Audio Pirates: Black-box Audio Watermark Removal via Diffusion Priors
Pith reviewed 2026-06-29 06:17 UTC · model grok-4.3
The pith
A black-box diffusion method removes inaudible audio watermarks by regenerating from intermediate noise without knowing the scheme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
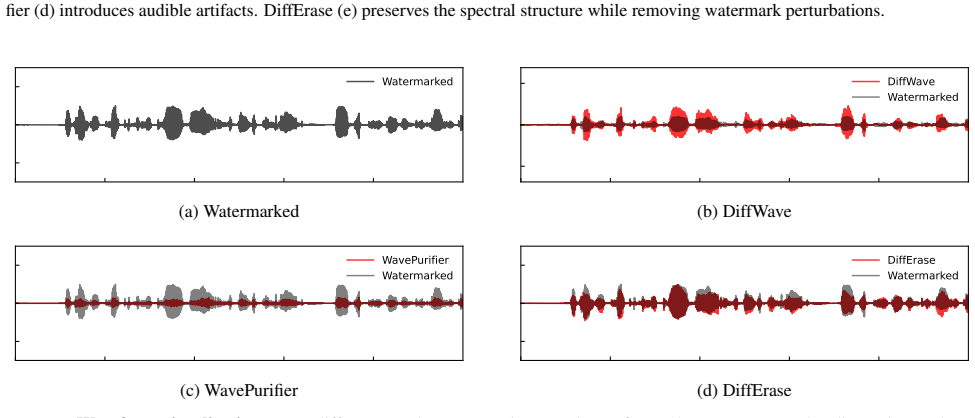
Theoretical analysis and extensive experiments demonstrate that inaudible audio watermarks are highly vulnerable: across multiple audio domains, DiffErase consistently removes watermarks while preserving perceptual quality by perturbing watermarked audio to an intermediate diffusion noise level and regenerating it using a pretrained denoising model.
What carries the argument
DiffErase, the process of perturbing watermarked audio to an intermediate diffusion noise level and regenerating with a pretrained denoising model to suppress watermark signals in a black-box setting.
If this is right
- Watermarks can be removed consistently while maintaining audio quality.
- The attack succeeds without any knowledge of or access to the watermarking scheme.
- The vulnerability holds across multiple audio domains.
- Future audio watermarking designs must account for diffusion-based removal threats.
Where Pith is reading between the lines
- The same regeneration approach might be tested on watermarking for images or video.
- Watermark developers could add tests against diffusion model regeneration during design.
- Watermarks that embed signals resistant to denoising steps might evade this type of attack.
Load-bearing premise
That perturbing watermarked audio to an intermediate diffusion noise level and regenerating with a pretrained denoising model will reliably suppress the watermark signal without access to the watermarking scheme or degrading perceptual quality.
What would settle it
An experiment in which DiffErase either leaves watermarks detectable at high rates or produces audio with clearly degraded perceptual quality would falsify the central claim.
Figures


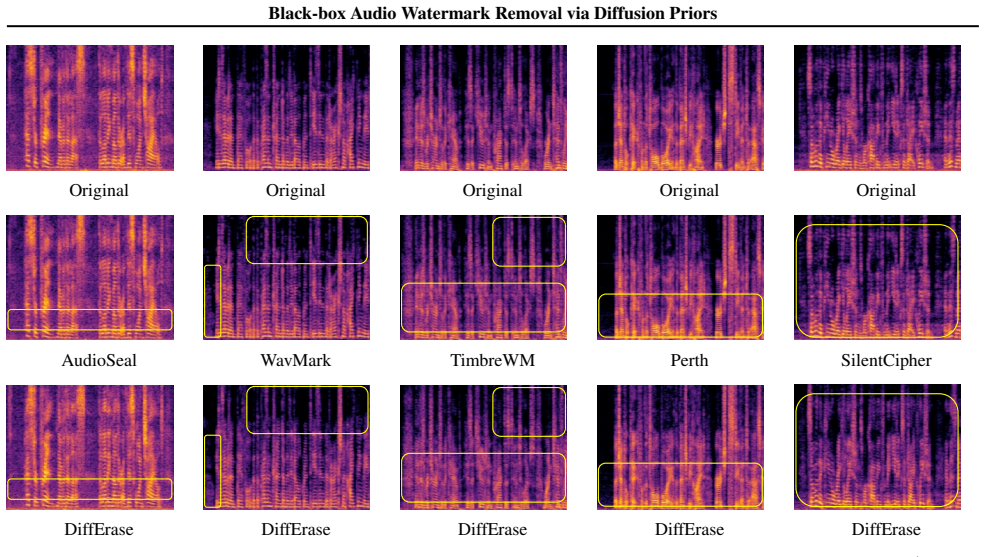
read the original abstract
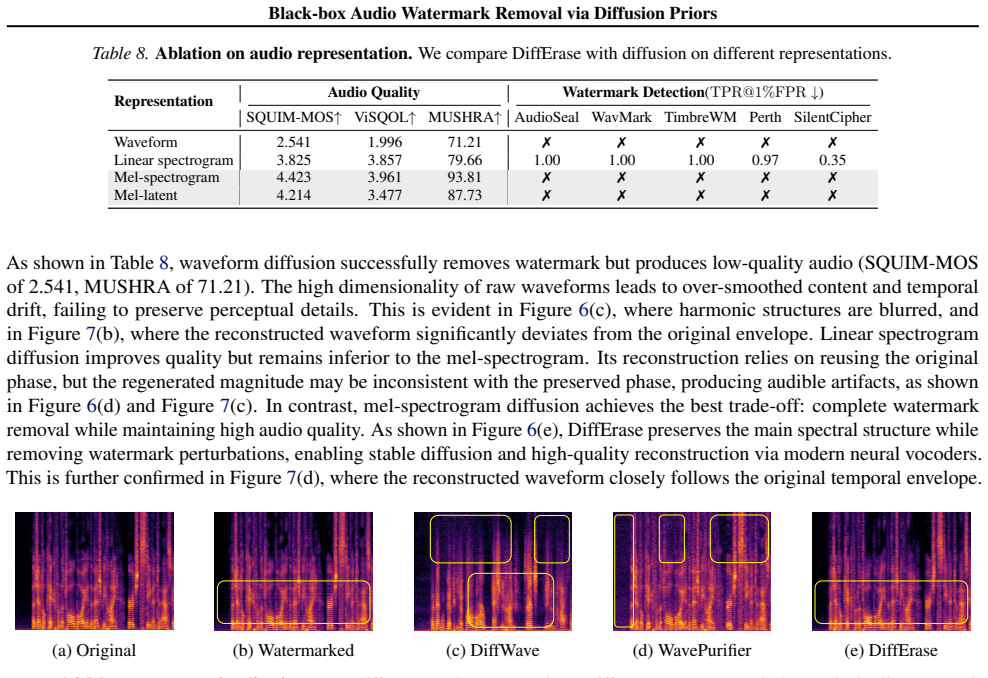
With the rise of AI-generated audio, watermarking has become widely used for detecting misuse and protecting intellectual property. However, adversaries may try to remove these watermarks, making it critical to evaluate how well watermarking schemes withstand removal attacks. Existing attacks are often impractical: they either noticeably degrade perceptual quality or require access to the watermarking scheme. We propose DiffErase, a black-box watermark removal attack that assumes no knowledge of the target watermarking scheme while maintaining perceptual quality. DiffErase perturbs watermarked audio to an intermediate diffusion noise level and regenerates it using a pretrained denoising model, effectively suppressing watermark signals. Theoretical analysis and extensive experiments demonstrate that inaudible audio watermarks are highly vulnerable: across multiple audio domains, DiffErase consistently removes watermarks while preserving perceptual quality. These findings highlight the need for future audio watermarking designs to consider diffusion-based threats. Code and demos are available at https://differase.github.io/DiffErase/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffErase, a black-box watermark removal attack on audio signals. It perturbs watermarked audio to an intermediate diffusion timestep and regenerates via a pretrained denoising model to suppress the watermark signal without access to the watermarking scheme or noticeable quality loss. Theoretical analysis and experiments across audio domains are claimed to show consistent watermark removal while preserving perceptual quality, highlighting vulnerabilities in existing watermarking designs.
Significance. If the central claim holds, the work identifies a practical diffusion-based threat to audio watermarking that is more general than prior attacks, which could drive more robust watermark designs for AI-generated content. The public release of code and demos is a positive factor for reproducibility.
major comments (2)
- [Method] Method section (diffusion perturbation step): the selection of the intermediate timestep t is not shown to be independent of the watermarking scheme or domain. If t is chosen via validation on the evaluated watermarks (or per-domain heuristics), the black-box guarantee fails for unseen schemes, directly undermining the claim that DiffErase 'consistently removes watermarks while preserving perceptual quality' without scheme access.
- [Experiments] Experiments (quantitative results): the abstract and claimed analysis assert support via metrics such as PESQ/STOI, but no error bars, dataset sizes, or statistical significance tests are referenced in the provided description; without these, the 'extensive experiments' do not yet establish robustness across domains.
minor comments (1)
- [Abstract] Abstract: no quantitative metrics or dataset details are provided despite claiming 'extensive experiments'; adding a sentence with key numbers (e.g., average detection rate drop, PESQ scores) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below. Where revisions are warranted we indicate them explicitly; we believe the core claims remain supported by the theoretical analysis and cross-domain results.
read point-by-point responses
-
Referee: [Method] Method section (diffusion perturbation step): the selection of the intermediate timestep t is not shown to be independent of the watermarking scheme or domain. If t is chosen via validation on the evaluated watermarks (or per-domain heuristics), the black-box guarantee fails for unseen schemes, directly undermining the claim that DiffErase 'consistently removes watermarks while preserving perceptual quality' without scheme access.
Authors: The timestep t is determined from the diffusion prior itself: we select the noise level at which the theoretical analysis shows watermark signals are attenuated while semantic content remains recoverable by the pretrained denoiser. This choice is fixed once the diffusion model is chosen and does not involve per-watermark validation or domain-specific heuristics. Experiments on multiple unseen watermarking schemes and audio domains were performed after fixing t, supporting the black-box claim. To make this explicit we will add a dedicated paragraph in the method section describing the selection criterion and its independence from any watermarking scheme. revision: partial
-
Referee: [Experiments] Experiments (quantitative results): the abstract and claimed analysis assert support via metrics such as PESQ/STOI, but no error bars, dataset sizes, or statistical significance tests are referenced in the provided description; without these, the 'extensive experiments' do not yet establish robustness across domains.
Authors: We agree that reporting error bars, exact dataset sizes per domain, and statistical significance tests would strengthen the presentation. In the revised manuscript we will include these details: standard deviations across runs, the number of audio clips evaluated in each domain, and p-values from paired statistical tests comparing watermarked and DiffErase-processed outputs. revision: yes
Circularity Check
No circularity; method relies on external pretrained models
full rationale
The paper describes an empirical black-box attack (DiffErase) that perturbs audio to an intermediate diffusion timestep and denoises with a pretrained model. No equations, derivations, or first-principles results are presented that reduce the claimed outcome to fitted parameters, self-definitions, or self-citation chains. The central claim rests on external pretrained diffusion models and experimental validation across domains, with no load-bearing self-referential steps or predictions that are forced by construction. The theoretical analysis is invoked but not shown to collapse into the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained diffusion denoising models trained on clean audio can regenerate natural-sounding audio from intermediate noise levels
Reference graph
Works this paper leans on
-
[1]
Wavmark: Watermarking for audio generation.arXiv preprint arXiv:2308.12770,
Chen, G., Wu, Y ., Liu, S., Liu, T., Du, X., and Wei, F. Wavmark: Watermarking for audio generation.arXiv preprint arXiv:2308.12770,
-
[2]
FMA: A Dataset For Music Analysis
Defferrard, M., Benzi, K., Vandergheynst, P., and Bresson, X. Fma: A dataset for music analysis.arXiv preprint arXiv:1612.01840,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
High Fidelity Neural Audio Compression
D´efossez, A., Copet, J., Synnaeve, G., and Adi, Y . High fidelity neural audio compression.arXiv preprint arXiv:2210.13438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Clotho: An audio captioning dataset
Drossos, K., Lipping, S., and Virtanen, T. Clotho: An audio captioning dataset. InICASSP 2020-2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 736–740. IEEE,
2020
-
[5]
Gilmer, J., Metz, L., Faghri, F., Schoenholz, S. S., Raghu, M., Wattenberg, M., and Goodfellow, I. Adversarial spheres.arXiv preprint arXiv:1801.02774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Huang, C., Yao, L., Lee, K. I., Zhang, L. E., Chen, X., and Pan, M. Echomark: Perceptual acoustic environ- ment transfer with watermark-embedded room impulse response.arXiv preprint arXiv:2511.06458,
-
[7]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Kong, J., Kim, J., and Bae, J. Hifi-gan: Generative ad- versarial networks for efficient and high fidelity speech synthesis.Advances in neural information processing systems, 33:17022–17033, 2020a. Kong, Z., Ping, W., Huang, J., Zhao, K., and Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761, 2020b. K...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
G., Ping, W., Ginsburg, B., Catanzaro, B., and Yoon, S
Lee, S. G., Ping, W., Ginsburg, B., Catanzaro, B., and Yoon, S. Bigvgan: A universal neural vocoder with large-scale training. In11th International Conference on Learning Representations, ICLR 2023,
2023
-
[9]
HarmonicAttack: An Adaptive Cross-Domain Audio Watermark Removal
Li, K., Hu, X., Grishchenko, I., and Lie, D. Harmoni- cattack: An adaptive cross-domain audio watermark re- moval.arXiv preprint arXiv:2511.21577,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ideaw: Robust neu- ral audio watermarking with invertible dual-embedding
Li, P., Zhang, X., Xiao, J., and Wang, J. Ideaw: Robust neu- ral audio watermarking with invertible dual-embedding. arXiv preprint arXiv:2409.19627,
-
[11]
Dear: A deep-learning-based audio re-recording resilient watermarking
Liu, C., Zhang, J., Fang, H., Ma, Z., Zhang, W., and Yu, N. Dear: A deep-learning-based audio re-recording resilient watermarking. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp. 13201–13209, 2023a. Liu, C., Zhang, J., Zhang, T., Yang, X., Zhang, W., and Yu, N. Detecting voice cloning attacks via timbre watermark- ing.arXiv...
-
[12]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Meng, C., He, Y ., Song, Y ., Song, J., Wu, J., Zhu, J.-Y ., and Ermon, S. Sdedit: Guided image synthesis and edit- ing with stochastic differential equations.arXiv preprint arXiv:2108.01073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
O’Reilly, P., Jin, Z., Su, J., and Pardo, B. Deep audio water- marks are shallow: Limitations of post-hoc watermarking techniques for speech.arXiv preprint arXiv:2504.10782,
-
[14]
URL https://github. com/resemble-ai/Perth. Roman, R. S., Fernandez, P., D ´efossez, A., Furon, T., Tran, T., and Elsahar, H. Proactive detection of voice cloning with localized watermarking.arXiv preprint arXiv:2401.17264,
-
[15]
K., Takahashi, N., Liao, W., and Mitsufuji, Y
Singh, M. K., Takahashi, N., Liao, W., and Mitsufuji, Y . Silentcipher: Deep audio watermarking.arXiv preprint arXiv:2406.03822,
-
[16]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Wen, Y ., Innuganti, A., Ramos, A. B., Guo, H., and Yan, Q. Sok: How robust is audio watermarking in generative ai models?arXiv preprint arXiv:2503.19176,
-
[18]
Defend- ing against adversarial audio via diffusion model.arXiv preprint arXiv:2303.01507,
Wu, S., Wang, J., Ping, W., Nie, W., and Xiao, C. Defend- ing against adversarial audio via diffusion model.arXiv preprint arXiv:2303.01507,
-
[19]
Fingerprinting deep neural networks for ownership protection: An ana- lytical approach
Yang, G., Geng, Z., Chen, Y ., and Luo, C. Fingerprinting deep neural networks for ownership protection: An ana- lytical approach. InThe Fourteenth International Confer- ence on Learning Representations, 2026a. URL https: //openreview.net/forum?id=sg3UNWKVFt. Yang, G., Geng, Z., Chen, Y ., and Luo, C. Liteguard: Effi- cient task-agnostic model fingerprint...
-
[20]
Proofs in Section 4.3 A.1
11 Black-box Audio Watermark Removal via Diffusion Priors A. Proofs in Section 4.3 A.1. Proof of Lemma 4.3 Lemma A.1(Score restores off-manifold deviations).Assume the manifold hypothesis and a local Gaussian approximation of pt, the score function points towards the high-density region. For a watermarked statext with off-manifold component Π⊥(xt)δ, there...
2021
-
[21]
The reconstructed mel-spectrogram is converted back to waveform using HiFi-GAN (Kong et al., 2020a)
Diffusion is then performed in the V AE latent space using a UNet with the following configuration: image size 64, base channels 128, 2 residual blocks per stage, channel multipliers [1,2,3,5] , and attention at resolutions {8,4,2} . The reconstructed mel-spectrogram is converted back to waveform using HiFi-GAN (Kong et al., 2020a). B.2. Baseline attacks ...
2025
-
[22]
in the spectrogram domain following Liu et al. (2024a). For speech, we use a query budget of 10,000 and perturbation bound ϵ= 0.02 . For music and environmental sounds, we foundϵ= 0.02insufficient for successful attacks and increased it toϵ= 0.2. 14 Black-box Audio Watermark Removal via Diffusion Priors Table 4.Comparison with baselineson the music domain...
2015
-
[23]
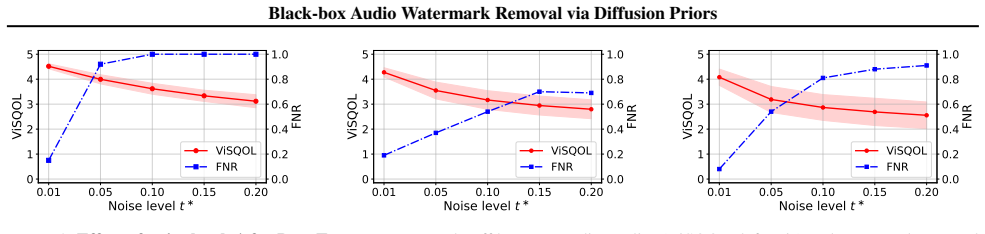
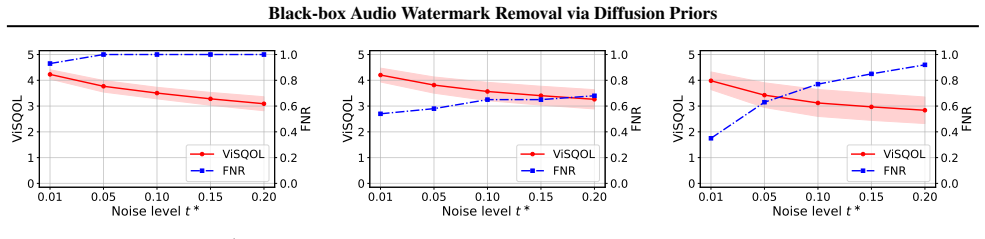
Noise level trade-off for DIFFERASE-LATENT Figure 5 shows the quality-removal trade-off for DIFFERASE-LATENT
C.2. Noise level trade-off for DIFFERASE-LATENT Figure 5 shows the quality-removal trade-off for DIFFERASE-LATENT. The trends are similar: increasing t∗ improves watermark removal (higher FNR) while reducing audio quality (lower ViSQOL). On speech, Perth becomes undetectable at t∗ ≥0.05 . On music and environmental sounds, complete removal requires higher...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.