D\'ej\`a View: Looping Transformers for Multi-View 3D Reconstruction
Pith reviewed 2026-06-29 07:51 UTC · model grok-4.3
The pith
Recurrent application of a single transformer block refines multi-view 3D reconstructions more effectively than deeper independent layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
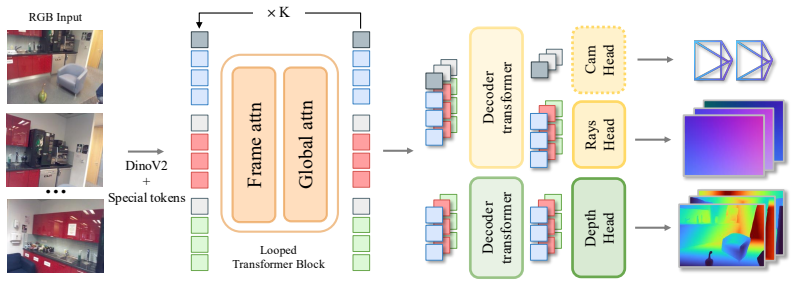
Our model, DéjàView, applies a single looped transformer block recurrently to per-view features for K refinement steps. Trained once, it exposes K as an inference-time compute knob, matching or outperforming substantially larger feed-forward baselines across five reconstruction benchmarks spanning indoor, outdoor, object-centric, and driving scenes, while using a fraction of their parameters and comparable or lower compute. Importantly, the same looped block formulation outperforms an otherwise identical variant with independent per-step parameters under matched training data and compute, suggesting that explicit iteration is not merely a compute-efficient substitute for capacity but a stron
What carries the argument
The single looped transformer block recurrently applied for K refinement steps to per-view features, serving as an explicit iterative refinement mechanism.
If this is right
- Performance can be scaled at inference by varying the number of recurrent applications K without any retraining.
- Competitive accuracy is achieved with a fraction of the parameters required by larger feed-forward transformer baselines.
- The looped formulation outperforms an equivalent-capacity model that uses distinct parameters for each step under identical training conditions.
- The approach delivers results across indoor, outdoor, object-centric, and driving scene benchmarks.
Where Pith is reading between the lines
- The recurrence may enforce more consistent operations across refinement steps than learning specialized per-layer functions.
- Similar looping could be tested on other progressive vision tasks such as iterative depth estimation or multi-step pose refinement.
- Dynamic adjustment of K per input based on scene complexity might further improve efficiency without changing the trained weights.
Load-bearing premise
That a single transformer block, when trained once, can learn to perform effective progressive refinement across K recurrent applications without requiring unique parameters per step or suffering from training instability.
What would settle it
Training the looped model and an otherwise identical model with independent per-step parameters on matched data and compute, then comparing their accuracy on the five benchmarks; if the independent version wins or ties, the claim that explicit iteration supplies a stronger bias fails.
Figures






read the original abstract
Recent feed-forward 3D reconstruction transformers have scaled to over a billion parameters, following the broader trend of increasing model capacity in computer vision. Yet emerging evidence suggests that contiguous transformer layers often behave like repeated applications of similar operations, and multi-view reconstruction transformers refine their predictions progressively across decoder depth. We posit that model depth partially buys iteration, paid for inefficiently in unique parameters, and instead make that iteration explicit in architecture. Our model, D\'ej\`aView, applies a single looped transformer block recurrently to per-view features for K refinement steps. Trained once, it exposes K as an inference-time compute knob, matching or outperforming substantially larger feed-forward baselines across five reconstruction benchmarks spanning indoor, outdoor, object-centric, and driving scenes, while using a fraction of their parameters and comparable or lower compute. Importantly, the same looped block formulation outperforms an otherwise identical variant with independent per-step parameters under matched training data and compute, suggesting that explicit iteration is not merely a compute-efficient substitute for capacity but a stronger inductive bias for multi-view 3D reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DéjàView, which replaces deep feed-forward transformer stacks for multi-view 3D reconstruction with recurrent application of a single shared transformer block for K refinement steps. It reports that this architecture matches or exceeds substantially larger feed-forward baselines across five benchmarks (indoor, outdoor, object-centric, driving) while using far fewer parameters and comparable or lower compute; crucially, the looped formulation also outperforms an otherwise identical model that uses independent parameters per step under matched data and compute, which the authors interpret as evidence that explicit iteration supplies a stronger inductive bias than additional capacity.
Significance. If the ablation comparison is robust, the result would challenge the prevailing scaling trend in 3D reconstruction transformers by showing that iteration can be made explicit and parameter-efficient rather than purchased through depth. The inference-time flexibility of K as a compute knob and the claim that looping is not merely a capacity substitute but a better bias are both potentially high-impact if supported by clean controls.
major comments (1)
- [Ablation comparison (abstract and §4)] The central ablation claim (abstract) that the single looped block outperforms the independent-per-step-parameter variant under matched training data and compute is load-bearing for the inductive-bias conclusion. However, recurrent application entails back-propagation through time over the shared block while the independent variant does not; without reported diagnostics on gradient norms, learning-rate schedules, convergence curves, or symmetric use of mitigations such as truncated BPTT or per-step gradient scaling, superior looped performance could arise from optimization differences rather than the claimed inductive bias.
minor comments (1)
- The abstract states performance claims across five benchmarks and a key ablation but supplies no details on exact metrics, statistical tests, data splits, or training procedures; these should be added to the main text or a table for verifiability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our ablation study. We address the concern point-by-point below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Ablation comparison (abstract and §4)] The central ablation claim (abstract) that the single looped block outperforms the independent-per-step-parameter variant under matched training data and compute is load-bearing for the inductive-bias conclusion. However, recurrent application entails back-propagation through time over the shared block while the independent variant does not; without reported diagnostics on gradient norms, learning-rate schedules, convergence curves, or symmetric use of mitigations such as truncated BPTT or per-step gradient scaling, superior looped performance could arise from optimization differences rather than the claimed inductive bias.
Authors: We appreciate this valid methodological point. Both the looped and independent-per-step variants were trained with identical hyperparameters, optimizer (AdamW), learning-rate schedule, batch size, and data order; the sole architectural difference is parameter sharing versus distinct weights per step. No truncated BPTT was used, as K ≤ 8. To directly address the concern that optimization dynamics may explain the gap, the revised manuscript will include side-by-side training-loss curves, gradient-norm histograms, and per-step loss trajectories for both variants. These diagnostics (which we have already computed) show comparable convergence behavior and no systematic gradient explosion or vanishing in the looped model. While we cannot retroactively alter the original training runs, the added evidence supports that the performance advantage is not an artifact of mismatched optimization. revision: yes
Circularity Check
No circularity: central claim is empirical ablation, not derived by construction
full rationale
The paper advances an architectural hypothesis that explicit recurrence supplies a stronger inductive bias than additional per-step parameters. This is tested via direct comparison of a shared-block looped model against an otherwise identical independent-parameter variant, under matched data and compute. No equations, uniqueness theorems, or self-citations are invoked to derive the performance difference; the result is presented as an experimental outcome. The provided abstract and reader summary contain no self-definitional steps, fitted inputs relabeled as predictions, or load-bearing self-citations that would reduce the claim to its own inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single transformer block can be applied recurrently to refine per-view features progressively across K steps
Reference graph
Works this paper leans on
-
[1]
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Naveen Arivazhagan, Ankur Bapna, Orhan Firat, Dmitry Lepikhin, Melvin Johnson, Maxim Krikun, Mia Xu Chen, Yuan Cao, George Foster, Colin Cherry, et al. Massively multilingual neural machine translation in the wild: Findings and challenges.arXiv preprint arXiv:1907.05019,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual KITTI 2.arXiv preprint arXiv:2001.10773,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Bardienus Duisterhof, Lojze Zust, Philippe Weinzaepfel, Vincent Leroy, Yohann Cabon, and Jerome Revaud. MASt3R-SfM: a fully-integrated solution for unconstrained structure-from-motion.arXiv preprint arXiv:2409.19152,
-
[4]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Understanding Multi-View Transformers
Michal Starý, Julien Gaubil, Ayush Tewari, and Vincent Sitzmann. Understanding Multi-View Transformers. InICCV 2025 E2E3D Workshop,
2025
-
[7]
13 Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[8]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025b. Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Romain Brégier, Yohann Cabon, Vaibhav Arora, Leonid Antsfeld, Boris Chidlovskii, Gab...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
language
15 Supplementary Material for Déjà View A Training Datasets We train on a mixture of 29 publicly available datasets that span synthetic renderings, indoor and outdoor real captures, multi-view object scans, and driving footage. The corpus is highly imbalanced: per-dataset image counts Ni span more than three orders of magnitude (from ∼10 k for Spring to ∼...
2019
-
[10]
As a result, we also obtain a depth confidence channel that can be used downstream to filter regions with uncertain reconstruction
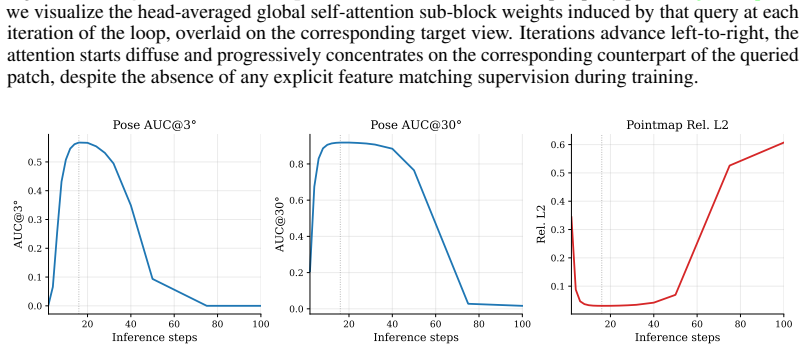
and yielding a slight improvement in Inlier Ratio (Table 8). As a result, we also obtain a depth confidence channel that can be used downstream to filter regions with uncertain reconstruction. C Emergent Iterative Correspondence Search We probe the global attention sub-block of our recurrent layer to investigate how its attention pattern evolves across it...
2024
-
[11]
L2 remain stable up to approximately Kinf = 30 but eventually collapse
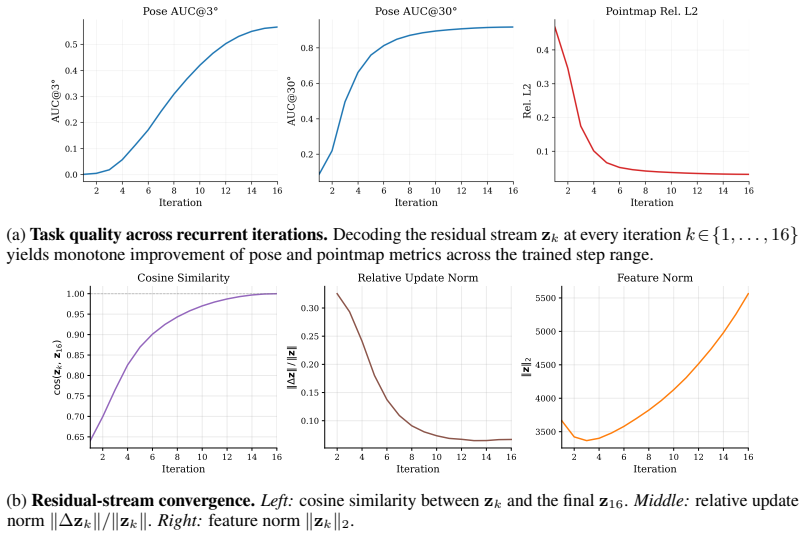
31.0 80.6 59.2 0.125 Pointmap Rel. L2 remain stable up to approximately Kinf = 30 but eventually collapse. Figure 7 shows that model iterations cannot be pushed arbitrarily far. Our analysis shows that this occurs because some feature channels grow unbounded as we scale beyond Kmax. The mechanism is already visible inside the trained range (Figure 3b): wh...
2025
-
[12]
Variant AUC@3 ◦ ↑AUC@30 ◦ ↑IR↑AbsRel↓ Linear head +ℓ 2 (stage 1, full recipe)56.8 91.879.80.031 Conv
yields a small, consistent gain in Inlier Ratio while leaving the pose metrics unchanged. Variant AUC@3 ◦ ↑AUC@30 ◦ ↑IR↑AbsRel↓ Linear head +ℓ 2 (stage 1, full recipe)56.8 91.879.80.031 Conv. head + conf. loss (stage 2 finetune) 56.8 91.8 80.3 0.031 Input Linear Head Convolutional Head Figure 5:Block artifacts.Depth predicted by the first-stage linear hea...
2026
-
[13]
Pi3 [Wang et al., 2025b].The official yyfz233/Pi3 checkpoint at 518-pixel longest edge with patch size14
We decode the released 9D camera encoding (translation, quaternion, FoV h, FoVw) via the offi- cial encoding_to_camera utility and use depth-unprojected pointmaps as the primary 3D output, matching the convention used for VGGT and DA3. Pi3 [Wang et al., 2025b].The official yyfz233/Pi3 checkpoint at 518-pixel longest edge with patch size14. MapAnything [Ke...
2026
-
[14]
We decode camera pose from predicted rays. MASt3R [Leroy et al., 2024].The official MASt3R_ViTLarge_BaseDecoder _512_catmlpdpt_metric (metric-scale) checkpoint at 512-pixel longest edge with patch size 16, using DUSt3R-style image normalization (mean and std 0.5). Pair selection is adaptive on scene size: complete (all pairs) for scenes with N≤8 views, an...
2024
-
[15]
The efficiency measurement at N=24 uses the swin-5 branch (120 pairs)
otherwise. The efficiency measurement at N=24 uses the swin-5 branch (120 pairs). The sparse global alignment uses the published defaults: 300 iterations of coarse alignment at learning rate 0.07 followed by 300 iterations of refinement at 0.01, with per-pixel depth optimization enabled (optim_level=refine+depth) and matching-confidence threshold 5.0. Cam...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.