LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
Pith reviewed 2026-06-29 08:17 UTC · model grok-4.3
The pith
Replacing selected text spans with their rendered images during training makes VLMs treat equivalent content the same across modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
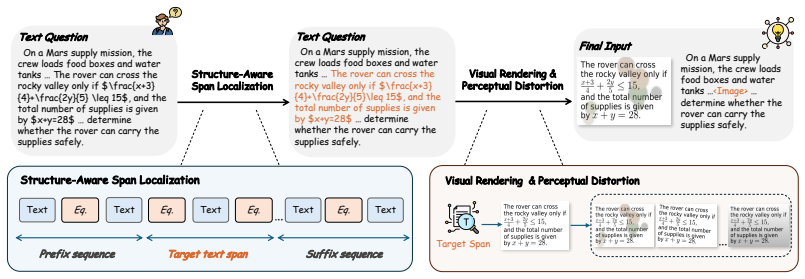
Current training corpora organize text and images into distinct roles that cause VLMs to develop modality-specific preferences, so they fail to align representations of the same semantics when the carrier changes. LoMo corrects this by reformulating single-modality prompts into text-visual-text sequences: it selects local text spans and recasts them as rendered images while preserving exact semantics. The resulting supervision signal teaches representational invariance between carriers.
What carries the argument
Local Modality Substitution (LoMo), a data curation step that selects target text spans inside prompts and replaces them with rendered images to form interleaved multimodal training sequences.
If this is right
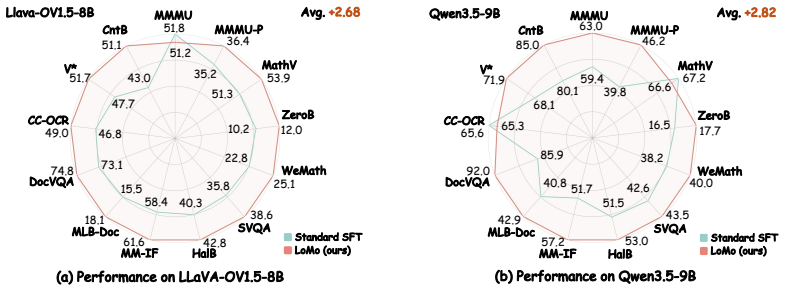
- Consistent accuracy gains on 13 multimodal benchmarks.
- Improvements of 2.67 points over standard supervised fine-tuning on LLaVA-OneVision-1.5-8B.
- Improvements of 2.82 points over standard supervised fine-tuning on Qwen3.5-9B.
- Deeper cross-modal fusion that is architecture-agnostic.
- Robustness to modality substitution on both understanding and reasoning tasks.
Where Pith is reading between the lines
- The same local-substitution pattern could be applied when curating data for other modality pairs such as audio-text.
- Future datasets might be collected with balanced carrier roles from the start instead of relying on post-hoc fixes.
- Models trained this way may handle mixed-modality inputs more gracefully in open-ended settings.
Load-bearing premise
The performance drop when text is swapped for images is caused primarily by asymmetric roles in existing training data, and rendering those text spans as images preserves semantics without adding new artifacts or shifts.
What would settle it
After LoMo training, measure the accuracy gap between original text prompts and their image-rendered counterparts on held-out benchmarks; a near-zero gap would support the claim while a persistent gap would falsify it.
Figures

read the original abstract
Vision-Language Models (VLMs) have achieved substantial progress across a wide range of understanding and reasoning tasks, driven by large-scale image-text training aimed at multimodal fusion. Ideally, replacing a textual question with its rendered-image counterpart should leave model performance essentially unaffected. In practice, however, such modality substitution induces dramatic performance degradation. We attribute this "carrier sensitivity" issue to an inherent bias in current training corpora. Across prevalent datasets such as image captioning, VQA, OCR, and web-sourced interleaved data, text and images are typically organized into distinct and asymmetric roles, with text serving as linguistic queries and images as visual references. Such data bias leads VLMs to exhibit distinct preferences for information acquisition across different modalities. Consequently, VLMs fail to align representations of semantically equivalent content across textual and visual carriers, making model reasoning fragile under modality substitution. To address this, we propose Local Modality Substitution (LoMo), a lightweight, architecture-agnostic data curation paradigm designed to provide supervision for cross-modal representational invariance between semantically equivalent text and image carriers. LoMo achieves this by reformulating single-modality prompts into seamlessly interleaved multimodal sequences. It dynamically selects target text spans and recasts them as rendered images, thereby preserving the same semantics across "text, visual, text" carriers. Extensive experiments across 13 diverse multimodal benchmarks demonstrate that LoMo significantly improves overall multimodal reasoning and yields deeper cross-modal fusion. Specifically, it delivers consistent gains across foundational models, improving over standard SFT by 2.67 points on LLaVA-OneVision-1.5-8B and 2.82 points on Qwen3.5-9B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Local Modality Substitution (LoMo), a data curation paradigm that dynamically selects text spans in single-modality prompts and renders them as images to produce interleaved multimodal sequences. This is intended to counteract 'carrier sensitivity'—performance degradation under text-to-image substitution—attributed to asymmetric text/image roles in existing corpora (captioning, VQA, OCR, interleaved data). The method is architecture-agnostic and is claimed to yield deeper cross-modal fusion, with reported gains of 2.67 points on LLaVA-OneVision-1.5-8B and 2.82 points on Qwen3.5-9B over standard SFT across 13 benchmarks.
Significance. If the reported gains can be shown to arise specifically from improved representational invariance rather than rendering artifacts or other data effects, LoMo would supply a lightweight, training-only intervention that strengthens VLM robustness without architectural modification. The architecture-agnostic framing and focus on local substitution are practical strengths that could influence data curation practices for multimodal training.
major comments (3)
- [Abstract] Abstract: The central empirical claims (consistent gains of 2.67 and 2.82 points, deeper fusion across 13 benchmarks) are stated without any description of experimental protocol, baseline implementations, training details, number of runs, or statistical tests. This absence directly affects verifiability of the performance improvements that support the invariance hypothesis.
- [Methods] Methods / LoMo description: The claim that dynamic rendering of selected text spans supplies 'clean supervision for cross-modal representational invariance' rests on the untested premise that rendered images preserve semantics without introducing new distributional shifts (font, layout, resolution, or visual artifacts). No controls, render-fidelity ablations, or direct measurements of representation alignment (e.g., before/after cosine similarity or probing) are referenced to rule out alternative explanations such as incidental robustness to rendered text.
- [Introduction] Introduction / motivation: The attribution of carrier sensitivity to 'inherent bias' and 'distinct and asymmetric roles' in prevalent datasets is presented without quantitative corpus analysis, examples of role asymmetry, or measurements showing how such asymmetry produces the observed substitution degradation. This leaves the causal premise for LoMo unsupported by evidence internal to the manuscript.
minor comments (1)
- [Abstract] The model name 'Qwen3.5-9B' should be verified against the exact release used; minor notation inconsistencies of this type reduce clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight areas where additional clarity and evidence would strengthen the manuscript. We address each major comment below and commit to revisions that improve verifiability and support for the core claims without altering the overall contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (consistent gains of 2.67 and 2.82 points, deeper fusion across 13 benchmarks) are stated without any description of experimental protocol, baseline implementations, training details, number of runs, or statistical tests. This absence directly affects verifiability of the performance improvements that support the invariance hypothesis.
Authors: We agree that the abstract is concise and omits these details. The full experimental protocol, including model specifications, training hyperparameters, baseline comparisons, and evaluation across the 13 benchmarks, is provided in Section 4. To address verifiability concerns, we will revise the abstract to include a short clause noting the two base models evaluated and the breadth of benchmarks, while remaining within length limits. We will also add explicit statements on run counts and variance in the Experiments section. revision: partial
-
Referee: [Methods] Methods / LoMo description: The claim that dynamic rendering of selected text spans supplies 'clean supervision for cross-modal representational invariance' rests on the untested premise that rendered images preserve semantics without introducing new distributional shifts (font, layout, resolution, or visual artifacts). No controls, render-fidelity ablations, or direct measurements of representation alignment (e.g., before/after cosine similarity or probing) are referenced to rule out alternative explanations such as incidental robustness to rendered text.
Authors: This observation is correct; the current manuscript does not include render-fidelity ablations or direct alignment measurements. We will add a dedicated ablation subsection (and appendix) that varies rendering parameters such as font style, resolution, and layout, reports performance sensitivity, and includes cosine similarity probes between original text embeddings and rendered-image embeddings for matched spans. These additions will directly test whether gains arise from invariance rather than artifacts. revision: yes
-
Referee: [Introduction] Introduction / motivation: The attribution of carrier sensitivity to 'inherent bias' and 'distinct and asymmetric roles' in prevalent datasets is presented without quantitative corpus analysis, examples of role asymmetry, or measurements showing how such asymmetry produces the observed substitution degradation. This leaves the causal premise for LoMo unsupported by evidence internal to the manuscript.
Authors: We acknowledge that the introduction currently relies on qualitative description rather than quantitative corpus evidence. In the revised manuscript we will insert a short quantitative analysis, including role-distribution statistics across representative datasets (e.g., captioning, VQA, OCR) and concrete examples of substitution degradation on held-out prompts. This will provide internal support for the motivation before presenting LoMo. revision: yes
Circularity Check
No circularity: method is an independent data-curation procedure with no equations, fits, or self-citation chains.
full rationale
The paper describes a heuristic curation step (select text spans, render as images, interleave) motivated by an observed performance drop under modality substitution. No equations, parameters, or predictions are defined; the claimed gains are presented as empirical outcomes of the curation rather than re-derivations of prior fitted quantities. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain is therefore self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text and images occupy asymmetric roles in prevalent training corpora (captioning, VQA, OCR, interleaved web data), inducing distinct modality preferences.
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[4]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[5]
Glyph: Scaling context windows via visual-text compression
Jiale Cheng, Yusen Liu, Xinyu Zhang, Yulin Fei, Wenyi Hong, Ruiliang Lyu, Weihan Wang, Zhe Su, Xiaotao Gu, Xiao Liu, et al. Glyph: Scaling context windows via visual-text compression. arXiv preprint arXiv:2510.17800, 2025
-
[6]
Simplevqa: Multimodal factuality evaluation for multimodal large language models
Xianfu Cheng, Wei Zhang, Shiwei Zhang, Jian Yang, Xiangyuan Guan, Xianjie Wu, Xiang Li, Ge Zhang, Jiaheng Liu, Yuying Mai, et al. Simplevqa: Multimodal factuality evaluation for multimodal large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4637–4646, 2025
2025
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Mm-ifengine: Towards multimodal instruction following
Shengyuan Ding, Shenxi Wu, Xiangyu Zhao, Yuhang Zang, Haodong Duan, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Mm-ifengine: Towards multimodal instruction following. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1099–1109, 2025
2025
-
[9]
Insight-v: Exploring long-chain visual reasoning with multimodal large language models
Yuhao Dong, Zuyan Liu, Hai-Long Sun, Jingkang Yang, Winston Hu, Yongming Rao, and Ziwei Liu. Insight-v: Exploring long-chain visual reasoning with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9062–9072, 2025
2025
-
[10]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pag...
2024
-
[11]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Deciphering cross-modal alignment in large vision-language models with modality integration rate.arXiv preprint arXiv:2410.07167, 2024
-
[13]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InInternational Conference on Learning Repre- sentations, volume 2025, pages 58791–58831, 2025
2025
-
[14]
Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024
-
[15]
Multilingual pretraining for pixel language models
Ilker Kesen, Jonas F Lotz, Ingo Ziegler, Phillip Rust, and Desmond Elliott. Multilingual pretraining for pixel language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29582–29599, 2025
2025
-
[16]
Pix2struct: Screenshot parsing as pretraining for visual language understanding
Kenton Lee, Mandar Joshi, Iulia Raluca Turc, Hexiang Hu, Fangyu Liu, Julian Martin Eisensch- los, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding. InInternational Confer- ence on Machine Learning, pages 18893–18912. PMLR, 2023
2023
-
[17]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024
2024
-
[18]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Yanhong Li, Zixuan Lan, and Jiawei Zhou. Text or pixels? it takes half: On the token efficiency of visual text inputs in multimodal llms.arXiv preprint arXiv:2510.18279, 2025
-
[20]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022
2022
-
[21]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[22]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[23]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[24]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language under- standing.arXiv preprint arXiv:2403.05525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems, 37:95963–96010, 2024
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems, 37:95963–96010, 2024
2024
-
[27]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 11
2021
-
[28]
Teaching clip to count to ten
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching clip to count to ten. InProceedings of the IEEE/CVF international conference on computer vision, pages 3170–3180, 2023
2023
-
[29]
Runqi Qiao, Qiuna Tan, Guanting Dong, MinhuiWu MinhuiWu, Chong Sun, Xiaoshuai Song, Jiapeng Wang, Zhuoma Gongque, Shanglin Lei, Yifan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 200...
2025
-
[30]
Jonathan Roberts, Mohammad Reza Taesiri, Ansh Sharma, Akash Gupta, Samuel Roberts, Ioana Croitoru, Simion-Vlad Bogolin, Jialu Tang, Florian Langer, Vyas Raina, et al. Zerobench: An impossible visual benchmark for contemporary large multimodal models.arXiv preprint arXiv:2502.09696, 2025
-
[31]
Simon Schrodi, David T Hoffmann, Max Argus, V olker Fischer, and Thomas Brox. Two effects, one trigger: On the modality gap, object bias, and information imbalance in contrastive vision-language models.arXiv preprint arXiv:2404.07983, 2024
-
[32]
Aligning large multimodal models with factually augmented rlhf
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13088–13110, 2024
2024
-
[33]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
2024
-
[34]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568–9578, 2024
2024
-
[35]
Lever- aging visual tokens for extended text contexts in multi-modal learning.Advances in Neural Information Processing Systems, 37:14325–14348, 2024
Alex Jinpeng Wang, Linjie Li, Yiqi Lin, Min Li, Lijuan Wang, and Mike Zheng Shou. Lever- aging visual tokens for extended text contexts in multi-modal learning.Advances in Neural Information Processing Systems, 37:14325–14348, 2024
2024
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.arXiv preprint arXiv:2406.01574, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024
2024
-
[40]
Vision-centric token compression in large language model.arXiv preprint arXiv:2502.00791, 2025
Ling Xing, Alex Jinpeng Wang, Rui Yan, Xiangbo Shu, and Jinhui Tang. Vision-centric token compression in large language model.arXiv preprint arXiv:2502.00791, 2025
-
[41]
Vision model pre-training on interleaved image-text data via latent compression learning.Advances in Neural Information Processing Systems, 37:23912– 23938, 2024
Chenyu Yang, Xizhou Zhu, Jinguo Zhu, Weijie Su, Junjie Wang, Xuan Dong, Wenhai Wang, Lewei Lu, Bin Li, Jie Zhou, et al. Vision model pre-training on interleaved image-text data via latent compression learning.Advances in Neural Information Processing Systems, 37:23912– 23938, 2024. 12
2024
-
[42]
Cc-ocr: A comprehensive and challenging ocr benchmark for evaluating large multimodal models in literacy
Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jianqiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, et al. Cc-ocr: A comprehensive and challenging ocr benchmark for evaluating large multimodal models in literacy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21744–21754, 2025
2025
-
[43]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[44]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134–15186, 2025
2025
-
[45]
Instruction-following evaluation for large language models, 2023
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. 13 A Pure-Text Capability Analysis To verify the effect of LoMo on pure-text capabilities, we evaluate Standard SFT and LoMo on five pure-text benchmarks: MMLU-Pro [ 37], GSM8K [7], Hu...
2023
-
[46]
The resulting rendered images are inserted back into multimodal SFT examples in place of the corresponding text spans
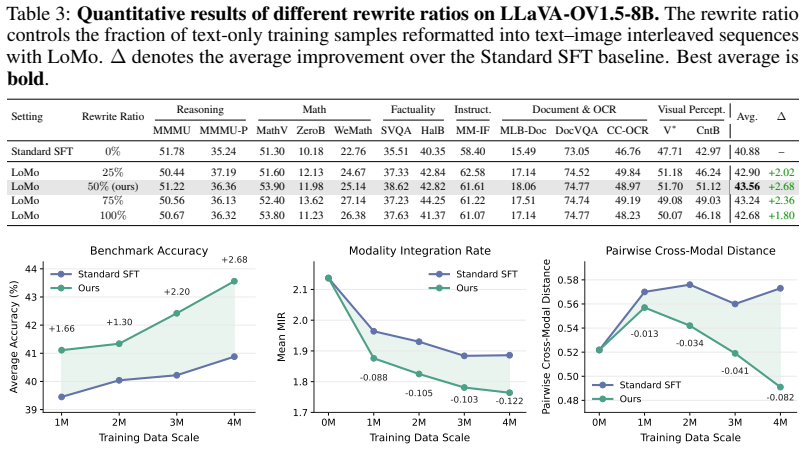
Rendered images are retained at their native resolution based on the length of text. The resulting rendered images are inserted back into multimodal SFT examples in place of the corresponding text spans. B.3 Training Setup We fine-tune LLaV A-OneVision-1.5-8B-Base and Qwen3.5-9B-Base using LLaMA-Factory under a standard supervised fine-tuning regime. We a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.