Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
Pith reviewed 2026-06-29 07:28 UTC · model grok-4.3
The pith
Penalizing uncertain memory summaries lets LLM agents keep performance at 1.75M-token scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
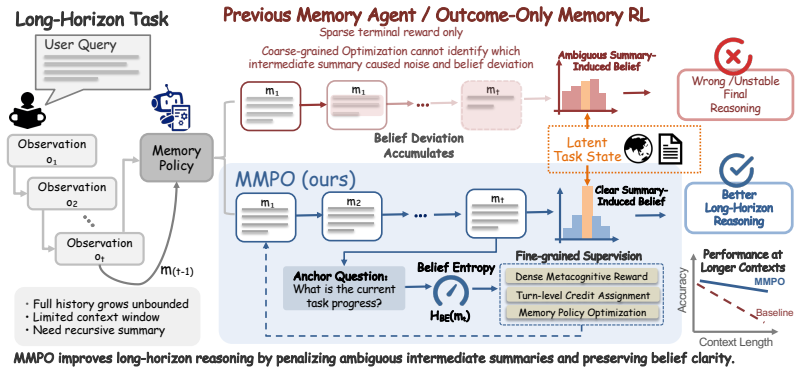
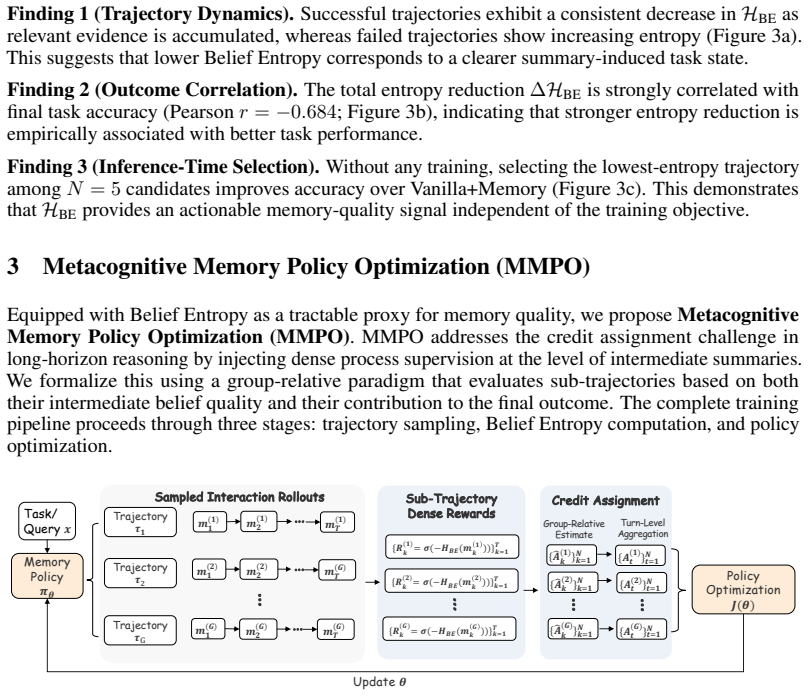
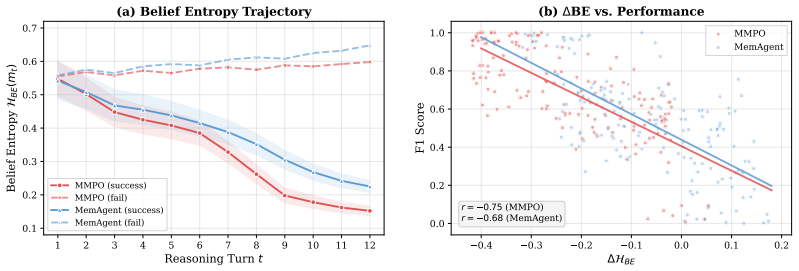
The paper claims that memory optimization for long-horizon LLM agents should target the clarity of the belief induced by intermediate summaries rather than trajectory-level success alone. Belief Entropy acts as a self-supervised proxy for the epistemic uncertainty the model holds about the latent task state given its current memory. MMPO uses this proxy to penalize high-entropy summaries during training, replacing sparse outcome-based reinforcement learning with memory-specific supervision that directly counters progressive belief deviation.
What carries the argument
Belief Entropy, a self-supervised proxy that quantifies the model's remaining uncertainty about the latent task state given its current memory summary.
If this is right
- MMPO outperforms prior outcome-based memory policies on diverse long-horizon tasks.
- Performance holds at 97.1 percent when context length reaches 1.75 million tokens.
- Training supplies fine-grained supervision at each summary step instead of sparse final rewards.
- Recursive summarization produces less progressive loss of task-relevant information.
Where Pith is reading between the lines
- The same entropy signal could diagnose memory quality in any agent that maintains compressed internal state, not only LLM summarizers.
- The approach may extend to compression methods other than natural-language summaries if an analogous uncertainty measure can be defined.
- Longer-horizon experiments could test whether the same penalty continues to prevent belief deviation beyond the lengths already measured.
Load-bearing premise
Belief Entropy reliably tracks how clear or degraded the agent's estimate of the task state has become after each summary, and lowering it improves reasoning without harming other behaviors.
What would settle it
A run of MMPO in which belief entropy drops yet the agent still loses track of task-critical facts or shows no gain in final success rate.
Figures

read the original abstract
Memory-augmented LLM agents tackle complex long-horizon tasks by recursively summarizing interaction trajectories into compact memory. However, existing approaches typically train these memory policies using outcome-based reinforcement learning, failing to localize where intermediate memory quality degrades. As interactions unfold, ambiguous recursive summaries progressively discard task-relevant information and introduce semantic noise. This exacerbates belief deviation, obscuring the agent's estimate of the latent task state and ultimately derailing long-horizon reasoning. We therefore argue that memory optimization should focus not merely on trajectory-level success, but on the clarity of the belief induced by intermediate summaries. To this end, we introduce Belief Entropy, a self-supervised proxy that probes how uncertain the model remains about the latent task state given its current memory. Based on this proxy, we propose Metacognitive Memory Policy Optimization (MMPO). Instead of relying only on sparse outcome-based signals, MMPO provides fine-grained, memory-specific supervision via explicitly penalizing summaries that induce high epistemic uncertainty. Experiments show that MMPO consistently outperforms existing methods on diverse long-horizon tasks, maintaining 97.1% performance even when scaled to 1.75M-token contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Belief Entropy, a self-supervised proxy for epistemic uncertainty induced by recursive memory summaries in LLM agents, and proposes Metacognitive Memory Policy Optimization (MMPO) to penalize high-uncertainty summaries during policy optimization. This provides fine-grained supervision beyond sparse outcome-based RL signals. The central empirical claim is that MMPO consistently outperforms existing methods on diverse long-horizon tasks while maintaining 97.1% performance at 1.75M-token contexts.
Significance. If the Belief Entropy proxy is shown to correlate with actual belief deviation and the performance gains are isolated to the metacognitive penalty, the work could meaningfully advance memory-augmented agents by localizing and mitigating information loss in long-horizon reasoning. The self-supervised nature and scaling result to very long contexts would be notable strengths if rigorously supported.
major comments (2)
- [Abstract] Abstract: The performance claim (97.1% at 1.75M tokens) is reported without any description of baselines, variance across runs, data exclusion criteria, or the precise computation of Belief Entropy, rendering it impossible to assess whether the data supports the outperformance claim or whether gains are attributable to the proposed penalty rather than other unisolated changes.
- [Abstract] The central claim that penalizing high Belief Entropy improves long-horizon reasoning rests on this quantity faithfully tracking degradation in the agent's estimate of the latent task state. No evidence is provided of correlation between Belief Entropy and downstream task failure, information loss, or an external measure such as KL divergence to an oracle state; without such grounding the self-supervised signal risks misalignment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's clarity and the need to ground the Belief Entropy proxy. We respond to each major comment below and commit to revisions that address the concerns without overstating current results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claim (97.1% at 1.75M tokens) is reported without any description of baselines, variance across runs, data exclusion criteria, or the precise computation of Belief Entropy, rendering it impossible to assess whether the data supports the outperformance claim or whether gains are attributable to the proposed penalty rather than other unisolated changes.
Authors: We agree the abstract is too condensed to support standalone evaluation of the claim. The body of the manuscript provides the requested details on baselines, run variance, and Belief Entropy computation. To resolve the issue, we will revise the abstract to briefly note the comparison to outcome-based RL, that results are averaged over runs, and a high-level reference to the self-supervised computation. This change will be incorporated in the next version. revision: yes
-
Referee: [Abstract] The central claim that penalizing high Belief Entropy improves long-horizon reasoning rests on this quantity faithfully tracking degradation in the agent's estimate of the latent task state. No evidence is provided of correlation between Belief Entropy and downstream task failure, information loss, or an external measure such as KL divergence to an oracle state; without such grounding the self-supervised signal risks misalignment.
Authors: The manuscript introduces Belief Entropy explicitly as a self-supervised proxy and demonstrates its value through end-to-end task improvements rather than direct correlation to oracle measures. We acknowledge that no explicit correlation analysis with task failure, information loss, or KL divergence appears in the current version. We will add a targeted analysis in the experiments section correlating Belief Entropy scores with observed information retention and failure points to provide additional empirical grounding. revision: yes
Circularity Check
No circularity; Belief Entropy is an independently defined proxy validated on external task benchmarks
full rationale
The paper defines Belief Entropy as a self-supervised probe of model uncertainty given memory summaries, then uses it to supply an auxiliary penalty in MMPO. Task performance (e.g., 97.1% at 1.75M tokens) is measured on separate long-horizon benchmarks, not by construction from the entropy definition itself. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the central claim to its inputs. The derivation remains self-contained against external outcome metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Belief Entropy is an effective self-supervised proxy for the quality of intermediate memory summaries
Forward citations
Cited by 1 Pith paper
-
ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
ThoughtFold applies introspective redundancy detection within correct CoT trajectories to create sub-trajectory spectra, then uses masked preference optimization to penalize redundant explorations, yielding 56% token ...
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.CoRR, abs/2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, Zhiyuan Liu, Maosong Sun, Bowen Zhou, and Ning Ding. Process reinforcement through implicit rewards.CoRR, abs/2502.01456,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers
Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers. arXiv preprint arXiv:2603.07670,
-
[6]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurélien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozière, Bethany...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. Rethinking entropy interventions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, Junpeng Ren, Zehao Lin, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhiqiang Yin, Qingchen Yu, Bo Tang, Hongkang Yang, Zhi-Qin John Xu, and Feiyu Xiong. Memos: An operating system for memory-augmented generation (MAG) in large langu...
-
[11]
A comprehensive survey on long context language modeling.CoRR, abs/2503.17407,
Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, Yuanxing Zhang, Zhuo Chen, Hangyu Guo, Shilong Li, Ziqiang Liu, Yong Shan, Yifan Song, Jiayi Tian, Wenhao Wu, Zhejian Zhou, Ruijie Zhu, Junlan Feng, Yang Gao, Shizhu He, Zhoujun Li, Tianyu Liu, Fanyu Meng, Wenbo Su, Yingshui Tan, ...
-
[12]
MemGPT: Towards LLMs as Operating Systems
11 Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems.CoRR, abs/2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
doi: 10.1016/0022-247X(65) 90154-X. Han Shen. On entropy control in llm-rl algorithms.arXiv preprint arXiv:2509.03493,
-
[14]
Leheng Sheng, Yongtao Zhang, Wenchang Ma, Yaorui Shi, Ting Huang, Xiang Wang, An Zhang, Ke Shen, and Tat-Seng Chua. When to memorize and when to stop: Gated recurrent memory for long-context reasoning.arXiv preprint arXiv:2602.10560,
-
[15]
doi: 10.1287/opre. 21.5.1071. Susanne Still and Doina Precup. An information-theoretic approach to curiosity-driven reinforcement learning.Theory in Biosciences, 131(3):139–148,
-
[16]
Mem-{\alpha}: Learning Memory Construction via Reinforcement Learning
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian J. McAuley, and Xiaojian Wu. Mem-α: Learning memory construction via reinforcement learning.CoRR, abs/2509.25911,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context LLM with multi-conv rl-based memory agent.CoRR, abs/2507.02259,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Youliang Yuan, Qiuyang Mang, Jingbang Chen, Hong Wan, Xiaoyuan Liu, Junjielong Xu, Jen-tse Huang, Wenxuan Wang, Wenxiang Jiao, and Pinjia He. Curing miracle steps in LLM mathematical reasoning with rubric rewards.CoRR, abs/2510.07774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Huayu Chen, Xiaoye Qu, Yafu Li, Weize Chen, Zhenzhao Yua...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Deepresearcher: Scaling deep research via reinforcement learning in real-world environments
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 414–431,
2025
-
[22]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
The key point is architectural: once the history is compressed into memory, downstream reasoning and action selection can only access the information preserved inm t
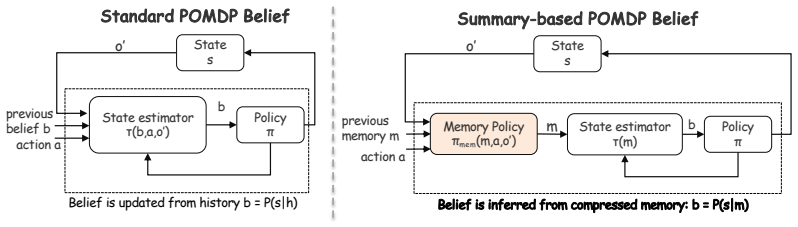
19:end for B Summary-Induced Belief: Architectural Justification This appendix justifies why the belief of a summary-based memory agent is conditioned on the textual memory mt rather than on the full interaction history ht. The key point is architectural: once the history is compressed into memory, downstream reasoning and action selection can only access...
1999
-
[24]
Based on current memory, what is the answer to the question?
studies long-horizon agents that jointly maintain in- ternal memory and perform task-directed reasoning. Instead of relying only on raw interaction history, the agent maintains a compact internal memory state across steps and uses it to support subsequent reasoning, querying, or environment interaction. This framework is evaluated in both multi-objective ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.