Exploring Autonomous Agentic Data Engineering for Model Specialization
Pith reviewed 2026-06-29 07:16 UTC · model grok-4.3
The pith
LLMs can act as autonomous data engineers to specialize models, achieving 57.29% gains through iterative agent-driven data adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
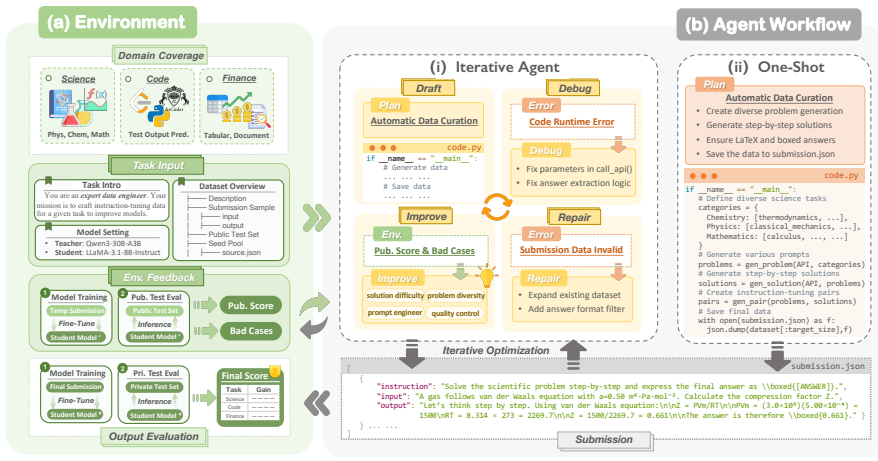
The paper claims that LLMs can execute an end-to-end data engineering pipeline for model specialization, with GPT-5.2 constructing a training curriculum that improves a student model by 57.29% solely through iterative, agent-driven data adaptation across multiple domains.
What carries the argument
Autonomous Agentic Data Engineering: LLM agents that plan, generate, and iteratively optimize training data guided by measured post-training performance improvement.
If this is right
- Agent-driven data adaptation can replace human-designed workflows for domain specialization.
- Iterative optimization of training data produces measurable gains on held-out tasks.
- Autonomous data engineering is a measurable capability that can be evaluated across LLMs.
- This establishes a path toward fully agent-driven model specialization without manual data curation.
Where Pith is reading between the lines
- The same loop might allow smaller models to perform useful data engineering if the planning steps are simplified.
- The approach could combine with other agent systems to handle data for multimodal or code-specialized tasks.
- Bottlenecks in long-horizon planning may appear when domains require more complex data structures than the tested cases.
- Gains could be tested by swapping the guiding evaluation set mid-process to check for hidden dependence on the iteration signal.
Load-bearing premise
Post-training performance on held-out tasks supplies a clean, non-circular signal that can safely direct iterative data generation and selection without human intervention or overfitting.
What would settle it
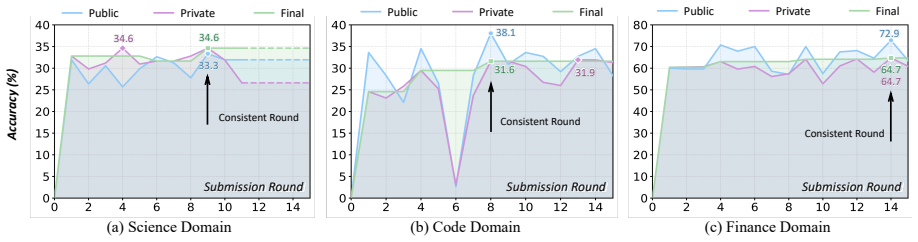
Measure whether the performance gains persist when the final evaluation uses a fresh set of tasks never seen during the agent's iterative data selection and refinement process.
Figures

read the original abstract
Large Language Models (LLMs) have demonstrated strong performance on general tasks, while often struggling to adapt to specialized domains without high-quality domain-specific data. Existing LLM-based data curation methods primarily rely on human-designed workflows, leaving it unexamined whether LLMs can autonomously execute an end-to-end data engineering pipeline for model specialization. We formalize Autonomous Agentic Data Engineering, a novel task designed to evaluate LLMs as autonomous data engineers that drive model specialization through end-to-end data curation. We frame data as an optimizable component and study agents that plan, generate, and iteratively optimize training data across multiple domains, guided by post-training performance improvement. Experiments show that autonomous LLM data engineers yield substantial gains, as GPT-5.2 constructs a training curriculum that improves a student model by 57.29%, entirely through iterative, agent-driven data adaptation. By illuminating both potential and bottlenecks, our study establishes autonomous data engineering as a measurable capability and charts a path toward agent-driven model specialization (Code will be released at https://github.com/zjunlp/DataAgent).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes 'Autonomous Agentic Data Engineering' as a task in which LLMs act as autonomous agents to plan, generate, and iteratively optimize training data for model specialization across domains. The central empirical claim is that an agent based on GPT-5.2 produces a training curriculum that improves a student model by 57.29% entirely through agent-driven data adaptation guided by post-training performance signals on held-out tasks.
Significance. If the reported gains are shown to arise from non-circular evaluation and proper controls, the work would establish autonomous data engineering as a measurable capability and reduce dependence on human-designed curation pipelines. The framing of data as an optimizable component and the release of code are positive elements that could support reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that GPT-5.2 'constructs a training curriculum that improves a student model by 57.29%' supplies no information on baselines, controls, dataset sizes, evaluation metrics, or statistical significance, rendering it impossible to assess whether the number supports the central claim of substantial gains via autonomous data engineering.
- [Abstract] Abstract (and any Methods/Experiments description of the iterative loop): the process is described as 'guided by post-training performance improvement' on held-out tasks, yet no distinct validation split is mentioned that separates the signal used for agent planning/generation/selection from the final reported test metric; without this separation the 57.29% figure risks arising from repeated optimization against the evaluation distribution rather than genuine adaptation.
minor comments (1)
- The promise to release code at the cited GitHub repository is welcome but should be accompanied by a brief description of the repository contents and any reproducibility artifacts (e.g., seeds, exact prompts) in the main text or appendix.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We address the concerns regarding the abstract's level of detail and the evaluation protocol for the iterative loop. We will revise the manuscript to improve transparency on both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GPT-5.2 'constructs a training curriculum that improves a student model by 57.29%' supplies no information on baselines, controls, dataset sizes, evaluation metrics, or statistical significance, rendering it impossible to assess whether the number supports the central claim of substantial gains via autonomous data engineering.
Authors: We agree the abstract is too concise and omits these details. The Experiments section reports comparisons against random selection and human-curated baselines, per-domain dataset sizes (thousands of examples), accuracy/F1 as metrics, and significance via 5-run averages with standard deviation. We will revise the abstract to briefly note the evaluation setup and controls while retaining its summary nature. revision: yes
-
Referee: [Abstract] Abstract (and any Methods/Experiments description of the iterative loop): the process is described as 'guided by post-training performance improvement' on held-out tasks, yet no distinct validation split is mentioned that separates the signal used for agent planning/generation/selection from the final reported test metric; without this separation the 57.29% figure risks arising from repeated optimization against the evaluation distribution rather than genuine adaptation.
Authors: This is a substantive concern. The current manuscript text refers to 'held-out tasks' for guidance but does not explicitly describe a validation split distinct from the final test set. We will revise the Methods and Experiments sections to state that a held-out validation partition (never seen in final reporting) supplies the performance signal for agent decisions, while the 57.29% figure is computed on a completely disjoint test partition. This clarification will be added to eliminate ambiguity about circularity. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper is an empirical study formalizing 'Autonomous Agentic Data Engineering' and reporting an observed 57.29% performance gain from an LLM agent's iterative data curation on held-out tasks. No mathematical derivation chain, equations, fitted parameters renamed as predictions, or self-definitional reductions are present. The central result is presented as an experimental outcome measured against external benchmarks rather than a quantity defined in terms of itself or forced by self-citation. The evaluation methodology concern (validation vs test split) is a validity issue, not a circularity reduction per the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. DeepSeek-AI. 2025. Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning. CoRR, abs/2501.12948. Etash Kumar Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashim...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Openthoughts: Data recipes for reasoning models.CoRR, abs/2506.04178. Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
AIDE: AI-Driven Exploration in the Space of Code
Datagen: Unified synthetic dataset generation via large language models. InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. 2025. Live- codebe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Large Language Models as Optimizers
OpenReview.net. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-instruct: Aligning language models with self-generated instructions. InProceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), ACL 2023, Toronto, Canada, Ju...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
In IEEE INFOCOM 2025 - IEEE Conference on Com- puter Communications, London, United Kingdom, May 19-22, 2025, pages 1–10
Espresso: Cost-efficient large model training by exploiting GPU heterogeneity in the cloud. In IEEE INFOCOM 2025 - IEEE Conference on Com- puter Communications, London, United Kingdom, May 19-22, 2025, pages 1–10. IEEE. A Dataset Details To systematically analyze the capability of LLM agents in end-to-end data engineering, we curate datasets across three ...
2025
-
[6]
instruction
Define the instruction format: • Define a single fixed"instruction"string matchingsample_submission.jsonstyle
-
[7]
Build topic templates spanning: • Mathematics:calculus (integrals, series, multivariable), differential equations, linear algebra, probability/statistics •Physics:mechanics, E&M, circuits, waves/optics, thermodynamics • Chemistry:gases (vdW/ideal), equilibrium, kinetics, thermodynamics, electrochemistry, colligative properties
-
[8]
where
Generate parameterized prompts (per template) requiring the teacher to: • Write a textbook-style problem with given numbers and a specified answer unit • Provide a step-by-step solution including computations • End with: The answer is therefore \boxed{...}. where ... is a decimal with exactly three digits
-
[9]
Bulk generation: • Use api_generate_batch with batch size 80 to produce ∼2200 candidates (buffer for filtering)
-
[10]
Post-process and filter: • Keep only items whose output contains at least one\boxed{...} and whose last\boxed{} matches a decimal number with 3 digits • Ensure output ends with the exact final sentence • Ensure fieldsinstruction,input,outputare non-empty strings
-
[11]
Regenerate if needed: • If<2000valid samples, regenerate only the deficit with stricter formatting reminders
-
[12]
Finalize dataset: • Shuffle, truncate to first 2000, and write to../submission/submission.json
2000
-
[13]
Checkpointing: • Save checkpoints every 200 valid samples to avoid data loss Based on self-reflection and environmental feedback, GPT-5.2 proposed the optimization approach shown below based on the original solution: Improvement Plan of GPT-5.2 in Science Task
-
[14]
Improve solution quality by: • Generating more focused, step-by-step solutions without excessive verbosity • Ensuring all calculations are complete and accurate • Requiring clear final answers in proper boxed format
-
[15]
Enhance problem diversity by: • Creating problems across broader difficulty ranges • Including more applied/real-world scientific scenarios • Balancing theoretical and computational problems
-
[16]
Better prompt engineering: • More specific instructions for concise, accurate solutions • Explicit requirements for complete calculations • Template-based solution structure to ensure consistency
-
[17]
/submission/submission.json
Quality control: • Filter out incomplete or malformed solutions • Validate that solutions have proper final answers • Ensure mathematical notation is correct Guided by the improvement plan above, the model generated a more complex and robust code version that covers a broader scope and includes more challenging questions. The improved code corresponding t...
2000
-
[18]
Step-by-step calculation (show intermediate numeric values)
-
[19]
input":
Final line exactly: The answer is therefore \\boxed{{X.XXX}}. 146- Output must be concise: aim for ~12-25 lines; no filler. 147- Final boxed value must be a decimal with exactly three digits; no units in the box. 148- Ensure the last \\boxed{{...}} in the output is the final answer. 149 150Return JSON only: 151{{"input": "...", "output": "..."}} 152""".st...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.