Gradient-Free Training of Spiking Neural Networks via Low-Rank Evolution Strategies
Pith reviewed 2026-06-30 20:11 UTC · model grok-4.3
The pith
Low-rank factorization of evolution strategy perturbations trains spiking neural networks to 79.21 percent accuracy without gradients or backpropagation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
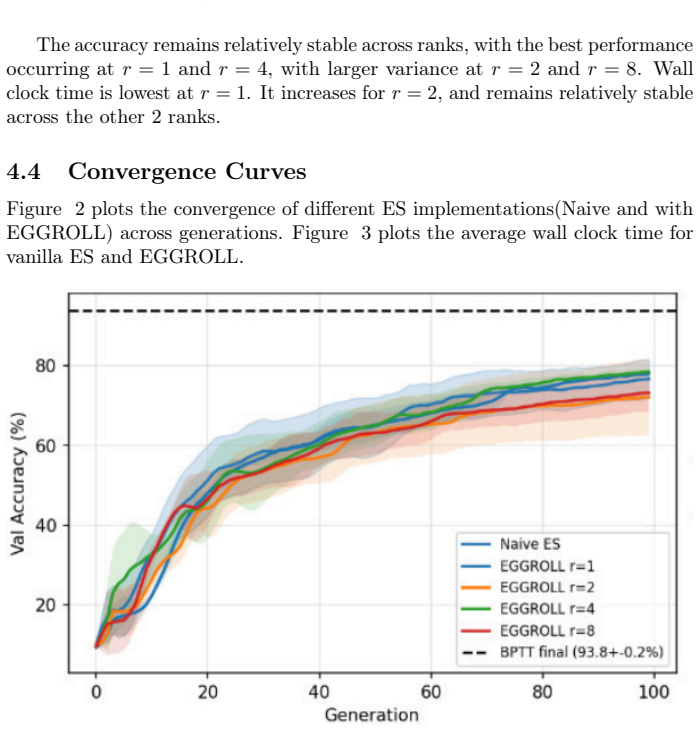
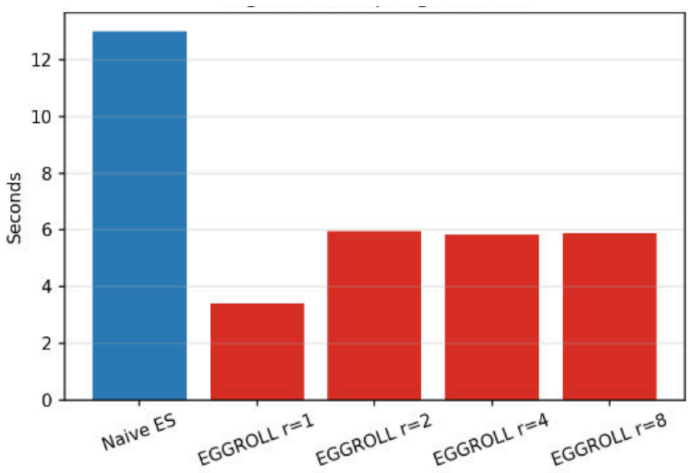
EGGROLL factorizes the perturbations used by evolution strategies so that each generation stores and applies updates in O(r(m+n)) memory instead of O(mn). When this factorization is paired with a leaky integrate-and-fire spiking network and evaluated on N-MNIST, gradient-free optimization reaches 79.21 percent test accuracy and runs 2.23 times faster per generation than the corresponding full-rank evolution strategy.
What carries the argument
EGGROLL, the low-rank factorization of evolution-strategy perturbations that reduces memory and compute from full matrix storage to the product of two smaller factors.
If this is right
- Spiking networks become trainable directly on neuromorphic chips without any surrogate-gradient or backpropagation circuitry.
- Memory cost of evolution-strategy training now grows linearly rather than quadratically with layer width, opening larger networks to gradient-free methods.
- The accuracy-speed tradeoff can be tuned by choosing the rank parameter, giving practitioners a concrete dial between fidelity and efficiency.
- Non-differentiable neuron models other than leaky integrate-and-fire become candidates for the same low-rank evolution strategy pipeline.
Where Pith is reading between the lines
- The same factorization could be applied to evolution strategies for other discrete or non-differentiable dynamical systems beyond spiking neurons.
- If the rank parameter can be adapted during training, the method might automatically balance exploration and memory use on varying hardware constraints.
- Because the approach removes any requirement for differentiable approximations, it may serve as a baseline when comparing surrogate-gradient accuracy on tasks where on-chip learning is mandatory.
Load-bearing premise
The low-rank factorization of perturbations still supplies enough directional information to produce useful parameter updates for spiking network optimization.
What would settle it
Running the same leaky integrate-and-fire network on N-MNIST with full-rank evolution strategies and obtaining substantially higher accuracy than 79.21 percent would show that the low-rank approximation discards critical search directions.
Figures

read the original abstract
Spiking Neural Networks (SNNs) offer compelling energy efficiency on neuromorphic hardware, yet their training remains challenging because the discrete spike threshold is non-differentiable. Surrogate-gradient methods sidestep this by approximating the derivative, but they impose backpropagation infrastructure that is incompatible with on-chip learning. Evolution Strategies (\es) are a natural gradient-free alternative, yet their computational cost scales with the number of parameters, making them impractical for large weight matrices. We present a method for training SNNs using EGGROLL, a low-rank factorisation of ES perturbations that reduces per-generation memory from $\mathcal{O}(mn)$ to $\mathcal{O}(r(m{+}n))$. Combining EGGROLL with a Leaky Integrate-and-Fire SNN on N-MNIST, we demonstrate that gradient-free training achieves 79.21% test accuracy while reducing per-generation wall-clock time by 2.23$\times$ relative to full-rank ES. Our results demonstrate EGGROLL is viable for SNN training, with a clear accuracy-speed tradeoff, compatible with training on neuromorphic hardware without surrogate gradients.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EGGROLL, a low-rank factorization of Evolution Strategies (ES) perturbations for gradient-free training of Spiking Neural Networks (SNNs). It reduces per-generation memory from O(mn) to O(r(m+n)) and, when combined with a Leaky Integrate-and-Fire SNN on N-MNIST, reports 79.21% test accuracy together with a 2.23× reduction in per-generation wall-clock time relative to full-rank ES, positioning the method as viable for neuromorphic hardware without surrogate gradients.
Significance. If the empirical claims hold under proper controls, the approach would supply a memory-efficient gradient-free alternative for SNN training that avoids backpropagation infrastructure, with a demonstrated accuracy-speed tradeoff. No machine-checked proofs, reproducible code, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the headline claim of 79.21% test accuracy on N-MNIST requires that the rank-r factorization U V^T still yields fitness gradients whose expectation approximates the true gradient of the SNN loss; the manuscript provides neither a bound on the bias introduced when dominant singular vectors lie outside the sampled subspace nor an ablation isolating directional loss, rendering the viability conclusion load-bearing on an untested assumption.
- [Abstract] Abstract: the reported accuracy and 2.23× speedup figures are presented without any information on experimental controls, error bars, number of independent runs, or the procedure used to select the rank hyperparameter r, which directly undermines verification of the central empirical result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims. We address each major comment below and outline revisions to improve clarity and empirical rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 79.21% test accuracy on N-MNIST requires that the rank-r factorization U V^T still yields fitness gradients whose expectation approximates the true gradient of the SNN loss; the manuscript provides neither a bound on the bias introduced when dominant singular vectors lie outside the sampled subspace nor an ablation isolating directional loss, rendering the viability conclusion load-bearing on an untested assumption.
Authors: We agree that a theoretical bound on approximation bias would strengthen the claims, but the current work is primarily empirical and does not derive such a bound. To address the concern, we will add an ablation study in the revised manuscript that varies rank r, reports resulting test accuracy, and compares convergence behavior against full-rank ES. This will provide direct empirical evidence on the impact of the low-rank directional approximation. revision: partial
-
Referee: [Abstract] Abstract: the reported accuracy and 2.23× speedup figures are presented without any information on experimental controls, error bars, number of independent runs, or the procedure used to select the rank hyperparameter r, which directly undermines verification of the central empirical result.
Authors: We acknowledge the need for these details. The revised manuscript will include the number of independent runs performed, standard deviations or error bars on the reported accuracy and timing figures, a description of experimental controls (e.g., fixed random seeds, hardware setup), and the procedure used to select r (grid search over validation accuracy). revision: yes
Circularity Check
No circularity; empirical result stands on observed performance
full rationale
The paper presents EGGROLL as a low-rank factorization technique for ES perturbations and reports an empirical outcome (79.21% accuracy on N-MNIST with 2.23× speedup) from combining it with an LIF SNN. No equations, derivations, or predictions appear that reduce the accuracy claim to a fitted quantity defined by the method itself, a self-citation chain, or an ansatz smuggled via prior work. The central claim is an observed experimental result rather than a mathematical identity or forced prediction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank r
axioms (1)
- domain assumption Low-rank perturbations suffice to drive effective evolution-strategy updates in spiking networks
invented entities (1)
-
EGGROLL
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The CMA Evolution Strategy: A Tutorial
Nikolaus Hansen. The cma evolution strategy: A tutorial.arXiv preprint arXiv:1604.00772,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Cifar10-dvs: An event-stream dataset for object classification.Frontiers in Neuroscience, Volume 11 - 2017,
10 Hongmin Li, Hanchao Liu, Xiangyang Ji, Guoqi Li, and Luping Shi. Cifar10-dvs: An event-stream dataset for object classification.Frontiers in Neuroscience, Volume 11 - 2017,
2017
-
[4]
ISSN 1662-453X. doi: 10.3389/fnins.2017.00309. URL https://www.frontiersin.org/journals/neuroscience/articles/ 10.3389/fnins.2017.00309. Paul A Merolla, John V Arthur, Rodrigo Alvarez-Icaza, et al. A million spiking- neuron integrated circuit with a scalable communication network and interface. Science, 345(6197):668–673,
-
[5]
Cohen, and Nitish Thakor
Garrick Orchard, Ajinkya Jayawant, Gregory K. Cohen, and Nitish Thakor. Converting static image datasets to spiking neuromorphic datasets using saccades.Frontiers in Neuroscience, Volume 9 - 2015,
2015
-
[6]
ISSN 1662- 453X. doi: 10.3389/fnins.2015.00437. URL https://www.frontiersin.org/ journals/neuroscience/articles/10.3389/fnins.2015.00437. Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, and Ilya Sutskever. Evo- lution strategies as a scalable alternative to reinforcement learning.arXiv preprint arXiv:1703.03864,
-
[7]
Evolution strategies at the hyperscale.arXiv preprint arXiv:2511.16652,
Soham Sarkar et al. Evolution strategies at the hyperscale.arXiv preprint arXiv:2511.16652,
-
[8]
A wafer-scale neuromorphic hardware system for large-scale neural modeling
Johannes Schemmel, Daniel Brüderle, Andreas Grübl, et al. A wafer-scale neuromorphic hardware system for large-scale neural modeling. InProceedings of the IEEE International Symposium on Circuits and Systems, pages 1947–
1947
-
[9]
ISSN 0893-6080. doi: https://doi. org/10.1016/j.neunet.2009.12.004. URL https://www.sciencedirect.com/ science/article/pii/S0893608009003220. The 18th International Confer- ence on Artificial Neural Networks, ICANN
-
[11]
URLhttp://arxiv.org/abs/1706.03762. 11 A Variance Analysis Across Seeds Table 2: Per-seed accuracy and average training time across three seeds. Method Test Acc. (%) Time / gen (s) Vanilla ES (seed
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.