Grounded 3D-Aware Spatial Vision-Language Modeling
Pith reviewed 2026-06-29 08:06 UTC · model grok-4.3
The pith
GR3D adds explicit 2D, implicit 2D, and monocular 3D grounding to vision-language models so they can decompose spatial tasks into 2D perception followed by 3D inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
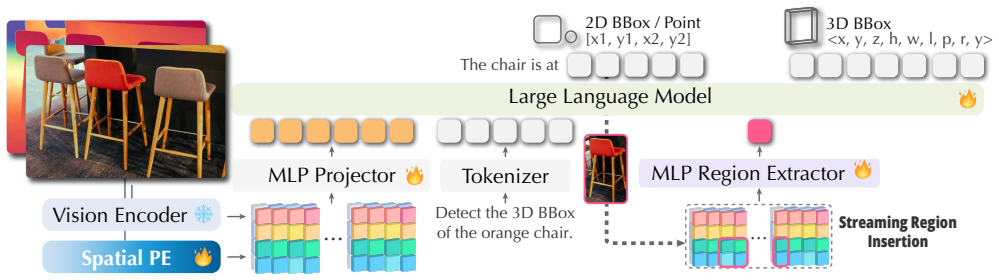
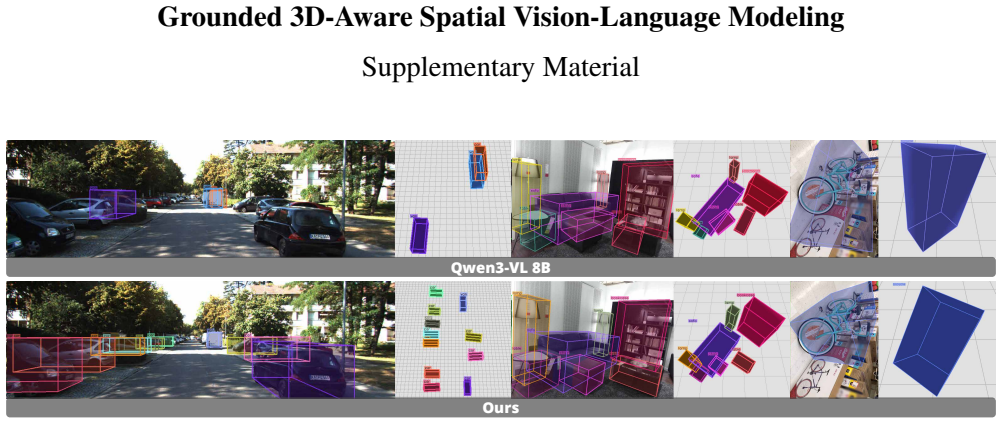
GR3D introduces an implicit grounding mechanism that identifies entity mentions during generation and inserts the corresponding region tokens into the text stream, allowing the model to reference visual evidence on the fly when producing spatial chain-of-thought responses. In parallel, a region-prompted monocular 3D grounding design predicts 3D bounding boxes in the camera view from grounded region queries, supported by intrinsic-aware normalization and dense geometric supervision. Together, these grounding capabilities enable GR3D to decompose complex spatial understanding problems into grounded 2D perception followed by 3D inference and produce consistent improvements across grounded and n
What carries the argument
Three complementary grounding capabilities—explicit 2D grounding, implicit 2D grounding via on-the-fly region-token insertion, and region-prompted monocular 3D grounding with intrinsic-aware normalization—operating inside one VLM framework.
If this is right
- Grounding functions as an effective inductive bias that strengthens spatial understanding in VLMs beyond the grounding tasks themselves.
- The model can reference visual evidence on the fly while generating spatial chain-of-thought responses.
- Complex spatial problems can be decomposed into grounded 2D perception followed by 3D inference.
- General spatial understanding improves even on benchmarks that do not require explicit grounding outputs.
Where Pith is reading between the lines
- The implicit token-insertion method could be tested on other generation-heavy VLM tasks such as visual question answering to measure whether factual consistency rises.
- Joint training of the three mechanisms suggests that multi-task grounding objectives may transfer to new modalities or larger model scales with limited interference.
- If the gains hold under controlled ablations, similar grounding layers might be added to existing open-source VLMs to test rapid improvement on spatial reasoning benchmarks.
Load-bearing premise
The three grounding mechanisms can be trained jointly without interference and the observed benchmark gains are produced by the grounding components rather than by other training choices or data differences.
What would settle it
Train an otherwise identical model that removes the three grounding mechanisms but keeps the same data, architecture size, and optimization schedule, then measure whether the spatial-benchmark gains disappear.
Figures



read the original abstract
We present GR3D, a spatial vision language model equipped with three complementary grounding capabilities--explicit 2D grounding, implicit 2D grounding, and monocular 3D grounding--within a single framework. GR3D introduces an implicit grounding mechanism that identifies entity mentions during generation and inserts the corresponding region tokens into the text stream, allowing the model to reference visual evidence on the fly when producing spatial chain-of-thought responses. In parallel, a region-prompted monocular 3D grounding design predicts 3D bounding boxes in the camera view from grounded region queries, supported by intrinsic-aware normalization and dense geometric supervision. Together, these grounding capabilities enable GR3D to decompose complex spatial understanding problems into grounded 2D perception followed by 3D inference. GR3D achieves consistent improvements across grounded and non-grounded spatial benchmarks, demonstrating grounding as an effective inductive bias for strengthening spatial understanding in VLMs. These grounding capabilities collectively enhance general spatial understanding beyond the grounding task itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GR3D, a spatial vision-language model incorporating three complementary grounding mechanisms: explicit 2D grounding, implicit 2D grounding via on-the-fly insertion of region tokens during text generation for spatial chain-of-thought, and monocular 3D grounding that predicts 3D bounding boxes from region queries using intrinsic-aware normalization and dense geometric supervision. The central claim is that these grounding capabilities function as an inductive bias, enabling decomposition of spatial problems into 2D perception followed by 3D inference and yielding consistent improvements on both grounded and non-grounded spatial benchmarks while also enhancing general spatial understanding beyond grounding tasks.
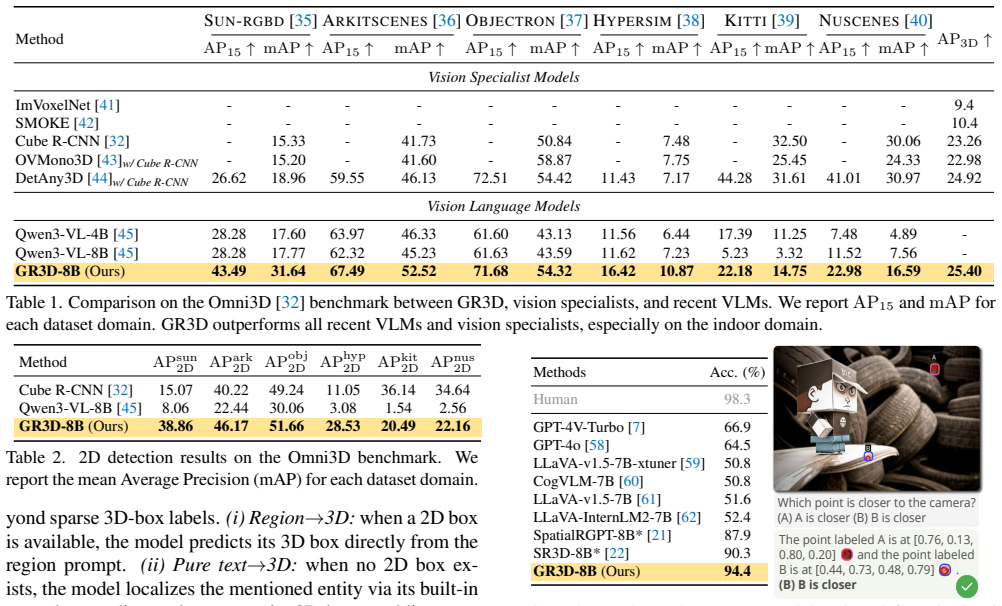
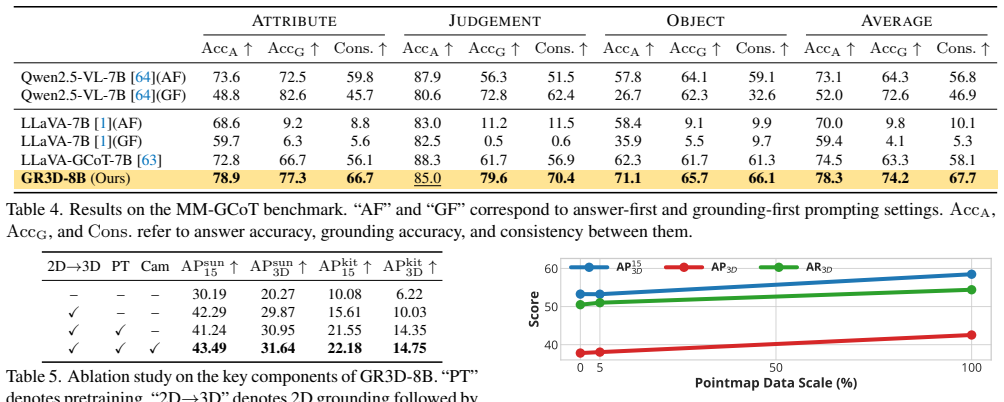
Significance. If the empirical results are supported by controlled experiments, the work would establish grounding as a practical inductive bias for spatial reasoning in VLMs, showing transfer benefits to non-grounding tasks without requiring changes to base architecture or data scale. This could influence future VLM designs focused on spatial capabilities.
major comments (1)
- [Experimental results / ablation studies] The central claim that benchmark gains demonstrate grounding as an effective inductive bias requires evidence that improvements are causally due to the three grounding components rather than uncontrolled differences in data mixture, optimization, or base model. The manuscript provides no controlled ablations that hold all other factors fixed while toggling only the grounding mechanisms (explicit 2D, implicit 2D token insertion, and monocular 3D). This is load-bearing for the abstract claim and the reader's weakest assumption.
minor comments (2)
- [Abstract] The abstract states performance improvements but supplies no quantitative numbers, ablation details, or error analysis; the full paper should ensure all tables and figures include error bars or statistical significance where appropriate.
- [Methods] The description of joint training of the three grounding mechanisms would benefit from explicit discussion of potential interference or training stability in the methods section.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the emphasis on establishing causal evidence for the inductive bias claim. We address the major comment below and commit to revisions that strengthen the experimental support.
read point-by-point responses
-
Referee: [Experimental results / ablation studies] The central claim that benchmark gains demonstrate grounding as an effective inductive bias requires evidence that improvements are causally due to the three grounding components rather than uncontrolled differences in data mixture, optimization, or base model. The manuscript provides no controlled ablations that hold all other factors fixed while toggling only the grounding mechanisms (explicit 2D, implicit 2D token insertion, and monocular 3D). This is load-bearing for the abstract claim and the reader's weakest assumption.
Authors: We agree that isolating the contribution of each grounding mechanism under fully matched conditions (identical data mixture, optimization schedule, and base model) is the most direct way to support the inductive-bias interpretation. The current manuscript reports performance gains of the full GR3D model relative to strong baselines that lack the three grounding modules, but these comparisons do not hold every other training factor fixed. We will therefore add a controlled ablation study in the revision: we will train three additional variants from the same initialization and data schedule, each ablating one grounding component while keeping all other hyperparameters identical. The results will be reported in a new table and discussed with respect to the causal claim. revision: yes
Circularity Check
No circularity in derivation chain; claims are empirical
full rationale
The paper introduces GR3D as a VLM architecture with explicit/implicit 2D and monocular 3D grounding mechanisms, then reports benchmark gains as evidence that grounding acts as an inductive bias. No equations, parameter-fitting procedures, or mathematical derivation steps appear in the abstract or description. Claims rest on empirical results rather than any self-definitional loop, fitted-input prediction, or self-citation that reduces the central result to its own inputs by construction. The absence of any load-bearing derivation chain makes circularity analysis inapplicable; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 2, 8
2023
-
[2]
Vila: On pre-training for vi- sual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for vi- sual language models. InCVPR, 2024. 2
2024
-
[3]
Nvila: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yux- ian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. InCVPR, 2025. 3
2025
-
[4]
Kosmos-2: Grounding multimodal large language models to the world
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. InICLR, 2024
2024
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jin- gren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
How far are we to gpt-4v? clos- ing the gap to commercial multimodal models with open- source suites.Science China Information Sciences, 2024
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? clos- ing the gap to commercial multimodal models with open- source suites.Science China Information Sciences, 2024
2024
-
[7]
OpenAI. Gpt-4 technical report, 2023. arXiv:2303.08774. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team. Gemini: a family of highly capable multi- modal models.arXiv:2312.11805, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Habitat 2.0: Training home assistants to rearrange their habitat
Andrew Szot, Alexander Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Singh Chaplot, Oleksandr Maksymets, et al. Habitat 2.0: Training home assistants to rearrange their habitat. InNeurIPS, 2021. 2
2021
-
[10]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InCVPR, 2024
2024
-
[11]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InCoRL, 2023
2023
-
[12]
Robocasa: Large-scale simulation of every- day tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of every- day tasks for generalist robots. InRSS, 2024
2024
-
[13]
Navila: Legged robot vision-language-action model for navigation.RSS, 2025
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language-action model for navigation.RSS, 2025
2025
-
[14]
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, et al. Egovla: Learning vision- language-action models from egocentric human videos. arXiv preprint arXiv:2507.12440, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
GR00T N1.5: An Improved Open Foundation Model for Generalist Humanoid Robots
NVIDIA Research. GR00T N1.5: An Improved Open Foundation Model for Generalist Humanoid Robots. https://research.nvidia.com/labs/gear/ gr00t-n1_5, 2025
2025
-
[16]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: A vision-language-action model with open-world generaliza- tion.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, Winson Han, Wilbert Pumacay, Angelica Wu, Rose Hendrix, Karen Farley, Eli VanderBilt, Ali Farhadi, Dieter Fox, and Ranjay Krishna. Molmoact: Action rea- soning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Cliport: What and where pathways for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. In CoRL, 2022. 2
2022
-
[19]
Rt-1: Robotics transformer for real-world con- trol at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world con- trol at scale. InRSS, 2023
2023
-
[20]
Robovqa: Multimodal long-horizon reasoning for robotics
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. Robovqa: Multimodal long-horizon reasoning for robotics. InICRA, 2024. 2
2024
-
[21]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. InNeurIPS, 2024. 2, 5, 8
2024
-
[22]
3d aware re- gion prompted vision language model.arXiv preprint arXiv:2509.13317, 2025
An-Chieh Cheng, Yang Fu, Yukang Chen, Zhijian Liu, Xiaolong Li, Subhashree Radhakrishnan, Song Han, Yao Lu, Jan Kautz, Pavlo Molchanov, et al. 3d aware re- gion prompted vision language model.arXiv preprint arXiv:2509.13317, 2025. 3, 5, 8, 1, 2
-
[23]
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, et al. Roborefer: Towards spa- tial referring with reasoning in vision-language models for robotics.arXiv preprint arXiv:2506.04308, 2025. 5, 1
-
[24]
Robobrain 2.0 technical report
BAAI RoboBrain Team. Robobrain 2.0 technical report. arXiv preprint arXiv:2507.02029, 2025. 1
-
[25]
Robopoint: A vision-language model for spatial affordance prediction for robotics
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousa- vian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics. InCoRL,
-
[26]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wen- qian Wang, et al. Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025. 5, 6, 8
-
[27]
Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness. InICCV, 2025. 8
2025
-
[28]
Video-3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. InCVPR, 2025. 8
2025
-
[29]
3d-r1: Enhanc- ing reasoning in 3d vlms for unified scene understanding
Ting Huang, Zeyu Zhang, and Hao Tang. 3d-r1: Enhanc- ing reasoning in 3d vlms for unified scene understanding. arXiv:2507.23478, 2025. 2
-
[30]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Are- nas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, 2017. 2
2017
-
[32]
Omni3d: A large benchmark and model for 3d object detection in the wild
Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, and Georgia Gkioxari. Omni3d: A large benchmark and model for 3d object detection in the wild. InCVPR, 2023. 2, 5, 6, 8
2023
-
[33]
Cambrian-1: A fully open, vision-centric ex- ploration of multimodal llms
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric ex- ploration of multimodal llms. InNeurIPS, 2024. 2, 6
2024
-
[34]
Sat: Dy- namic spatial aptitude training for multimodal language models
Arijit Ray, Jiafei Duan, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A Plummer, Ranjay Krishna, Kuo-Hao Zeng, et al. Sat: Dy- namic spatial aptitude training for multimodal language models. InCOLM, 2025. 2, 6, 8
2025
-
[35]
Sun rgb-d: A rgb-d scene understanding benchmark suite
Shuran Song, Samuel P Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene understanding benchmark suite. InCVPR, 2015. 5
2015
-
[36]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A di- verse real-world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Objectron: A large scale dataset of object-centric videos in the wild with pose annotations
Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. Objectron: A large scale dataset of object-centric videos in the wild with pose annotations. InCVPR, 2021. 5
2021
-
[38]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, At- ulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In ICCV, 2021. 5
2021
-
[39]
Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 2013. 5
2013
-
[40]
nuscenes: A mul- timodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A mul- timodal dataset for autonomous driving. InCVPR, 2020. 5
2020
-
[41]
Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection
Danila Rukhovich, Anna V orontsova, and Anton Konushin. Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection. InWACV,
-
[42]
Smoke: Single- stage monocular 3d object detection via keypoint estima- tion
Zechen Liu, Zizhang Wu, and Roland T´oth. Smoke: Single- stage monocular 3d object detection via keypoint estima- tion. InCVPRW, 2020. 5, 8
2020
-
[43]
Open vocabulary monocular 3d object detection
Jin Yao, Hao Gu, Xuweiyi Chen, Jiayun Wang, and Zezhou Cheng. Open vocabulary monocular 3d object detection. arXiv preprint arXiv:2411.16833, 2024. 5, 6, 8
-
[44]
Detect anything 3d in the wild
Hanxue Zhang, Haoran Jiang, Qingsong Yao, Yanan Sun, Renrui Zhang, Hao Zhao, Hongyang Li, Hongzi Zhu, and Zetong Yang. Detect anything 3d in the wild. InCVPR,
-
[45]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical re- port.arXiv preprint arXiv:2511.21631, 2025. 5, 6, 8, 1, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InECCV, 2024. 6
2024
-
[47]
RealWorldQA: A benchmark dataset for real-world spatial understanding.https://huggingface.co/ datasets/visheratin/realworldqa, 2024
xAI. RealWorldQA: A benchmark dataset for real-world spatial understanding.https://huggingface.co/ datasets/visheratin/realworldqa, 2024. 6
2024
-
[48]
Embspatial-bench: Benchmarking spa- tial understanding for embodied tasks with large vision- language models
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spa- tial understanding for embodied tasks with large vision- language models. InACL, 2024. 6, 8
2024
-
[49]
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reason- ing
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reason- ing. InACL, 2022. 6
2022
-
[50]
Mme: A comprehensive evaluation bench- mark for multimodal large language models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation bench- mark for multimodal large language models. InNeurIPS,
-
[51]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InEMNLP, 2023. 6
2023
-
[52]
A Diagram is Worth a Dozen Images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A Diagram is Worth a Dozen Images. InECCV, 2016. 6
2016
-
[53]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Ste- fan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. IJCV, 2020. 5
2020
-
[54]
Cubify anything: Scaling indoor 3d object detection
Justin Lazarow, David Griffiths, Gefen Kohavi, Francisco Crespo, and Afshin Dehghan. Cubify anything: Scaling indoor 3d object detection. InCVPR, 2025. 5
2025
-
[55]
Florence-2: Advancing a unified representation for a va- riety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a va- riety of vision tasks. InCVPR, 2024. 5
2024
-
[56]
Embodiedscan: A holistic multi- modal 3d perception suite towards embodied ai
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. Embodiedscan: A holistic multi- modal 3d perception suite towards embodied ai. InCVPR,
-
[57]
Depthlm: Metric depth from vision language models
Zhipeng Cai, Ching-Feng Yeh, Hu Xu, Zhuang Liu, Gre- gory Meyer, Xinjie Lei, Changsheng Zhao, Shang-Wen Li, Vikas Chandra, and Yangyang Shi. Depthlm: Metric depth from vision language models. InICLR, 2026. 5
2026
-
[58]
Hello gpt-4o.https : / / openai
OpenAI. Hello gpt-4o.https : / / openai . com / index/hello-gpt-4o/, 2024. 5, 2
2024
-
[59]
Xtuner: A toolkit for efficiently fine-tuning llm.https://github.com/InternLM/ xtuner, 2023
XTuner Contributors. Xtuner: A toolkit for efficiently fine-tuning llm.https://github.com/InternLM/ xtuner, 2023. 5
2023
-
[60]
Cogvlm: Visual expert for pretrained language models
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. InNeurIPS, 2024. 5, 2
2024
-
[61]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In CVPR, 2024. 5
2024
-
[62]
Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report.arXiv preprint arXiv:2403.17297, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Grounded chain-of-thought for multimodal large language models
Qiong Wu, Xiangcong Yang, Yiyi Zhou, Chenxin Fang, Baiyang Song, Xiaoshuai Sun, and Rongrong Ji. Grounded chain-of-thought for multimodal large language models. arXiv preprint arXiv:2503.12799, 2025. 7, 8
-
[64]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv:2502.13923, 2025. 8, 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabil- ities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabil- ities. InCVPR, 2024. 8, 1
2024
-
[66]
Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors
Chenyang Ma, Kai Lu, Ta-Ying Cheng, Niki Trigoni, and Andrew Markham. Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors. InNeurIPS, 2024. 8
2024
-
[67]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. InICRA, 2025
2025
-
[68]
3dsrbench: A comprehen- sive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Celso M de Melo, Alan Yuille, and Jieneng Chen. 3dsrbench: A comprehen- sive 3d spatial reasoning benchmark. InICCV, 2025
2025
-
[69]
Sparkle: Mastering basic spatial capabilities in vision language models elicits gen- eralization to spatial reasoning
Yihong Tang, Ao Qu, Zhaokai Wang, Dingyi Zhuang, Zhaofeng Wu, Wei Ma, Shenhao Wang, Yunhan Zheng, Zhan Zhao, and Jinhua Zhao. Sparkle: Mastering basic spatial capabilities in vision language models elicits gen- eralization to spatial reasoning. InFindings of EMNLP, 2025
2025
-
[70]
Scene-llm: Extending language model for 3d visual understanding and reasoning
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning. InWACV, 2025
2025
-
[71]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InCVPR, 2025
2025
-
[72]
Llava-spacesgg: Visual instruct tuning for open-vocabulary scene graph generation with enhanced spatial relations
Mingjie Xu, Mengyang Wu, Yuzhi Zhao, Jason Chun Lok Li, and Weifeng Ou. Llava-spacesgg: Visual instruct tuning for open-vocabulary scene graph generation with enhanced spatial relations. InWACV, 2025
2025
-
[73]
Visual agentic ai for spatial reasoning with a dynamic api
Damiano Marsili, Rohun Agrawal, Yisong Yue, and Geor- gia Gkioxari. Visual agentic ai for spatial reasoning with a dynamic api. InCVPR, 2025
2025
-
[74]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spa- tialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task plan- ning.arXiv:2501.10074, 2025
-
[75]
Reasoning paths with reference objects elicit quan- titative spatial reasoning in large vision-language models
Yuan-Hong Liao, Rafid Mahmood, Sanja Fidler, and David Acuna. Reasoning paths with reference objects elicit quan- titative spatial reasoning in large vision-language models. InEMNLP, 2024
2024
-
[76]
Thinking in space: How mul- timodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. InCVPR, 2025. 2
2025
-
[77]
Situa- tional awareness matters in 3d vision language reasoning
Yunze Man, Liang-Yan Gui, and Yu-Xiong Wang. Situa- tional awareness matters in 3d vision language reasoning. InCVPR, 2024
2024
-
[78]
Multi- modal situated reasoning in 3d scenes
Xiongkun Linghu, Jiangyong Huang, Xuesong Niu, Xiao- jian Shawn Ma, Baoxiong Jia, and Siyuan Huang. Multi- modal situated reasoning in 3d scenes. InNeurIPS, 2024
2024
-
[79]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progres- sive training for spatial reasoning in vision-language mod- els.arXiv preprint arXiv:2510.08531, 2025. 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.