategy that jointly preserves signal-level fidelity, incorporates semantic information, and maintains strong latent learnability. Based on this tokenization, we build a unified AR+DiT model for speech synthesis and recognition, where the same latent sequence supports both generation-specific and unified generation-understanding tasks. Experiments show that HoliTok achieves competitive reconstruction fidelity, improves generative learnability for high-quality and controllable synthesis, and, among the evaluated representations, is the only one that operates robustly in our unified generation-understanding architecture without additional optimization tricks. These results suggest that HoliTok serves as an effective speech tokenizer and a foundational representation interface for unified spoken language modeling. The code is available at: https://github.com/bovod-sjtu/HoliTok.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HoliTok, a continuous holistic speech tokenizer that encodes 48 kHz audio into compact 25 Hz sequences of 128-dimensional latents. It employs a progressive training strategy intended to simultaneously preserve signal-level fidelity, incorporate semantic information, and ensure strong latent learnability for language models. These latents are then used within a unified AR+DiT architecture to support both speech synthesis (generation) and recognition (understanding) tasks without task-specific adjustments. The central experimental claims are competitive reconstruction fidelity, improved generative learnability for high-quality and controllable synthesis, and that HoliTok is the only evaluated representation that operates robustly in the unified architecture without additional optimization tricks. Code is released at https://github.com/bovod-sjtu/HoliTok.
Significance. If the robustness and performance claims are substantiated with controlled experiments, HoliTok could reduce architectural complexity in unified speech foundation models by providing a single representation usable for both generation and understanding. The public code release is a clear strength that enables direct reproducibility and extension by the community.
major comments (1)
- [Abstract] Abstract: The load-bearing claim that 'among the evaluated representations, HoliTok is the only one that operates robustly in our unified generation-understanding architecture without additional optimization tricks' requires explicit evidence that the AR+DiT model, training procedure, and all hyperparameters were held identical across every compared tokenizer (continuous and discrete). No such statement, table, or section is referenced confirming this control; without it, observed differences could arise from architecture mismatch (e.g., handling of 128-dim continuous latents at 25 Hz or the progressive schedule) rather than intrinsic properties of the tokenizers.
minor comments (1)
- [Abstract] The abstract summarizes results as 'competitive' and 'improves' without citing specific tables, figures, or quantitative metrics (e.g., reconstruction error, WER, or MOS scores), which reduces immediate clarity even if such details appear later in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the need to strengthen the documentation of our experimental controls. We address the comment below and will revise the manuscript to provide the requested explicit evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that 'among the evaluated representations, HoliTok is the only one that operates robustly in our unified generation-understanding architecture without additional optimization tricks' requires explicit evidence that the AR+DiT model, training procedure, and all hyperparameters were held identical across every compared tokenizer (continuous and discrete). No such statement, table, or section is referenced confirming this control; without it, observed differences could arise from architecture mismatch (e.g., handling of 128-dim continuous latents at 25 Hz or the progressive schedule) rather than intrinsic properties of the tokenizers.
Authors: We confirm that the AR+DiT model architecture, training procedure, optimizer settings, learning rate schedule, batch size, number of training steps, and all other hyperparameters were held strictly identical across every compared tokenizer (both continuous and discrete) in the unified generation-understanding experiments. The only variable was the input representation itself. To make this control explicit and address the absence of a dedicated statement or table, we will add a new subsection (Section 4.2 in the revised manuscript) titled 'Controlled Experimental Setup for Unified Modeling' that describes the shared architecture and hyperparameters in detail, accompanied by a summary table listing the fixed configurations. This revision will also include a brief note in the abstract and Section 4.1 cross-referencing the new subsection. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external evaluation rather than definitional reduction.
full rationale
The paper proposes HoliTok via a progressive training strategy and evaluates it empirically against other representations in a unified AR+DiT architecture. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would make the robustness claim or reconstruction fidelity reduce to inputs by construction. The central claim (unique robust operation without tricks) is presented as an experimental outcome, not a mathematical identity or self-referential fit. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
dots.tts Technical Report
dots.tts reports SOTA benchmark results on Seed-TTS-Eval and other tests via continuous latent-space autoregressive modeling with three listed innovations and code release.
Reference graph
Works this paper leans on
-
[1]
Seed-x: Multimodal models with unified multi- granularity comprehension and generation.Preprint, arXiv:2404.14396. Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE International Conference...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
InInterspeech 2021, pages 2756–2760
AISHELL-3: A Multi-Speaker Mandarin TTS Corpus. InInterspeech 2021, pages 2756–2760. Cees H. Taal, Richard C. Hendriks, Richard Heusdens, and Jesper Jensen. 2010. A short-time objective intel- ligibility measure for time-frequency weighted noisy speech. In2010 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 4214– 4217. Kang...
2021
-
[3]
Show-o2: Improved native unified multimodal models.Advances in Neural Information Processing Systems, 38:47490–47518. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025a. Qwen2.5-omni technical report. Preprint, arXiv:2503.20215. Jin Xu, Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
arXiv preprint arXiv:2511.05516 , year=
Ming-uniaudio: Speech llm for joint under- standing, generation and editing with unified repre- sentation.Preprint, arXiv:2511.05516. Guanrou Yang, Tian Tan, Qian Chen, Zhikang Niu, Yakun Song, Ziyang Ma, Yushen Chen, Zeyu Xie, Tianrui Wang, Yifan Yang, Wenxi Chen, Qi Chen, Wenrui Liu, Shan Yang, and Xie Chen. 2026a. Wavcube: Unifying speech representatio...
-
[5]
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Emovoice: Llm-based emotional text-to- speech model with freestyle text prompting. InPro- ceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 10748–10757, New York, NY , USA. Association for Computing Machin- ery. Yifan Yang, Bing Han, Hui Wang, Wei Wang, Ziyang Ma, Long Zhou, Zengrui Jin, Guanrou Yang, Tian- rui Wang, Xu Tan, an...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.